智能涌现
大模型是如何练成的
(预印本)
v1.0 2026年3月23日
致 谢
谨以此书献给我的妻子和女儿,
没有她们在精神上的支持,
我是没有信心开始本书的工作。
同时感谢各种 AI 工具,
没有它们在效率上的支持,
我是没有时间精力完成本书的。
序章:为什么你需要读这个系列
一个吃螃蟹的人的崩溃
2024年年底,我盯着屏幕上一份来自客户的需求文档,第一次认真怀疑自己是不是步子迈太大了。
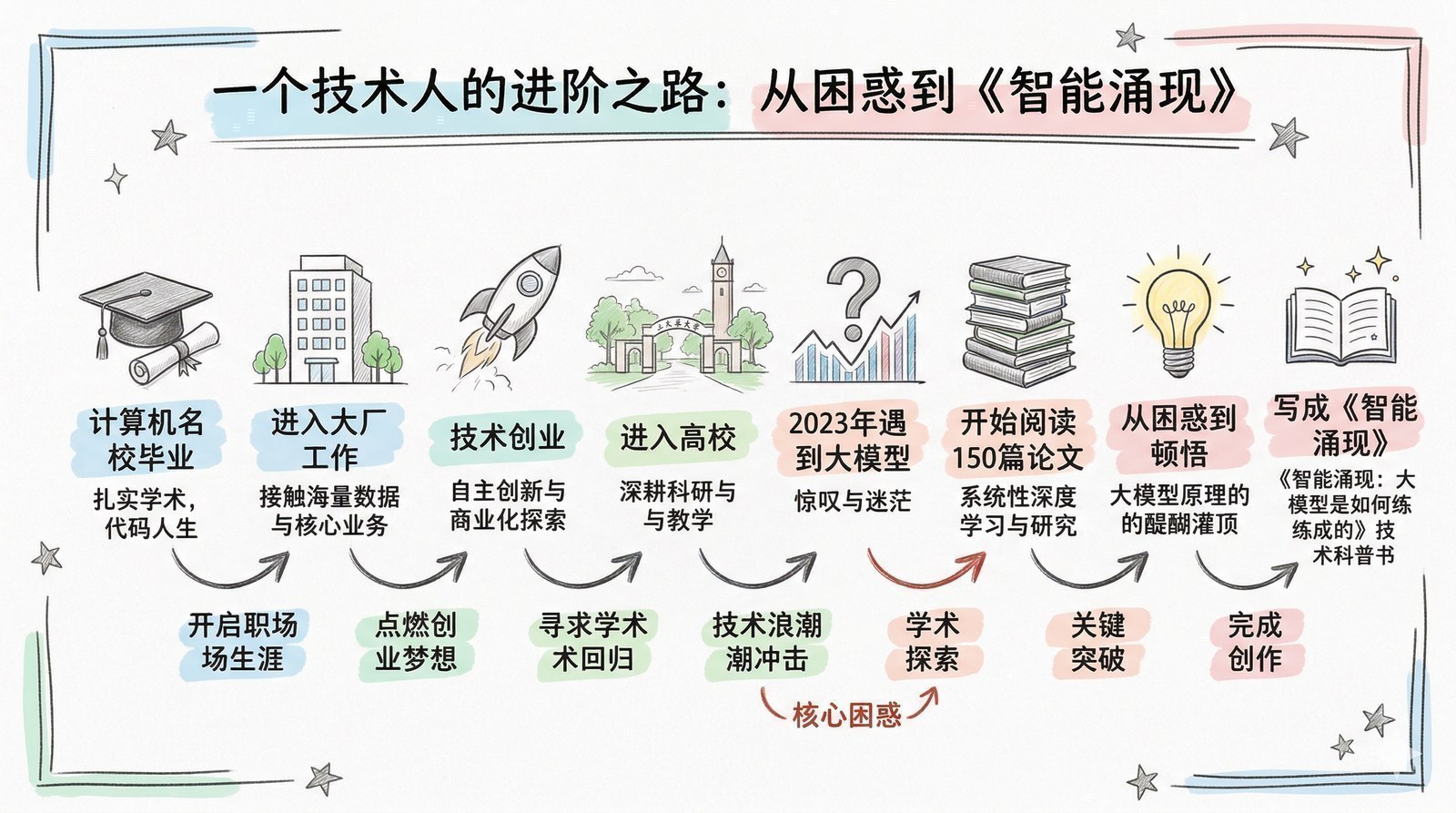
说来也好笑。十几年前我从计算机名校毕业,进了大厂做技术,后来出来创业,公司被收购,辗转几番回到高校做科技成果转化——说白了就是把实验室里的论文变成能解决真实问题的产品。听起来履历挺光鲜,但此刻坐在电脑前的我,和一个刚入行的实习生面对大模型时的困惑,其实没什么本质区别。
事情是这样的。2024年初,当大多数人还在讨论"大模型到底有没有用"的时候,我们团队已经开始接项目了——带着一股子"先干了再说"的劲头,成了行业里最早一批试图把大模型塞进真实业务场景的人。用今天时髦的话说,叫"AI落地先行者"。用更朴素的话说,叫"吃螃蟹的"。
螃蟹好不好吃暂且不论,先被扎了满手。
那个让我凌晨崩溃的项目,来自一家大型制造企业。他们想用AI自动审核供应商提交的技术规格书——几十页的PDF文档,混杂着表格、流程图、技术参数和手写批注。需求听起来合理:人工审核一份文档要两天,一年几千份,能不能用大模型压缩到两小时?
我的第一反应是"应该行吧"。毕竟GPT-4已经能看图了,openAI o1已经出现强大的推理能力了,多模态模型和推理模型一日千里。
然后现实给了我一记耳光。
模型能读懂合同里的文字,但读不准工程图纸上0.01mm精度的标注。能提取简单表格的数据,但遇到跨页合并单元格就乱了套。能总结一段话的意思,但没法在几十页文档中交叉比对前后矛盾的技术参数。
更要命的是接下来的决策——如果现在的模型做不到,我是该投入三个月自己造一个专用系统,还是再等三个月,等基座大模型迭代到能解决这个问题的水平?
这不是技术问题。这是赌注。赌错了方向,三个月的研发投入就打了水漂;等错了时间,客户就被竞争对手抢走了。
那天晚上我打开arXiv——一个科学论文搜索平台,搜了"multimodal document understanding",一篇论文引出另一篇,另一篇又引出十篇。我本以为会越读越迷糊,结果恰恰相反。
我发现自己陷入了一条清晰的线索:原来GPT-4的多模态能力[1]来自于2021年CLIP的对比学习思路[2],CLIP又站在了2020年SimCLR[3]和MoCo[4]这些对比学习方法的肩膀上,而这些方法又根植于2017年Transformer的自注意力架构[5]……
每一个我在项目中遇到的困惑——"为什么这个任务模型做不好""为什么那个能力突然出现了""下一步模型会往哪个方向进化"——答案都藏在这些论文里,写得清清楚楚、明明白白。
我只是之前从来没有系统地读过。
做了十几年技术,创过业,做过产品,自认为对技术趋势有一定的判断力。但面对大模型,我发现过去的经验框架几乎全部失效。这玩意儿的进化速度、涌现方式和迭代逻辑,和以往任何一次技术浪潮都不一样。你不能靠"直觉"来判断,你得回到论文里去找第一性原理。
于是那个夏天,一个吃螃蟹的人决定暂时放下螃蟹,先把菜谱研究明白。
150篇论文教会我的事
从那个夏天开始,我开始系统性地阅读AI和大模型领域的论文与技术报告。最初只是为了解决手头项目的困惑,但越读越停不下来。一年多的时间里,我读了超过150篇论文和技术报告——从2012年引爆深度学习的AlexNet[6],到2017年改写一切的Transformer[5],到2022年让全世界震惊的ChatGPT背后的InstructGPT[7],再到2025年DeepSeek-R1用纯强化学习"涌现"出推理能力[8]。
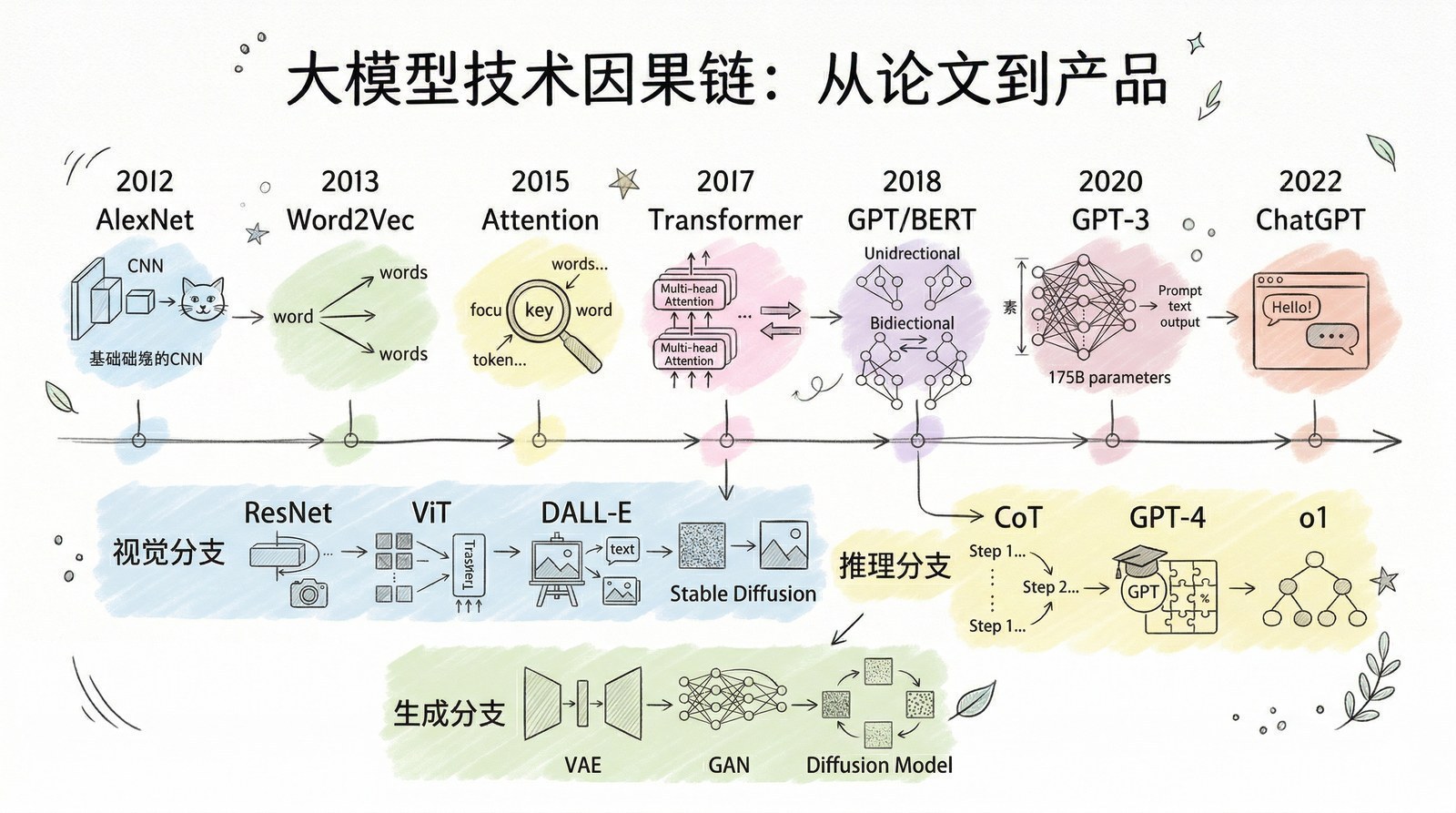
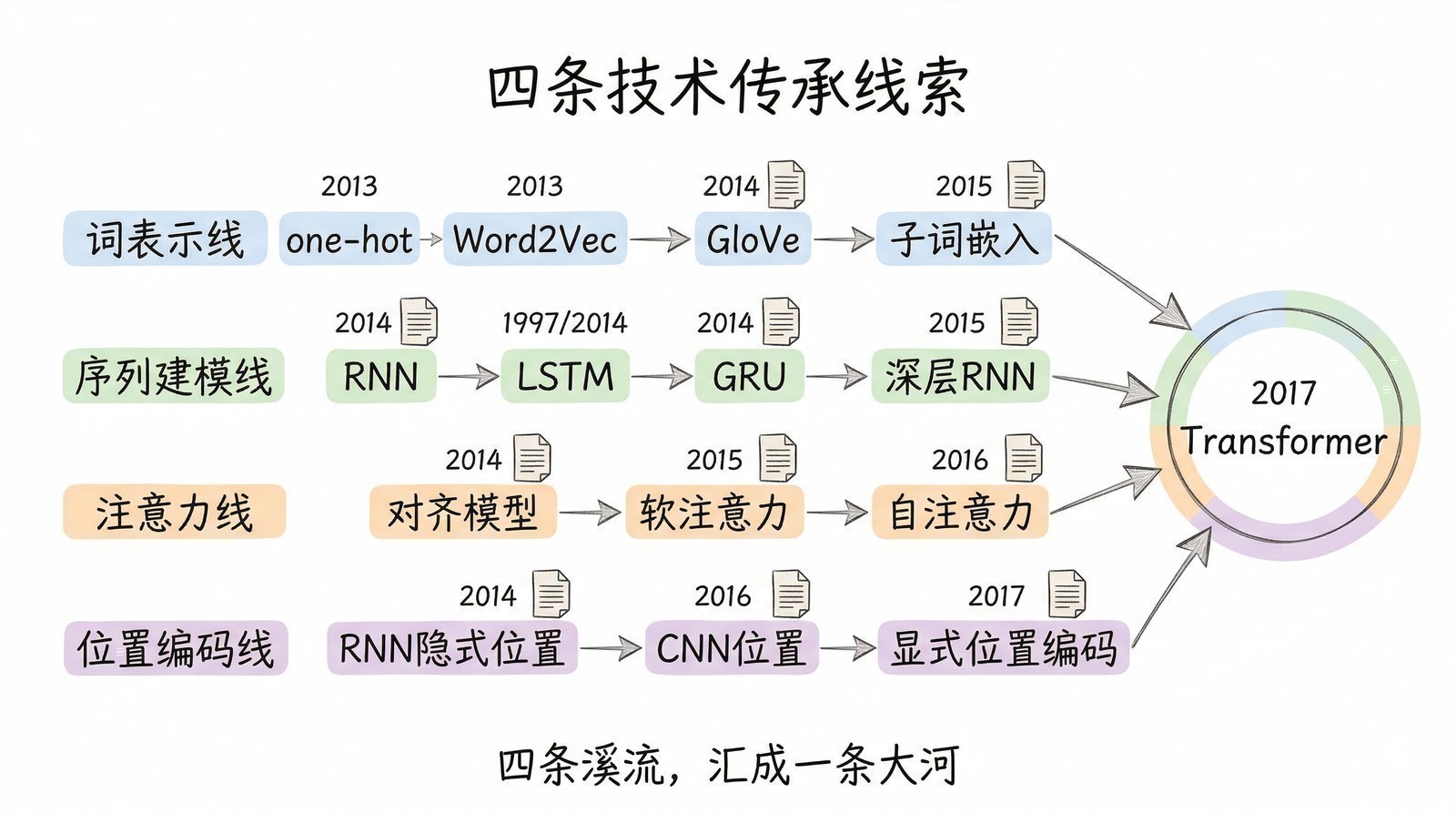
这150篇论文,在时间线上串起来,就是一部完整的"大模型进化史"。
让我说说它们教会了我什么。
第一件事:大模型的每一次跃迁都不是凭空出现的,它有精确的因果链条。
很多人觉得AI的发展是"突然爆发"的——2022年11月ChatGPT突然出现,好像一夜之间AI就无所不能了。但当你读完这些论文,你会发现ChatGPT的"一夜成名"背后是十年的积累:2012年AlexNet[6]证明深度学习可行 → 2017年Transformer[5]统一了模型架构 → 2018年GPT-1[9]证明"预测下一个词"是条好路 → 2020年GPT-3[10]证明规模出奇迹 → 2022年InstructGPT[7]用RLHF让模型"听话" → ChatGPT只不过是最后一块拼图落下的声音。
每一步都不可跳过,每一步都有论文记录。
第二件事:很多"做不到"的事,论文里已经告诉你什么时候能做到。
回到我那个凌晨两点的困惑。当我读完CLIP[2]、LLaVA、GPT-4V[1]这一系列多模态论文后,我明白了:2024年的大模型在"理解照片里的文字"这件事上已经相当不错了,但在"理解工程图纸上的精确标注"这件事上还差一大截。差距在哪里?在于训练数据中工程图纸太少、在于当前OCR模型对复杂版式的处理能力不够、在于多模态模型对表格结构的理解仍然脆弱。
这些不是我猜的。这些是论文里量化的benchmark数据告诉我的。
有了这些信息,决策就变得清晰了:核心的文本审核用大模型API,图纸识别的部分自研一个专用模块,表格提取用传统CV方案兜底。不需要赌,不需要等,也不需要焦虑。我们按照这个方案交付了项目,客户很满意。
但故事并没有结束。
大约一年后,2025年上半年,行业里突然密集发布了一批专攻文档理解的开源模型——DeepSeek发布了DeepSeek-OCR和OCR 2[11],百度持续迭代了PaddleOCR开源方案。这些模型在复杂表格还原、公式和数学符号识别、图片噪点过滤等方面有了质的飞跃。我在论文里读到的那些"还差一大截"的短板——一年后,开源社区用新的模型架构和训练数据把它们一个个补上了。
我们当初自研的那个"专用模块"?很快就被替换成了开源方案,效果更好,成本更低。
这个经历让我体会到了一种奇妙的节奏感:论文告诉你"现在做不到,瓶颈在哪里",然后行业的进化会告诉你"现在做到了,瓶颈被攻破了"。 你不需要预测未来,你只需要读懂当下的论文,就能在技术浪潮的节拍上踩准每一步——知道什么时候该自己造轮子,什么时候该等一等让行业替你把轮子造好。
这种感觉,就像是在看一本悬疑小说——论文是前面的伏笔,产品发布是后面的揭晓。只不过这个故事是真实发生的,而且还在不断续写。
第三件事:读懂了底层逻辑,焦虑就自然消退了。
过去两年,AI行业最不缺的就是焦虑。
每隔几周就有一个新模型发布,媒体不是说"颠覆"就是说"革命"。2023年3月GPT-4[1]发布,说要颠覆所有白领工作。2024年2月Sora[12]发布演示视频,说影视行业要完了。2025年1月DeepSeek-R1[8]发布,说推理能力已经赶上OpenAI了。2025年8月GPT-5[13]发布,说这是通向AGI的最后一步。
如果你只看新闻标题,你会觉得世界每三个月就要被彻底重塑一次。焦虑感铺天盖地。
但当你读完这150篇论文,你会获得一种完全不同的视角。你会看到:Sora[12]的视频生成能力本质上是DiT架构[14](2022年)在视频领域的扩展,而DiT又是Transformer[5](2017年)和Diffusion模型[15](2020年)的结合——它不是凭空出现的魔法,是两条已知技术线的交汇。你会看到:DeepSeek-R1[8]的"涌现推理"其实和2017年AlphaGo Zero[16]的"纯自我学习"是同一种哲学——用强化学习让模型自己探索,不依赖人类示范。你会看到:o1的"慢思考"能力其实在2022年Chain-of-Thought论文[17]里就已经埋下了伏笔——那篇论文发现只要让模型"说出思考过程",推理正确率就会大幅提升,两年后OpenAI把这个发现变成了一整个产品方向。
当你理解了底层逻辑和发展规律,就会发现大模型的优势和劣势、已经突破的难题和还没搞定的卡脖子问题,都是清清楚楚、了然于胸的。焦虑来自于不确定性,而论文提供的恰恰是确定性。
这大概就是"吃螃蟹"最大的收获——螃蟹扎了手不要紧,关键是你学会了怎么拆螃蟹。
我为什么要写这个系列
说到底是因为一种"不甘心"。
做了十几年技术和产品,从大厂到创业再到高校,我的职业主线一直是同一件事:把复杂的技术变成能解决实际问题的东西。 在大厂时是把架构方案翻译成产品方案,创业时是把前沿技术翻译成商业模式,在高校做科技成果转化时是把论文翻译成可落地的项目。
大模型时代,我发现这种"翻译"的需求比以往任何时候都更迫切。
过去两年的AI浪潮中,我接触了大量的从业者——产品经理、运营总监、创业者、投资人。他们聪明、勤奋、对AI充满热情,但在面对技术决策时常常感到无力。不是因为他们不够努力,而是因为他们和核心知识之间隔着一道"论文墙"。
这道墙有多高?
一篇典型的AI论文,20-50页的PDF,充满了数学公式、架构图、实验表格,用的是只有同行才能理解的专业术语。一个非CS背景的产品经理,就算有心去读,打开第一页看到"multi-head self-attention with scaled dot-product"大概率就会关掉。
但这篇论文真正想说的事情,可能只用一句话就能概括:"让模型在处理每个词的时候都能同时参考整段话中所有其他词的信息。"不需要公式,不需要代码,一个类比就够了。
问题是,谁来做这个"翻译"?
学术界的人不太愿意做,因为简化意味着不精确,不精确在学术界是一种"罪过"。媒体倒是愿意做,但往往简化过头——把所有新模型都写成"颠覆性突破",所有技术都标注为"里程碑",读者看完除了焦虑什么也没获得。而真正天天在项目里用大模型的人,又大多忙于交付,没有时间和精力去系统地梳理这些知识。
我觉得我恰好卡在一个合适的位置上。计算机科班出身,读论文不算太吃力;在行业里做了十几年,知道从业者真正关心的问题是什么;现在在高校做成果转化,本来就是干"把论文变成产品"这件事的。
于是,在各种AI工具的辅助下,我决定把自己读过的这150多篇论文和技术报告汇总起来,梳理成一条从2012年到2025年的大模型进化路线图。用最朴素的语言,把最复杂的技术演进讲清楚。
我给这个系列起了一个名字:智能涌现。
"涌现"是大模型领域一个很有意思的概念——当模型的规模达到某个临界点时,会突然展现出没有人设计过的新能力。GPT-3[10]突然学会了翻译,没有人教过它。DeepSeek-R1[8]突然学会了反思自己的错误,没有人编程让它这么做。这些能力不是被"设计"出来的,是从规模中"涌现"出来的。
我希望这个系列本身也能产生某种"涌现"——当足够多的论文、故事、数据和洞见被串联在一起时,读者能自发地形成一种看待AI发展的全局直觉。这种直觉不是任何单篇文章能给的,它只能从对全貌的理解中自然生长出来。
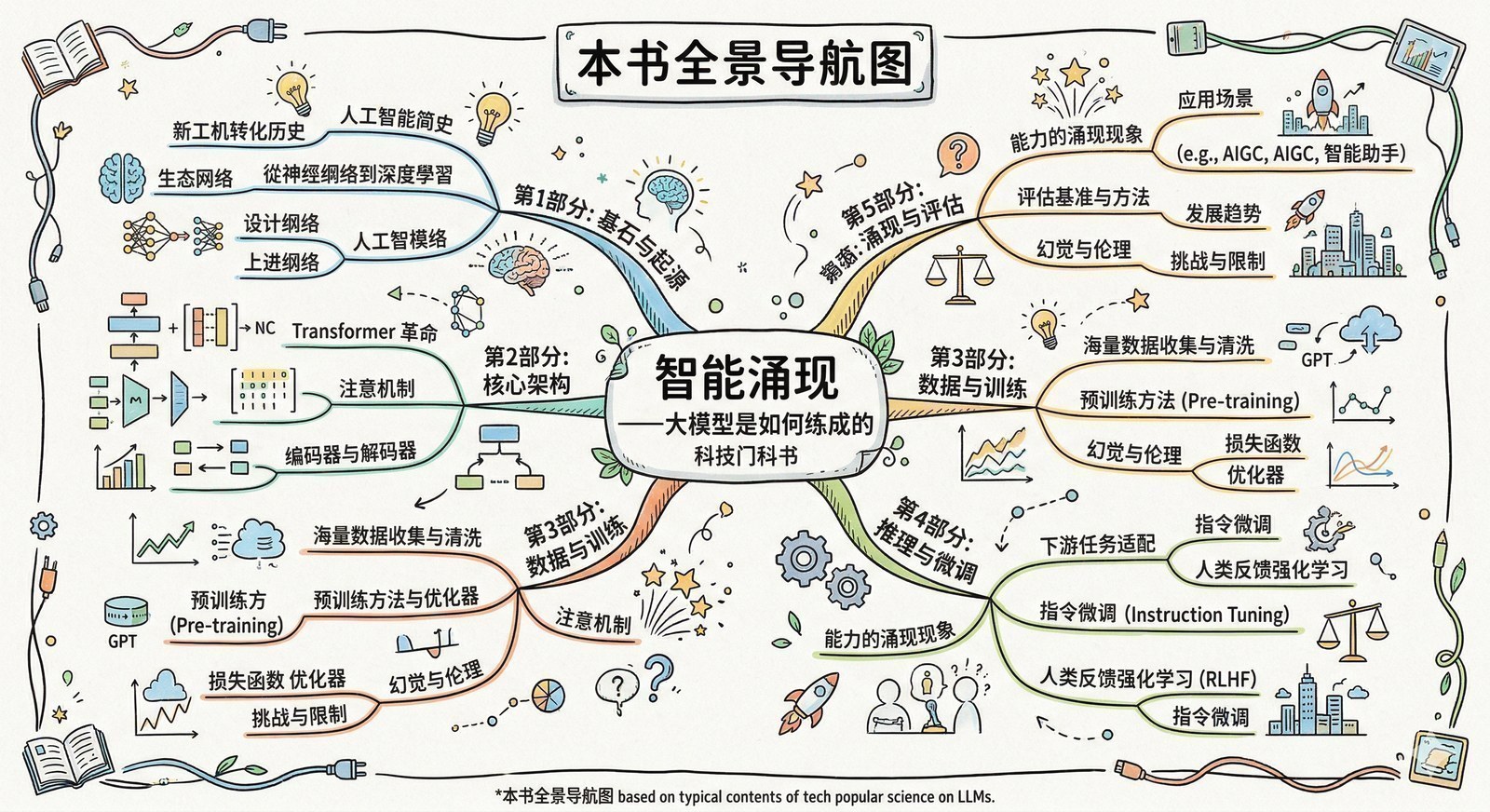
这个系列讲什么
一句话:大模型是怎么一步步"练成"今天这个样子的。
我会沿着时间线,用14个章节讲述大模型从萌芽到爆发的完整故事。每一章回答一个问题——"这个阶段,AI又能做什么以前做不到的新事情了?"
- AI是怎么学会"看图"的?(2012年的AlexNet[6],到今天特斯拉自动驾驶的视觉系统)
- AI是怎么学会"理解人话"的?(从2016年Google翻译的突然变好[18],到今天的实时同传)
- 为什么NVIDIA成了全世界最值钱的芯片公司?(从游戏显卡到H100一卡难求)
- 一篇论文是怎么改写整个AI历史的?(2017年的Transformer[5],今天所有大模型的基础)
- GPT和BERT[19]这两条路,为什么最终GPT赢了?(Google起了个大早赶了个晚集的故事)
- "模型越大越好"这件事背后的数学和工程是什么?(Scaling Law[20]、ZeRO[21]、万卡GPU集群[22])
- ChatGPT凭什么两个月破亿用户?(RLHF[7]让AI从"能力强"变成"好用"的关键一步)
- AI是怎么学会画画的?(CLIP[2]打通视觉和语言,Midjourney零融资做到5亿美元)
- 为什么2023年之后突然冒出来这么多大模型?(开源运动、效率革命、全球混战)
- AI是怎么从"快思考"进化到"慢思考"的?(从ChatGPT的直觉回答到o1/DeepSeek-R1[8]的深度推理)
- OpenAI用七年走了一条什么样的路?(GPT-1[9]到GPT-5[13]的完整编年史)
- DeepSeek用两年走了一条什么样的路?(17篇论文拼出的效率优先路线)
- 今天市面上几十个大模型,到底该怎么选?(一张开源大模型全景地图)
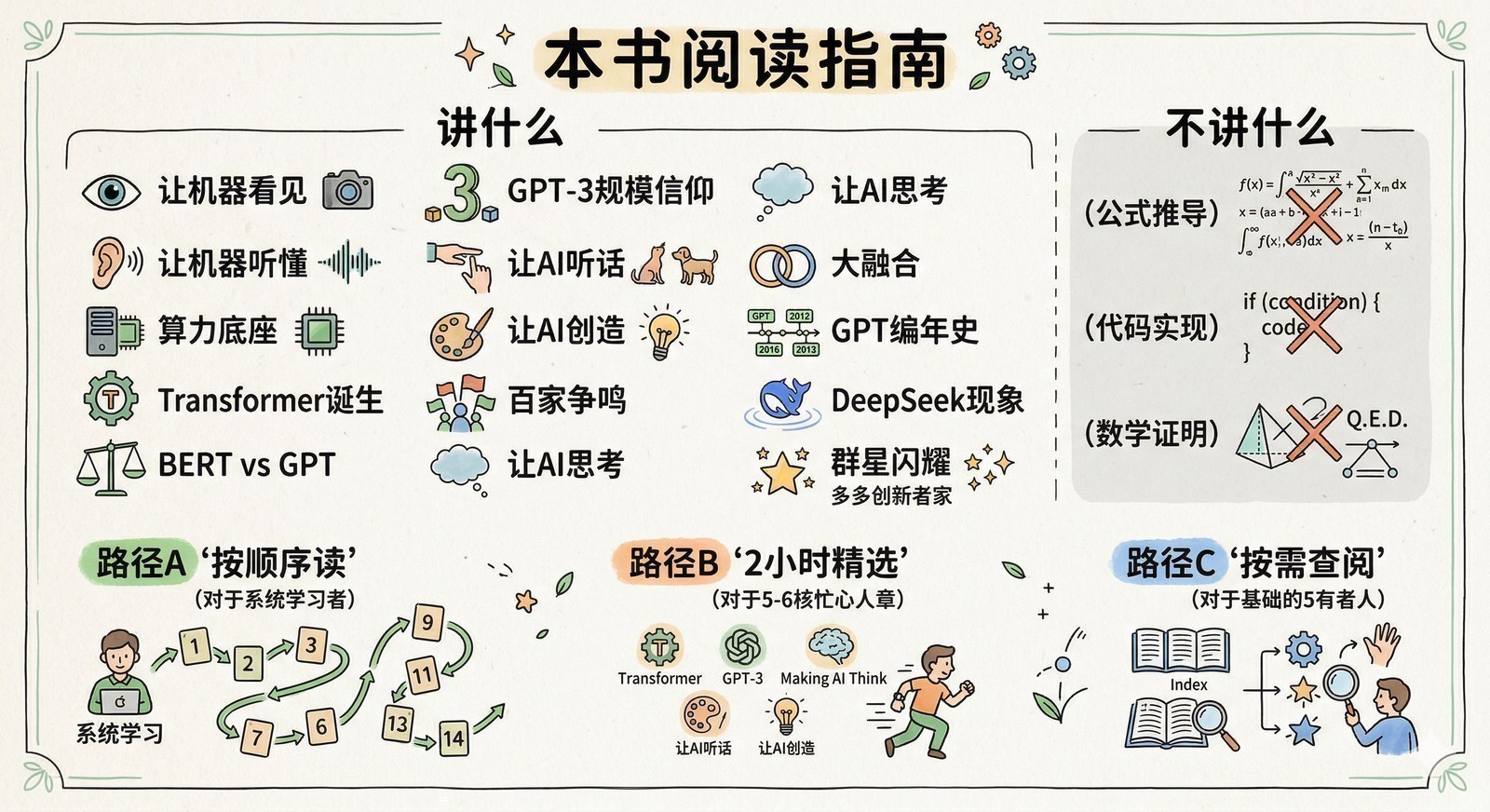
这个系列不讲什么
我想先管理一下预期。
不讲数学公式。 不会出现任何一行求导、矩阵运算或概率推导。每个技术概念都会用日常类比来解释。
不讲代码实现。 不会教你如何训练模型、如何调参数、如何部署。这些有大量优秀的技术教程,不需要我重复。
不做预测。 不会告诉你"AGI会在2027年到来"或者"某某公司会赢得AI竞赛"。我只呈现已经发生的事实和已被验证的规律,判断留给你自己。
不贩卖焦虑。 恰恰相反,我希望你读完这个系列后,焦虑能减少一些。因为当你看清了大模型的发展脉络,就会发现很多"颠覆性"新闻其实是技术演进的自然结果,既不需要恐慌,也不需要狂喜。
谁应该读这个系列
如果你符合以下任何一条,这个系列就是为你写的:
- 你用过ChatGPT、Claude或其他AI产品,觉得很厉害,但不太清楚"为什么厉害"和"还能厉害到什么程度"
- 你在工作中需要判断"这个需求能不能用AI做",但缺少技术直觉
- 你看到各种AI新闻感到兴奋又焦虑,想搞清楚哪些是真突破、哪些是炒作
- 你想理解OpenAI、DeepSeek、Meta、Google这些公司在做什么、为什么这么做
- 你是产品经理、运营、投资人、创业者,需要一个关于AI的"全局认知框架"
- 你想读论文但读不下去,需要一个"翻译者"
如果你是AI研究员或算法工程师,这个系列对你来说可能太浅了——你应该直接读原始论文。但如果你想找一份材料推荐给你的非技术同事,让他们快速理解你每天在做的事情,这个系列也许是个不错的选择。
一张地图
在正式开始之前,让我给你一张"地图",帮你建立全局感。
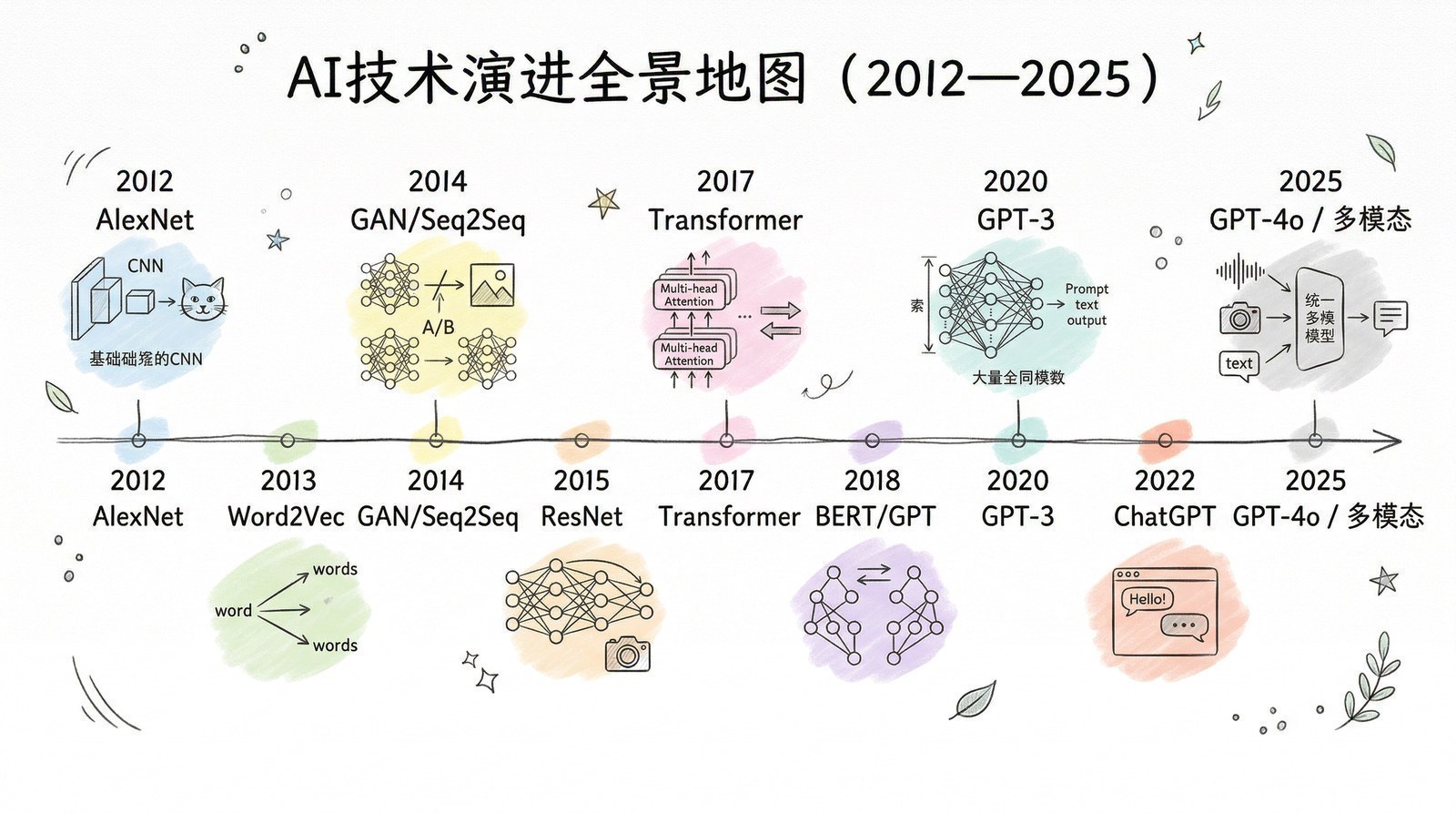
大模型从2012年到2025年的进化,可以浓缩成一条主线:
2012年——AI睁开眼睛,学会了看图,AlexNet[6]在ImageNet竞赛上碾压传统方法。
2015年——AI学会了"重点阅读",注意力机制[23]让模型能关注最重要的信息。
2017年——一篇论文统一了一切,Transformer[5]架构诞生,同年NVIDIA推出第一款AI专用芯片V100。
2018年——两条路线的分叉,Google的BERT[19]走"理解",OpenAI的GPT[9]走"生成"。
2020年——规模涌现奇迹,GPT-3[10]的1750亿参数证明:模型够大,能力自动涌现
2022年——AI学会听话,变成产品,InstructGPT[7] + RLHF → ChatGPT两月破亿。
2022年——从文字到画画,CLIP[2] + Diffusion[15] → Stable Diffusion / Midjourney / DALL-E 2引爆AI绘画。
2023年——百家争鸣,Meta开源Llama,Google发布Gemini,Anthropic推出Claude,全球AI竞争白热化。
2024年——AI从"快思考"进化到"慢思考",OpenAI o1让模型学会"想一想再回答"。
2025年——DeepSeek-R1[8]震动全球,GPT-5[13]统一快慢思考,开源模型追平闭源
这条线上的每一个节点,背后都有几篇到十几篇论文支撑。接下来的14章,我会带你一个节点一个节点地走过去。
怎么读这个系列
如果你时间充裕——按顺序从第一章读到终章。全书的叙事是连贯的,每一章的结尾都会自然引出下一章的问题。
如果你只有两小时——读第四章(Transformer)、第七章(ChatGPT)、第十章(快思考到慢思考)。这三章覆盖了大模型历史上最重要的三次跳跃。
如果你只关心当下和未来——直接跳到第十章(推理模型)、第十二章(GPT编年史)、第十三章(DeepSeek现象)、第十四章(全景地图)。
如果你只想解决工作中的具体问题——翻到第十四章的"开源vs闭源决策框架"和终章的"从业者行动指南"。
无论你从哪里开始,我希望读完之后,你能获得三样东西:
一条时间线——大模型是怎么一步步走到今天的,每一步的因果关系是什么。
一张地图——当下几十个模型和公司各自在做什么,你该怎么看这个格局。
一种直觉——下次看到AI新闻时,你能判断它在整个进化链条上处于什么位置,是真突破还是渐进改良。
好了,让我们开始吧。
当然,我个人的基座模型能力、推理能力、记忆能力、上下文能力都有限,虽然也用了很多AI工具来协助我校验本文提到的事实、技术、产品的准确性,但是难免有出错的地方,还请大家多包容和指正。
第一站:2012年。一个叫Alex Krizhevsky的博士生,用两块游戏显卡训练了一个神经网络,让整个世界重新相信——机器可以学会"看见"。
本章引用论文
| 编号 | 论文题目 | 年份 | 机构 |
|---|---|---|---|
| [1] | GPT-4 Technical Report | 2023 | OpenAI |
| [2] | CLIP: Learning Transferable Visual Models From Natural Language Supervision | 2021 | OpenAI |
| [3] | SimCLR: A Simple Framework for Contrastive Learning of Visual Representations | 2020 | |
| [4] | MoCo: Momentum Contrast for Unsupervised Visual Representation Learning | 2019 | FAIR (Meta) |
| [5] | Attention Is All You Need (Transformer) | 2017 | |
| [6] | ImageNet Classification with Deep Convolutional Neural Networks (AlexNet) | 2012 | Toronto |
| [7] | InstructGPT: Training Language Models to Follow Instructions with Human Feedback | 2022 | OpenAI |
| [8] | DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning | 2025 | DeepSeek |
| [9] | GPT-1: Improving Language Understanding by Generative Pre-Training | 2018 | OpenAI |
| [10] | GPT-3: Language Models are Few-Shot Learners | 2020 | OpenAI |
| [11] | DeepSeek-OCR: Contexts Optical Compression / DeepSeek-OCR 2: Visual Causal Flow | 2025 | DeepSeek |
| [12] | Sora: Video Generation Models as World Simulators | 2024 | OpenAI |
| [13] | GPT-5 System Card | 2025 | OpenAI |
| [14] | DiT: Scalable Diffusion Models with Transformers | 2022 | Meta/UC Berkeley |
| [15] | DDPM: Denoising Diffusion Probabilistic Models | 2020 | UC Berkeley |
| [16] | Mastering the Game of Go Without Human Knowledge (AlphaGo Zero) | 2017 | DeepMind |
| [17] | Chain-of-Thought Prompting Elicits Reasoning in Large Language Models | 2022 | |
| [18] | Google's Neural Machine Translation System (GNMT) | 2016 | |
| [19] | BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding | 2018 | |
| [20] | Scaling Laws for Neural Language Models | 2020 | OpenAI |
| [21] | ZeRO: Memory Optimizations Toward Training Trillion Parameter Models | 2019 | Microsoft |
| [22] | MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs | 2024 | ByteDance |
| [23] | Neural Machine Translation by Jointly Learning to Align and Translate (Bahdanau Attention) | 2015 | Montreal |
第一章:让机器"看见"——深度学习觉醒与计算机视觉的胜利
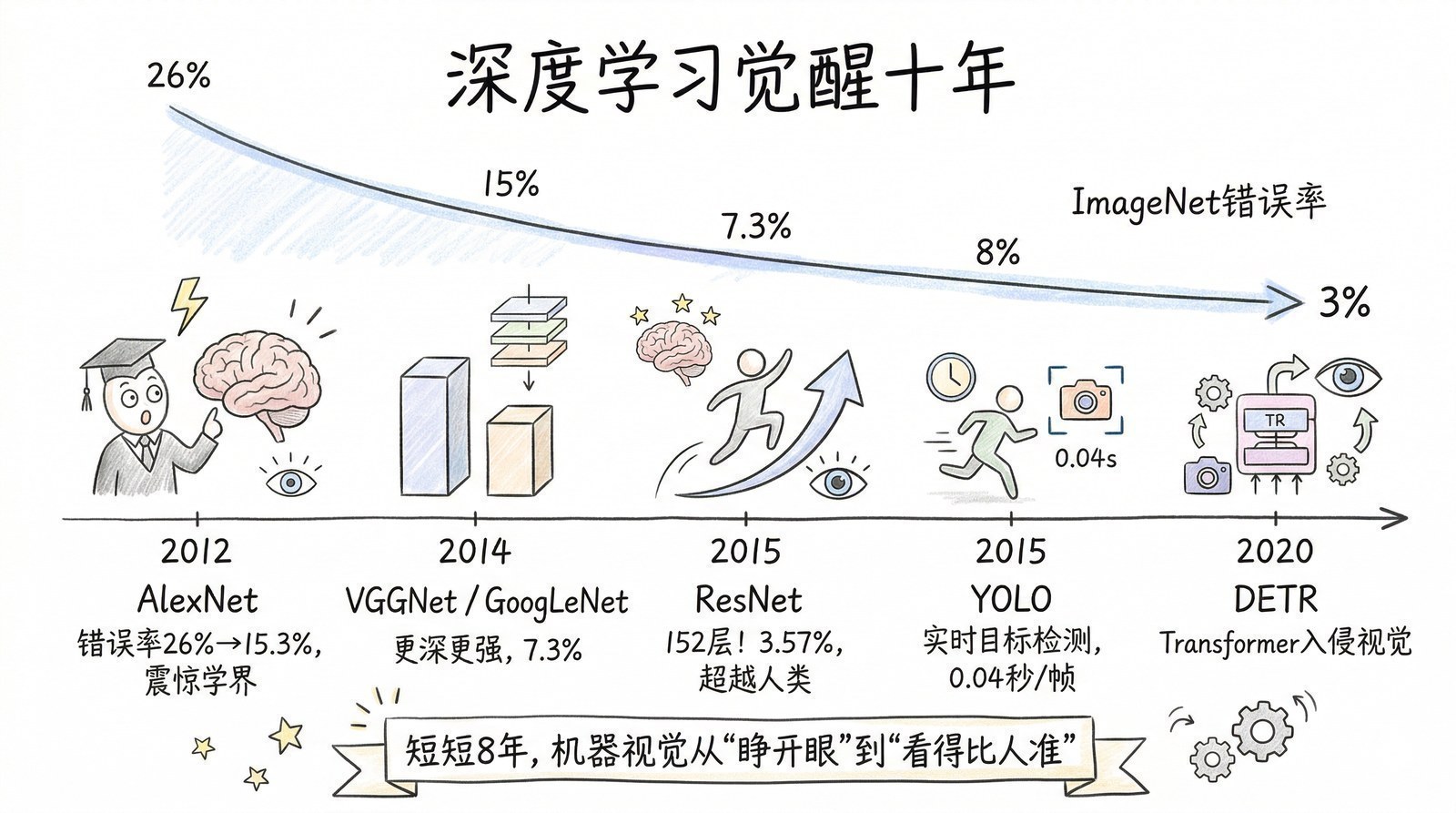
两块游戏显卡改变世界
2012年9月30日,加拿大多伦多大学的一个三人小组向ImageNet大规模视觉识别挑战赛(ILSVRC)提交了他们的参赛作品。
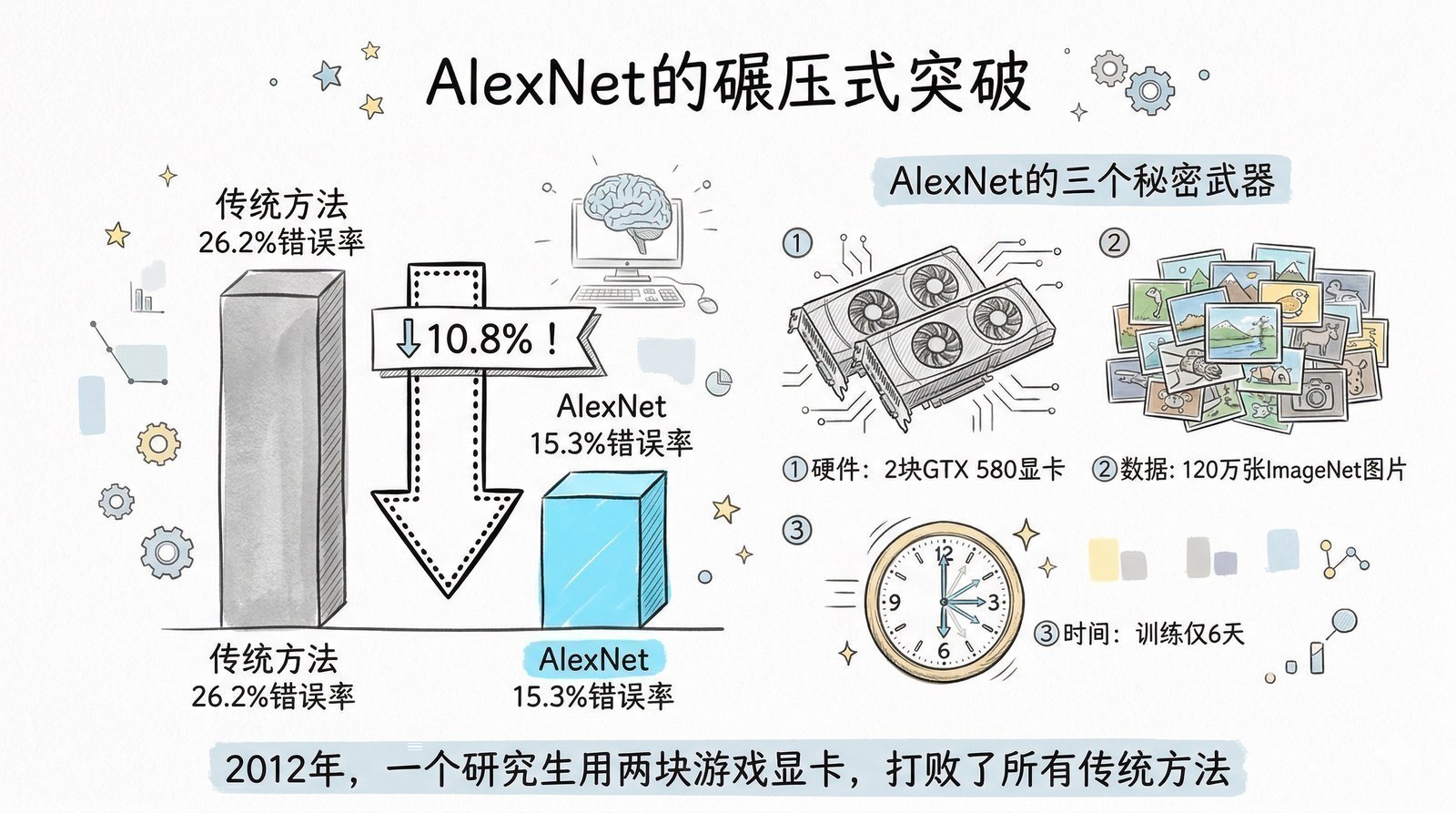
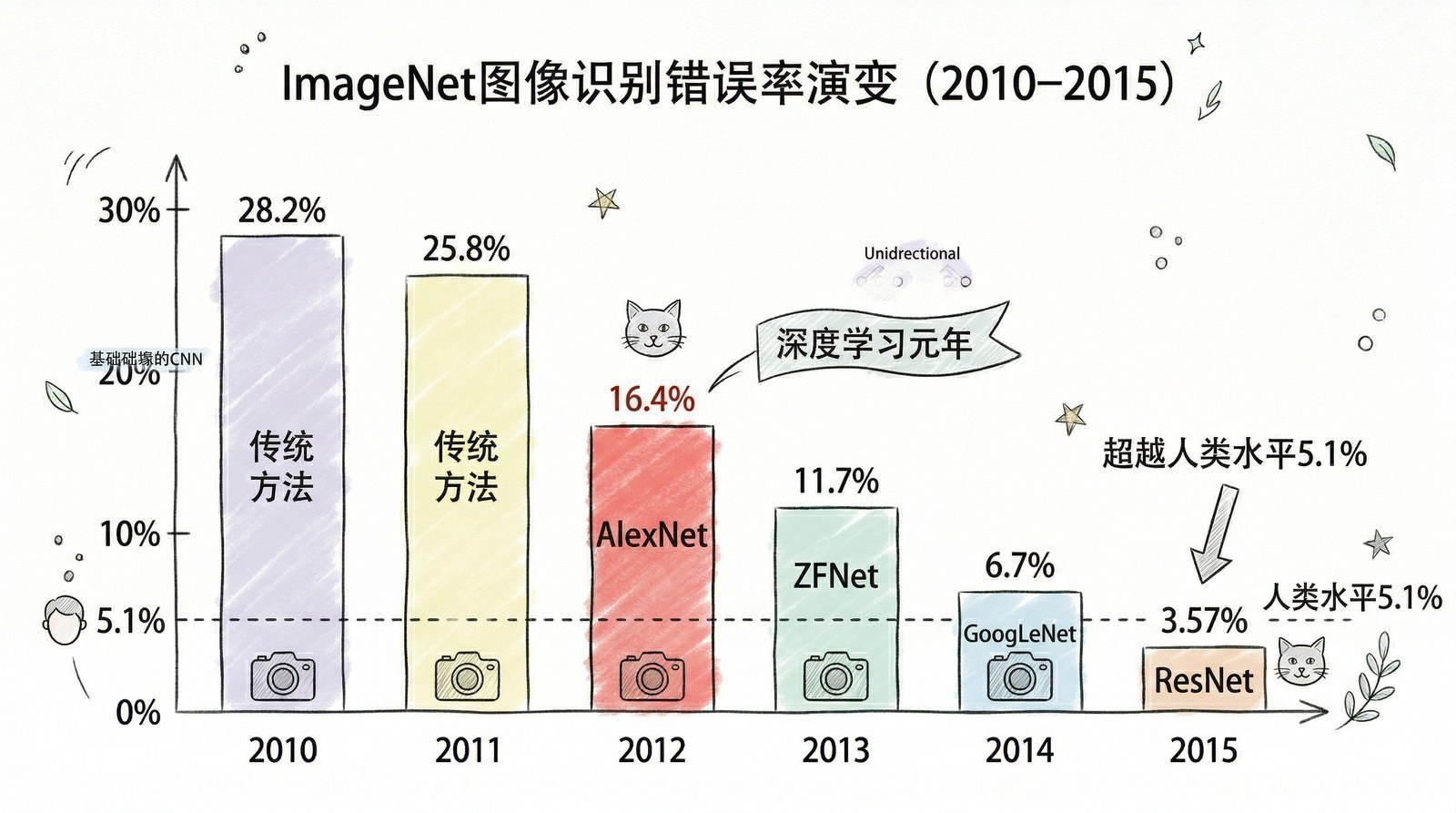
ImageNet竞赛的规则很简单:给计算机一张图片,让它猜这是什么东西——从"金鱼"到"火山"到"吉他",总共1000个类别。衡量标准是Top-5错误率——计算机可以猜5次,如果5次都没猜对,就算错。这是计算机视觉领域的"高考",全球最顶尖的团队每年都会参加。
在AlexNet[1]出现之前的2010年和2011年,参赛系统用的都是手工设计的特征提取器——研究者需要亲手编写算法来告诉计算机"边缘长什么样""纹理长什么样""颜色分布是什么",然后把这些特征喂给一个支持向量机(SVM)做分类。说白了,这种方法的核心是人的智慧,而不是机器的学习。两年来最好的成绩是Top-5错误率25%-26%——也就是说,每四张图片计算机就会彻底认错一张。
Alex Krizhevsky,一个乌克兰裔的加拿大博士生,和他的导师Geoffrey Hinton——后来被称为"深度学习教父"、2024年诺贝尔物理学奖得主——以及师兄Ilya Sutskever(后来成为OpenAI的联合创始人和首席科学家,2024年离开OpenAI创办了安全超级智能公司SSI),提交了一个完全不同的方案。
他们没有手工设计任何特征。而是搭了一个8层深的卷积神经网络——一种模拟人类视觉皮层结构的计算模型——然后让它在120万张标注图片上自己"学会"区分不同物体。
训练这个网络用的硬件是什么?不是什么超级计算机。是两块NVIDIA GTX 580——一款零售价不到500美元的游戏显卡。总显存加起来不到3GB。训练跑了大约6天。
结果出来的时候,所有人都震惊了。
AlexNet的Top-5错误率是15.3%,而第二名是26.2%。不是微弱优势,是碾压——足足低了10.8个百分点,超过了此前整个领域三年的进步幅度之和。
要知道,在学术竞赛中,哪怕0.5%的进步都值得发一篇论文。10.8个百分点的差距,几乎等于宣告:过去几十年,你们方向都走错了。
这个结果在计算机视觉学术界引发了一场地震。原本被视为"过时玩具"的神经网络,突然以令人无法反驳的方式证明了自己的价值。第二年的ImageNet竞赛,几乎所有参赛团队都改用了深度学习。
用今天的眼光看,AlexNet的架构简单得像一个课程作业——8层网络、几千万个参数、两块游戏显卡。放在2025年,这连一个手机上的AI模型都算不上。但正是这个朴素的网络,撕开了深度学习三十年冬眠的幕布,让整个世界重新相信——机器可以学会"看见"。
这篇论文后来成为机器学习历史上被引用最多的论文之一。而它的三位作者,也从此走上了截然不同的人生轨迹:Hinton获得了图灵奖和诺贝尔奖,成为AI时代最受尊敬的学者之一;Sutskever参与创建了OpenAI,主导了GPT系列的早期研发,塑造了今天大模型的基本形态;Krizhevsky短暂加入Google后逐渐淡出公众视野——但他点燃的那把火,至今还在燃烧。
AI的三十年冬眠与一个被忽视的真相
要理解2012年的震撼,需要先理解此前的沉寂。
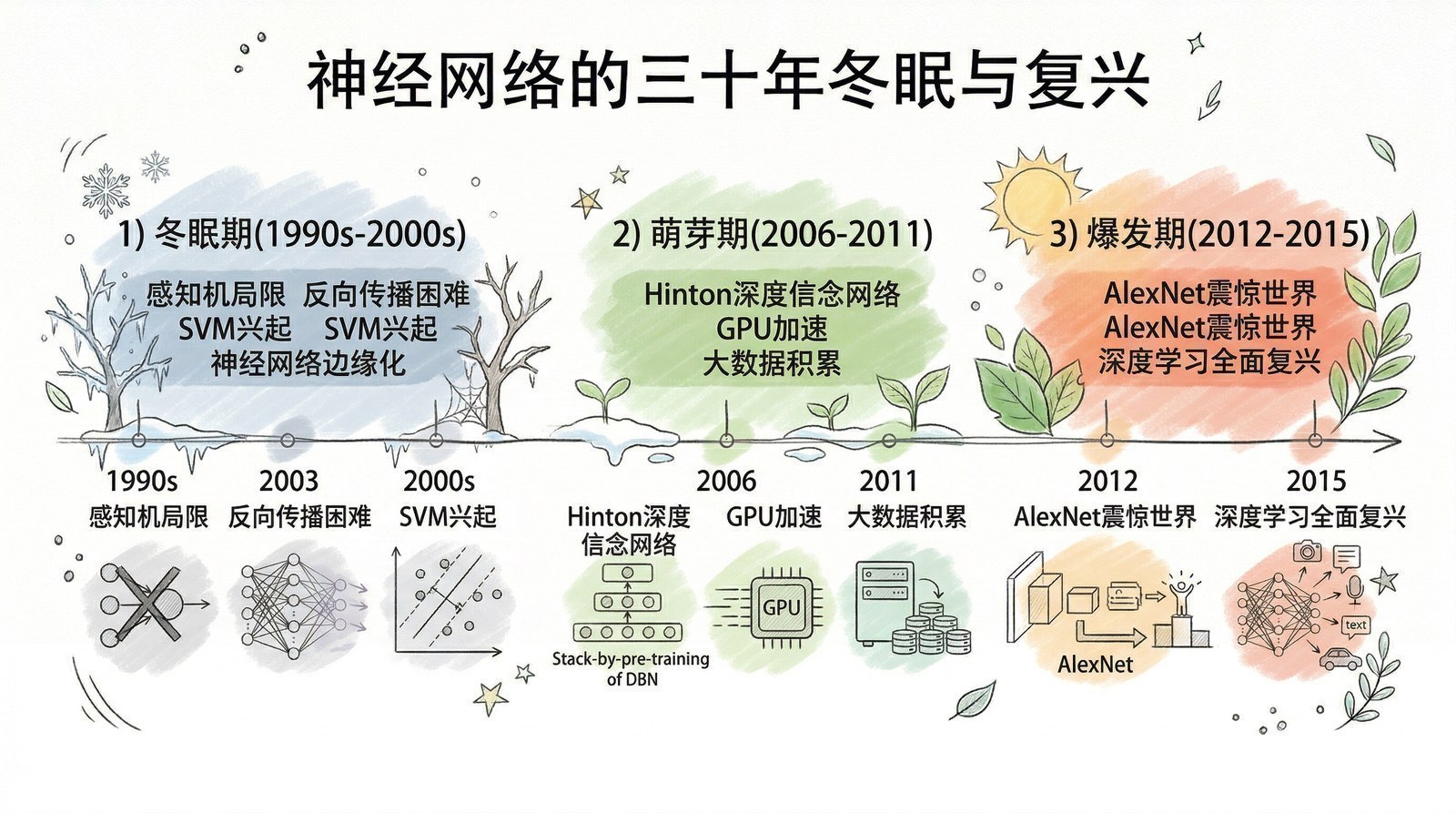
神经网络的想法最早可以追溯到1950年代。1989年,Yann LeCun在贝尔实验室用一个5层的卷积神经网络(LeNet)来识别手写支票上的数字,效果不错,被用于美国银行系统处理了数十亿美元的支票。但之后的二十多年里,神经网络几乎被整个学术界抛弃了。
原因有三个:
第一,算力不够。 训练一个稍微深一点的网络需要的计算量,在1990年代的CPU上要跑几个月甚至几年。没人等得起,也没人愿意为一个看起来"不靠谱"的方法投入这么多计算资源。
第二,数据不够。 LeNet能识别手写数字,只有10个类别,几万张图片。但真实世界有几万种物体,需要几百万甚至上千万张标注图片。这种规模的标注数据集在2000年代之前根本不存在——谁会花几年时间去给上千万张图片一张张打标签呢?
第三,"浅层"方法够用了。 支持向量机(SVM)、随机森林这些"传统"机器学习方法在小数据集上表现不差,而且有严格的数学理论支撑——你能证明它为什么有效。相比之下,神经网络像一个"黑箱"——效果不稳定,理论不清楚,训练困难,还容易过拟合。在"能解释"和"效果好"之间,学术界选择了前者。
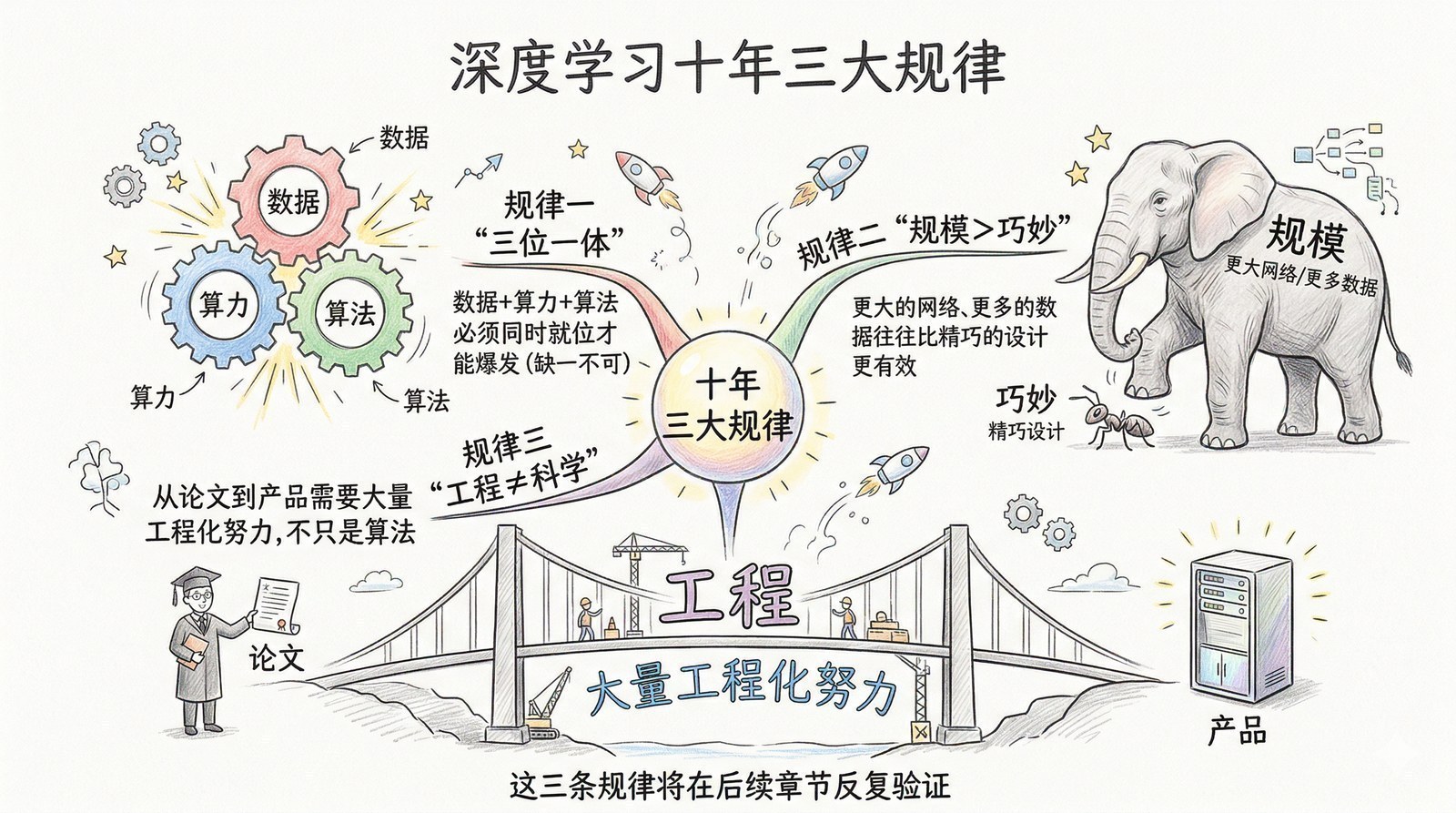
更深层的原因是,那个时代的研究者忽视了一个后来被证明至关重要的真相:算法的能力不是孤立存在的,它必须建立在数据规模和算力规模之上。 在小数据、弱算力的条件下,精巧设计的手工特征确实比粗糙的神经网络更好用。但这并不意味着神经网络"不行",只是说它的威力需要在更大的尺度上才能展现出来。
Richard Sutton——强化学习领域的先驱——在2019年写了一篇著名的短文《The Bitter Lesson》(苦涩的教训)[24],回顾了AI六十年的历史后得出一个尖锐的结论:每一次,那些试图依靠人类知识和精巧设计的方法,最终都会被"简单方法+大规模计算"所打败。 人类一次又一次地低估了"规模"的力量,一次又一次地高估了"巧妙"的价值。
这个洞见在2012年被AlexNet第一次验证:手工设计的特征提取器(巧妙+小规模)输给了粗糙的卷积神经网络(简单+大规模GPU计算+大规模数据)。八年后,它又在GPT-3身上被再次验证:精心设计的小模型输给了"暴力堆参数"的大模型。这条规律贯穿了本书的每一章。
AI不仅仅是算法。它是算法、数据、算力和系统的整体协同进化。 任何一个要素的缺失,都会让其他要素无法发挥作用。AlexNet的成功不是某一个突破的功劳,而是三个条件同时成熟的结果:
2004年:GPU可以做通用计算了。 Stanford大学的Ian Buck等人发表了Brook for GPUs[2],证明图形处理器可以做通用计算。两年后NVIDIA推出CUDA平台,让程序员可以用类似C语言的方式编写GPU程序。GPU原本是为了渲染游戏画面中的成千上万个像素而设计的——它天生擅长大规模并行计算。而神经网络的核心运算——矩阵乘法——恰好也是大规模并行的。这个巧合为后来的一切铺好了路。
2009年:ImageNet诞生。 斯坦福大学的李飞飞教授花了两年多时间,用亚马逊Mechanical Turk众包平台组织标注,建成了一个包含超过1400万张图片、涵盖2万多个类别的数据集。在一个大多数人还在用几千张图片做实验的年代,这个规模堪称疯狂。很多同行不理解:花这么大力气收集数据有什么意义?算法才是关键啊。但李飞飞坚信,数据的规模和多样性是AI进步的根本驱动力——而不是更精巧的算法。后来的历史证明她是对的。
2012年:三者同时就位。 GPU提供了算力,ImageNet提供了数据,更深的卷积网络结构提供了模型表达能力。AlexNet是第一个同时站在这三条腿上的系统。
从此,AI从冬眠中苏醒,而它睁开眼睛后做的第一件事,是学会"看见"。
从"看见"到"看懂":图像识别的飞跃
AlexNet打开了大门,但它只是开始。接下来三年,卷积神经网络(CNN)的深度和能力以每年一个台阶的速度飞速攀升。
2014年的VGGNet做到了19层,证明"更深的网络效果更好"这条直觉是正确的。但当研究者试图继续往深里做——50层、100层——的时候,遇到了一个诡异的问题:网络越深,反而越不准。 梯度信号在层层传递中"消失"了,深层根本学不到东西。这被称为"梯度消失"问题,一度被认为是深度网络不可逾越的障碍。
2015年:ResNet让网络可以"无限深"[3]
微软亚洲研究院的何恺明等人提出了一个极其优雅的解决方案:快捷连接(shortcut connection)——让每一层的输入可以"抄近道"直接传到后面,跳过中间的变换层。
这是什么意思?打个比方:假设你要把一句话从中文翻译成英文,传统的方式是每一层做一点变换,一层层传递下去。但到了第100层,原始信息可能已经面目全非了。快捷连接相当于给了信息一条"直通车"——原始输入可以直接跳到第100层,和中间层的输出相加。这样网络需要学习的就不是"从头构造输出",而只是"在原始输入的基础上做微调"——这个任务要简单得多。
听起来简单得难以置信——就是加一条"旁路"而已。但效果是革命性的。ResNet做到了152层,在ImageNet上的Top-5错误率降到了3.57%,第一次低于人类专家水平(约5%)。
这意味着,在"识别图片里是什么东西"这件事上,机器已经比人类更准了。整个过程——从AlexNet的15.3%到ResNet的3.57%——只用了三年。
何恺明后来加入Meta(Facebook)AI研究院,成为当今计算机视觉领域最有影响力的研究者之一。他参与的后续工作——Mask R-CNN[13]、ResNeXt、Feature Pyramid Network——直接塑造了目标检测和实例分割的技术版图。
优化算法:深度学习的幕后英雄
模型架构的进步是台前的明星,但幕后还有一群同样重要的角色——优化算法。没有好的优化算法,再精妙的网络也训练不起来。
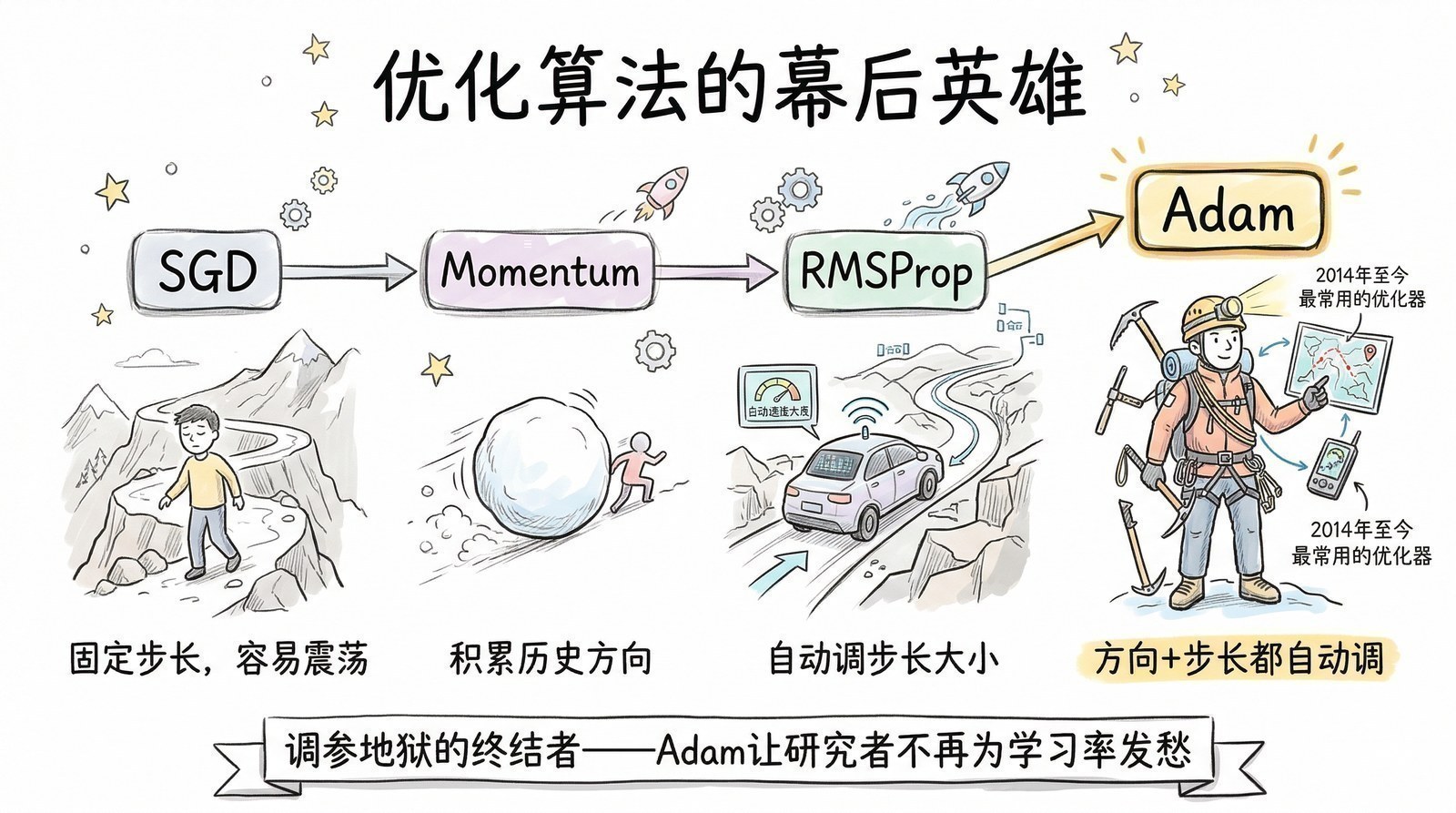
Adam优化器(2014)[4]
2014年,Diederik Kingma和Jimmy Ba提出了Adam(Adaptive Moment Estimation)优化器。在Adam之前,训练神经网络是一件非常需要"手感"的事——学习率设大了,训练会发散;设小了,收敛慢得令人绝望。Adam的核心想法是让学习率自适应调整:对于梯度大的参数,学习率自动缩小;对于梯度小的参数,学习率自动放大。
这听起来是个技术细节,但它的影响是深远的。Adam让神经网络的训练变得更稳定、更不容易失败,大幅降低了"调参"的门槛。至今,它仍然是最广泛使用的优化器之一——几乎所有你今天用的AI模型,从ChatGPT到Stable Diffusion,训练时大概率用的就是Adam或它的变体。
泛化之谜(2016)[25]
2016年,Chiyuan Zhang等人发表了一篇引发广泛讨论的论文《Understanding Deep Learning Requires Rethinking Generalization》[25]。他们做了一个惊人的实验:把ImageNet的标签完全随机打乱(猫的图片标记为"飞机",狗的图片标记为"火山"),然后用深度网络去训练。结果网络居然能完美地"记住"所有的错误标签——训练准确率达到100%。
这说明深度网络的记忆能力远超我们的想象,它强大到可以死记硬背一百万张完全没有规律的图片。那问题来了:既然网络有能力记住所有训练数据,为什么它在真实测试中还能表现得那么好? 它是真的"学会"了识别物体,还是只是在"背答案"?
这个问题至今没有完全解答,但它揭示了深度学习最深层的奥秘之一——这些网络的工作方式,可能比我们以为的更加复杂和微妙。
不只是认出来,还要找到它:目标检测的进化
识别一张只有"一只猫"的图片是一回事。但真实世界的图片里往往有很多物体——一条街上有行人、汽车、交通灯、商店招牌、路面标线。AI不仅需要知道"图里有什么",还需要知道"它们分别在哪里",并且用方框精确地标出每个物体的位置。这就是目标检测要解决的问题。
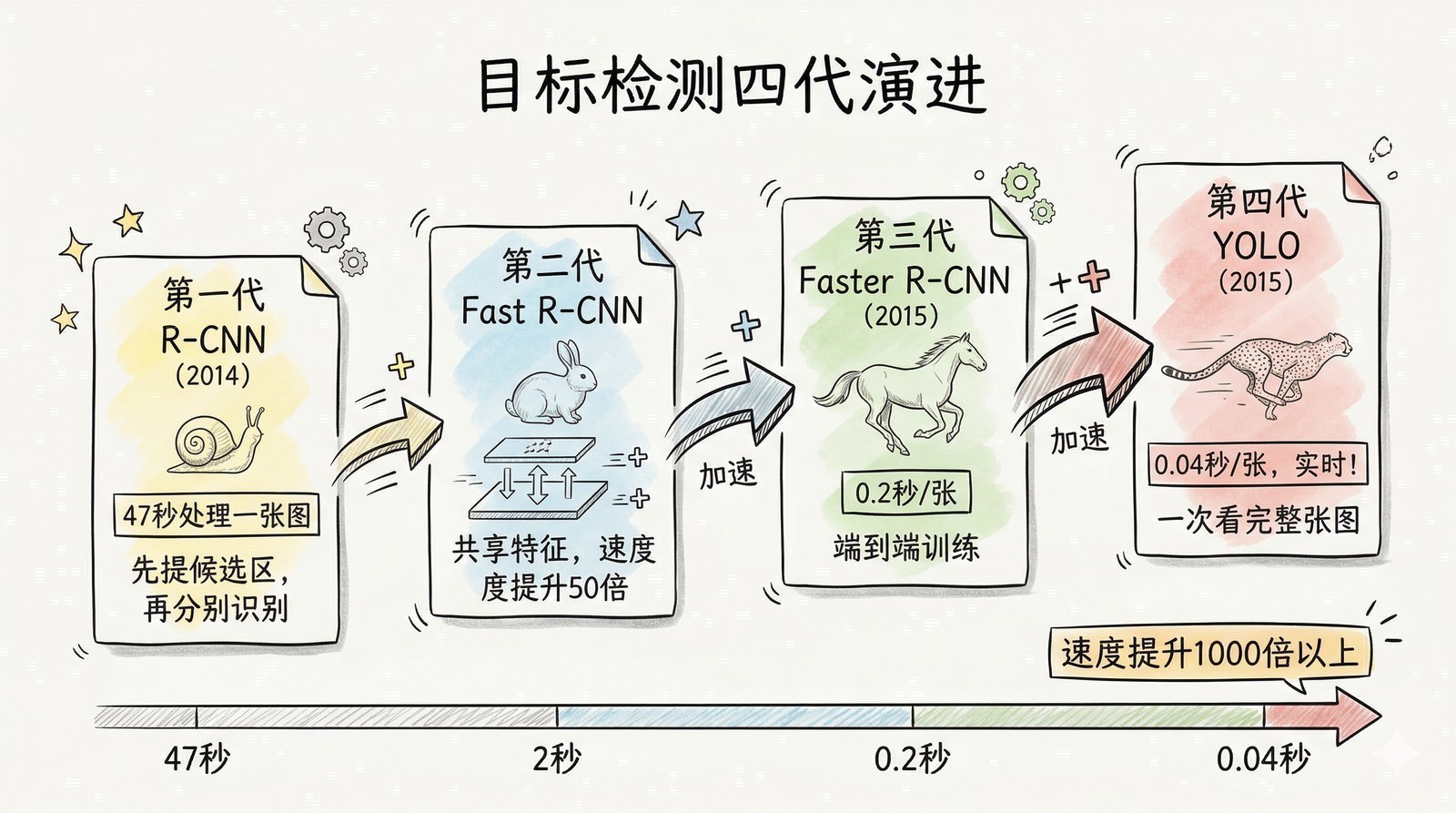
目标检测的进化是一条特别清晰的技术迭代链。它直接支撑了2015-2020年以国内"AI四小龙"为代表的整个计算机视觉产业链——人脸识别、车牌识别、安防监控、自动驾驶感知,底层都是目标检测技术。可以说,这条技术链是深度学习时代AI商业化的第一条"主干道"。
2014年:R-CNN——第一次用深度学习做检测[6]
UC Berkeley的Ross Girshick提出R-CNN(Regions with Convolutional Neural Networks),思路分三步:首先用一个传统算法(Selective Search)在图片上"猜"出大约2000个可能包含物体的候选区域;然后把每个区域逐一送进CNN提取特征;最后用SVM分类器判断每个区域是什么物体。
R-CNN的效果相比传统方法有巨大提升,在PASCAL VOC数据集上的检测精度从33%跳到了58%。但它有一个致命的问题:太慢了。每张图片要生成2000个候选区域,每个区域都要独立跑一次CNN——处理一张图片需要47秒。在学术论文里可以接受,但在任何实际应用场景中完全不可用——你总不能让安防摄像头每47秒才能分析一帧画面。
2015年:Fast R-CNN——共享计算,快了百倍[7]
仅仅一年后,Girshick自己改进了R-CNN。他发现R-CNN最大的浪费在于:2000个候选区域,每个都要独立跑一次CNN,但其实大部分计算是重复的——因为这些区域都来自同一张图片。Fast R-CNN[7]的改进很简单但非常有效:先对整张图片跑一次CNN提取特征图,然后从特征图上"裁剪"出每个候选区域对应的部分。这样2000次CNN前向传播变成了1次,速度提升了几十倍。
2015年:Faster R-CNN——端到端,速度再翻倍[8]
Fast R-CNN还有一个瓶颈:候选区域的生成仍然依赖传统的Selective Search算法,这一步本身就很慢。任少卿、何恺明、Ross Girshick和孙剑提出Faster R-CNN[8],核心创新是用一个小型神经网络(Region Proposal Network, RPN)来替代传统候选区域生成算法——让网络自己学习"哪里可能有物体"。
RPN和检测网络共享同一个CNN的特征,整个系统实现了真正的端到端训练——从原始图片输入到检测结果输出,中间没有任何非神经网络的步骤。处理速度达到了每秒5帧(每张图约0.2秒),精度也更高。
Faster R-CNN成为目标检测领域的"标准答案",在之后两三年里统治了各大检测基准测试。直到今天,它的"区域提议+分类"两阶段框架仍然是很多检测系统的基础。
2016年:YOLO——"你只需要看一次"[9]
就在Faster R-CNN成为学术界的宠儿时,Joseph Redmon——一个充满个性的华盛顿大学研究者——提出了一个截然不同且更加激进的想法:能不能跳过"找候选区域"这一步,一步搞定?
YOLO(You Only Look Once)[9]把整张图片分成一个S×S的网格(比如7×7=49个格子),每个格子直接预测"这里是否有物体、物体是什么、物体的精确边框在哪"。整个检测过程就是一次神经网络的前向传播——看一次就够了,所以叫"You Only Look Once"。
YOLO的速度达到了每秒45帧——是Faster R-CNN的9倍,是最初R-CNN的千倍以上。虽然精度略低于Faster R-CNN(尤其是在检测小物体时),但它是第一个达到实时性能的深度学习检测器。这意味着,目标检测终于可以用在视频流上了——安防监控、自动驾驶、无人机避障,所有需要"实时看"的场景,都因为YOLO的出现而成为可能。
同年,Wei Liu等人提出SSD(Single Shot MultiBox Detector)[10],用另一种方式实现了单阶段检测。SSD在图片的不同尺度上同时检测物体,在精度和速度之间取得了更好的平衡。
2017-2019年:YOLO家族的持续进化
Joseph Redmon没有停下来。YOLOv2[11](2017年)引入了批归一化、锚框机制和多尺度训练,在保持速度优势的同时大幅提升了精度。YOLOv3[12](2018年)采用了多尺度预测——在三个不同分辨率的特征图上同时检测,让小物体的检测精度有了明显提升。
与此同时,何恺明团队的Mask R-CNN[13](2017年)在Faster R-CNN基础上增加了一个分支,实现了像素级别的实例分割——不仅找到物体在哪里,还能精确画出它的轮廓。这项技术后来被广泛用于自动驾驶中的场景理解和医学影像中的病灶标注。
CenterNet[14](2019年)则提出了更优雅的无锚框方法——把物体检测简化为"找物体中心点",去掉了锚框这个需要人工调参的组件,让检测器的设计更加简洁。
2020年:DETR——Transformer入侵视觉[15]
2020年,Meta AI的Nicolas Carion等人做了一件让很多人意想不到的事:用Transformer(本书第四章的主角)来做目标检测。DETR[15]去掉了所有手工设计的组件——锚框、非极大值抑制(NMS)后处理——用一个纯粹的编码器-解码器结构,端到端地预测物体。
DETR在大物体检测上效果出色,但在小物体上还有不足。更重要的是,它标志着一个深远的趋势:Transformer正在从NLP领域入侵计算机视觉。这条线将在后续章节中不断延伸——先是ViT用Transformer做图像分类(第六章),然后是CLIP用Transformer打通视觉和语言(第八章),最终走向今天的多模态大模型。
这条进化链的产业意义
R-CNN → Faster R-CNN → YOLO → Mask R-CNN → DETR,这条目标检测的技术进化链不是学术游戏。它直接支撑了2015-2020年以深度学习为核心的第一波AI商业化浪潮:
- 安防监控:实时检测行人、车辆、异常行为。海康威视、大华股份等公司将YOLO类算法嵌入摄像头芯片,让"智能监控"成为城市基础设施
- 自动驾驶:车辆需要以毫秒级速度识别行人、车辆、交通标志和车道线。Tesla的纯视觉方案本质上就是YOLO思路的延伸
- 人脸识别:从手机解锁到支付验证到安检通关,底层都是"先检测人脸位置,再识别是谁"的两步流程
- 零售自动化:Amazon Go无人商店用摄像头+目标检测跟踪每个顾客拿了什么商品
- 工业质检:在流水线上用视觉检测产品缺陷——划痕、裂纹、错位——替代人工目检
可以说,2015-2020年整个"深度学习+计算机视觉"的产业链——国内的AI四小龙(商汤、旷视、云从、依图)、安防巨头(海康威视、大华)、自动驾驶公司(百度Apollo、小鹏、蔚来)——它们的核心技术根基,都建立在这条目标检测进化链之上。
而从2020年开始,随着GPT-3和ChatGPT的出现,AI产业的主轴逐渐从"以计算机视觉为核心"转向了"以大语言模型为核心"。但视觉并没有被淘汰——它通过CLIP、GPT-4V等多模态技术,融入了大模型体系,成为了更大故事的一部分。这条融合之路,我们将在第八章(打通视觉与语言)中详细讲述。
让AI理解运动:视频理解的挑战
图片是静止的一帧。但真实世界是动态的——人在走路、球在飞、车在拐弯。理解视频比理解图片难得多,因为你不仅要理解每一帧"有什么",还要理解帧与帧之间"发生了什么"。一个人举起手臂——他是在打招呼、投篮还是要打人?单看一帧你可能分辨不出来,必须看前后几帧的动作序列才能判断。
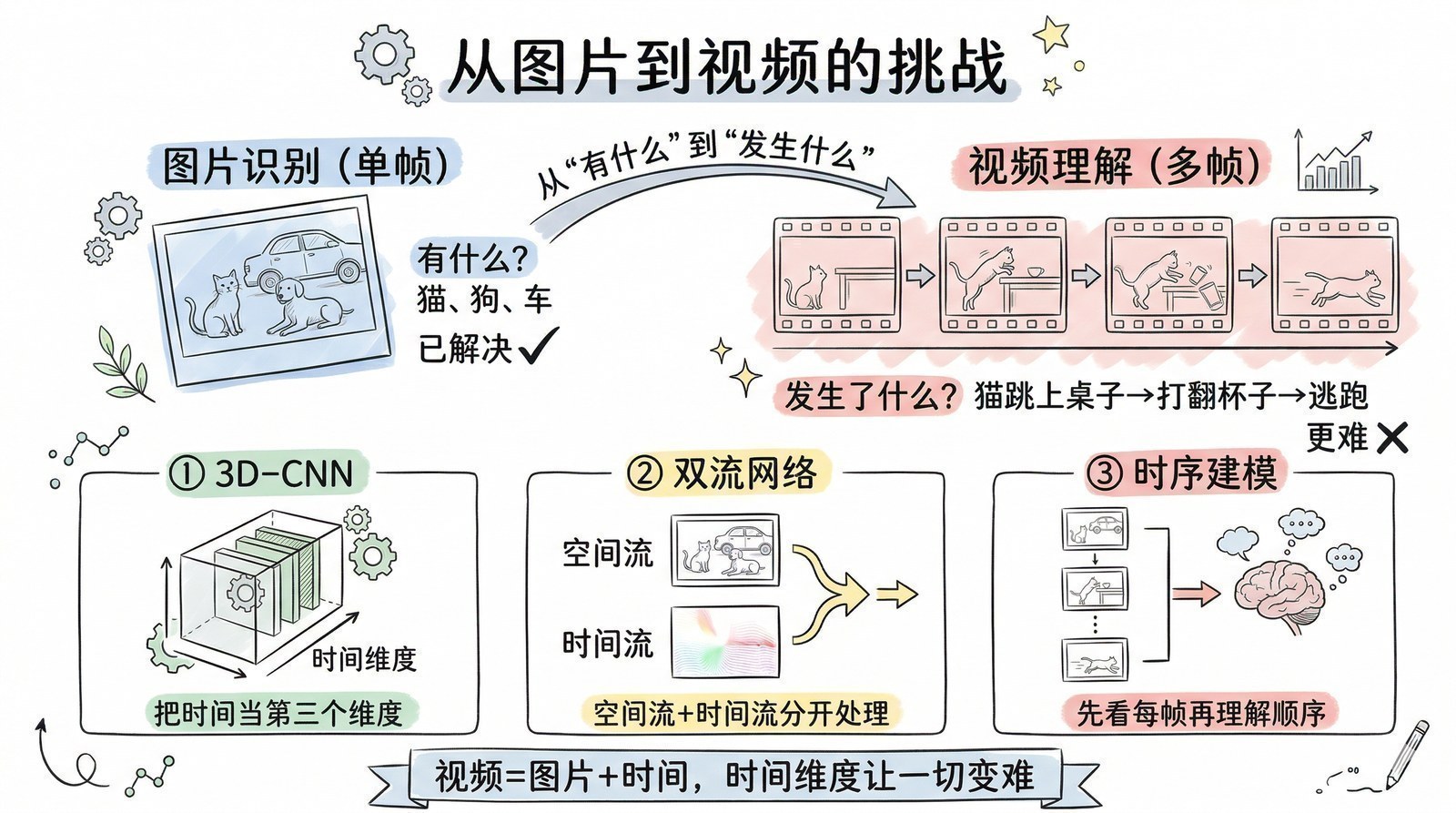
这就是视频理解要解决的问题。它的技术迭代路径清晰地展示了研究者如何一步步攻克"时间维度"这个难题。
2014年:双流网络——分开看"样子"和"动作"[16]
Karen Simonyan和Andrew Zisserman(牛津大学,VGGNet的作者)提出了一个巧妙的架构:Two-Stream Network[16]。核心洞见来自神经科学——人类视觉系统有两条独立的通路:腹侧通路处理"这是什么"(物体形状、颜色),背侧通路处理"它怎么动的"(运动方向、速度)。
双流网络模拟了这个结构:一个"空间流"CNN处理单帧RGB图像(看画面长什么样),一个"时间流"CNN处理光流图(看东西怎么动的),最后把两个流的结果融合。光流是一种描述像素运动方向和速度的表示方法——如果一个人向右走,他所在的像素点都会有一个向右的光流向量。
同期还有其他尝试:C3D[17]用3D卷积核直接在时间和空间维度上同时提取特征,相当于把2D的图像卷积"膨胀"到3D的视频卷积;DeepVideo[18]则由Stanford和Google合作探索了如何将CNN应用于大规模视频分类(Sports-1M数据集,100万个视频)。
2016年:TSN——把长视频"切片"采样[19]
视频可能有几分钟长,但受限于GPU显存,模型一次只能处理几秒钟。如何让模型"看到"整个视频?TSN(Temporal Segment Networks)[19]的解决方案简单而有效:把视频均匀切成若干段,从每段中随机抽一帧来处理,然后把所有段的结果汇总(取平均或投票)。
这个方法的哲学是:一段视频的关键信息分布在整个时间线上,不需要逐帧分析,只需要在每个时间段上"采一个样"就够了。TSN成为视频理解领域的标准基线方法,后续很多工作都在它的框架上改进。
2017年:I3D和R(2+1)D——Inflate和分解[20][21]
来自DeepMind的Joao Carreira和Andrew Zisserman提出I3D(Inflated 3D ConvNet)[20],做了一件巧妙的事:把已经在ImageNet上预训练好的2D卷积核"膨胀"成3D卷积核——相当于给一个学会了看图片的模型,加上一个时间维度,让它带着已有的图像知识去理解视频。同时他们发布了Kinetics数据集(包含40万个视频片段,涵盖400种人类动作),成为视频理解的"ImageNet"。
同年,Meta的Du Tran等人提出R(2+1)D[21],发现把3D卷积分解为2D空间卷积+1D时间卷积,效果反而更好——因为这种分解让网络先学空间特征再学时间特征,优化更容易,而且参数量更少。
2018年:SlowFast——快慢双通道[22]
Meta的何恺明团队提出SlowFast Network[22],灵感同样来自人类视觉系统——视网膜上有两种细胞:约80%的细胞(P细胞)响应缓慢但对空间细节敏感,约20%的细胞(M细胞)响应快速但只关注运动。
SlowFast用两个分支模拟这两种通路:一个"慢路径"以低帧率(如每秒2帧)处理高分辨率的空间信息;一个"快路径"以高帧率(如每秒16帧)处理低分辨率的运动信息。快路径的计算量很小(因为通道数少),但能捕获关键的运动模式。两条路径的特征在多个层级上融合,在视频动作识别上取得了当时最佳效果。
2021年:TimeSformer——Transformer统一视频理解[23]
和DETR对目标检测做的事一样,Meta AI的Gedas Bertasius等人将Transformer引入了视频理解。TimeSformer[23]把视频拆成一系列时空patch(比如把每一帧切成16×16的小块,再沿时间串起来),然后用自注意力机制让每个patch能"看到"视频中任意位置、任意时间点的其他patch。
这种"全局注意力"意味着模型不再受限于局部卷积的"视野"——它可以直接关联视频开头和结尾的信息。TimeSformer再次证明了Transformer架构的通用性:处理文字能行,处理图片能行,处理视频也能行。
视频理解的产业落地
视频理解技术已经渗透到了很多你可能没有意识到的场景中:
- 短视频推荐:抖音/TikTok需要"理解"每个视频的内容(是美食、舞蹈还是搞笑),才能做精准推荐。视频理解模型帮助平台从每天上传的千万条视频中自动打标签、分类和过滤违规内容
- 体育赛事分析:自动识别进球、犯规、精彩回放。NBA和英超联赛已经在使用AI自动剪辑集锦、追踪球员跑位数据
- 安防视频分析:从数千小时的监控视频中自动找出异常行为(翻越围栏、逆行、聚集),不再需要人盯着屏幕看。海康威视的"深眸"系列摄像头内置了视频分析AI
- 工业质检:在流水线视频中实时检测产品缺陷。华为的机器视觉解决方案"好望"(HoloSens)被应用于多条制造业产线
- 医学影像分析:分析超声视频中的心脏运动、内窥镜视频中的息肉检测,辅助医生诊断
产品与公司聚光灯:AI技术大开大合,AI产品润物细无声
计算机视觉的十年进化催生了一批改变世界的产品。有意思的是,AI技术本身的发展是大开大合的——每年一篇重磅论文、每次竞赛刷新记录、媒体争相报道。但AI产品对日常生活的渗透,却是悄然无息的。
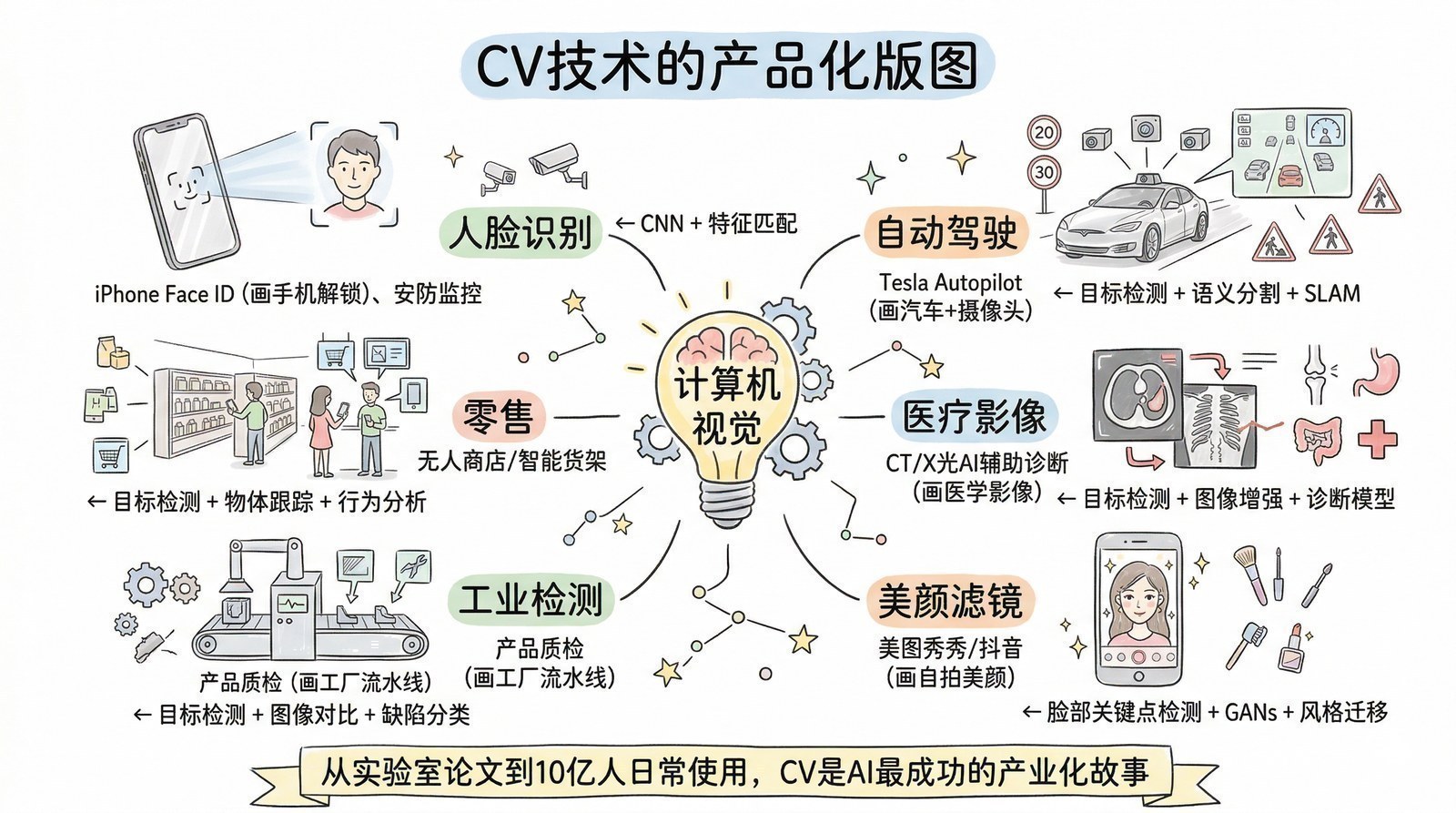
回想一下:你是从什么时候开始用人脸解锁手机的?什么时候开始刷脸过地铁闸机的?什么时候开始习惯手机自动把照片分类到"人物""风景""美食"?你可能根本记不住具体的日期——因为这些功能就是在某一天默默上线,然后你就习惯了。
这大概就是最成功的AI产品的特征:润物细无声。用户甚至意识不到自己在使用AI。
以下是计算机视觉时代最具代表性的产品和应用——你大概率每天都在使用其中的好几个:
| # | 产品/应用 | 公司 | 核心CV技术 | 故事 |
|---|---|---|---|---|
| 1 | ImageNet竞赛 | 斯坦福 | 图像分类基准 | 李飞飞花两年众包标注1400万张图片。竞赛从2010年11支队伍发展到2017年38支,错误率从28%降到不足5%。2017年后停办——AI已经超过了人类,比赛没有意义了 |
| 2 | Google Photos | CNN图像分类+人脸聚类 | 2015年上线,用深度学习自动对照片分类和搜索。你输入"沙滩"就能找到所有海边照片,输入"狗"就能找到所有狗的照片——不需要手动打标签。这是普通人第一次在日常生活中无感使用深度学习 | |
| 3 | Face ID | Apple | 3D人脸检测+识别 | 2017年随iPhone X发布。用结构光投射3万个红外点建立人脸3D模型,配合深度学习做活体检测和身份识别。这是深度学习进入十亿级消费设备的里程碑——从此每个人口袋里都有一个深度学习模型在运行 |
| 4 | Tesla Autopilot | Tesla | YOLO类实时目标检测+车道线识别 | 2016年起持续迭代。Tesla坚持纯摄像头方案(不依赖激光雷达),用8个摄像头+视觉神经网络构建360度感知。争议极大——出过致命事故,监管多次调查——但它推动了整个自动驾驶行业从"实验室"走向"量产" |
| 5 | 美图秀秀/抖音特效 | 美图/字节 | 人脸关键点检测+图像分割+风格迁移 | 美图秀秀的"一键美颜"基于人脸关键点检测(68-106个点精确定位五官位置),然后对肤色、轮廓、眼睛大小做像素级调整。抖音的AR特效(猫耳朵、变脸、背景替换)同样依赖实时人脸检测和图像分割。这类应用让数亿用户在不知不觉中成为了深度学习的日常使用者 |
| 6 | 手机AI拍照 | 华为/小米/苹果 | 场景识别+语义分割+超分辨率 | 你对着菜拍照手机自动切到"美食模式",对着人拍自动切到"人像模式"背景虚化——这是CNN在做场景分类。夜景模式的"计算摄影"用多帧融合+神经网络降噪。华为P30 Pro的"月亮模式"曾引发争议,但本质上就是AI超分辨率 |
| 7 | Amazon Go无人商店 | Amazon | 多摄像头目标检测+跟踪+行为识别 | 2018年在西雅图开业。数百个摄像头+深度学习追踪每个顾客拿了什么商品、放回了什么,出门时自动从账户扣款。虽然后来规模缩减(成本太高),但它验证了"视觉AI替代收银员"的技术可行性 |
| 8 | 海康威视智能摄像头 | 海康威视 | 嵌入式目标检测+行为分析 | 全球最大的视频监控设备商。将YOLO类检测算法压缩后嵌入摄像头端侧芯片,实现"前端智能"——摄像头本身就能做人脸识别、车牌识别、行为异常检测,不需要把所有视频传回后台。2023年营收超890亿元人民币 |
| 9 | 医学影像AI(肺结节检测) | 多家公司 | 3D CNN+目标检测 | 用CT扫描的3D图像训练CNN检测肺结节。AI可以在几百张CT切片中找到直径仅几毫米的可疑结节,辅助放射科医生诊断。FDA已经批准了多款AI辅助诊断软件。在中国,推想科技、依图医疗等公司的产品已进入数百家医院 |
| 10 | 刷脸支付/刷脸通行 | 支付宝/微信 | 人脸检测+活体检测+1:N识别 | 支付宝2015年率先推出刷脸支付(旷视科技提供技术),到2020年全国刷脸支付终端超过千万台。地铁闸机刷脸通行、机场自助通关、酒店刷脸入住——所有这些场景的底层都是"人脸检测+识别"这条计算机视觉技术链 |
你可能注意到了一个有趣的现象:上面这10个产品和应用,大部分都没有在发布时引发什么"震动"。没有人因为Google Photos能搜索"沙滩"就觉得世界要被颠覆了。iPhone X的Face ID发布时人们关注的是刘海屏好不好看,而不是里面的深度学习模型有多先进。美图秀秀的用户只关心自拍变好看了多少,不会去想背后是68个人脸关键点在做像素级别的变换。
这和大模型时代的产品形成了鲜明对比——ChatGPT两月破亿用户,Sora的演示视频让全网炸锅——大模型时代的AI产品是"大开大合"式的出场。
但计算机视觉时代的AI产品,走的是润物细无声的路线。它们在某一天默默地上线了一个新功能,然后你就习惯了。等到你习惯之后,你甚至忘了以前没有这个功能的日子是什么样的。
这种"无感渗透"可能才是AI对社会最深远的影响方式。
中国"AI四小龙":一场辉煌与教训并存的资本故事
如果说AlexNet点燃了全球学术界对深度学习的热情,那么2016年AlphaGo战胜李世石则点燃了中国资本市场对AI的狂热。一夜之间,"人工智能"成了创投圈最性感的标签,而计算机视觉——因为商业落地路径最清晰(人脸识别、安防、自动驾驶)——成了资本追逐的主赛道。
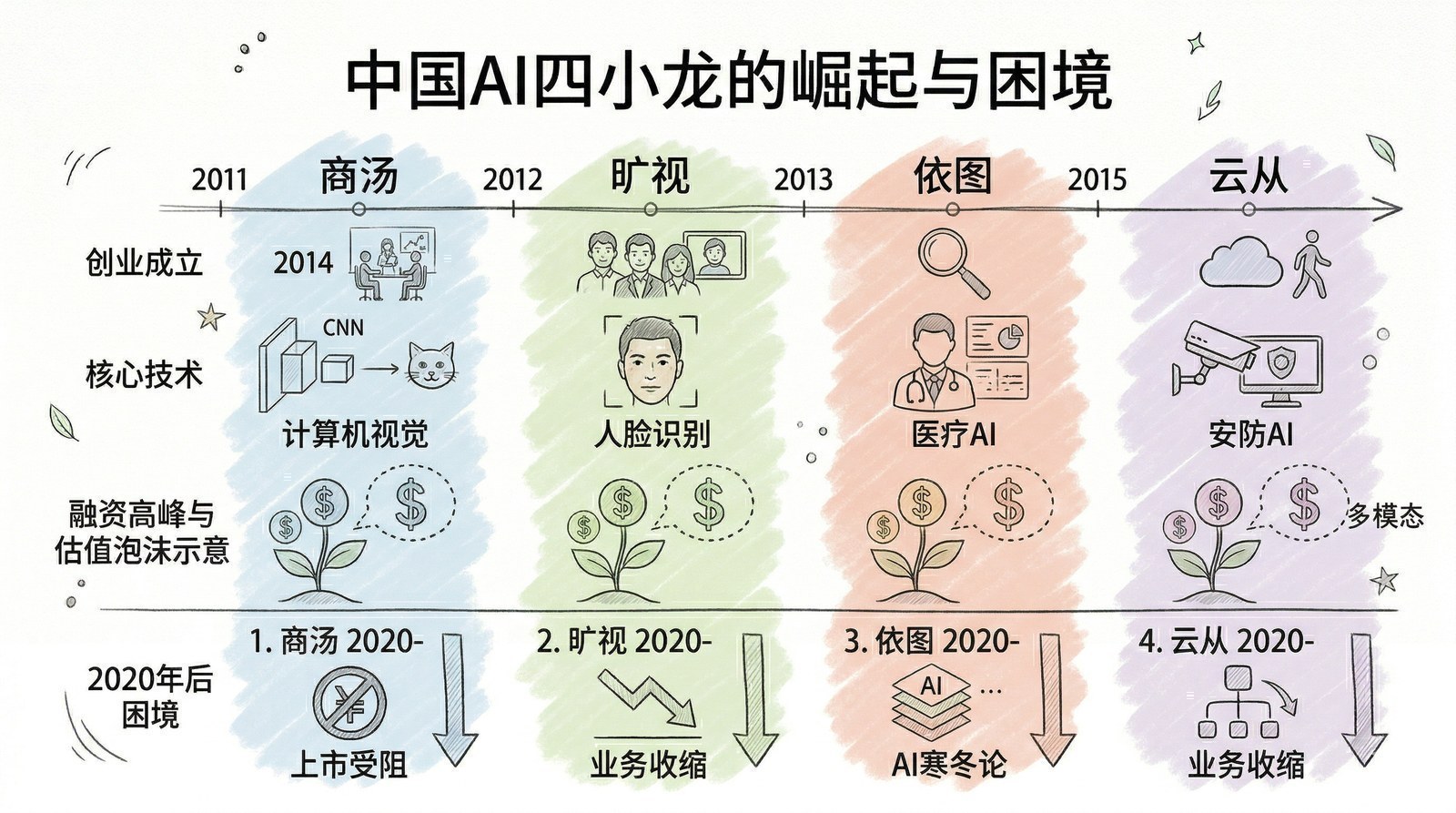
在这个赛道上,四家公司脱颖而出,被业界并称为"AI四小龙":
| 公司 | 成立时间 | 创始团队 | 技术起点 | 最高估值 |
|---|---|---|---|---|
| 旷视科技 | 2011 | 三位清华学生(印奇等) | 人脸识别 | ~50亿美元 |
| 依图科技 | 2012 | MIT背景(朱珑、林晨曦) | 医疗影像+安防 | ~40亿美元 |
| 商汤科技 | 2014 | 香港中文大学汤晓鸥团队 | 计算机视觉全栈 | ~100亿美元 |
| 云从科技 | 2015 | 中科院背景 | 金融+安防 | ~42亿美元 |
崛起期(2014-2018):技术变现金
旷视科技是最早嗅到商机的。2014年,支付宝寻找"刷脸支付"的技术提供商,旷视拿下了这个标杆项目——这是人脸识别技术第一次大规模商用。此后四小龙各显神通:商汤帮中国移动完成3亿人手机实名认证,云从成为银行领域第一大AI供应商,依图凭借"蜻蜓眼系统"帮助公安部门做人像识别。
2016年AlphaGo之后,资本彻底疯狂了。2017年10月,旷视完成C轮4.6亿美元融资,刷新了当时全球人工智能单笔融资最高纪录。商汤科技在2017-2018年连续完成多轮融资,估值飙升至60亿美元以上,投资方阵容堪称豪华——软银、银湖、IDG、阿里巴巴等明星机构云集。到2020年,四家公司在一级市场融资接近500亿元人民币,总估值超过1400亿元。IDC数据显示,2020年这四家加上海康威视,合计占据了中国计算机视觉市场近50%的份额。
困境期(2019-2022):高融资、高研发、高亏损
但资本狂欢掩盖了一个根本问题:技术门槛在快速降低,而商业化落地远比想象中困难。
人脸识别的算法门槛其实并不高。当阿里、百度、腾讯等大厂自行开发出类似的技术后,四小龙最引以为豪的技术壁垒开始瓦解。蚂蚁金服在2020年就透露,公司刷脸系统早已不再与旷视合作,改为自主研发。
四小龙的营收主要来自政府和大企业客户(ToG/ToB),但这类项目周期长、回款慢、定制化程度高,做完一个项目几乎没有可复用的组件。与此同时,研发费用居高不下——商汤科技2022年的研发费用率高达105%,研发投入超过了营业收入。
数字触目惊心:2018-2024年,商汤科技累计亏损超过546亿元。四小龙三年合计亏损超过500亿元。
上市坎坷(2021-2022)
四小龙的上市之路堪称一波三折。旷视科技最早行动,2019年递交港股招股书,却遭遇美国"实体清单"制裁,被迫转战科创板,到2021年通过审核后又长期卡在注册环节。依图科技两次IPO中止后主动撤材料。商汤科技2021年底匆忙登陆港股,上市四天市值冲破2720亿港元,随后一路下跌,六个月后一天内市值蒸发超900亿。云从科技2022年5月登陆科创板,上市后一个月即进入下行通道。
转型期(2023-2025):押注大模型
ChatGPT的出现给了四小龙一线希望。商汤科技押注生成式AI,2024年生成式AI业务收入达24亿元,占总营收的64%。依图科技创始人林晨曦透露公司已经盈利,现金流为正。旷视转向纯视觉自动驾驶方案。云从科技发布"从容大模型"进军行业AI。
但新赛道上,它们面对的对手已经换了一批——不再是彼此,而是DeepSeek、智谱AI、月之暗面这些"AI新六虎",以及阿里Qwen、字节豆包等大厂的碾压。
昔日的"计算机视觉四小龙"正试图蜕变为"大模型玩家"。这场转型能否成功,将在第十四章(群星闪耀)中再次提及。但无论最终命运如何,它们在中国AI产业史上的地位不可磨灭——它们证明了中国团队可以在全球AI技术竞争中站到第一梯队,也用自己的血泪经验为后来者留下了最昂贵的一课。
这十年告诉我们什么
从2012年的AlexNet到2020年的DETR,计算机视觉的进化展现了几个在整个大模型时代反复出现的规律。
技术规律
规律一:数据、算力、算法必须同时就位——而且规模比巧妙更重要。
AlexNet的成功不是某一个突破的功劳,是ImageNet(数据)+ GPU(算力)+ 更深的CNN(算法)三者同时成熟的结果。这个"三位一体"的模式在此后每一次大跃迁中都会反复出现。而正如Richard Sutton在《The Bitter Lesson》[24]中总结的:每一次,简单的方法配合大规模计算,都会战胜精巧但规模有限的方法。 AlexNet用粗糙的CNN打败了精心设计的手工特征,八年后GPT-3用"暴力堆参数"打败了精心设计的小模型,历史不断重演。
规律二:简单粗暴往往打败精巧设计。
YOLO[9]的设计思路比R-CNN[6]"粗糙"得多——一步到位而不是精确分两步——但因为够快,反而在实际应用中胜出。ResNet[3]的快捷连接简单到让人怀疑"这也能发论文?",但效果是革命性的。这种"简单即力量"的哲学,后来在Transformer(去掉了所有循环和卷积,只留注意力)、GPT(只做"预测下一个词"这一件事)中一再被验证。
规律三:架构统一的力量。
从R-CNN到YOLO到DETR[15],从CNN到Transformer入侵视觉(DETR、TimeSformer[23]),我们看到一个反复出现的趋势:最终胜出的不是"为某个任务专门设计的最优架构",而是"足够通用、可以无限扩展的统一架构"。 专用架构在自己的领域里可能更精确,但通用架构因为可以吃到更多数据和更大算力的红利,最终会追平甚至超越。这个趋势在第四章(Transformer的诞生)中会被推到极致——一个架构统一了NLP、CV、语音乃至所有AI领域。
产品规律
规律四:AI产品最成功的渗透方式是润物细无声。
回顾这十年最成功的CV产品——Google Photos、Face ID、美图秀秀、手机AI拍照——它们有一个共同特征:用户根本不知道自己在用AI。没有人因为Face ID而觉得自己在使用"人工智能技术",它就是"用脸解锁手机"而已。最好的AI产品,是让技术完全消失在体验中。
这和今天大模型产品的思路形成了对比——ChatGPT是以"AI"为卖点的,用户清楚地知道自己在和AI对话。但计算机视觉时代的教训是:长期来看,AI的最大价值可能不在于创造新的"AI产品"类别,而在于让所有现有产品都变得更智能。 手机变得更会拍照了,相册变得更会搜索了,监控变得更会识别了——这些提升无声无息,但累积起来改变了整个世界。
规律五:技术最强的公司未必赢——海康威视的启示。
在AI四小龙的光环下,很少有人注意到一个事实:过去十年计算机视觉领域最赚钱的中国公司,不是商汤、旷视中的任何一家,而是海康威视——一家成立于2001年的"传统"安防公司。2023年海康威视营收超过890亿元人民币,利润超过140亿元,而四小龙的营收加起来还不到它的十分之一。
海康威视做对了什么?它没有最先进的算法(它的AI算法团队远小于四小龙),但它有遍布全球的销售渠道、成熟的硬件制造能力和二十年积累的客户关系。当深度学习检测算法成熟后,海康威视将其集成进自己的摄像头产品线——这个过程花了不到两年。对它来说,AI只是给已有产品加了一个新功能,而不是需要从零建立商业模式的全新业务。
这个故事的教训很清楚:在AI行业,技术是入场券,但不是终点线。 渠道、场景理解、硬件能力、客户关系——这些"非技术"壁垒,往往比算法本身更难被复制。
产业规律
规律六:技术领先≠商业成功——AI四小龙的三条教训。
四小龙的故事是中国AI产业最好的教科书。它揭示了三个在今天的大模型时代依然高度相关的产业规律:
其一,算法的门槛在快速降低,但场景的门槛在快速升高。 四小龙在2016年拥有世界一流的人脸识别技术,但仅仅两三年后,阿里、百度、腾讯就自研了同等水平的方案。技术壁垒消失的速度远超所有人预期。今天的大模型创业面临完全相同的处境——当Llama、Qwen、DeepSeek等开源模型把基座能力拉平后,纯技术优势几乎不可能维持。真正的壁垒在于对行业场景的深度理解、数据的独特性和客户关系的粘性。
其二,ToG/ToB定制化是一条看起来安全但极其危险的路。 四小龙超过70%的营收来自政府和大企业客户。这类项目单笔金额大,但周期长、回款慢、高度定制化,做完一个项目几乎没有可复用的组件。更要命的是,当政府预算收紧时,营收会断崖式下跌——云从科技2024年营收同比下降了37%。今天做AI落地的团队,如果业务模式是"接项目做定制",四小龙的经历就是前车之鉴。
其三,融资和估值不是护城河,造血能力才是。 四小龙在一级市场融资近500亿元,总估值一度超过1400亿元。但七年过去,没有一家实现稳定盈利,商汤累计亏损超过546亿元。资本可以催大一家公司的估值,但不能替代产品的市场竞争力。这个教训在今天的大模型投资热潮中尤其刺耳——当下的"AI新六虎"们,是否也在重复同样的剧本?
回头看,2012到2020这八年,AI完成了一件了不起的事:让计算机学会了"看见"。从识别一张猫的照片,到在高速路上以毫秒级速度识别行人和车辆,到从几千小时的监控视频中自动找出异常——机器的"视觉"已经在很多场景中达到甚至超过了人类水平。
但"看见"只是第一步。机器能看懂一张猫的图片,却读不懂一句"今天天气真好"。AI的下一个挑战,是学会理解人类最复杂的创造——语言。
而解决这个问题的关键线索——注意力机制——恰恰来自于一位做机器翻译的研究者在2015年的一个灵感。
本章引用论文
| 编号 | 论文题目 | 年份 | 机构 |
|---|---|---|---|
| [1] | ImageNet Classification with Deep Convolutional Neural Networks (AlexNet) | 2012 | Toronto |
| [2] | Brook for GPUs: Stream Computing on Graphics Hardware | 2004 | Stanford |
| [3] | Deep Residual Learning for Image Recognition (ResNet) | 2015 | Microsoft Research Asia |
| [4] | Adam: A Method for Stochastic Optimization | 2014 | Toronto/Montreal |
| [6] | R-CNN: Rich Feature Hierarchies for Accurate Object Detection | 2014 | UC Berkeley |
| [7] | Fast R-CNN | 2015 | Microsoft Research |
| [8] | Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks | 2015 | Microsoft Research Asia |
| [9] | You Only Look Once: Unified, Real-Time Object Detection (YOLO v1) | 2016 | U. of Washington |
| [10] | SSD: Single Shot MultiBox Detector | 2016 | UNC Chapel Hill |
| [11] | YOLO9000: Better, Faster, Stronger (YOLOv2) | 2017 | U. of Washington |
| [12] | YOLOv3: An Incremental Improvement | 2018 | U. of Washington |
| [13] | Mask R-CNN | 2017 | FAIR (Meta) |
| [14] | CenterNet: Objects as Points | 2019 | UT Austin |
| [15] | DETR: End-to-End Object Detection with Transformers | 2020 | FAIR (Meta) |
| [16] | Two-Stream Convolutional Networks for Action Recognition in Videos | 2014 | Oxford |
| [17] | C3D: Learning Spatiotemporal Features with 3D Convolutional Networks | 2014 | FAIR (Meta) |
| [18] | Large-scale Video Classification with CNNs (DeepVideo) | 2014 | Stanford/Google |
| [19] | TSN: Temporal Segment Networks | 2016 | CUHK |
| [20] | I3D: Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset | 2017 | DeepMind |
| [21] | A Closer Look at Spatiotemporal Convolutions (R(2+1)D) | 2017 | FAIR (Meta) |
| [22] | SlowFast Networks for Video Recognition | 2018 | FAIR (Meta) |
| [23] | TimeSformer: Is Space-Time Attention All You Need for Video Understanding? | 2021 | FAIR (Meta) |
| [24] | The Bitter Lesson | 2019 | Richard Sutton |
| [25] | Understanding Deep Learning Requires Rethinking Generalization | 2016 | MIT/Google |
第二章:让机器"听懂"——从词向量到神经翻译,大模型前夜的三年蜕变
2016年11月的一个深夜
2016年11月15日,全球数亿Google翻译用户在毫不知情的情况下,成为了一场技术革命的见证者。
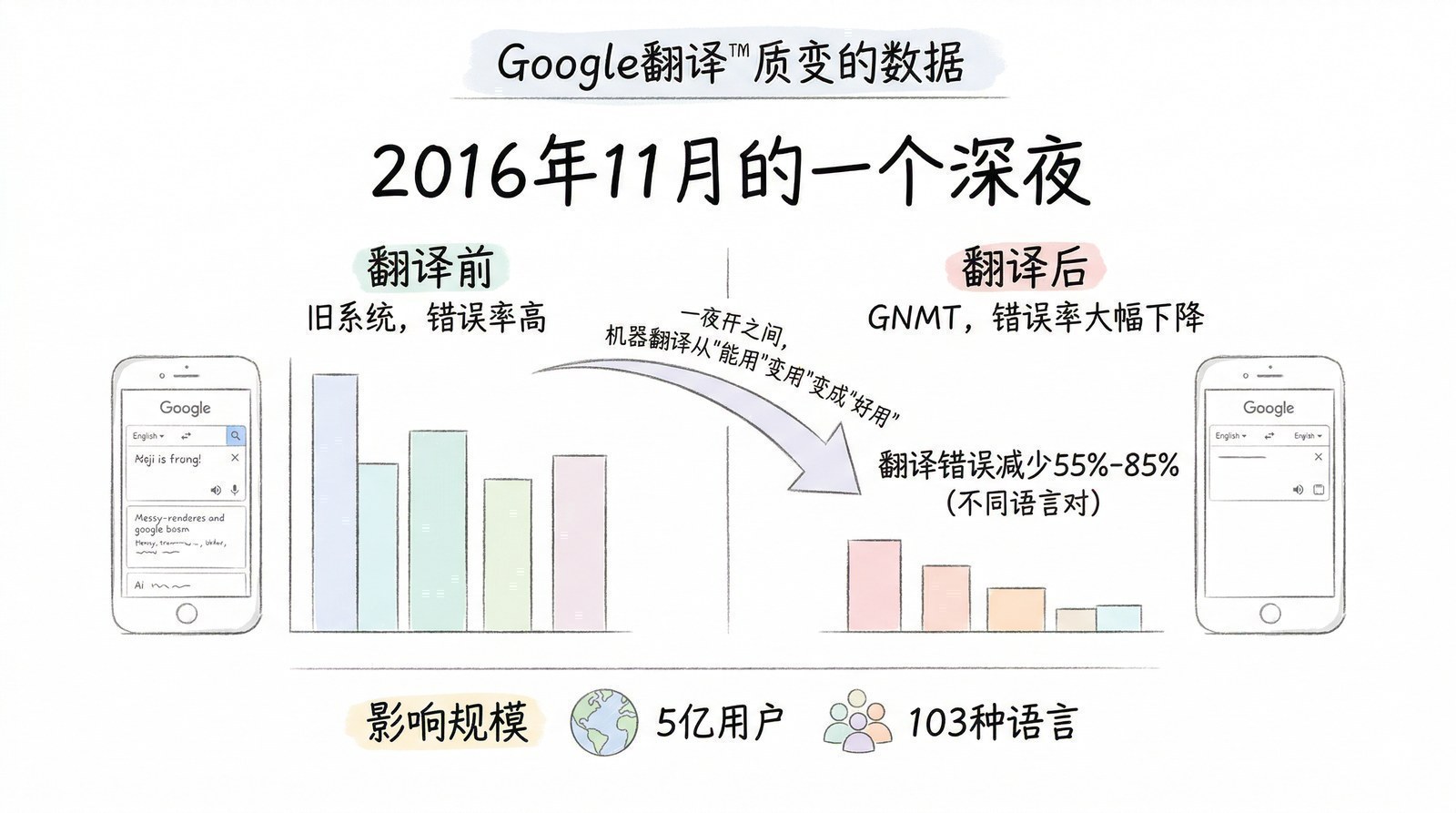
这天,Google悄悄地把中文↔英文翻译的后端系统从运行了十年的统计翻译引擎,切换成了一个全新的神经网络翻译系统——GNMT[6]。没有发布会,没有新闻稿,只是在Google Research的博客上低调地发了一篇文章。
但用户立刻感觉到了变化。
在此之前,Google翻译的中译英经常像是一个不太懂中文的外国人在逐字查词典:语法颠倒、词不达意、偶尔还会蹦出让人啼笑皆非的翻译。在此之后,翻译结果突然变得通顺了——不是完美的,但至少像一个"懂中文的人在说英文"了。
有多大的改善?Google自己的测量数据显示:在主要语言对上,翻译错误减少了55%-85%。社交媒体上的反应是即时的——"Google翻译怎么突然变好了?"在各种论坛被反复提问。有人甚至怀疑Google偷偷雇了真人翻译员在后台工作。
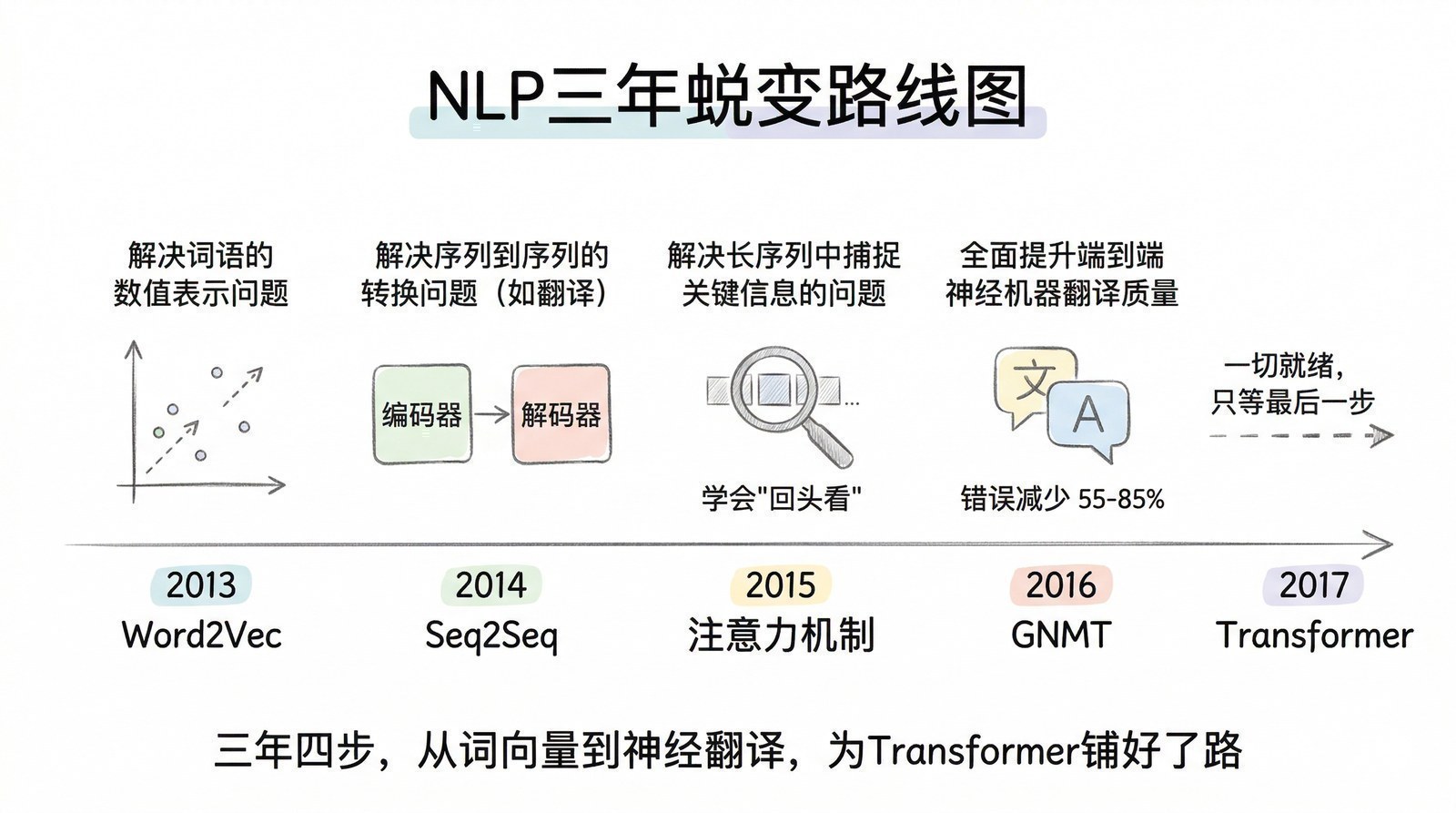
背后的秘密是一条从Word2Vec到Seq2Seq到注意力机制再到GNMT的技术进化链——只有短短三年(2013-2016),却为后来的整个大模型时代奠定了几乎所有的核心基础。今天你使用的ChatGPT、Claude、GPT-4——它们身上几乎每一个关键组件,都可以追溯到这三年间诞生的论文。
第一步:让词语变成数字——Word2Vec与词向量革命
在AI能"理解"语言之前,首先要解决一个最基本的问题:怎么把文字变成计算机能处理的数字?
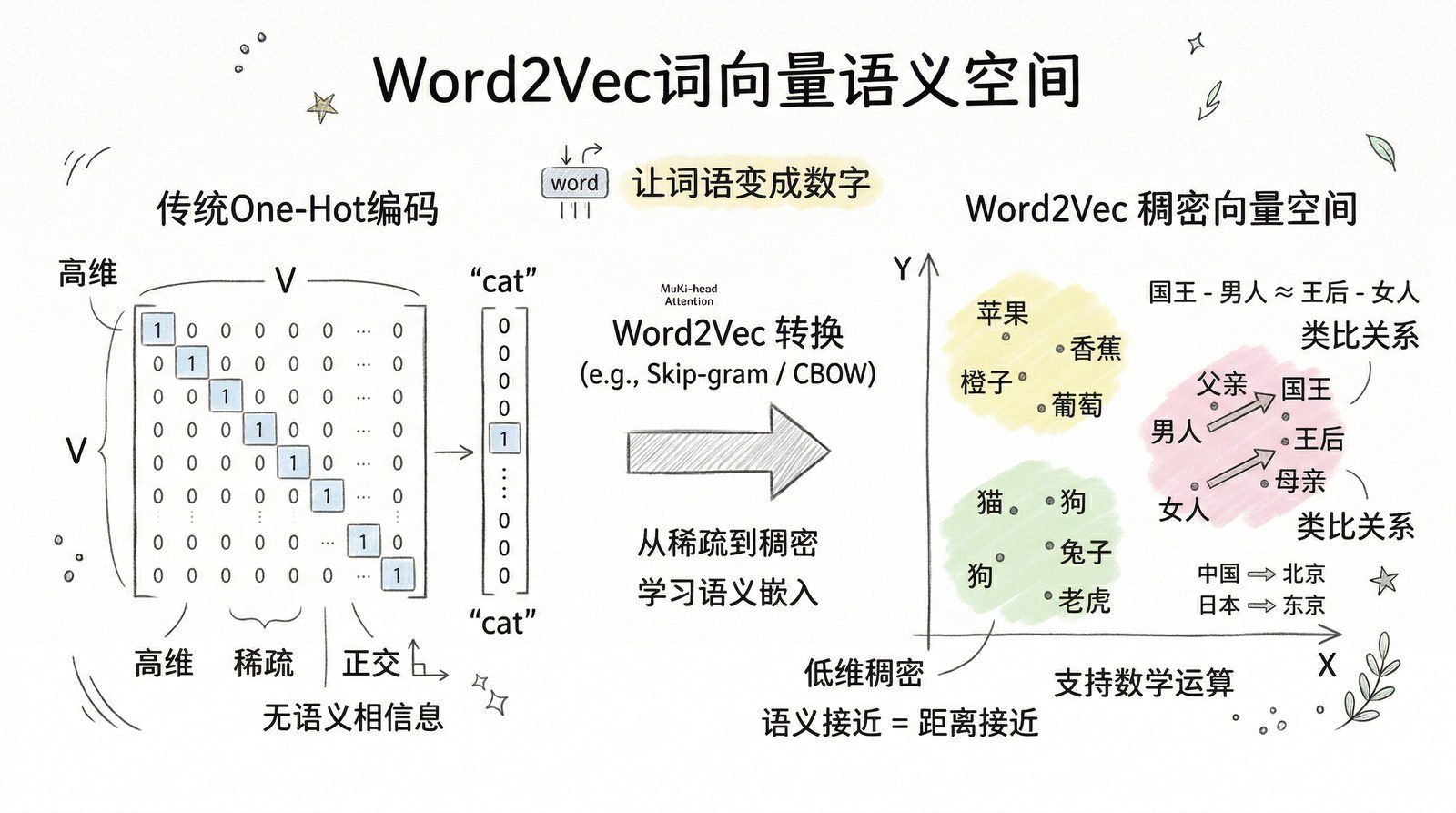
最朴素的做法叫"one-hot编码"——假设词典里有10万个词,每个词用一个10万维的向量表示,只有对应位置是1,其他全是0。问题很明显:在计算机看来,"猫"和"狗"的距离,与"猫"和"经济学"的距离完全一样。计算机根本不知道"猫"和"狗"是相似的概念。 语言中蕴含的丰富语义关系——同义、反义、类比、从属——全部丢失了。
2013年,Google的Tomas Mikolov、Kai Chen、Greg Corrado和Jeffrey Dean发表了Word2Vec[1],提出了一个简单但深刻的想法:通过预测一个词周围的词来学习这个词的"含义"。
核心逻辑基于语言学中的"分布假说":一个词的含义由它经常出现的语境决定。"猫"经常和"宠物""毛茸茸的""喂食"一起出现,"狗"也是——所以它们的向量应该很接近。"经济学"经常和"市场""GDP""通胀"一起出现,所以它的向量应该离"猫""狗"都很远。
Word2Vec用一个只有一层隐藏层的浅层神经网络,提供了两种训练方式:CBOW(Continuous Bag-of-Words,用周围的词预测中间的词)和Skip-gram(用一个词预测它周围的词)。在大量文本上训练后,每个词被表示为一个几百维的"词向量"——维度从常见的100维到Google自己使用的300维不等。
这些向量有一些令人惊叹的性质,其中最著名的是语义算术:
"国王" - "男人" + "女人" ≈ "女王"
"巴黎" - "法国" + "日本" ≈ "东京"
词向量不仅捕捉了词语之间的相似性,还捕捉了词语之间的关系。"国王到男人的关系"和"女王到女人的关系"被编码在向量空间中相同的方向上——语义关系可以用简单的向量加减法来计算。这在2013年是一个令人震惊的发现。
Word2Vec确立了一种贯穿整个大模型时代的核心思想:语言可以被"压缩"成数学空间中的点和方向,语义关系可以用向量运算来表达。 后来BERT(2018年)的核心任务——随机遮住一个词,让模型根据上下文猜测是什么词——本质上就是Word2Vec"用上下文预测目标词"的深度升级版。GPT的"预测下一个词",和Skip-gram在精神上一脉相承。
但Word2Vec有两个根本性的局限。第一,它为每个词只能生成一个固定的向量——无法处理一词多义。"苹果"在"吃苹果"和"苹果公司"中含义完全不同,但Word2Vec给它们同一个向量。第二,它只能捕捉局部的词与词关系,无法理解句子级别的含义——"狗咬人"和"人咬狗"在Word2Vec看来差别不大,因为包含的词完全相同。
要解决这些问题,需要一种能处理序列的模型——不只是看单个词,而是按顺序读整句话。
第二步:让机器学会"读入一句话,吐出另一句话"——Seq2Seq
2014年是自然语言处理历史上极为密集的一年。三篇几乎同时发表的论文,共同确立了Seq2Seq(Sequence to Sequence) 这个影响深远的框架。
第一篇来自蒙特利尔大学的Kyunghyun Cho等人,提出了RNN Encoder-Decoder框架[2]——用一个循环神经网络(RNN)把输入序列"编码"成一个向量,再用另一个RNN把这个向量"解码"成输出序列。他们在这篇论文中还提出了GRU(门控循环单元),一种比标准RNN更高效的变体。
第二篇同样来自蒙特利尔团队,Cho等人分析了编码器-解码器架构的特性[4]——发现当输入句子变长时,翻译质量会急剧下降。
第三篇来自Google的Ilya Sutskever(AlexNet的那位作者,此时已加入Google Brain)、Oriol Vinyals和Quoc Le,题目直截了当:《Sequence to Sequence Learning with Neural Networks》[3]。这篇论文用更深的LSTM(长短期记忆网络——一种专门设计来记住长距离信息的RNN变体)实现了Seq2Seq,并加入了一个巧妙的技巧——把输入句子反转后再喂给编码器,在英法翻译上取得了当时最好的结果。
用一个比方来理解整个框架:想象你要把中文翻译成英文。你先从头到尾读一遍中文句子,在脑子里形成一个"这句话大概意思是什么"的整体理解——这是编码器的工作,把输入序列压缩成一个固定长度的"上下文向量"。然后你根据这个整体理解,一个词一个词地输出英文——这是解码器的工作,从这个向量中逐步生成输出序列。
Seq2Seq的编码器-解码器框架是一个极其通用的抽象。翻译只是它的第一个应用——文本摘要(长文→短文)、对话(问题→回答)、语音识别(音频→文字)、代码生成(自然语言→代码)都可以用它建模。今天ChatGPT回答你的每一个问题,本质上就是Seq2Seq——从输入序列生成输出序列。一年后Transformer(第四章)的架构直接继承了编码器-解码器结构;BERT只用了编码器(专注"理解"),GPT只用了解码器(专注"生成")——都是Seq2Seq框架的"半边天"。
但Seq2Seq有一个根本性的缺陷:信息瓶颈。无论输入是5个词还是50个词,都被塞进同一个几百维的向量里。就像把一本书压缩成一句话,短句还好,长句必然丢失大量信息。蒙特利尔团队的分析[4]清楚地展示了这一点:句子超过20个词后,翻译质量就开始显著下降。
更深层的限制来自硬件。Seq2Seq使用的RNN必须按顺序处理每个词,一个接一个,无法并行。读一个100词的句子就要顺序执行100步——即使2014年的主力GPU NVIDIA K80也无法加速这个过程,因为GPU擅长的是并行计算,而RNN偏偏是串行的。Sutskever的论文中,训练一个英法翻译模型需要在8块GPU上跑10天。想把模型做得更大、处理更长的文本?算力需求会急剧膨胀——这在当时完全不可承受。
RNN的顺序瓶颈和算力的天花板,成了NLP进一步突破的最大障碍。突破它需要两件事:一种不需要顺序处理的新机制,和更强大的并行计算硬件。 前者在一年后到来,后者是第三章的故事。
第三步:注意力机制——让模型学会"回头看"
2015年,Dzmitry Bahdanau、Kyunghyun Cho和Yoshua Bengio(深度学习三巨头之一、2018年图灵奖得主)发表了《Neural Machine Translation by Jointly Learning to Align and Translate》[5],提出了注意力机制(Attention Mechanism)。
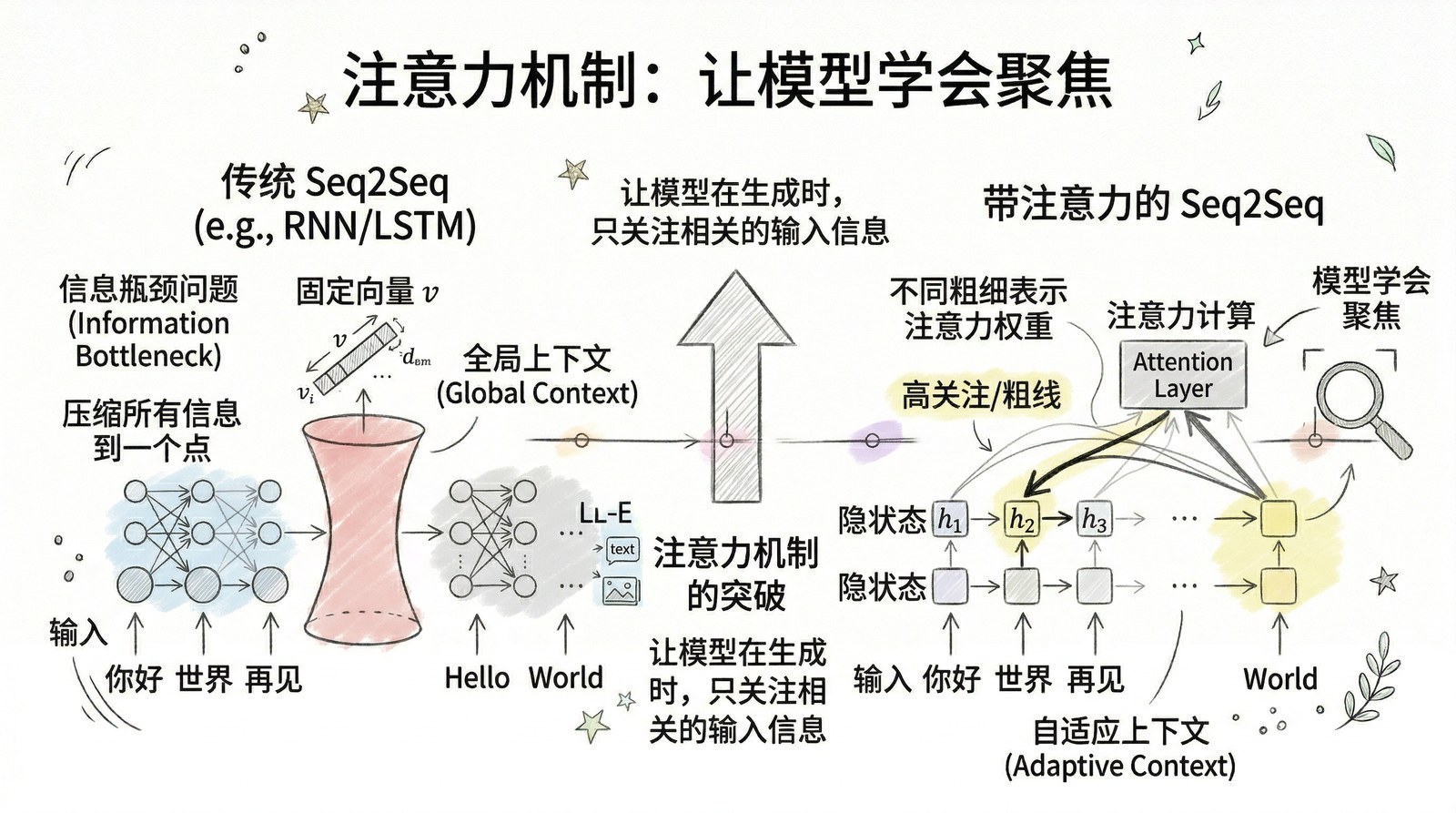
Bahdanau的洞见很直接:Seq2Seq把整个输入压缩成一个固定向量,信息必然丢失。何必压缩呢?让解码器在生成每个输出词的时候,自己去"回头看"输入句子中最相关的部分。
翻译"我今天在北京吃了一碗很好吃的牛肉面"时,翻译到"beef noodles"就"回头看""牛肉面",翻译到"Beijing"就关注"北京"。模型在生成每个输出词时计算一组"注意力权重"——权重高的输入位置对当前输出产生更大影响。这些权重通过训练自动学习,不需要人工指定。
效果立竿见影——在长句子上(恰恰是Seq2Seq最弱的环节)提升尤为显著。而且注意力权重可以可视化:画出一张"对齐图",能直观看到模型翻译每个词时关注了输入的哪些位置。在深度学习的"黑箱"世界里,这种可解释性极为罕见。
注意力机制的影响远超翻译质量本身。它从根本上改变了神经网络处理信息的方式——从"必须顺序处理"变成了"可以跳跃关注"。两年后Google的八人团队把这个想法推到极致:如果注意力这么好用,为什么不把整个模型都建立在注意力之上? 去掉RNN,去掉卷积,只留注意力——这就是Transformer,论文标题"Attention Is All You Need"本身就是在向Bahdanau致敬。
Bahdanau注意力是"解码器关注编码器"的跨注意力。Transformer进一步发展出了"自注意力"——序列中每个位置都关注所有其他位置——彻底摆脱了RNN的顺序束缚。BERT用自注意力实现双向理解,GPT用带掩码的自注意力实现从左到右的生成。两者都直接站在Bahdanau的肩膀上。
但2015年的注意力仍然嫁接在RNN之上——模型主体还是顺序处理的LSTM,注意力只是一个附加组件。RNN的根本瓶颈并没有被消除。要彻底解决这个问题,需要一种完全基于注意力、不需要任何循环结构的新架构——这需要等到2017年的Transformer,而Transformer的训练又依赖更强大的GPU(从K80到P100再到V100,详见第三章)。
如果大模型时代有一个"创世时刻",那不是GPT-1的发表,不是ChatGPT的上线,而是2015年注意力机制的发明。它是后来一切的起点。
第四步:Google翻译的质变——GNMT
从学术论文到实际产品,中间隔着一段漫长的工程之路。Google翻译每天处理超过1800万次中英翻译请求,全部语言对加起来每天翻译超过1000亿个词。学术模型能翻译几百个句子就算成功,工业系统需要在毫秒级延迟内完成上亿次请求。
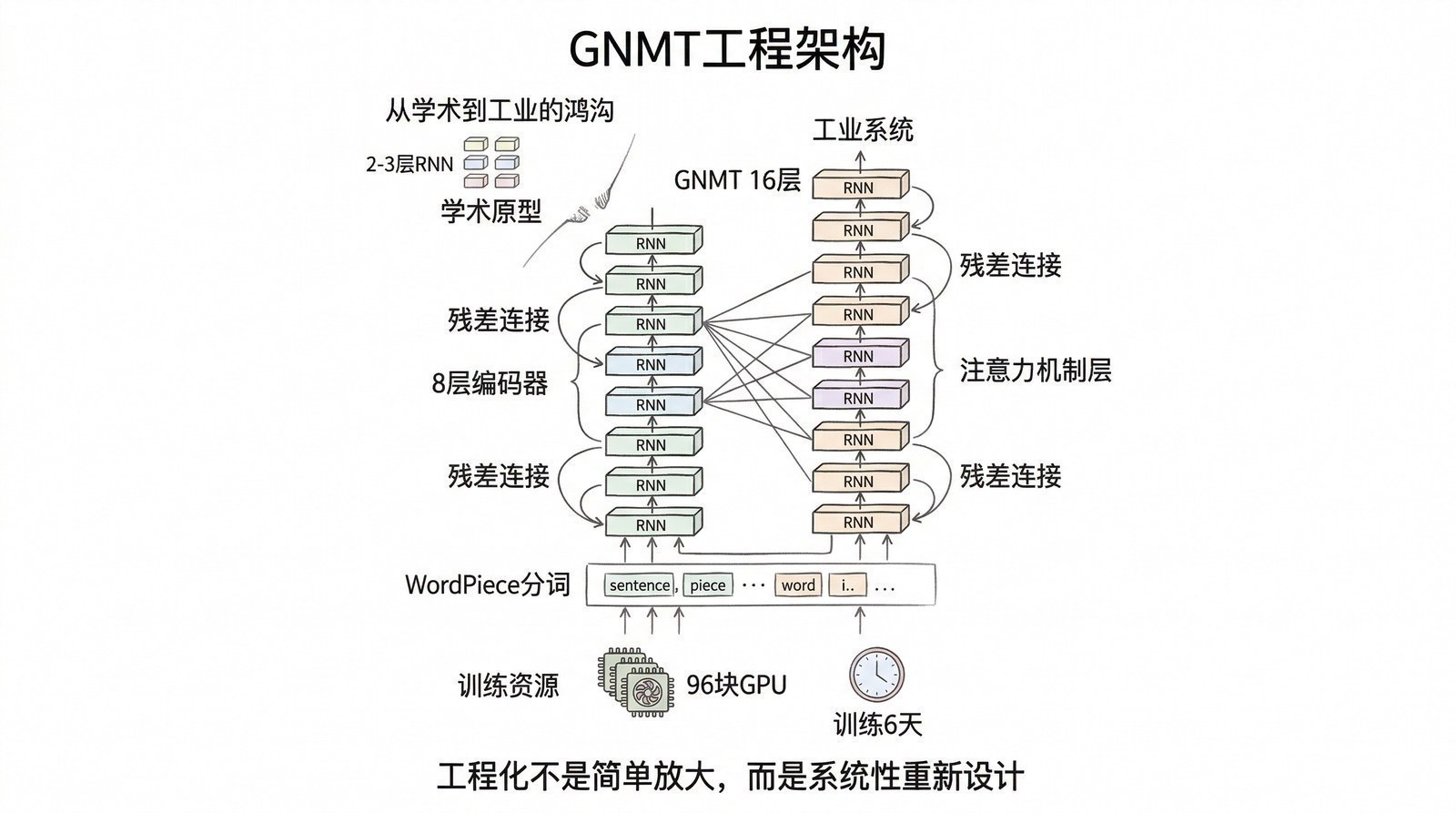
Google的吴永辉(Yonghui Wu)等人在《Google's Neural Machine Translation System》[6]中详细描述了这座桥是怎么搭起来的。GNMT的关键创新:
深层堆叠——8层LSTM编码器+8层LSTM解码器+注意力机制,总参数约2.1亿。当时学术模型通常只有2-4层,GNMT把深度推到了极限。但训练这样的深层网络需要Google专门研发的TPU(张量处理单元)——普通GPU已经扛不住了。
WordPiece分词——今天所有大模型"看"文字的方式在这里定型。 传统方法用整词作为最小单位,遇到陌生词只能标记"未知"。WordPiece把单词拆成更小的子词片段——"unbelievable"变成"un"+"believ"+"able"。即使遇到训练时没见过的新词,也能通过组合已知子词来处理。这个思路直接被BERT的WordPiece分词器和GPT的BPE(字节对编码)分词器继承。
残差连接——和ResNet(第一章)的思路一样,在深层LSTM之间加入快捷连接,让梯度可以"抄近道"直达深层。这使训练极深的序列模型成为可能,后来也被Transformer全面采用。
GNMT于2016年11月上线,首批支持中英等8个语言对。翻译错误减少55%-85%——Google评估这一次升级的提升幅度,相当于过去十年统计翻译方法累积的全部进步。到2017年底覆盖100+种语言。
GNMT往往被视为"一个翻译产品的升级",但它的贡献远超翻译本身:WordPiece/BPE分词成为所有主流大模型的标配,深层残差网络+注意力的组合为Transformer提供了工程经验,GNMT对算力的饥渴更是直接驱动了Google TPU的研发——"模型推动芯片进化"这条路线,后来在NVIDIA的A100/H100上不断重演。
GNMT也暴露了RNN架构的终极天花板。8层LSTM的训练需要TPU集群跑6天,而且由于RNN的顺序特性,即使有更多TPU也很难进一步提速。如果想从2亿参数扩展到10亿、100亿,训练时间会变得不可接受。无法并行是RNN的"原罪"。
这个瓶颈让Google内部开始思考一个根本性的问题:有没有一种架构,既保留注意力的优势,又彻底摆脱RNN的顺序束缚?
一条注定走向"只留注意力"的进化之路
回头看这三年的技术演进,你会发现一条清晰到几乎"命中注定"的淘汰链——每一步进化都在做同一件事:扔掉不必要的组件,只保留真正有效的那个。
最初的Seq2Seq(2014年),核心组件有三个:RNN(负责顺序处理序列)、编码器-解码器框架(负责"读入→输出"的整体结构)、以及把整个输入压缩成一个固定向量的"信息瓶颈"。
这三个组件中,第一个被扔掉的是"信息瓶颈"。Bahdanau注意力(2015年)让模型可以直接"回头看"输入的任意位置,不再需要把所有信息塞进一个向量。但注意力此时只是一个附件——模型的主体仍然是RNN,信息仍然是一个词一个词顺序处理的。
GNMT(2016年)把这套"RNN + 注意力"的组合推到了工业极限——8层LSTM,2.1亿参数,TPU集群训练6天。结果证明了两件事:第一,注意力是真正带来质变的组件(它让翻译错误减少了55%-85%)。第二,RNN是那个拖后腿的组件——它让模型无法并行训练,成为扩展规模的最大瓶颈。
这就产生了一个很自然的问题:既然注意力才是带来效果提升的核心,而RNN是阻碍规模扩展的瓶颈,那为什么不把RNN也扔掉,只留注意力?
这个问题的答案不是理论上的飞跃,而是工程上的必然。背后的驱动力主要有三个:
第一,并行化的需求。 GPU(以及后来的TPU)天生擅长大规模并行计算——同时处理成千上万个运算。但RNN必须按顺序处理每个词(第1个词处理完才能处理第2个词),完全无法利用GPU的并行能力。注意力机制则不同——计算每个位置的注意力权重时,可以同时计算所有位置,天然适合并行。如果把模型全部建立在注意力之上,训练速度会有数量级的提升。
第二,长距离依赖的需求。 RNN处理序列时,信息必须一步一步传递——从第1个词传到第100个词,中间经过了99步传递,信息不可避免地衰减。LSTM通过记忆门控机制缓解了这个问题,但在超过几百个词的序列上仍然力不从心。而注意力机制可以让第1个词直接"看到"第100个词——信息传递的路径从99步缩短到1步。只用注意力的模型在处理长文本时有天然的优势。
第三,规模扩展的需求。 2016年的GNMT有2.1亿参数,已经需要TPU集群训练6天。如果想把模型扩展到10亿、100亿参数(后来GPT-3确实做到了1750亿),必须要一种能高效利用大规模并行硬件的架构。RNN的顺序瓶颈意味着增加再多的GPU也没法线性加速训练。只有去掉RNN,才能真正释放硬件的全部潜力。
所以,2017年Transformer论文的标题"Attention Is All You Need"(注意力就是你所需要的一切)不是一句口号,而是对前三年技术进化的精确总结——经过三年的逐步试错和排除,RNN被排除了(因为无法并行),卷积被排除了(因为视野有限),最终只剩下注意力机制被证明是那个既能捕获语义关系、又能完全并行化的组件。
Transformer没有发明注意力——Bahdanau在2015年已经做了。Transformer也没有发明编码器-解码器——Seq2Seq在2014年已经做了。Transformer真正做的事情是:把前三年摸索出来的所有有效成分保留下来(注意力、编码器-解码器框架、残差连接、子词分词),把所有被证明是瓶颈的成分去掉(RNN的顺序处理、卷积的局部视野),重新组装成一个干净、统一、完全可并行的新架构。
这就是为什么说"Attention Is All You Need"不是凭空出现的——它是一条确定的进化路线的终点。从Seq2Seq到注意力到GNMT,每一步都在指向同一个方向:去掉冗余,只留注意力。 2017年的那篇论文只是把这个方向走到了逻辑上的尽头。
而这个新架构需要的算力支撑——能让注意力完全并行运行的硬件——恰好也在同一年成熟了。2017年NVIDIA发布了V100 GPU,首次集成了专为矩阵运算设计的Tensor Core。技术和算力,在2017年这个节点上再次同时就位——就像2012年AlexNet需要GPU和ImageNet同时成熟一样。这是第三章要讲的故事。
技术传承全景:从Word2Vec到大模型的四条线索
在进入产品和公司的故事之前,把这三年的技术传承关系梳理清楚:
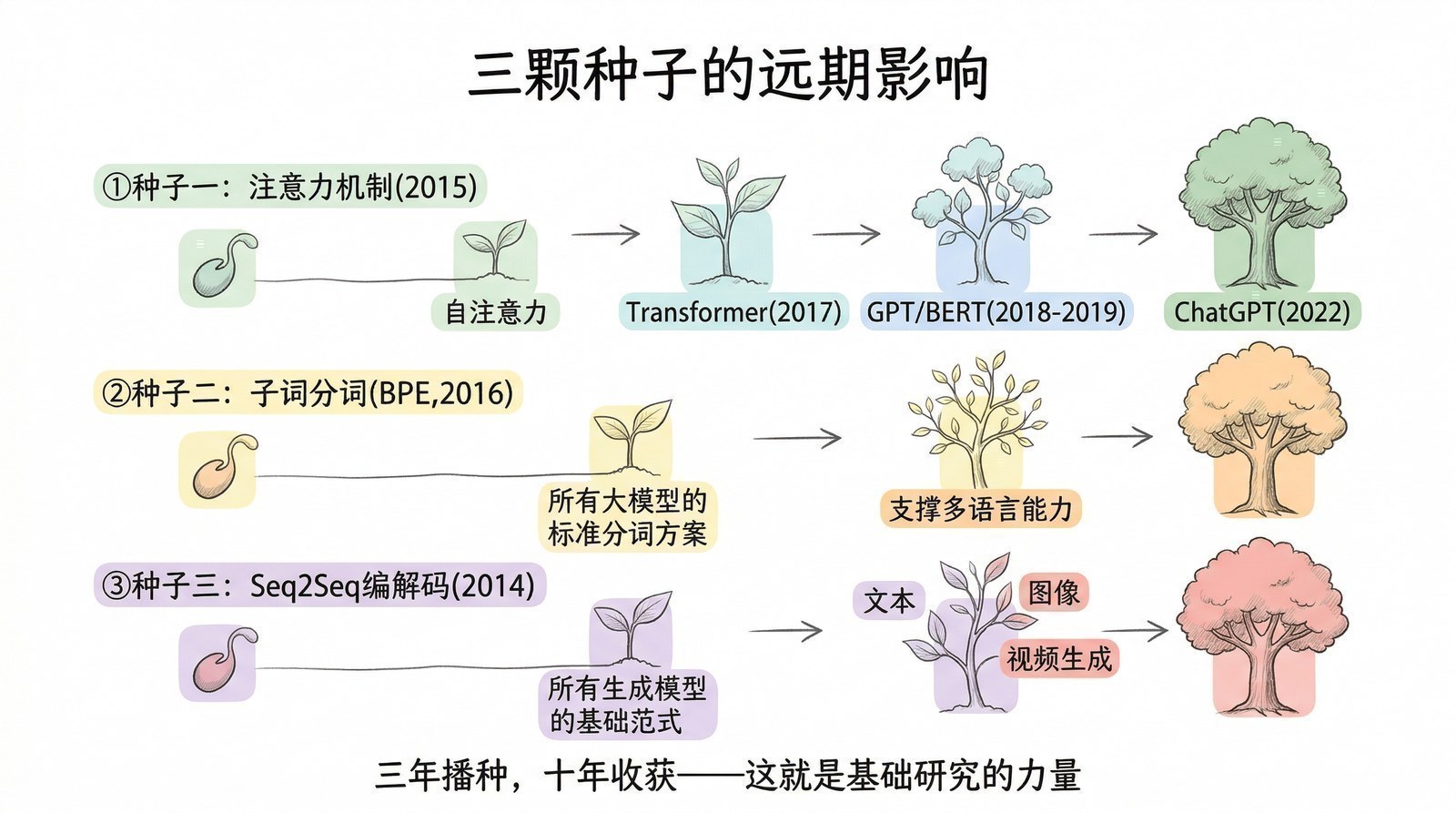
线索一:词的表示方法 Word2Vec词向量(2013)→ GNMT的WordPiece子词表示(2016)→ BERT的WordPiece(2018)→ GPT的BPE分词(2018)→ 今天所有大模型的token化方式
线索二:序列建模框架 Seq2Seq编码器-解码器(2014)→ GNMT深层编码器-解码器(2016)→ Transformer编码器-解码器(2017)→ BERT只用编码器 / GPT只用解码器
线索三:注意力机制的进化 Bahdanau跨注意力(2015)→ GNMT工业级注意力(2016)→ Transformer自注意力+多头注意力(2017)→ 今天所有大模型的核心计算单元
线索四:算力需求的升级 Word2Vec在普通服务器上训练 → Seq2Seq需要多块GPU跑数天 → GNMT需要TPU集群跑一周 → Transformer需要更大规模并行 → GPT-3需要上万块GPU训练数月
每一步技术进步都要求更大的算力,每一次算力突破又使能新的技术。这种"技术推动算力需求,算力反过来使能新技术"的螺旋式上升,正是大模型时代最核心的动力学。第三章会专门展开这个故事。
为什么最终"只留注意力"——一条注定的进化路线
回顾这三年的技术演进,有一条暗线贯穿始终:RNN在一步步被淘汰,注意力在一步步被加强,直到注意力完全取代了RNN。 这个过程不是偶然的灵光一闪,而是一条有着清晰因果逻辑的进化路线。
故事要从RNN的"原罪"说起。
RNN(循环神经网络)处理语言的方式是逐词顺序读取——读完第一个词,才能读第二个词;读完第二个词,才能读第三个词。这种设计在直觉上很自然——人类读书也是从左到右一个字一个字读的。但它带来了三个越来越严重的问题:
问题一:记忆衰减。 RNN把已经读过的信息"压缩"在一个固定大小的隐藏状态中。句子越长,早期读到的信息在隐藏状态中的"痕迹"就越淡。读到第100个词时,第1个词的信息可能已经被后面99个词冲刷得所剩无几。LSTM(1997年发明)通过引入"门控"机制部分缓解了这个问题——它像一个有选择性记忆的人,能决定"记住什么、忘掉什么"。但LSTM也不是万能的:在超过几百个词的序列上,记忆衰减依然存在。
问题二:无法并行。 这是RNN最致命的缺陷。由于每一步的计算都依赖上一步的输出(第2个词的处理必须等第1个词处理完),RNN天生是串行的。一个100词的句子就是100步顺序计算,一个1000词的文档就是1000步。GPU的核心优势是大规模并行——它有数千个计算核心可以同时工作。但RNN只能让这数千个核心排着队一个一个干活,算力利用率极低。这就好比你有一支1000人的团队,但任务只能一个人接一个人地做——999个人在等待。
问题三:训练速度的天花板。 问题二直接导致了问题三。模型越大、序列越长,训练时间就以线性甚至超线性的速度增长。Sutskever在2014年训练一个Seq2Seq模型需要8块GPU跑10天,GNMT在2016年需要Google TPU集群跑6天。如果想继续扩大模型——比如从2亿参数到10亿参数——训练时间会从几天变成几周甚至几个月。这在工业界完全不可接受。
研究者们尝试了各种修补方案:LSTM加了门控来缓解记忆衰减,GRU简化了门控结构来加速计算,双向RNN让模型既能从前往后读也能从后往前读,深层RNN通过堆叠多层来增加表达能力。这些改进都有效果,但都没有触及根本——只要还是"逐词顺序处理",瓶颈就还在。
2015年注意力机制的出现打开了一扇窗。Bahdanau注意力[5]让解码器可以"跳回去"直接关注输入序列中的任意位置——这意味着模型获取远距离信息时不再依赖RNN的隐藏状态层层传递,而是可以"一步到位"。这大大缓解了记忆衰减问题。
但Bahdanau注意力只是一个"补丁"——它仍然嫁接在RNN之上。编码器还是逐词顺序地处理输入,只是在解码时多了一条"直达通道"。RNN的串行瓶颈依然存在。
接下来发生的事情,回头看几乎是不可避免的。当研究者们发现注意力机制如此有效——它不需要顺序处理、天然支持并行计算、能直接关联任意距离的信息——一个自然的问题就浮现了:
如果注意力能解决RNN解决不了的问题,那我们为什么还需要RNN?
如果把RNN比作一条必须按站停靠的地铁线路(从第1站到第100站必须经过中间98站),那注意力机制就像一个直升机——可以直接从第1站飞到第100站,不需要经过任何中间站。既然有了直升机,还要地铁干什么?
2017年,Google的Vaswani等人用一篇论文回答了这个问题:不需要了。 他们设计的Transformer架构完全去掉了RNN和卷积,只保留了注意力机制(以及一些必要的辅助组件如位置编码和前馈网络)。
这个选择的底层逻辑非常清晰:
并行化:Transformer用"自注意力"处理输入——序列中的所有位置可以同时计算它们之间的关联,不需要等前一个位置处理完。一个100词的句子不再需要100步顺序计算,而是一步并行完成。这让GPU的数千个计算核心可以同时满负荷工作。
长距离依赖:在RNN中,第1个词的信息要传到第100个词,需要经过99步传递,每一步都会有信息损耗。在自注意力中,第1个词和第100个词之间只隔一步计算——信息损耗几乎为零。
可扩展性:正因为可以并行,Transformer的训练速度和序列长度不再是线性关系。这意味着模型可以做得更大、处理更长的文本——这直接打开了后来GPT-3的1750亿参数和GPT-4的超长上下文窗口的可能性。
回顾这条进化路线:
RNN(顺序处理,记忆衰减)
→ LSTM/GRU(加门控缓解记忆,但仍然顺序)
→ Seq2Seq(编码器-解码器框架,但信息瓶颈)
→ 注意力+RNN(缓解瓶颈,但RNN仍是主体)
→ Transformer(去掉RNN,只留注意力)
每一步都在解决上一步的瓶颈,每一步都在减少对RNN的依赖,直到最后一步把RNN完全去掉。"Attention Is All You Need"不是凭空出现的。 它是这条进化路线走到尽头后唯一合理的终点——当你发现注意力能做RNN做的所有事情,而且做得更好、更快、更容易扩展,那么保留RNN就没有任何理由了。
这也是为什么说2013-2016年这三年如此重要——不是因为它们产出了多少惊天动地的产品,而是因为它们沿着一条确定的技术路线,一步步走到了Transformer的门口。Transformer只是最后推开了那扇已经半开的门。
产品与公司聚光灯
① Google翻译大升级(2016年11月) — Seq2Seq + 注意力 + 深层LSTM。首批支持中英等8个语言对,到2017年底覆盖100+种语言。Google翻译至今服务超过5亿用户,每天翻译超过1000亿个词。数亿用户在毫不知情的情况下体验到了神经网络的威力。
② Amazon Alexa / Echo(2014年) — 2014年11月Amazon发布Echo智能音箱,内置语音助手Alexa,AI助手第一次以独立硬件进入普通家庭。虽然早期的NLP能力相当原始(大部分是规则匹配),但它开启了"语音交互"这个全新品类。到2020年全球智能音箱出货量超过1.5亿台。
③ Apple Siri的进化(2014-2016) — Siri最初(2011年)用传统语音识别和规则匹配,理解能力有限。2014年起Apple引入深度学习改造语音识别,准确率大幅提升。虽然Siri后来在AI助手竞赛中逐渐落后,但它在2011年首次让"对手机说话"成为主流行为。
④ Google Duplex(2018年5月) — 在Google I/O大会上演示AI打电话给餐厅预约座位,对方完全没有察觉在和机器对话。AI能处理停顿、犹豫、话题变化,甚至会说"嗯哼"表示在听。震惊全场的同时,也引发了AI伦理讨论——AI是否应该表明身份?
⑤ 搜索引擎的语义升级 — Word2Vec发布后,各大搜索引擎陆续引入词向量技术。之前搜"感冒怎么办"找不到"着凉的处理方法",词向量让搜索引擎理解了"感冒"和"着凉"是近义概念。又一个"润物细无声"的AI升级。
中国语音公司群像:技术与商业的互补之路
在Google翻译的GNMT震动全球的同时,中国的语音AI赛道也在上演一场精彩的竞争。这个故事值得细讲,因为它揭示了AI产业中一个反复被验证的规律——有技术还不够,技术与商业必须互补,才能走得远。
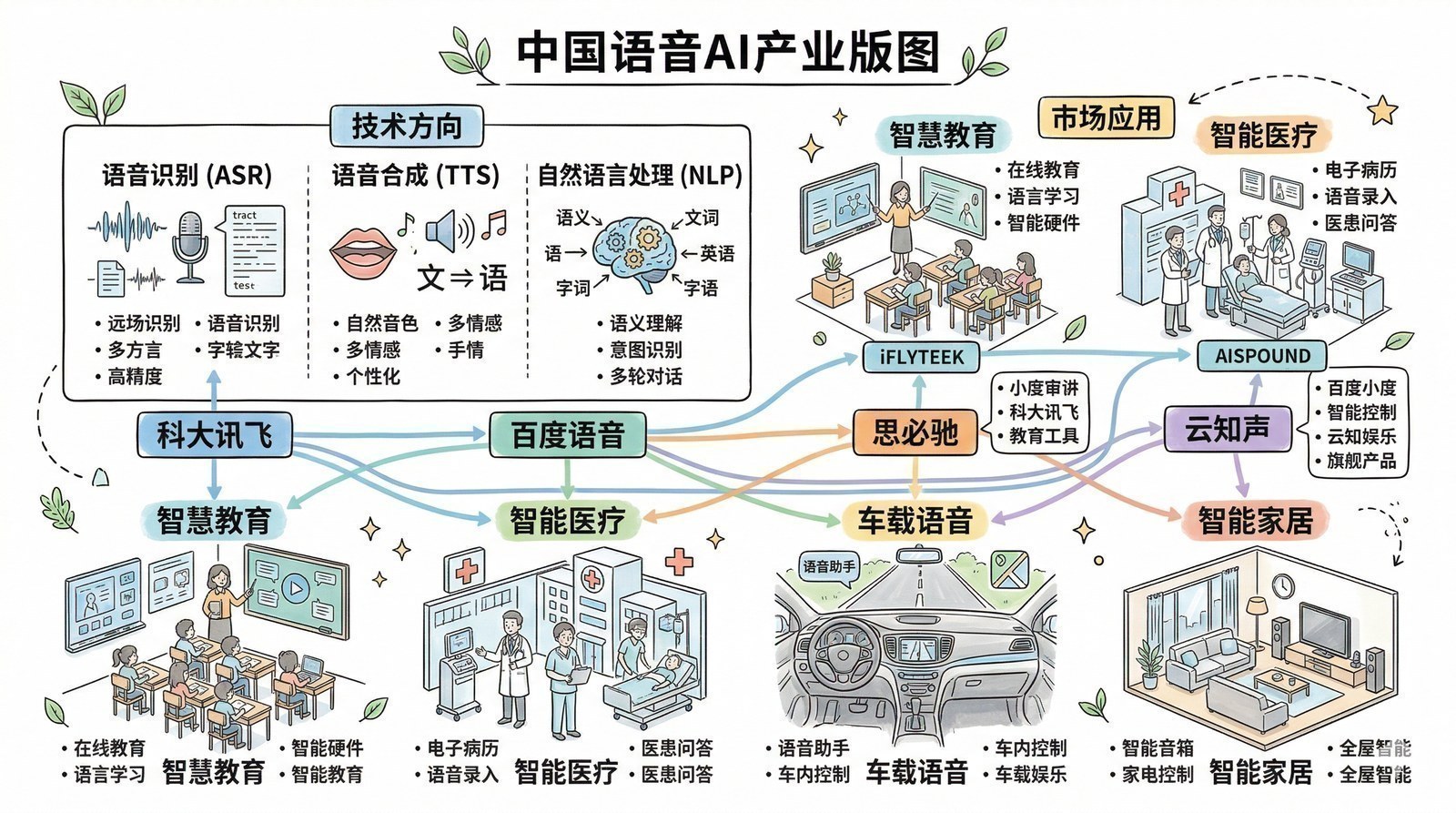
科大讯飞:老牌龙头,找到了"考试"这把金钥匙
1999年成立的科大讯飞是中国智能语音领域的先驱,创始团队来自中国科学技术大学。2008年上市,成为"中国AI第一股"。
科大讯飞的技术实力毋庸置疑——语音识别准确率长期保持国内领先。但真正让它屹立不倒的,是一个非常聪明的商业选择:深耕教育市场。通过收购多家语音评测公司,科大讯飞垄断了全国中高考英语口语评测市场——当你家孩子在学校做英语口语测试时,打分的大概率就是讯飞的系统。
考试场景的妙处在于:对技术精度要求极高(这正好是科大讯飞的强项),但一旦成为标准就极难被替代(没有学校愿意在考试评分上冒险换供应商)。到2023年,科大讯飞营收超过200亿元,在中国智能语音市场占据超过60%的份额。技术是入场券,"考试标准"才是护城河。
思必驰与云知声:在巨头的缝隙中找到自己的位置
2007年成立于英国剑桥的思必驰选择了IoT作为主攻方向——智能车载、智能家居、智能音箱。它的DUI开放平台打通了从语音识别到对话管理的全链路,在智能音箱爆发的2017-2019年为天猫精灵等产品提供了前端方案。2019年思必驰更进一步,发布了AI语音专用芯片TH1520,从纯软件走向"算法+芯片"一体化——用硬件绑定来建立更深的壁垒。
2012年成立的云知声团队来自盛大研究院,创始人梁家恩毕业于中科大(和科大讯飞是"师兄弟")。云知声选择了差异化路线——深耕智慧医疗,推出的AI语音病历系统让医生口述自动生成结构化病历,已在北京协和医院、福建省立医院等多家三甲医院上线。
这三家公司面对一个共同挑战:当BAT以免费或低价切入语音市场后,纯技术壁垒迅速降低。百度推出DuerOS,阿里有天猫精灵语音系统,腾讯也在自建。最终活下来并站稳的,都是找到了巨头不愿深耕的垂直场景——科大讯飞的教育考试、思必驰的IoT芯片、云知声的智慧医疗。
李志飞与出门问问:科学家创业的启示
在所有海外归来的AI创业者中,李志飞的故事最能说明"技术与商业互补"这个主题。
李志飞的履历堪称顶配:约翰霍普金斯大学计算机博士,师从全球顶级NLP实验室;博士期间开发了开源机器翻译软件Joshua,成为学术界两大主流翻译软件之一;毕业后拿到IBM、微软、Google、雅虎、Facebook的offer,加入Google翻译团队,参与开发了手机离线翻译系统。
2012年,李志飞从Google辞职回国创业。用他自己的话说:"从美国Google总部Research Scientist回中国创业,我是第一。"他拿到红杉资本和真格基金的天使投资,创办了出门问问,目标做"中国的Google Now"。
出门问问的发展轨迹揭示了一个关键洞见。最初它是一个语音搜索App——技术惊艳但缺乏用户粘性。李志飞很快意识到纯软件的语音助手很难建立壁垒,于是转向"软硬结合"——用自研AI语音技术打造智能硬件。2015年获得Google的C轮投资7500万美元,2017年大众汽车集团以1.8亿美元D轮独家投资,双方成立合资公司做智能车载。出门问问的TicWatch智能手表做到全球前五,进入了北美最大运营商Verizon的渠道——与苹果、三星同台竞争。
2023年大模型浪潮来临时,十年创业积累的技术底蕴和商业经验让李志飞再次站到了风口上。出门问问发布了自研大模型"序列猴子",推出AI配音助手"魔音工坊"、AI数字人"奇妙元"等AIGC产品矩阵,服务全球千万级用户。十年前从Google带回NLP技术的科学家,在大模型时代找到了技术与商业新的结合点。
李志飞的故事和第一章的AI四小龙形成了有意思的对照——同样是技术领先的AI创业者,李志飞的出门问问活了下来并持续进化,关键在于他很早就意识到:技术是敲门砖,但产品和场景才是护城河。 Google最前沿的NLP技术可以被大厂追平,但智能手表的硬件供应链、车载系统的客户关系、AIGC产品的用户数据——这些"非技术壁垒"需要时间积累,不是砸钱就能复制的。
这三年播下的种子
从2013年的Word2Vec到2016年的GNMT,自然语言处理在短短三年内完成了一次蜕变。这三年虽然不如计算机视觉那么声势浩大,但它播下的种子,每一颗都在后来长成了参天大树。
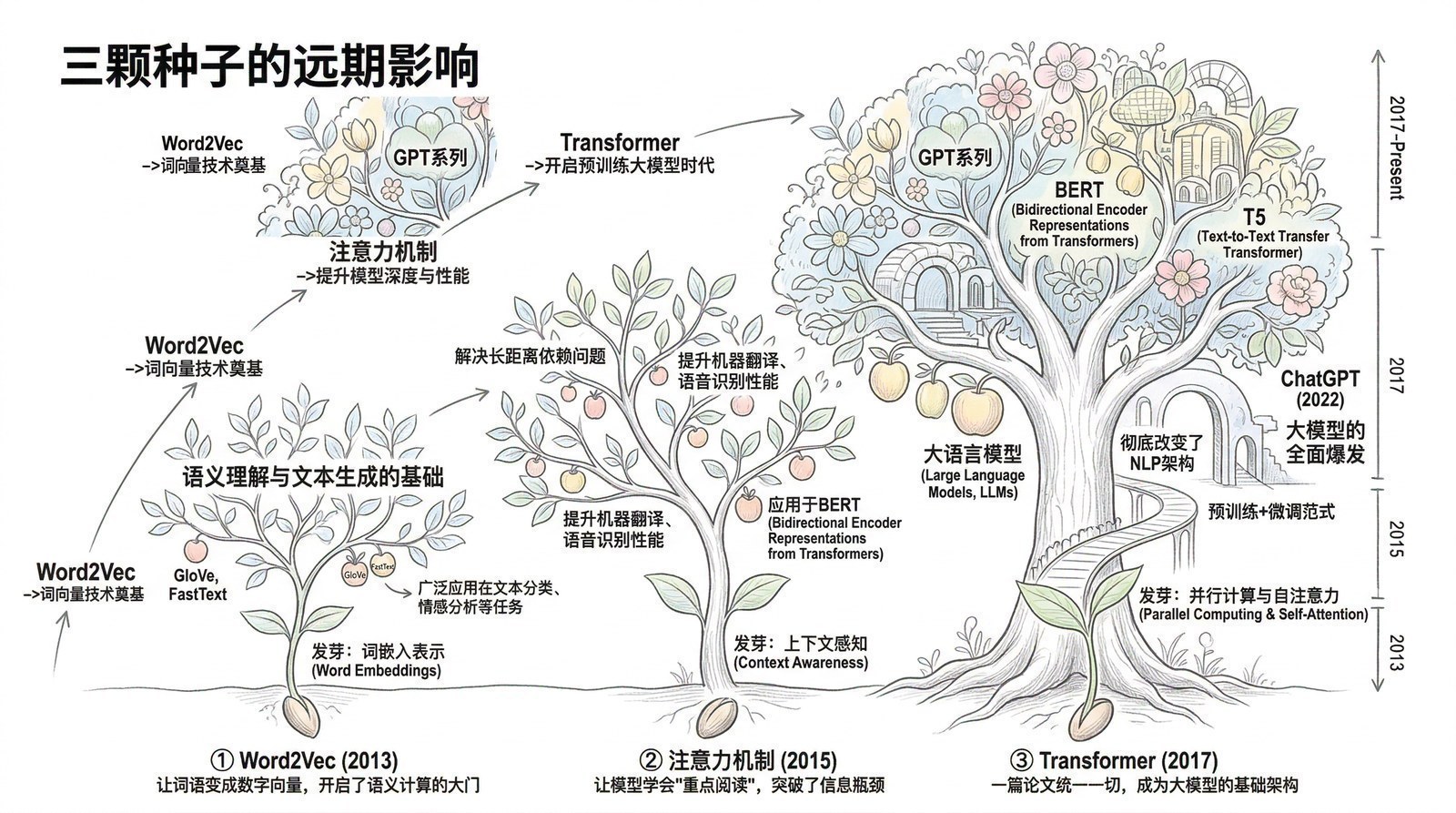
种子一:注意力机制——后来一切的起点。 Bahdanau在2015年种下的那颗种子,两年后长成了Transformer,再后来成为GPT、BERT、CLIP乃至整个大模型时代的核心基础设施。
种子二:Seq2Seq + 词向量——大模型的DNA。 今天的大模型至少携带着三段来自这个时代的"基因":Word2Vec开创的"用预测学习语义"的训练范式、Seq2Seq建立的编码器-解码器框架、GNMT定型的子词分词方法。理解了这三件事,就理解了大模型最底层的工作原理。
种子三:算力是技术进步的"隐形台阶"。 Word2Vec可以在普通服务器上训练,Seq2Seq需要多块GPU,GNMT需要TPU集群。每一步技术进步都在要求更大的算力——而RNN因为无法并行,在算力利用上碰到了天花板。这条"技术与算力协同进化"的螺旋将在第三章完整展开。
种子四:技术与商业的互补才能走得远。 无论是Google翻译靠GNMT实现产品质变,还是科大讯飞靠教育考试站稳脚跟,还是李志飞靠智能硬件找到独特定位——成功的AI公司无一例外都在"技术能做什么"和"市场需要什么"之间找到了交汇点。
回到2016年那个11月的深夜。当全球数亿用户在不知不觉中用上了更好的翻译时,很少有人意识到:让这一切成为可能的注意力机制,其实是一种比翻译本身深远得多的发明。
它本质上是在说:处理信息时,不需要从头到尾按顺序看每一个元素。你可以直接跳到最重要的部分。
一年后,Google的一个八人小组把这个想法推到了逻辑上的极端:如果注意力这么好用,为什么不全部用注意力?
他们给论文起了一个霸气的标题:Attention Is All You Need。
但在那之前,还有一个故事需要讲——是什么样的硬件进化,让这些越来越大的模型有了生存的土壤?
本章引用论文
[1] Efficient Estimation of Word Representations in Vector Space (Word2Vec), 2013, Google (Mikolov, Chen, Corrado, Dean)
[2] Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation, 2014, Montreal (Cho et al.)
[3] Sequence to Sequence Learning with Neural Networks (Seq2Seq), 2014, Google (Sutskever, Vinyals, Le)
[4] On the Properties of Neural Machine Translation: Encoder-Decoder Approaches, 2014, Montreal (Cho et al.)
[5] Neural Machine Translation by Jointly Learning to Align and Translate (Bahdanau Attention), 2015, Montreal (Bahdanau, Cho, Bengio)
[6] Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation (GNMT), 2016, Google (Wu et al.)
第三章:算力底座——从游戏显卡到AI超级计算机
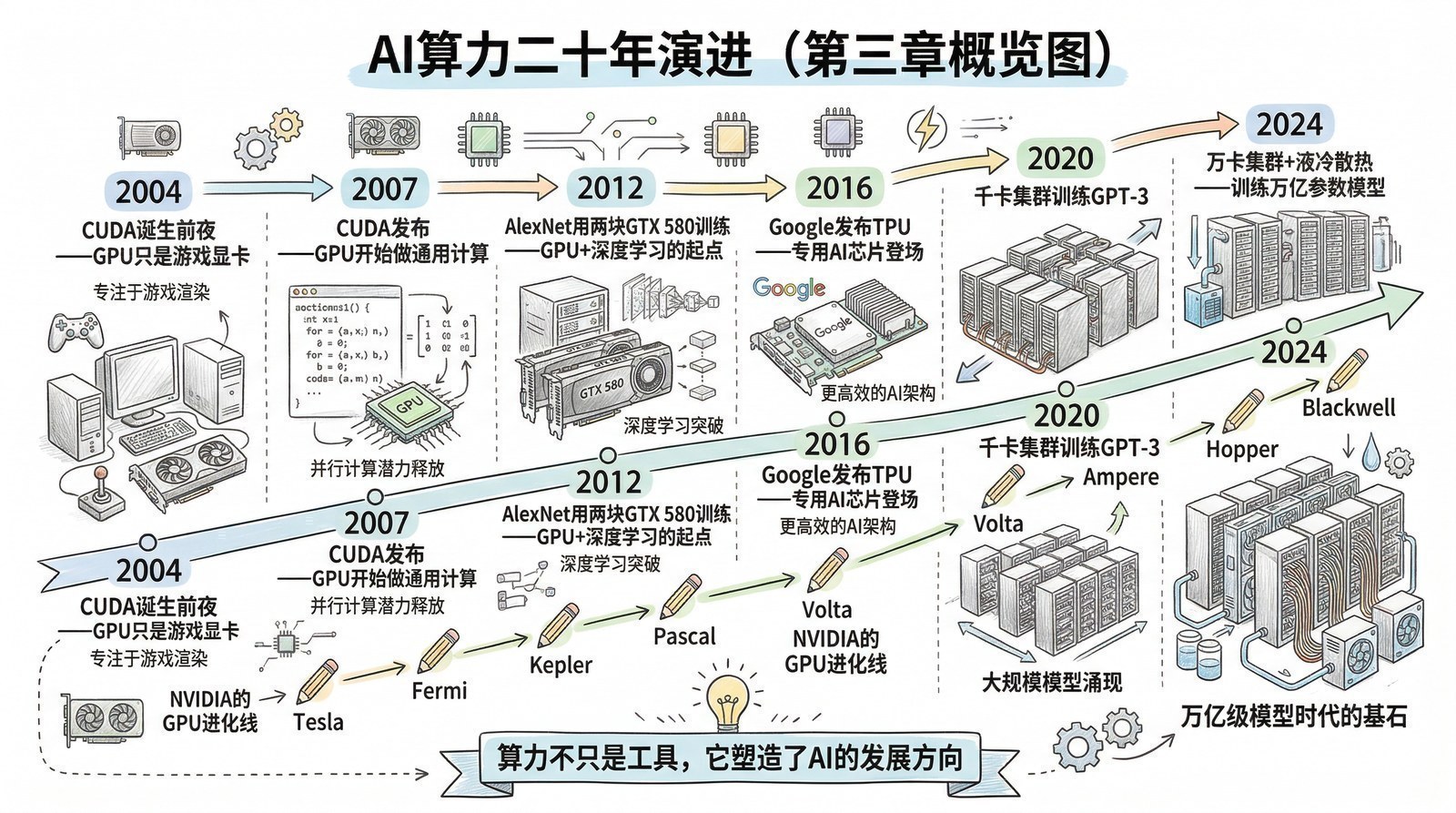
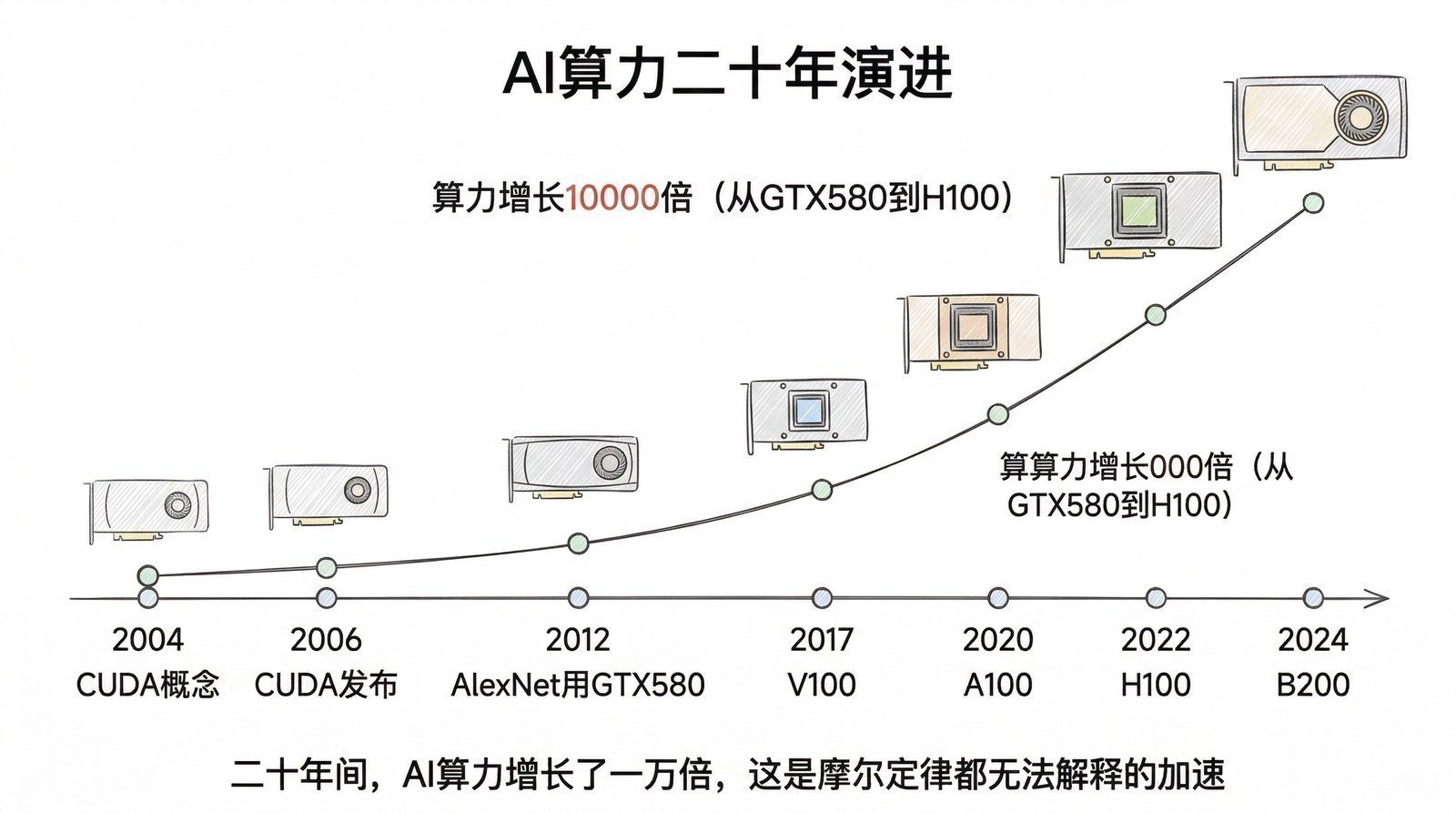
一块"错配"的芯片
2012年AlexNet横扫ImageNet竞赛的时候(第一章),它用的训练硬件是两块NVIDIA GTX 580——零售价499美元、为游戏玩家设计的消费级显卡,每块只有1.5GB显存,总共3GB。
2024年,训练一个前沿大模型(如GPT-4级别)需要什么?上万块NVIDIA H100 GPU,每块售价约3万美元,总投资数亿甚至数十亿美元。一个H100 GPU集群的年电费账单就要几千万美元。
从两块500美元的游戏显卡到价值数十亿美元的AI超级计算机,中间只隔了12年。这12年间究竟发生了什么?
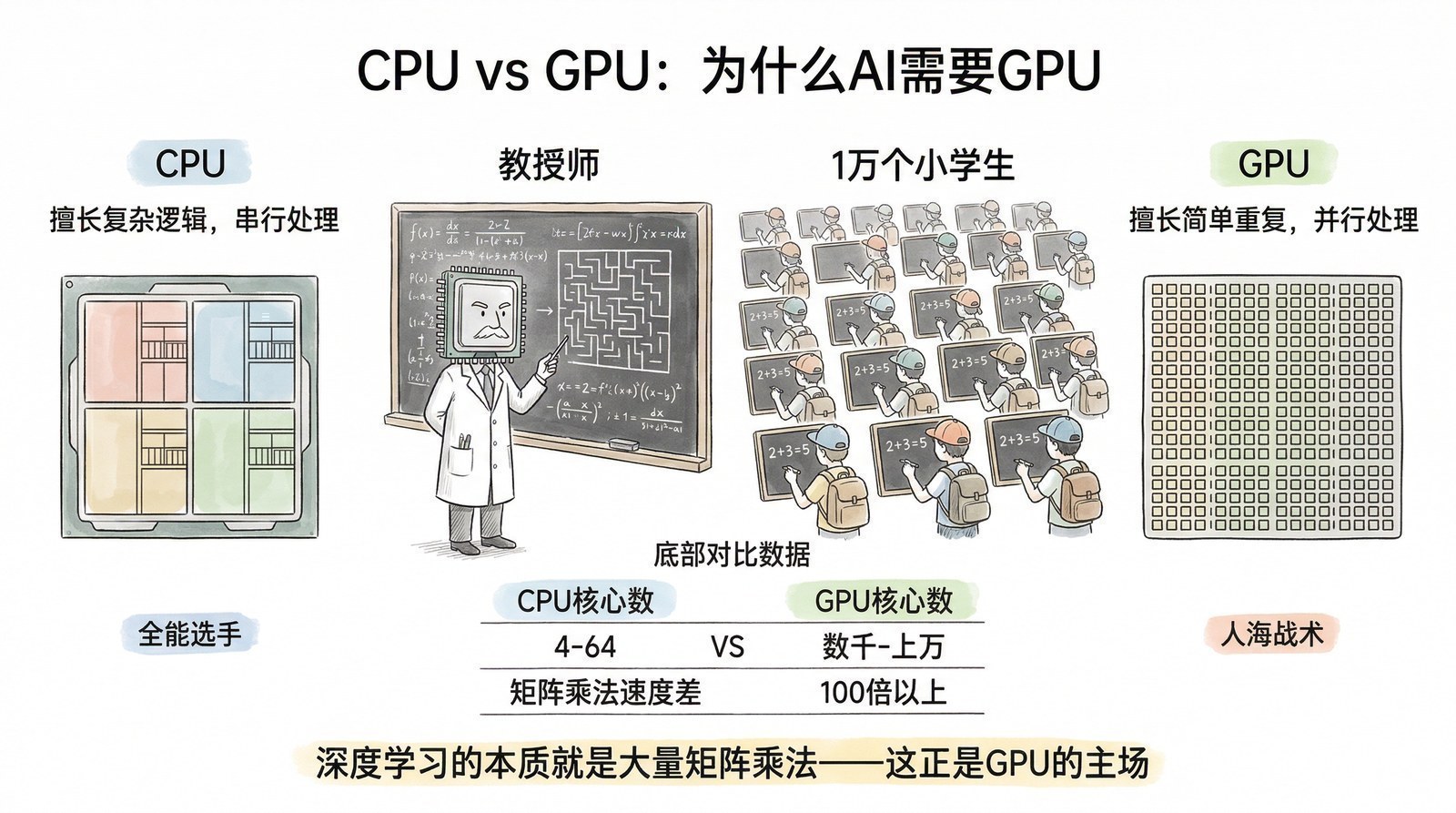
答案藏在一个反直觉的事实中:AI的爆发,最初不是因为有人专门为AI设计了芯片,而是因为一种为渲染游戏画面设计的芯片,恰好适合做AI需要的数学运算。 GPU被设计来渲染像素,每帧画面有几百万个像素需要独立计算颜色和亮度,GPU因此拥有数千个可以同时并行工作的计算核心。而训练神经网络的核心运算恰好也是大规模并行的矩阵乘法。渲染像素和训练神经网络,在数学层面上惊人地相似。
从游戏到科学:GPU通用计算的诞生
2004年之前,GPU只能做一件事:画图。如果你想用GPU做矩阵乘法,你必须把运算伪装成"给图片上色"的图形操作——荒谬但真实。
2004年,Stanford大学的Ian Buck等人发表了Brook for GPUs[1],第一次系统性地证明GPU可以高效执行通用计算。Ian Buck随后加入NVIDIA,主导开发了CUDA(Compute Unified Device Architecture)——2007年2月正式发布。CUDA让任何程序员都可以用类似C/C++的语言编写GPU程序,不再需要伪装成图形操作。
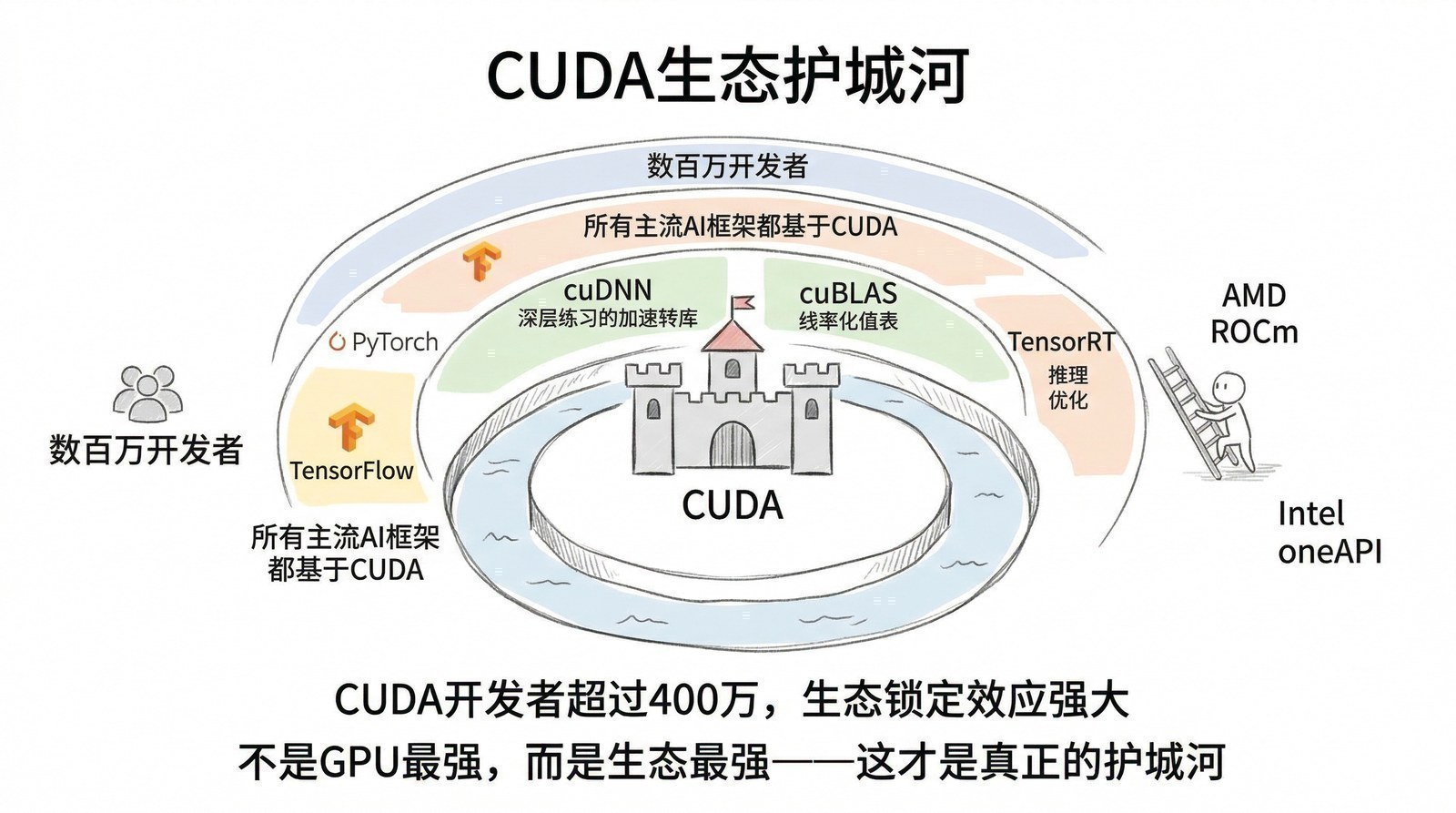
CUDA的重要性怎么强调都不为过。 它不是一块硬件,但可能是AI时代最重要的软件基础设施。后来NVIDIA在AI芯片市场占据超过80%的份额,CUDA建立的软件生态是最深的护城河——比任何一块芯片都更难被替代。
一段亲历者的记忆:CUDA 1.0的蛮荒时代
我(作者)在2008年左右就接触了第一代CUDA产品——用的是8800 Ultra(基于2006年发布的G80 Tesla架构,NVIDIA第一款统一着色器GPU)和CUDA 1.0工具链。那时候我们已经看中了GPU通用计算的巨大潜力,在本科期间就用CUDA做过人脸识别算法、信号处理算法、遗传算法的加速,性能提升效果都非常好——有些任务比CPU快了几十倍。
但那时候的CUDA开发体验极其痛苦。一方面,并行算法本身就不好写——把串行算法改成能在几百个核心上同时跑的并行版本,需要彻底重新设计计算流程。另一方面,CUDA的软硬件工具链极其不成熟:debugger几乎不存在,性能profiler非常原始,内存对齐、线程同步、bank conflict这些问题全靠经验排查。改一行代码性能可能差十倍,但你根本定位不了问题出在哪。
更关键的是,2008-2010年间深度学习还没有爆发,我们拿着CUDA的高算力找不到真正大规模的应用场景。后来移动互联网来了,Android来了,那才是当时最大的浪潮,我们也就逐渐从CUDA转向了Android开发。
后来我和本科期间的导师交流,他说如果你能再坚持两年左右对CUDA的投入,AlexNet就来了(2012年),深度学习就爆发了,CUDA的最大应用场景也就来了——我们本来可能成为第一代用CUDA加速深度学习和神经网络的团队之一。因为时至今日,开发和调优CUDA算子仍然是各个AI公司最头疼的事情,没有之一。但历史没有那么多如果——这段经历让我切身体会到:技术的价值不取决于它本身有多先进,而取决于它能否在正确的时间遇上正确的应用场景。
NVIDIA GPU进化史:八代架构,从游戏到AI的蜕变
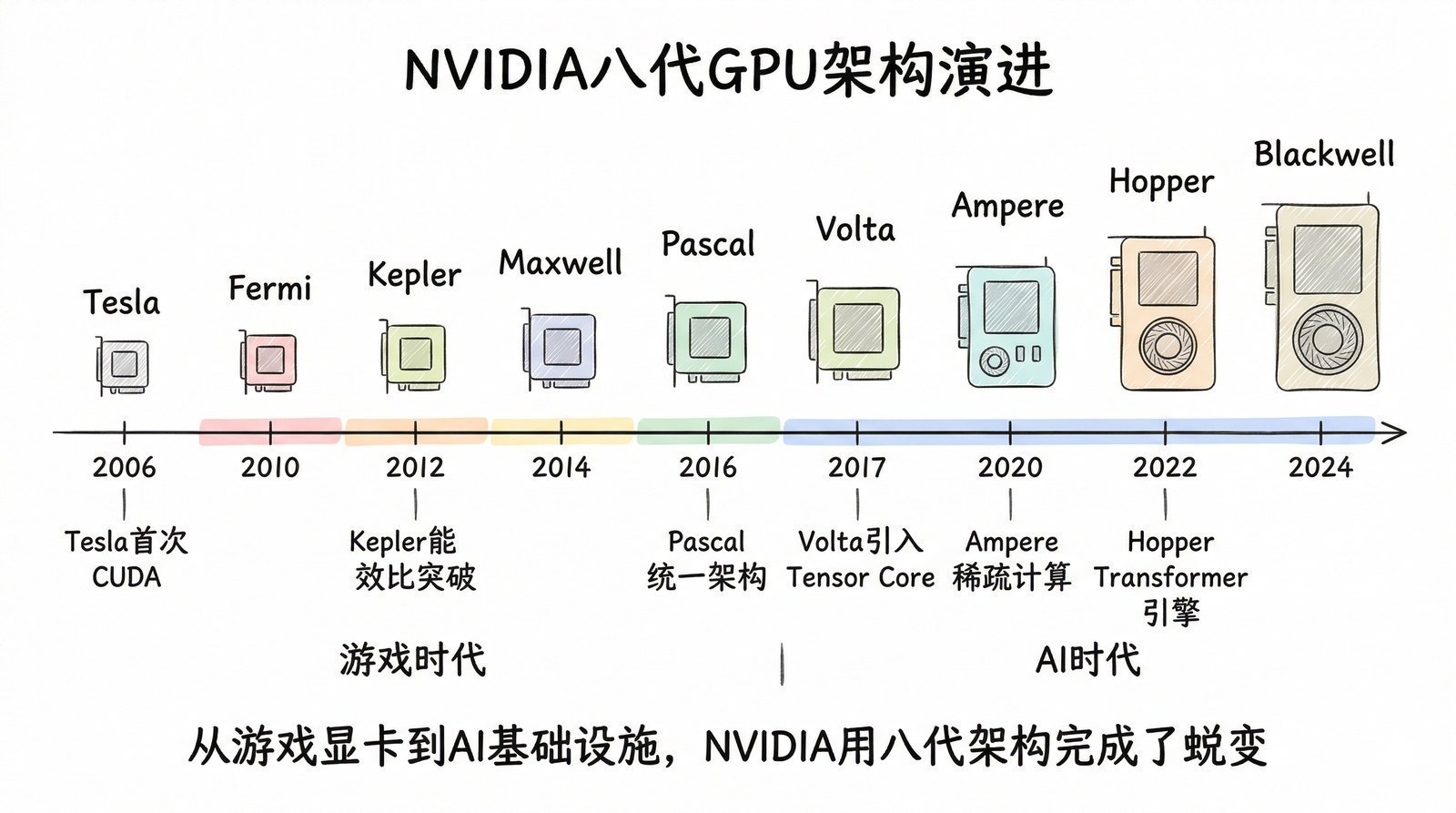
早期探索(2006-2012)
2006年:Tesla架构(G80/GeForce 8800)——第一代CUDA GPU
2006年11月,NVIDIA发布了GeForce 8800 GTX,基于全新的Tesla架构(以发明家尼古拉·特斯拉命名)。G80是NVIDIA第一款统一着色器架构——把之前分开的顶点处理器和像素处理器合并成128个统一的流处理器(Stream Processor),既能渲染图形也能做通用计算。G80拥有约6.81亿个晶体管,是当时最大的商用GPU芯片。搭配2007年发布的CUDA 1.0,G80成为第一款真正可以编程做通用并行计算的GPU。
2010年:Fermi架构——GPU通用计算走向成熟
Fermi架构(GTX 480/580)是GPU从"能做通用计算"到"好用的通用计算平台"的关键一步。它引入了L1/L2缓存层次结构、首次支持ECC纠错内存(让GPU可以用于科学计算等对精度要求高的场景)、支持完整的C++编程。AlexNet用的GTX 580正是Fermi架构——两块GTX 580、总共3GB显存,训练了6天,改变了AI的历史。
深度学习时代(2012-2020)
2012年:Kepler架构(K80)——学术界的主力,24GB显存(双GPU),训练了Word2Vec[第二章]、VGGNet、ResNet[第一章]等经典模型。但K80没有任何AI专用硬件,训练深度网络纯靠通用浮点运算的暴力堆叠。
2016年:Pascal架构(P100)——第一款明确面向深度学习优化的GPU。引入FP16半精度浮点支持(训练神经网络不需要32位高精度,16位就够了,速度翻倍),搭载HBM2高带宽内存(16GB,带宽732GB/s)。P100是GNMT[第二章]训练的主力硬件。
2017年:Volta架构(V100)——分水岭
V100首次引入Tensor Core——专门为矩阵乘法设计的计算单元。普通CUDA核心一次做一个浮点乘法,一个Tensor Core一次做一个4×4的FP16矩阵乘法并用FP32累加,相当于64次乘加运算。V100有640个Tensor Core,混合精度深度学习算力达到约125 TFLOPS——成为第一款突破100 TFLOPS深度学习性能的GPU。
V100是Transformer(第四章)诞生时的主力硬件——自注意力的大规模矩阵乘法恰好是Tensor Core最擅长的运算。技术创新和硬件进化在这里完美同步了。
2020年:Ampere架构(A100)——第三代Tensor Core,引入TF32/BF16格式、结构化稀疏(自动跳过零值计算,有效算力翻倍)、MIG分区(一块A100可划分为7个独立GPU实例)。AI算力312 TFLOPS。虽然GPT-3(2020年)是在10,000块V100上训练的,但A100发布后迅速成为大模型训练的标配——此后的GPT-3.5、BLOOM、LLaMA等模型都以A100为主力。
大模型时代(2022-2025)
2022年:Hopper架构(H100)——针对Transformer做了深度优化。Transformer Engine自动在FP8/FP16精度间切换:大部分计算用低精度FP8够了,关键步骤切到FP16。训练速度比A100快约4.5倍。FP16算力约990 TFLOPS。2023年全球"一卡难求"的主角。
2024年:Blackwell架构(B200)——双芯片封装设计,192GB HBM3e(带宽8TB/s),FP16算力约2250 TFLOPS,首次支持FP4。GB200 NVL72机柜系统72块GPU通过第五代NVLink互连,推理性能宣称是H100的30倍。
不只是芯片:NVLink与多卡互联的进化
单块GPU的算力提升只是故事的一半。大模型训练需要几千块GPU协同工作,GPU之间的通信速度往往比GPU本身的计算速度更关键——如果数据在GPU之间搬运的速度跟不上计算速度,再快的芯片也只能在等待中空转。NVIDIA很早就意识到了这一点,从2016年起同步推进了一条平行的技术线:GPU间高速互连。
NVLink 1.0(2016年,Pascal P100)——NVIDIA自研的GPU-to-GPU高速链路,双向带宽160GB/s,是当时PCIe 3.0(双向约32GB/s)的5倍。这是NVIDIA第一次绕开通用的PCIe总线,为GPU之间建立"专线高速公路"。NVLink让同一台服务器内的多块GPU可以高效共享数据,是后来所有多卡并行训练的基础。
NVLink 2.0(2017年,Volta V100)——带宽提升到300GB/s,同时支持GPU和CPU之间的高速连接。8块V100通过NVLink组成的DGX-1成为当时最强的AI训练节点。
NVLink 3.0(2020年,Ampere A100)+ NVSwitch——NVLink带宽提升到600GB/s。更重要的是引入了NVSwitch芯片——一种专用的GPU交换芯片,让8块A100可以实现全对全(all-to-all)互连,任意两块GPU之间都有600GB/s的直连带宽。在此之前,8块GPU的NVLink连接是"环形"或"网格"拓扑,不是所有GPU之间都能直连。NVSwitch让GPU集群在逻辑上更像一块"超级GPU"。
NVLink 4.0(2022年,Hopper H100)——单GPU带宽提升到900GB/s。通过NVSwitch,最多256块H100可以在一个"SuperPOD"中实现高速互联。这个规模已经足够训练百亿参数级别的模型。
NVLink 5.0 + NVL72(2024年,Blackwell B200)——这是最激进的一步。72块B200 GPU通过第五代NVLink和NVSwitch连接在一个机柜内,形成一个巨大的统一计算节点——GB200 NVL72。72块GPU之间的总互联带宽达到130TB/s,几乎可以当作一块拥有13.8TB显存的"超级GPU"来使用。这种机柜级的一体化设计,让模型不需要跨节点通信就能利用72块GPU的全部算力——而跨节点通信恰恰是大模型训练中最大的效率损耗点。
跨节点互联:InfiniBand与以太网——NVLink解决的是"同一台服务器内"GPU之间的通信,但训练万卡级集群还需要"服务器与服务器之间"的高速网络。这里的主力是InfiniBand——一种专为高性能计算设计的网络协议,单端口带宽从2020年的200Gb/s发展到2024年的400Gb/s(NDR)和800Gb/s(XDR)。NVIDIA在2019年以69亿美元收购了InfiniBand的主要供应商Mellanox Technologies——这笔收购让NVIDIA同时掌控了"计算"(GPU)和"通信"(网络),成为AI基础设施的全栈供应商。
这条互联技术线的进化速度丝毫不逊于芯片本身——从2016年NVLink 1.0的160GB/s到2024年NVL72的130TB/s总带宽,八年间提升了约800倍。芯片决定了每块GPU能算多快,互联决定了一万块GPU能不能真的像一块GPU一样协同工作。 大模型训练的瓶颈,往往不在计算而在通信。NVIDIA之所以能在大模型时代独占鳌头,不仅因为它有最快的芯片,更因为它同时拥有最快的互联——从NVLink到NVSwitch到InfiniBand,构建了一个从芯片到机柜到数据中心的完整算力系统。
从2006年的G80到2024年的B200+NVL72,这不仅是十八年间单块GPU算力提升数百倍的故事,更是从"一块孤立的芯片"进化到"万卡协同的超级计算机"的系统工程故事。
不只是芯片:NVIDIA的互连进化同样关键
单块GPU的算力提升只是故事的一半。大模型训练需要成百上千块GPU协同工作,GPU之间的通信速度往往比单GPU性能更能决定训练效率。如果GPU之间交换数据的速度跟不上计算速度,大量时间就浪费在"等待通信"上——这就是所谓的"通信墙"。NVIDIA在互连技术上的持续投入,和芯片本身的进化同样重要。
NVLink:GPU之间的"高速公路"。 传统的PCIe总线带宽有限(PCIe 3.0约32GB/s),成为多GPU训练的瓶颈。2016年NVIDIA随P100推出了第一代NVLink,GPU间直连带宽达到160GB/s,是PCIe的5倍。此后每代NVLink都在翻倍:V100的NVLink 2.0达到300GB/s,A100的NVLink 3.0达到600GB/s,H100的NVLink 4.0达到900GB/s。到Blackwell的第五代NVLink,单GPU双向带宽达到1.8TB/s。NVLink让同一台服务器内的8块GPU可以像"一块大GPU"一样高效协作。
NVSwitch:从8卡到更大规模的桥梁。 NVLink解决了单台服务器内8块GPU的互连,但大模型训练需要跨服务器。NVIDIA在2018年推出NVSwitch芯片,作为GPU之间的"交换机",让一台DGX服务器内8块GPU实现全对全(all-to-all)的满速通信。H100时代的NVSwitch升级到第三代,支持在一个机柜内连接更多GPU。到了Blackwell的NVL72架构,NVSwitch更进一步——72块GPU通过NVSwitch组成一个巨大的统一内存域,所有GPU可以直接访问彼此的显存,仿佛72块GPU是一块拥有13.8TB显存的"超级GPU"。
InfiniBand:跨服务器的"神经系统"。 当训练规模扩展到数千块GPU、分布在数百台服务器上时,服务器之间需要更高速的网络。NVIDIA在2020年收购了InfiniBand网络的领导者Mellanox,获得了ConnectX网卡和Quantum交换机系列。InfiniBand的延迟比以太网低一个数量级,带宽从HDR(200Gb/s)到NDR(400Gb/s)再到XDR(800Gb/s)持续翻倍。Meta训练LLaMA 3.1用的万卡集群、OpenAI训练GPT-4用的超级计算机,骨干网络都是InfiniBand。
从"卖芯片"到"卖系统"。 NVIDIA的商业模式也随之进化——从单独卖GPU芯片,到卖DGX整机(8块GPU+NVLink+NVSwitch+网络),再到卖SuperPOD(数百块GPU的完整集群方案),再到GB200 NVL72这样的机柜级系统。芯片、互连、网络、软件栈被打包成一体化解决方案。这种"全栈交付"策略让客户更容易部署,也让NVIDIA的护城河从单一的芯片层延伸到了整个系统层。
算力是一个系统工程,不只是一块芯片。 这个道理在大模型时代被反复验证:一块H100的算力再强,如果GPU之间的通信跟不上,训练效率可能还不如一群通信高效的较弱芯片。NVIDIA之所以能在AI算力市场占据主导地位,不仅因为它的GPU最快,更因为它构建了从芯片到互连到网络到软件的完整体系——而这个体系的每一个环节都在同步进化。
Google TPU:另一条路——从推理到训练,软硬件一体的十年进化
NVIDIA沿"通用GPU→AI专用GPU"路线迭代,Google则从2013年开始走了一条完全不同的路——从零设计一款只做AI计算的芯片。这个决定的背后有一个很现实的驱动力:2013年Google内部评估发现,如果用户每天对着手机用语音搜索说话三分钟,那么用当时的CPU来做语音识别推理,需要把Google整个数据中心的服务器数量翻一倍[6]。这个成本完全不可接受。
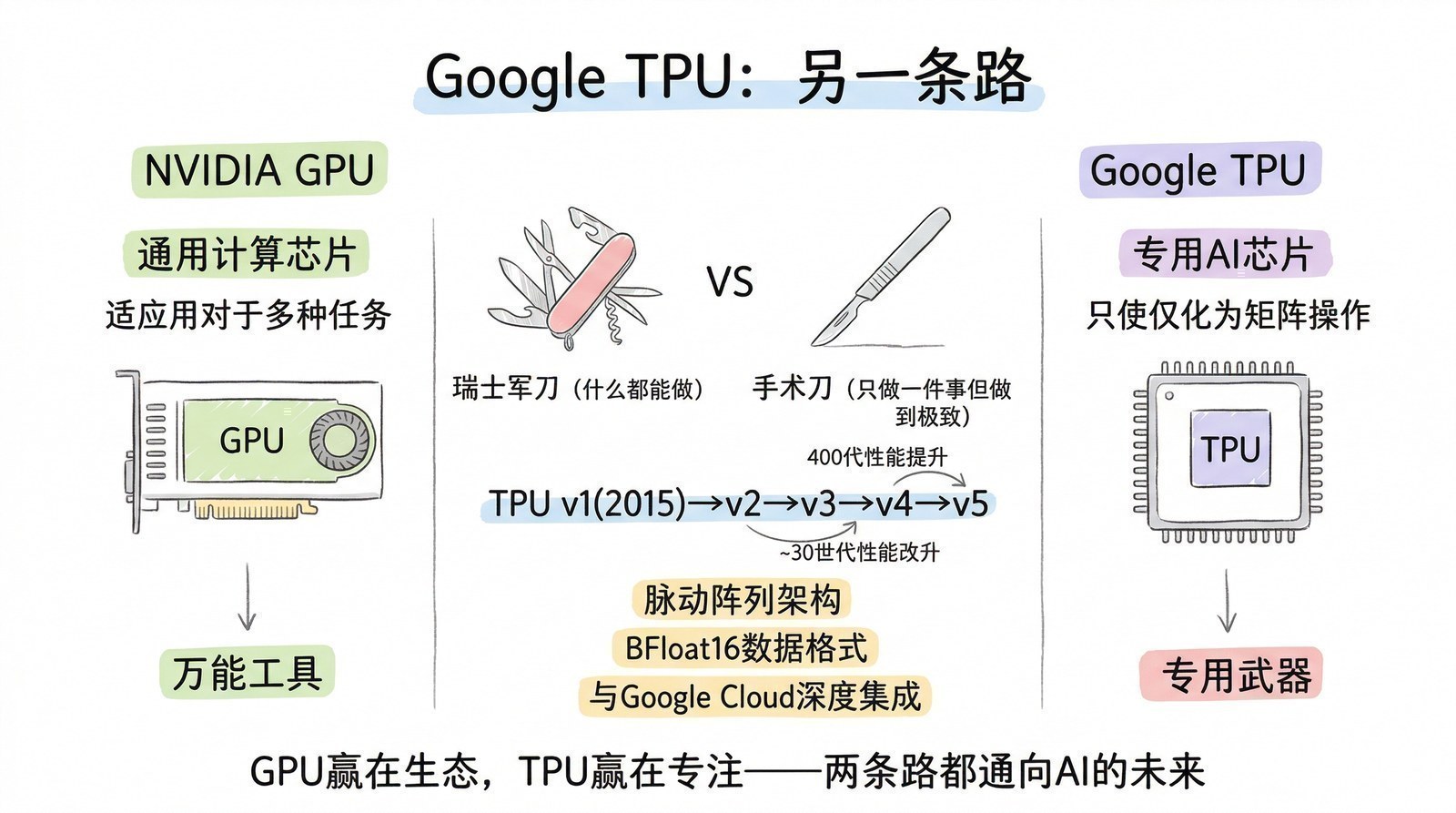
TPU v1(2015年内部部署,2017年ISCA论文[6])——推理专用,15个月从设计到上线
TPU v1的核心是一个256×256的8位整数脉动阵列(systolic array),峰值92 TOPS(每秒92万亿次整数运算),功耗仅75W。它只做推理、不做训练,设计极其简约——没有缓存层次、没有复杂的控制逻辑,就是一个巨大的矩阵乘法器。Google论文显示TPU v1比同期CPU快15-30倍,每瓦性能高30-80倍[6]。从设计到部署仅用15个月——Google内部的"快做完就好"原则让它在FPGA验证后迅速转为ASIC量产。
TPU v1解决的是推理成本问题——Google搜索、翻译、照片等服务背后海量的AI推理请求。但它不能训练模型,这限制了它的用途。
TPU v2(2017年)——第一次能训练,BF16格式影响全行业
TPU v2解决的核心问题是让TPU也能做训练。它引入了BF16(Brain Float 16)数据格式——保留了FP32的指数范围但缩减了尾数精度,在几乎不损失训练效果的前提下将算力翻倍[7]。BF16后来被全行业采纳,包括NVIDIA的A100和H100。
更重要的创新是芯片间自定义互连(ICI)。之前的加速器靠以太网或InfiniBand做多芯片通信,延迟高、带宽低。Google为TPU v2设计了专用高速链路,每块TPU直连四个邻居,256块组成2D环面(torus)拓扑的Pod,总算力11 PFLOPS。这种"把多块芯片当一个大芯片用"的思路,为后来的万卡训练奠定了基础。
TPU v3(2018年)——水冷散热,训练了BERT
TPU v3把单芯片算力翻倍至123 TFLOPS BF16,代价是功耗飙升到450W。这迫使Google做出一个大胆的工程决策:从风冷改为水冷。每块TPU v3都需要液冷管路——这在当时的数据中心加速器中几乎没有先例。1024块组成的Pod总算力达到125 PFLOPS。Google用TPU v3训练了BERT(第五章),证明了TPU在Transformer训练上的竞争力[7]。
TPU v4(2021年,2023年ISCA论文[8])——光交换互连,超越A100
TPU v4是Google最大的架构跳跃。每块芯片275 TFLOPS BF16,4096块组成Pod——但最革命性的创新是光路交换互连(OCS):Pod内部的芯片间通信不再走固定的电路拓扑,而是通过光交换机动态重新配置连接。这意味着网络拓扑可以按需调整——训练不同模型时,芯片之间的连接方式可以重新组合,大幅提高了通信效率和容错能力。论文显示TPU v4 Pod(4096块)比同规模的A100集群快5%-87%,同时功耗更低[8]。Google用TPU v4训练了PaLM(5400亿参数)等大模型。
TPU v5p(2023年)及后续——8960块组成Pod,3D环面拓扑,总算力接近4.5 EFLOPS。训练了Gemini系列。2025年Google发布了TPU v7(代号Ironwood),单芯片算力达4614 TFLOPS,继续在效率上追求极致。
TPU的独特价值和局限
Google是全球唯一实现AI全栈自研的公司——从芯片(TPU)到编译器(XLA)到框架(JAX/TensorFlow)到模型(BERT/PaLM/Gemini)到产品(搜索/翻译/Gmail)。这种垂直整合让软件团队可以直接向硬件团队反馈需求——比如发现BF16对训练够用后直接在下一代芯片里做原生支持——形成"模型需求→芯片设计→软件优化→模型提升"的闭环。十年间TPU的峰值性能提升了约100倍,但软硬件协同带来的实际效率提升远超纸面数字。
TPU的最大局限是生态封闭——只能通过Google Cloud使用,不能购买硬件,软件栈和CUDA不兼容。这让大多数AI公司和研究者无法使用TPU,客观上限制了它的产业影响力。
而TPU和中国AI芯片之间,有一条鲜为人知但极其重要的学术渊源。Google TPU v1论文的参考文献中,有6篇来自同一个中国团队——中科院计算所的陈云霁、陈天石兄弟。更耐人寻味的是,与陈氏兄弟合作发表这些论文的法国学者Olivier Temam,后来加入了Google,参与了TPU的后续研发。这意味着:全球最重要的两条AI芯片路线——Google TPU和中国寒武纪——在学术源头上共享着同一批开创性的工作。 这个故事,我们留到本章"中国算力之战"一节详细展开。
光有芯片不够:分布式训练的艺术
一块GPU再强,也撑不起一个真正的大模型。
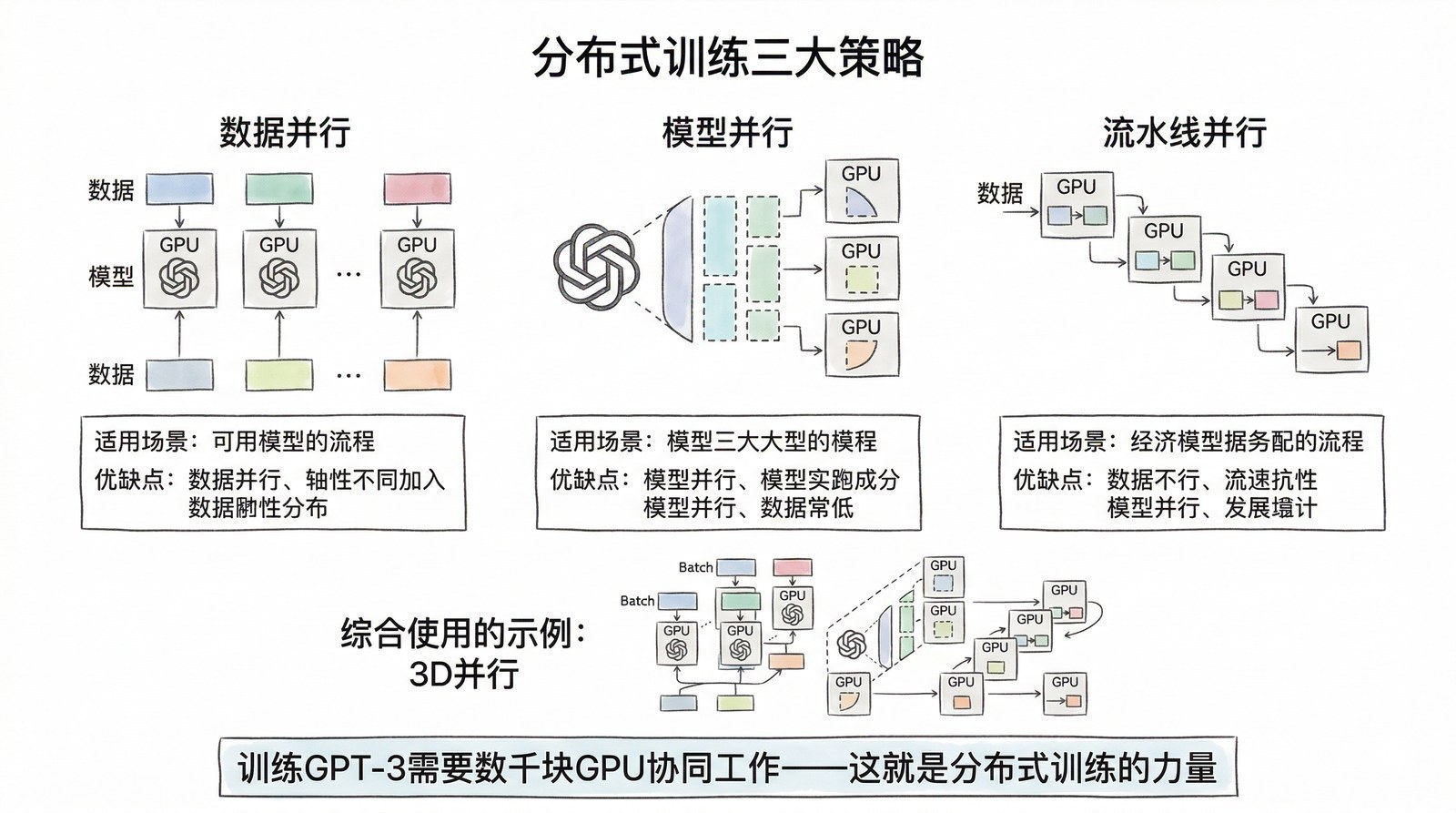
GPT-3有1750亿个参数。即使用FP16(每个参数2字节),模型本身就要占350GB显存——远超任何单块GPU。而训练过程中产生的中间数据更加庞大:每个参数需要存储梯度(2字节)、优化器的一阶动量(4字节)和二阶动量(4字节),光是Adam优化器的状态就要占模型大小的6倍以上。一个1750亿参数的模型,训练时的总内存需求可以达到2-3TB。
这意味着训练大模型必须把计算分摊到成百上千块GPU上。但"分给1000块GPU"远不是简单的除以1000——中间有一系列深刻的工程挑战。2014-2019年间,研究者们发明了几种互补的并行策略,每一种都解决了上一种解决不了的问题。
数据并行:最朴素但最有力的起点
最简单的思路:每块GPU放一份完整的模型副本,但各自处理不同的训练数据。每处理完一批数据,所有GPU交换梯度信息,取平均后更新模型——确保所有副本保持同步。
2014年,Google的Jeffrey Dean等人发表了Parameter Server[2],建立了数据并行的标准架构——一组"参数服务器"集中管理模型参数,多个"工人节点"分头计算梯度再发回汇总。这个框架之所以在2014年出现,是因为深度学习模型的规模(几千万到上亿参数)已经超过了单机训练的效率极限,但还没有大到单块GPU装不下——数据并行的前提是每块GPU能装下完整模型。
数据并行的优势是简单、通用、扩展性好——加更多GPU就能处理更多数据,训练更快。但它有一个根本局限:当模型大到一块GPU装不下的时候,就行不通了。2019年GPT-2(15亿参数)还勉强能塞进一块V100(32GB显存),但2020年GPT-3(1750亿参数)无论如何都装不下——模型本身就需要被"切开"。
流水线并行:把模型按层切开
2018年,Google提出GPipe[3],把模型的不同层放在不同GPU上。数据像工厂流水线一样依次经过各个GPU:第一块GPU处理完第一层,结果传给第二块处理第二层,同时第一块开始处理下一批数据的第一层。
GPipe之所以在2018年出现,是因为研究者开始尝试训练几十亿参数级别的模型(如AmoebaNet-B,5.57亿参数),这些模型的层数已经多到需要跨多块GPU存放。GPipe解决了"模型太深、单GPU放不下所有层"的问题。
但流水线并行有一个著名的效率问题:pipeline bubble(流水线气泡)。当第一块GPU在处理最后一批数据时,后面的GPU还在等中间结果——流水线的开头和结尾会有大量GPU处于空闲状态。GPipe通过把每批数据切成更小的micro-batch来缓解这个问题,但无法完全消除。
张量并行:在单层内部切开矩阵
流水线并行解决了"层与层之间"的分配问题。但如果单个层本身就太大呢?一个GPT-3规模模型的单个Transformer层,其中的矩阵乘法操作就可能需要几十GB的显存。
2019年,NVIDIA提出Megatron-LM[4],将单层内的矩阵运算切分到多块GPU上。一个巨大的矩阵乘法被拆成多个小矩阵乘法,分别在不同GPU上执行,结果再拼回来。这种方式打破了"一层必须在一块GPU上"的限制。
Megatron-LM之所以在2019年出现而不是更早,有两个原因:一是V100的NVLink高速互连让GPU之间的数据交换足够快(张量并行需要频繁的GPU间通信,如果通信慢则效率崩溃),二是Transformer的矩阵结构天然适合沿行或列均匀切分。Megatron-LM在NVIDIA DGX SuperPOD上把模型扩展到83亿参数,其方法论被后来几乎所有大模型训练采用。
张量并行的局限是通信开销:切分越细,GPU之间需要交换的数据越多。当扩展到数十块GPU以上时,通信开销会侵蚀计算效率。因此张量并行通常在8-16块GPU的"节点内"使用,跨节点则用其他并行方式。
ZeRO:换一个角度——不切计算,切存储
前面三种方法都在切分"计算"。2019年微软DeepSpeed团队的ZeRO(Zero Redundancy Optimizer)[5]换了一个角度:不切分模型的计算,而是切分模型的存储。
在传统数据并行中,每块GPU都完整存储模型参数、梯度和优化器状态——这是巨大的冗余。如果有1000块GPU,同一份模型就被存了1000份。ZeRO的核心洞见是:这些数据不需要每块GPU都存一份,可以分散存储,需要的时候再临时通信获取。
ZeRO分三个阶段逐步消除冗余:ZeRO-1分散优化器状态(节省约4倍内存),ZeRO-2再分散梯度(节省约8倍),ZeRO-3连模型参数都分散(理论上可线性扩展到任意规模)。代价是增加了通信——但通过精心设计通信调度,与计算重叠,实际性能损失很小。
ZeRO的影响是革命性的:它让研究者可以在相对较少的GPU上训练远超GPU显存的大模型。但它也有边界——当模型规模大到通信量超过计算量时,效率会下降。因此大规模训练通常把ZeRO和其他并行方式组合使用。
"3D并行":今天的标准配方
今天训练千亿参数级模型的标准做法是"3D并行"——数据并行(扩展数据吞吐量)+ 张量并行(切分单层计算,节点内)+ 流水线并行(切分跨层计算,节点间),外加ZeRO的内存优化。这个组合让从GPT-3到GPT-4到DeepSeek-V3的大模型训练成为可能。
每一种并行技术的出现都不是偶然的——它们各自回答了模型规模增长过程中遇到的不同瓶颈问题,而它们的局限又推动了下一种技术的发明。这正是算力领域"需求驱动创新,创新使能更大需求"的典型螺旋。
产品与公司聚光灯
NVIDIA:卖铲子的人赢了淘金热
(1) DGX-1(2016年) — NVIDIA第一台"AI超级计算机",搭载8块P100,AI算力约170 TFLOPS。黄仁勋亲手把第一台交给了OpenAI,机箱上写"To the future of computing"。
(2) 市值破万亿(2023年5月) — 2024年中一度超3万亿美元,短暂成为全球市值最高公司。在淘金热中,最确定赚钱的是卖铲子的人。
(3) H100一卡难求(2023年) — Meta订购35万块,二手价超5万美元。NVIDIA 2024财年营收609亿美元,同比增126%。
Google TPU:十年磨一剑的另一条路
(4) TPU v1的"15个月奇迹"(2015年) — 从设计到部署仅15个月,立刻进入Google搜索、翻译、照片等核心服务。一款仅75W功耗的推理芯片,悄悄支撑着数十亿用户每天的AI请求。
(5) BF16格式的全行业影响 — TPU v2发明的BF16数据格式被NVIDIA(A100起)、AMD、Intel全面采纳,成为AI训练的事实标准。一家公司的芯片设计决策,改变了整个行业的数据表示方式。
寒武纪:用中文拼音命名芯片的中国先驱
(6) DianNao系列横扫顶会(2014-2016) — 陈氏兄弟的DianNao系列在ASPLOS、MICRO、ISCA上连获最佳论文,成为AI芯片领域引用最多的学术系列。合作者Olivier Temam后来加入Google,DianNao的学术思想影响了全球AI芯片方向。
(7) 寒武纪1A进入手机(2017年) — 被华为集成进麒麟970芯片,AI算力第一次进入消费级手机——每秒能识别约2000张图片。
华为昇腾:系统工程的极致
(8) CloudMatrix 384(2024-2025) — 384颗昇腾910C组成全对等超节点,总算力300 PFLOPS。当单芯片性能追不上NVIDIA时,用极致的互连和系统架构来弥补。黄仁勋说过"任何轻视华为的人都极其天真",CloudMatrix就是华为给出的回答。
中国算力之战:三条并行的追赶路线
第一条线:寒武纪——从学术论文到AI芯片的先驱
陈云霁和陈天石兄弟,先后考入中科大少年班,之后都进入中科院计算技术研究所。哥哥是处理器架构专家(参与"龙芯"设计),弟弟是数学出身研究机器学习。两人笑称自己是"全世界唯一用南昌话讨论计算机问题的"。
2010年,兄弟俩提出了一个当时看起来异想天开的想法:专门设计一种芯片来加速神经网络。那时连20万元的科研经费都申请不到,学生们直言是"虚无缥缈的研究"。
但他们坚持了下来。2014年,与法国INRIA的Olivier Temam教授合作发表的《DianNao》[9]获得ASPLOS 2014最佳论文奖——亚洲科研机构首次在体系结构顶会获此殊荣。同年12月续作《DaDianNao》[10]再获MICRO 2014最佳论文——打破该奖自1963年以来由美国垄断的历史。
此后团队连续发表了以中文拼音命名的系列论文,在国际学术界教老外说中文:
- DianNao(电脑,2014)[9]——第一个专用神经网络加速器架构,ASPLOS最佳论文
- DaDianNao(大电脑,2014)[10]——面向大规模神经网络的超级计算机架构,MICRO最佳论文
- PuDianNao(普电脑,2015)[11]——支持多种机器学习算法的通用加速器
- ShiDianNao(视电脑,2015)[12]——面向视觉处理、靠近传感器的加速器
- Cambricon(寒武纪指令集,2016)[13]——第一个神经网络专用指令集架构
- Cambricon-X(2016)[14]——面向稀疏神经网络的加速器
- Cambricon-F(2019)[15]——分形冯·诺依曼架构机器学习计算机
- Cambricon-Q(2020)[16]——高效训练的混合架构
- Cambricon-S(2024)[17]——面向神经场景表示的加速器
这个故事有一条和Google TPU的重要关联: 合作者Olivier Temam教授后来加入了Google。Google 2017年发表的TPU v1论文[6]全文引用了寒武纪团队6篇论文,并专门用一段文字回顾DianNao系列,提到DaDianNao、PuDianNao、ShiDianNao时还特意用英文注释其中文含义("Big computer, general computer, vision computer")——这在学术界是罕见的致敬。中国团队的开创性学术工作,通过人才和思想的流动,深刻影响了全球AI芯片的发展方向。
2016年陈天石创办寒武纪公司。2017年"寒武纪1A"处理器被华为集成进麒麟970手机芯片——AI算力第一次进入消费级手机。2020年科创板上市。此后发布思元系列数据中心芯片,持续追赶。
第二条线:华为昇腾——从达芬奇架构到CloudMatrix 384
华为2018年发布了自研的达芬奇AI计算架构和昇腾910芯片(FP16算力320 TFLOPS),宣告进入AI芯片赛道。达芬奇架构的核心是一个可伸缩的3D Cube计算单元,从端侧到云端使用统一的指令集,打通"训练-推理-端侧"全场景。
芯片禁令后,华为在2023年推出昇腾910B,成为"A100国产替代"的核心选项。多家国内大模型公司(包括华为自己的盘古大模型、百度文心、科大讯飞星火)已在昇腾上完成训练或适配。
CloudMatrix 384超节点是华为2024-2025年最引人注目的系统级突破。核心思路:单芯片性能追不上NVIDIA,那就用架构创新来弥补。 384颗昇腾910C NPU通过自研UB(Unified Bus)统一总线互连,组成逻辑上的"超级服务器"——全对等架构,384颗芯片之间可以直接通信,不需要经过CPU中转。超节点网络交换机使用6812个400G光模块实现高速互联,让几百颗芯片像一颗"超级芯片"一样协同工作。
对比NVIDIA GB200 NVL72(72块GPU):CloudMatrix 384总算力约300 PFLOPS(BF16),互联总带宽和内存总带宽均有显著提升。代价是功耗高数倍——因为用了5倍多的芯片来"堆"算力。华为的逻辑很直接:当单芯片制程受限时,通过极致的互连和软件调度,让大量芯片高效协同。任正非曾提过的"用数学补物理",在CloudMatrix上体现得淋漓尽致。
第三条线:制裁之后的全面突围
2022年10月美国芯片禁令的影响是双重的。短期冲击真实存在——A100/H100被禁,NVIDIA随后推出的"降速版"A800/H800也在2023年10月被封堵。据估计中国科技公司在禁令前紧急囤积了数十万块高端GPU,但库存终会消耗。
但长期来看,禁令意外地加速了中国AI算力的自主化:
芯片设计上,寒武纪思元系列、华为昇腾系列、海光DCU系列、百度昆仑芯片都在快速迭代。系统架构上,华为CloudMatrix 384和字节跳动MegaScale万卡集群展示了中国团队在系统工程上的实力。软件生态上,华为CANN计算框架和MindSpore深度学习框架正在逐步构建国产CUDA替代方案。
最深远的影响可能在算法效率上:算力受限倒逼了效率创新。DeepSeek-V3(第十三章)用远少于OpenAI的算力训练出了接近GPT-4水平的模型——当你拿不到最好的硬件时,就必须让算法跑得更聪明。
这场算力之战远未结束。EUV光刻机和先进制程代工仍被荷兰ASML和台积电主导,中国在制造环节的追赶需要更长时间。但在芯片设计、系统架构和软件生态上,追赶速度正在超出许多人的预期。
这二十年告诉我们什么
规律一:AI的每一次突破,背后都站着一次算力飞跃——但因果关系是双向的。
AlexNet需要GPU,Transformer需要Tensor Core,GPT-3需要万卡V100集群。表面上看是"有了更强的硬件,才有了更强的模型"。但反过来也成立:正是因为AlexNet证明了深度学习的巨大潜力,NVIDIA才下决心在V100中加入Tensor Core;正是因为Transformer让并行计算成为刚需,NVIDIA才在A100中加入TF32和结构化稀疏。模型的需求定义了芯片的方向,芯片的能力又解锁了新的模型可能性。 这是一个协同进化的螺旋,而不是单向的因果链。对从业者的启示是:判断下一代AI的方向,不仅要看模型论文,还要看芯片路线图——因为芯片厂商的设计选择,往往提前两三年预告了AI的发展方向。
规律二:软件生态的壁垒比硬件更深——这可能是AI产业最被低估的事实。
NVIDIA的芯片性能领先固然重要,但CUDA生态才是它真正的护城河。全球几乎所有深度学习框架(PyTorch、TensorFlow、JAX)都是基于CUDA开发的,数百万开发者的代码、经验、调优技巧、第三方库都建立在CUDA之上。AMD的MI300X在硬件性能上已经非常接近H100,价格更有竞争力,但市场份额仍然很小——因为开发者迁移的成本太高了。你不是在换一块芯片,你是在换整个软件栈、重新调优所有代码、重新训练工程团队。这个迁移成本可能比芯片本身的价格差更大。对中国AI芯片的启示同样深刻:华为昇腾面临的最大挑战不是做出一块性能达标的芯片(这已经接近做到了),而是建立一个让开发者愿意迁移过来的软件生态——这需要的不是两三年,而是五到十年的持续投入。
规律三:算力是系统工程,"木桶效应"决定最终效率。
一块H100的算力再强,如果GPU之间的通信速度跟不上(互连瓶颈)、显存装不下模型(内存瓶颈)、服务器散热不够(功耗瓶颈)、训练过程中一块GPU故障就要重启(容错瓶颈),整个系统的效率就会被最短的那块板拖累。NVIDIA的成功不仅在于GPU最快,更在于它构建了从芯片到NVLink到NVSwitch到InfiniBand到DGX到SuperPOD的完整体系。华为CloudMatrix 384的思路也是一样——当单芯片受限时,通过极致的互连和系统架构让384块芯片像一块"超级芯片"一样工作。对于从业者而言,选择AI基础设施时不能只看单卡TFLOPS——互连带宽、内存容量、软件栈成熟度、容错能力同样是关键指标。字节跳动的MegaScale之所以能实现万卡训练,不是因为用了最快的GPU,而是因为在容错和通信调度上做到了极致。
规律四:约束有时候是创新最好的催化剂——但前提是你有足够的底蕴来"被催化"。
芯片禁令催生了华为的全对等互连架构、DeepSeek的高效训练策略、国产软件栈的加速建设。当一条路被堵死时,人们确实会找到另一条路。但这里有一个容易被忽略的前提:华为之所以能在禁令后快速推出昇腾910B和CloudMatrix,是因为它在禁令之前已经有了多年的芯片设计积累和达芬奇架构。DeepSeek之所以能用有限算力训练出接近GPT-4的模型,是因为它的团队在算法效率上有深厚的研究功底。 约束催化创新,但不能凭空创造能力——它只能激发已有底蕴的快速释放。对从业者的启示是:真正的竞争力不在于你能否在顺境中跑得快,而在于你是否在逆境来临之前积累了足够的底蕴来"被催化"。
规律五:AI算力的竞争正在从"芯片竞赛"升级为"体系竞赛"。
2012年AlexNet时代,算力竞争的核心是单块GPU的性能。2020年GPT-3时代,竞争升级到了万卡集群的系统效率。到2025年,竞争已经进一步升级为包含芯片设计、互连网络、分布式软件、数据中心基建、能源供应在内的完整体系。一个前沿大模型的训练可能需要上万块GPU、消耗数百万度电、持续数月——这不再是一个技术问题,而是一个涉及工程、基建、能源、资本的系统问题。NVIDIA卖的不再是一块芯片,而是一个从硬件到软件的完整解决方案。Google建的不再是一个芯片,而是一个从芯片到编译器到框架到模型到产品的垂直体系。华为做的也不再是一块芯片,而是从达芬奇架构到CANN框架到MindSpore生态到CloudMatrix超节点的全链路。未来的AI算力竞争,将是体系与体系的较量,而不是芯片与芯片的比拼。
本章讲了AI算力的第二把钥匙:从G80到V100,GPU并行能力在十一年间提升了数百倍,Tensor Core为矩阵乘法提供了专用加速。与此同时,Parameter Server、GPipe、Megatron-LM和ZeRO让成千上万块GPU可以协同训练一个模型。这些硬件和软件的进步,让"完全基于并行注意力计算"的新架构成为可能。
而第一把钥匙,就是2017年那篇八人合著的论文——他们写道,新架构"完全基于注意力机制","不需要任何循环或卷积"。在8块P100上训练3.5天,就达到当时最好的翻译效果。
他们管这个架构叫Transformer。
本章引用论文
[1] Brook for GPUs: Stream Computing on Graphics Hardware, 2004, Stanford (Buck et al.)
[2] Large Scale Distributed Deep Networks (Parameter Server), 2014, Google (Dean et al.)
[3] GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism, 2018, Google (Huang et al.)
[4] Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism, 2019, NVIDIA (Shoeybi et al.)
[5] ZeRO: Memory Optimizations Toward Training Trillion Parameter Models, 2019, Microsoft (Rajbhandari et al.)
[6] In-Datacenter Performance Analysis of a Tensor Processing Unit (TPU v1), 2017, Google (Jouppi et al.) — ISCA 2017
[7] A Domain-Specific Supercomputer for Training Deep Neural Networks (TPU v2/v3), 2020, Google (Jouppi, Young, Patil, Patterson et al.) — Communications of the ACM
[8] TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning, 2023, Google (Jouppi et al.) — ISCA 2023
[9] DianNao: A Small-Footprint High-Throughput Accelerator for Ubiquitous Machine-Learning, 2014, ICT/INRIA (Chen T., Du, Sun, Wang, Wu, Chen Y., Temam) — ASPLOS 2014 Best Paper
[10] DaDianNao: A Machine-Learning Supercomputer, 2014, ICT/INRIA (Chen Y. et al.) — MICRO 2014 Best Paper
[11] PuDianNao: A Polyvalent Machine Learning Accelerator, 2015, ICT/INRIA (Liu et al.) — ASPLOS 2015
[12] ShiDianNao: Shifting Vision Processing Closer to the Sensor, 2015, ICT/INRIA (Du et al.) — ISCA 2015
[13] Cambricon: An Instruction Set Architecture for Neural Networks, 2016, ICT (Liu et al.) — ISCA 2016
[14] Cambricon-X: An Accelerator for Sparse Neural Networks, 2016, ICT (Zhang et al.) — MICRO 2016
[15] Cambricon-F: Machine Learning Computers with Fractal von Neumann Architecture, 2019, ICT (Song et al.)
[16] Cambricon-Q: A Hybrid Architecture for Efficient Training, 2020, ICT (Zhang et al.)
[17] Cambricon-S: An Accelerator for Neural Scene Representation with Sparse Encoding Table, 2024, ICT
第四章:一统天下——Transformer的诞生
简单的榫卯结构,搭上GPU算力的快车,让AI从手工捏泥娃娃走向了无限搭建的宫殿
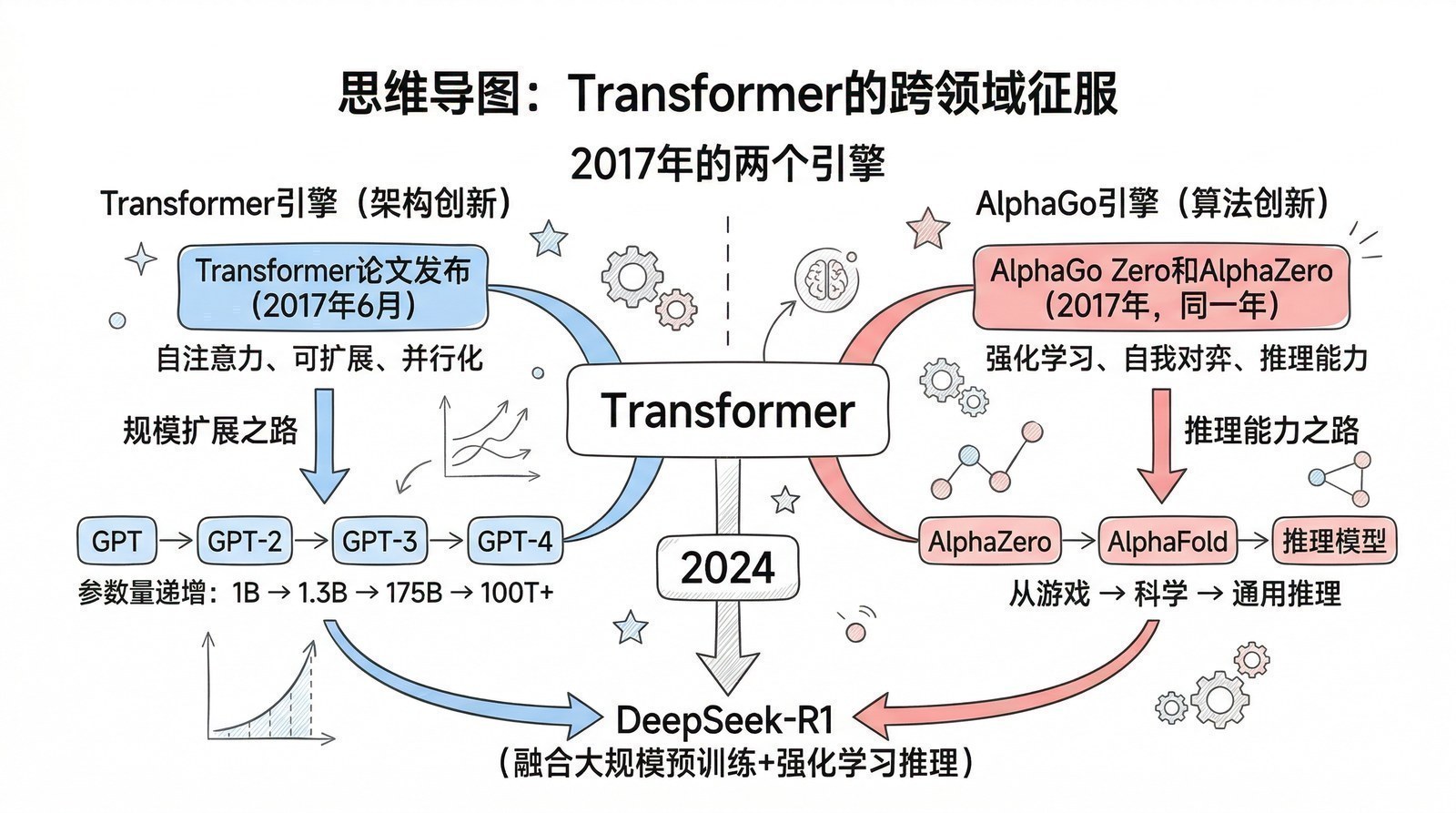
八个人,一篇论文,一颗种子
2017年6月12日,一篇论文被上传到arXiv预印本平台。
论文标题只有五个词:Attention Is All You Need[1]——标题取自Beatles的歌"All You Need Is Love"的戏仿。作者是八个人,来自Google Brain和Google Research的七位研究员加上多伦多大学的一位实习生Aidan Gomez。论文标注"Equal contribution. Listing order is random"——八位作者贡献相同,署名顺序随机排列。"Transformer"这个名字是作者之一Jakob Uszkoreit起的,仅仅因为他喜欢这个词的发音。
在2017年,这篇论文只是在机器翻译这个相对小众的领域引起了关注。它证明了一种"只用注意力机制"的新架构可以在翻译任务上超越所有基于RNN的模型,而且训练速度快了一个数量级。这固然令人印象深刻,但在当时看来,也就是机器翻译领域的一次技术迭代——就像之前从统计翻译到神经翻译的升级一样。
谁都没有预料到,这篇论文提出的架构会成为整个AI时代的基石。
今天你用的ChatGPT、Claude、Gemini、DeepSeek,底层全是Transformer。计算机视觉的ViT、AI绘画的Stable Diffusion、蛋白质预测的AlphaFold 2——也全是Transformer。一个架构统一了几乎所有AI领域,这在技术史上极为罕见。截至2025年,这篇论文的引用量超过17万次,是21世纪被引用最多的论文之一。
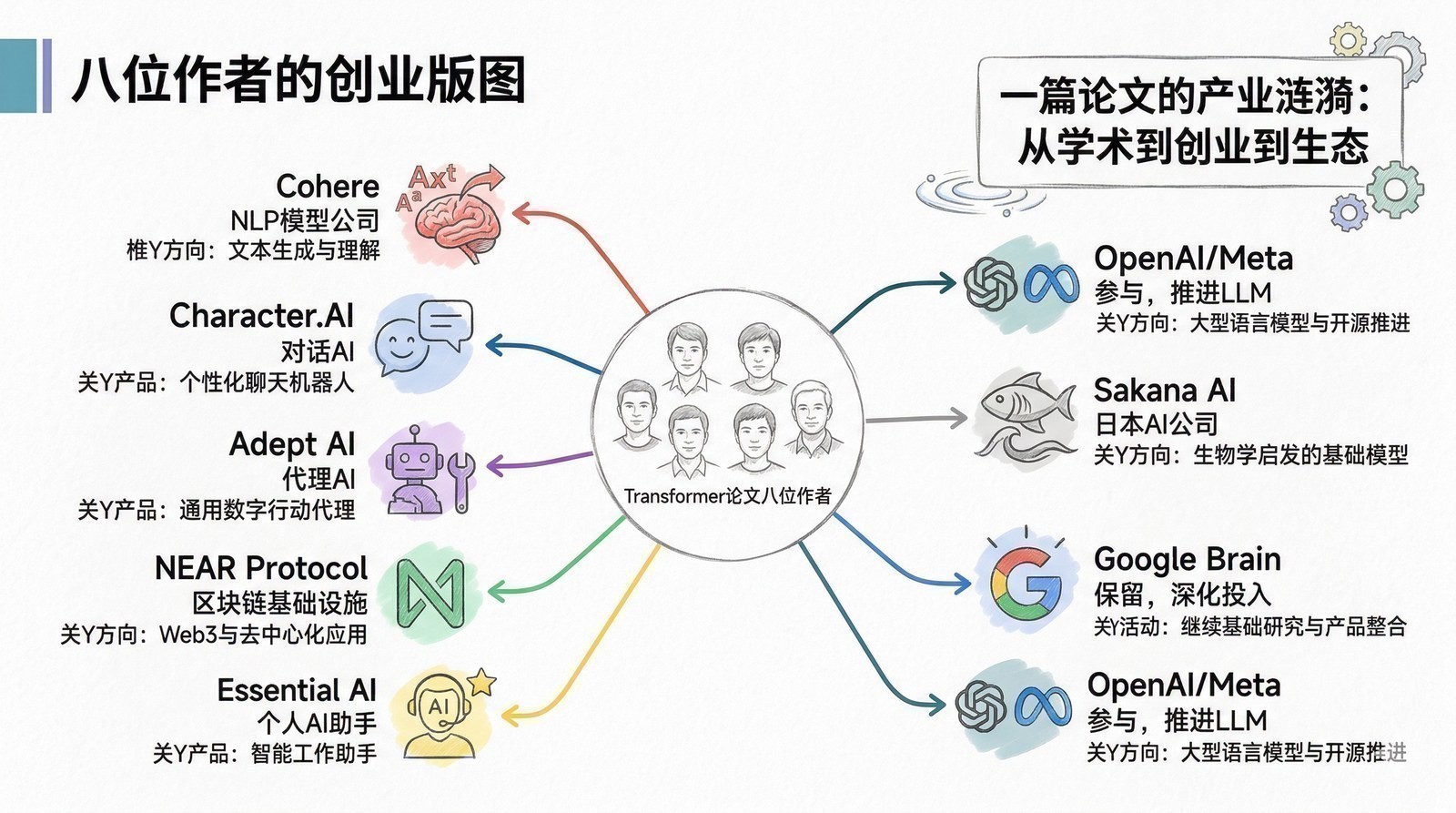
而这八位作者的故事,本身就是一个关于"一粒种子如何长成一片森林"的隐喻。论文发表后的几年里,八位作者陆续离开了Google,像蒲公英的种子一样散落到AI产业的各个角落:Aidan Gomez创办了企业级大模型公司Cohere(估值超55亿美元);Noam Shazeer创办了Character.AI(2024年Google以27亿美元的交易将他请回来主导Gemini开发);Ashish Vaswani和Niki Parmar先后联合创办了Adept AI和Essential AI;Jakob Uszkoreit创办了Inceptive,用Transformer做mRNA药物设计;Llion Jones创办了日本AI实验室Sakana AI;Illia Polosukhin创办了区块链项目NEAR Protocol;而Łukasz Kaiser加入了OpenAI,参与了GPT-4、GPT-5以及推理模型o1/o3的核心研发——他是八人中唯一选择留在技术一线、不走创业路线的人。
Google的实验室孕育了Transformer这项技术,更孕育了这批人才。他们从Google出发,在不同的土壤里长出了不同形态的植物——有的做大模型,有的做AI药物,有的做区块链,有的在OpenAI推动AGI——但所有这些植物的基因都来自同一颗种子。一个实验室对产业最大的贡献,不仅是它产出的论文,更是它培养的人。
Transformer到底做了什么——一次"点石成金"的简化
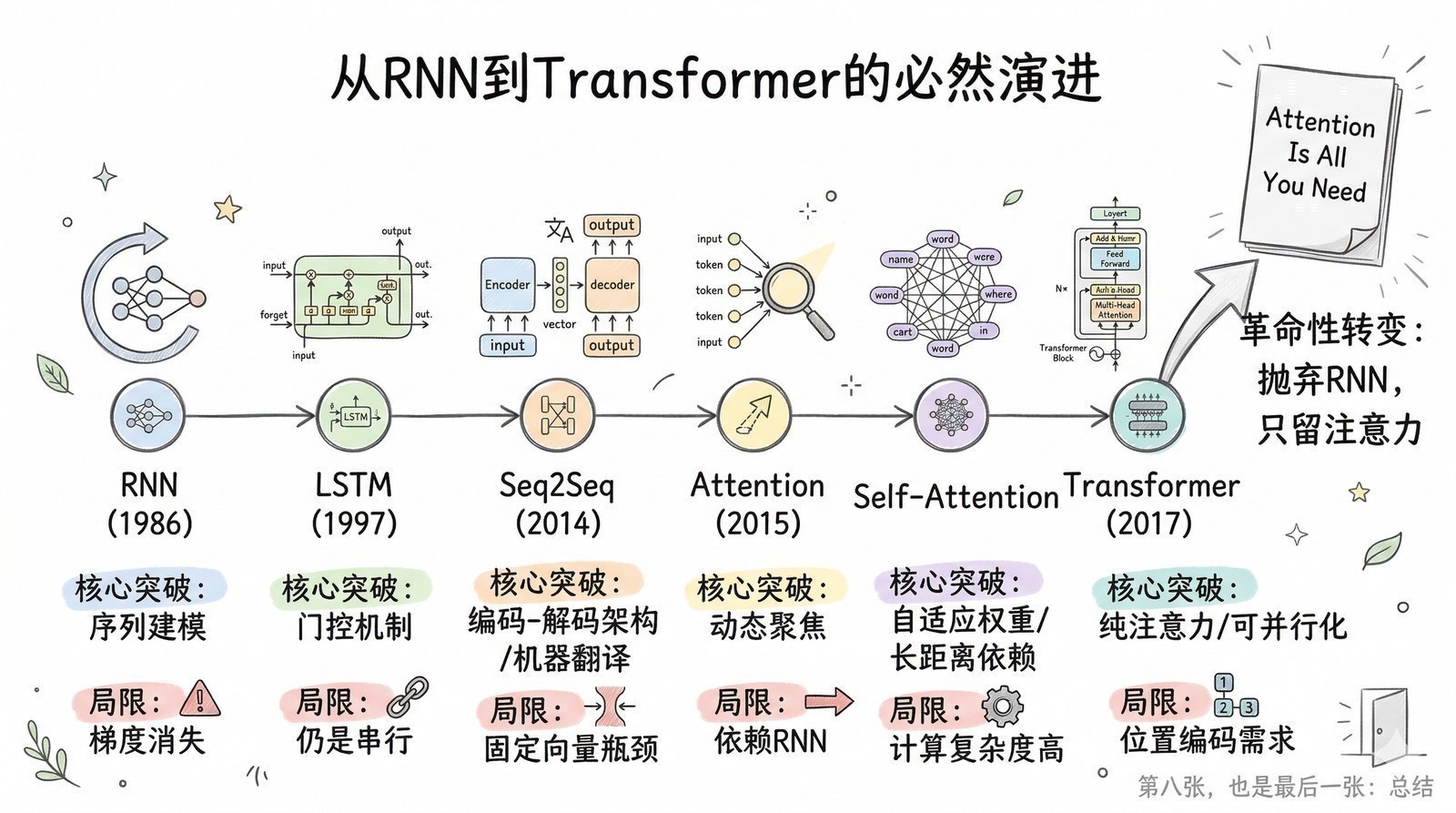
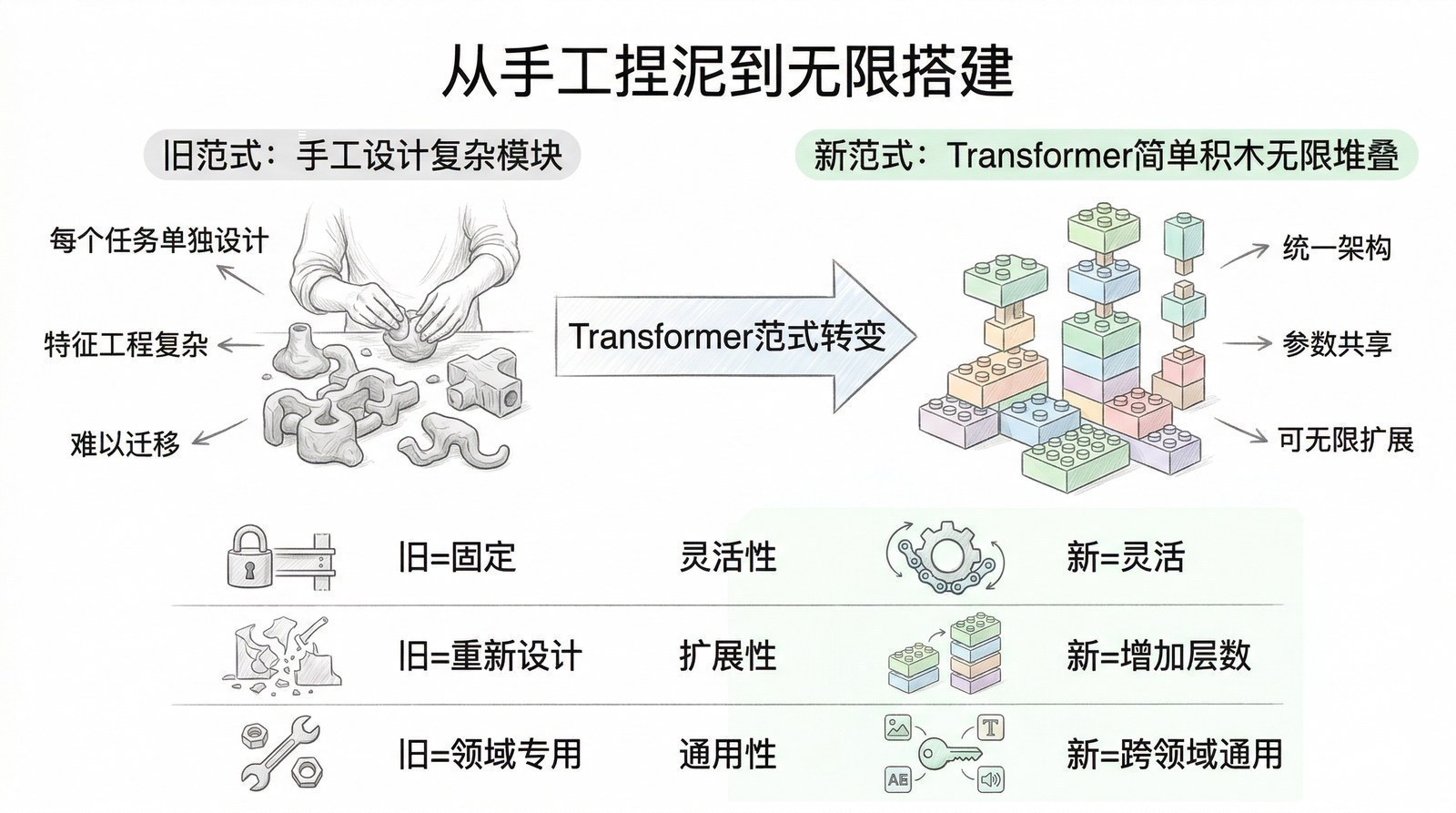
第二章用整整一节讲了从RNN到注意力机制的进化路线:RNN → LSTM/GRU → Seq2Seq → 注意力+RNN → 最终的问题是"为什么不去掉RNN,只留注意力"。Transformer就是这条路线的终点。
但Transformer做的事情,远不止"去掉RNN"那么简单。它的真正革命性在于一种点石成金的简化——丢掉了所有复杂的、串行的、精巧的算法结构,只留下了最简单、最朴素、但最有效的核心机制。
在Transformer之前,NLP领域的研究就像在手工捏泥娃娃——每个研究者精心设计不同形状的网络结构(LSTM的门控、GRU的简化门控、各种注意力变体、highway连接、残差门控……),捏出来千奇百怪的样子,有些在特定任务上效果很好,但换一个任务可能就不灵了。这些精巧的设计很脆弱,泛化能力差,而且因为结构复杂,很难并行化,很难扩展到更大的规模。
Transformer做的事情完全不同——它不再手工捏泥娃娃,而是发明了一套榫卯结构。榫卯本身极其简单朴素(就是注意力+前馈网络+残差连接),但它可以无限搭建——从一张桌子到一座桥到一座宫殿。这种简单但可无限组合的特性,才是Transformer真正的力量所在。
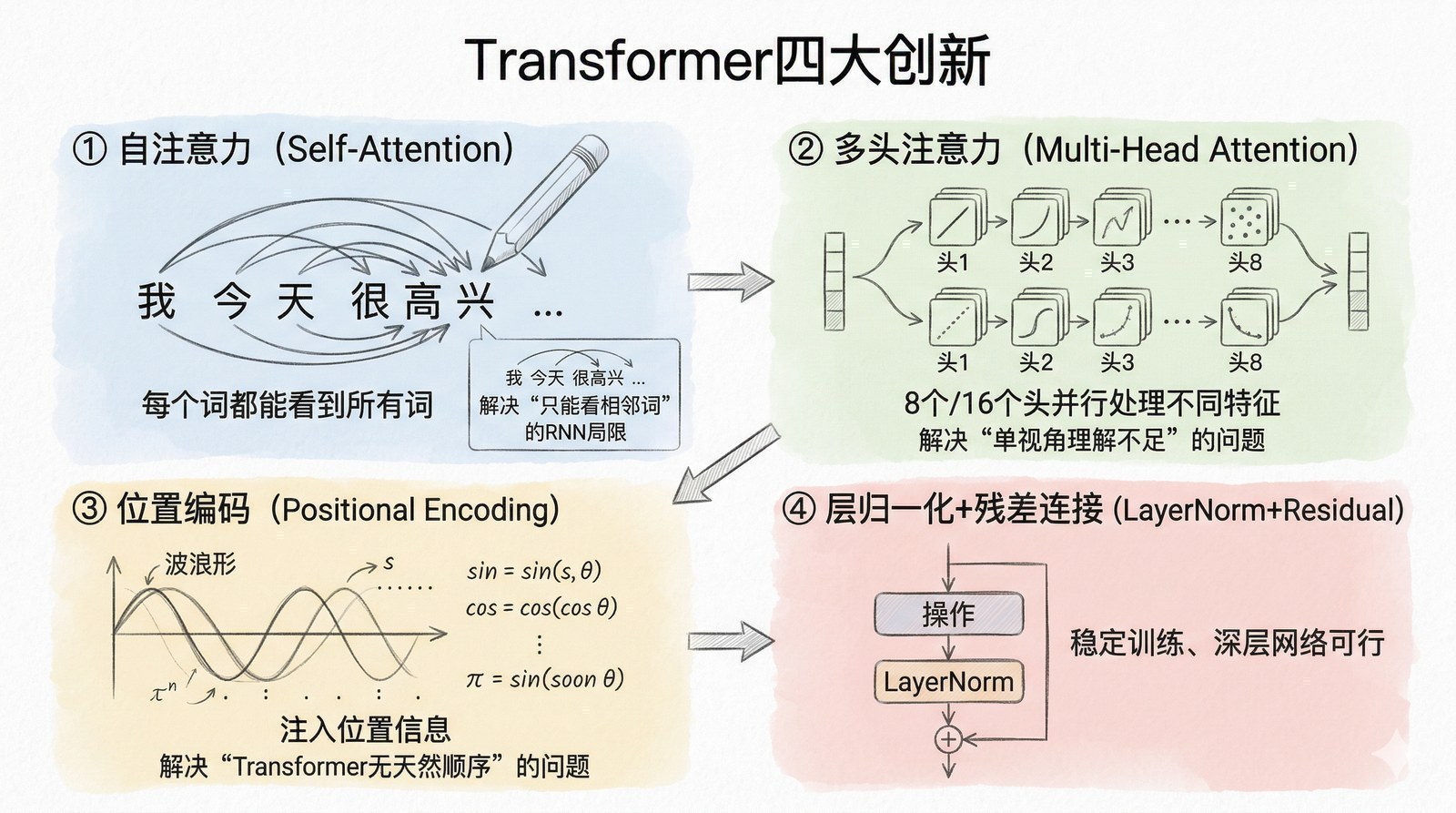
具体来说,Transformer的"榫卯"由四个关键创新组成:
自注意力(Self-Attention):让每个词同时"看到"所有其他词
第二章讲的Bahdanau注意力是"跨注意力"——翻译时解码器去关注编码器的输出。Transformer把这个想法推到了极致:序列中的每个位置都同时关注所有其他位置,这叫"自注意力"。
为什么这个创新如此重要?因为它一次性解决了RNN的三个根本问题。
第一,彻底消除了串行依赖。RNN处理100个词需要100步顺序计算——第2步依赖第1步的结果。自注意力用一次矩阵乘法同时计算所有位置之间的关联——100个词只需要一步并行计算。这让GPU的数千个计算核心可以同时满负荷工作。
第二,任意两个位置之间的信息传递只需一步。在RNN中,第1个词的信息要传到第100个词,需要经过99步传递,每一步都有信息衰减。在自注意力中,第1个词和第100个词直接"对话"——信息零损耗。这彻底解决了长距离依赖问题。
第三,计算结构完全是矩阵乘法。自注意力的核心运算是三个矩阵(Query、Key、Value)的乘法和softmax——这恰好是GPU和Tensor Core(第三章)最擅长的运算。Transformer不是恰好能用GPU加速——它几乎就是为GPU量身定做的架构。
自注意力对后续的影响是全方位的:BERT用它实现了双向上下文理解(第五章),GPT用带掩码的自注意力实现了从左到右的生成(第五章),ViT用它处理图像patch(第八章)。可以说,自注意力是今天所有大模型的核心计算单元——没有它就没有大模型时代。
多头注意力(Multi-Head Attention):从多个角度理解世界
一组注意力权重只能捕捉一种关系。但语言中的关系是多维度的——"他"和"小明"之间有指代关系,"银行"和"钱"之间有语义关系,"去"和"取"之间有时序关系。用一个注意力头来捕捉所有关系太勉强了。
Transformer的方案是多头注意力——同时运行多组独立的注意力计算(原论文8个头),每个头自由学习关注不同类型的关系,最后拼接结果。这就像同时用8种不同的视角来解读同一句话——有的头关注语法结构,有的关注语义相似性,有的关注位置距离——然后综合所有视角得出最终理解。
多头注意力的妙处在于它的自动分工——研究者不需要告诉每个头"你负责关注语法"、"你负责关注语义",这种分工是通过训练自动"涌现"出来的。后来GPT-3等大模型的可视化研究发现,不同的注意力头确实学会了关注不同层次的语言结构——有些头专注于句法,有些关注共指关系,有些捕捉主题相关性。这种"自发分工"是大模型"涌现"能力的早期线索之一。
位置编码(Positional Encoding):一个巧妙的补丁
自注意力有一个副作用:它把所有位置同等对待,丢失了词序——"狗咬人"和"人咬狗"在纯自注意力看来没有区别。但语序对语义至关重要。
RNN天然知道词序(因为它按顺序读),CNN也知道空间位置(因为卷积有固定的感受野)。Transformer把这些都扔掉了,就必须另想办法把位置信息"注入"模型。解决方案是位置编码——给每个位置加上一个独特的向量。原论文用正弦和余弦函数生成这些向量,让模型能学到"第3个词在第1个词后面"这样的相对位置关系。
位置编码看似是个小技术细节,但它的选择对后续发展影响深远。后来的改进版本——旋转位置编码(RoPE)——成为了GPT系列和LLaMA等主流大模型的标配,使模型能够处理远超训练长度的文本。这一切都始于Transformer论文中这个"巧妙的补丁"。
堆叠结构:简单重复,深度带来能力
Transformer的编码器和解码器各由多层相同结构堆叠而成。原论文给出了两个版本:base模型(6层编码器+6层解码器,隐藏维度512,8个注意力头,总参数约6500万)和big模型(6层但隐藏维度翻倍至1024,16个注意力头,总参数约2.13亿)。直观地说:base模型像一栋六层的公寓楼,每层有8个房间;big模型也是六层,但每层有16个更大的房间——楼层数一样,但每层的"容量"大了很多。big模型在翻译质量上显著优于base模型,验证了一个关键直觉:同样的架构,更大的尺寸带来更好的效果。每一层的结构出奇地简单:多头自注意力 → 残差连接+层归一化 → 前馈网络 → 残差连接+层归一化。
这里的关键词是"相同结构堆叠"——不像之前的网络需要为每一层设计不同的结构,Transformer的每一层都是同样的"榫卯"。你想要更强的模型?再叠一层就行,或者把每层做得更宽。从6层到12层到24层到96层——性能持续提升,而架构不需要任何改变。
这就是"榫卯结构"的力量:单个榫卯极其简单,但无限堆叠后可以构建任何规模的建筑。BERT用12层,GPT-2用48层,GPT-3用96层——架构完全一样,只是层数和宽度不同。这种"一套架构打天下"的可扩展性,是Transformer最终统一所有AI领域的核心前提。
为什么简单反而赢了——Transformer的"点石成金"逻辑
把四个创新放在一起看,Transformer做的事情可以概括为一句话:丢掉所有复杂的人工设计,只保留最简单的、可无限扩展的计算结构,然后让数据和算力去"填满"这个结构。
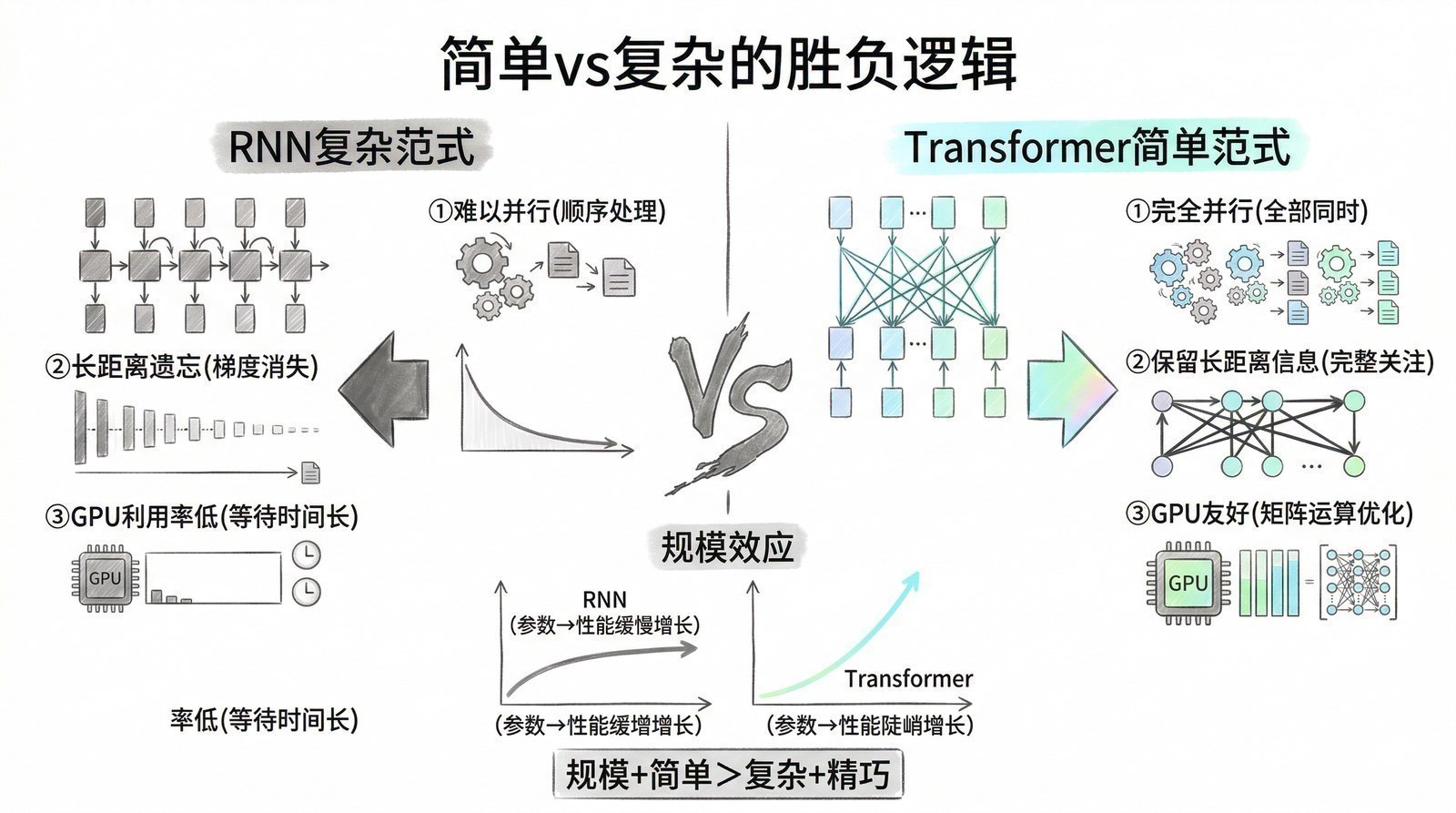
这和之前的范式完全不同。之前的AI研究追求的是"更精巧的算法"——设计更巧妙的门控机制、更精细的注意力变体、更复杂的网络拓扑。每一种精巧设计都像手工打造的瑞士钟表——在特定任务上运行精准,但换个任务就可能失灵,而且很难做大。
Transformer反其道而行之:它的核心计算(矩阵乘法+softmax)简单到连本科生都能实现。但正是这种简单,赋予了它三个前辈架构无法企及的优势:
第一,完美匹配GPU并行计算。 自注意力的核心就是矩阵乘法,而矩阵乘法是GPU最擅长的运算——数千个CUDA核心可以同时处理不同位置之间的注意力计算。2017年V100的Tensor Core让矩阵乘法效率再翻几倍。Transformer不只是"能用GPU",它几乎是"为GPU而生"的架构。 这意味着GPU算力的每一次提升(V100→A100→H100→B200),Transformer都能立刻、直接、完整地受益——不需要任何架构改动。
第二,可以无限扩展。 想要更强?加更多层、加更宽的矩阵、喂更多数据——效果会持续提升。从GPT-1的1.17亿参数到GPT-3的1750亿参数,参数量增加了1500倍,架构没有任何本质变化。这种"线性扩展带来线性收益"(后来被总结为Scaling Law,第六章)在RNN/LSTM时代是不可能的——因为RNN的顺序瓶颈让训练时间随模型增大而超线性增长。
第三,对数据结构不做假设。 CNN假设数据有空间局部性,RNN假设数据有时间顺序。这些假设在特定领域很有效,但也限制了通用性。Transformer不做任何假设——它只是让序列中的每个元素都能关注所有其他元素,让数据自己"告诉"模型什么是重要的。文本是序列,图像可以切成patch变成序列,蛋白质是氨基酸序列,音频是帧序列——只要能变成序列,Transformer就能处理。
三个优势叠加在一起,形成了一个前所未有的正循环:简单的架构 → 完美利用GPU → 可以做得更大 → 更大的模型从更多数据中学到更多知识 → 效果更好 → 吸引更多算力投入 → 模型继续变大 → 效果继续变好…… 这个正循环就是大模型时代的底层引擎。
这里值得特别展开讲一下Richard Sutton在2019年写的《The Bitter Lesson》(苦涩的教训)[2]。Sutton是强化学习领域的奠基人之一,他回顾了AI七十年的历史后得出一个让很多研究者不愿接受的结论:在AI发展的每一个领域——国际象棋、围棋、语音识别、计算机视觉、自然语言处理——最终胜出的方案都不是那个最精巧、最有人类先验知识的方案,而是那个最简单、最通用、但配合了最大规模计算的方案。
这条规律为什么"苦涩"?因为它意味着研究者花几年时间精心设计的巧妙算法,往往会被一个更简单但规模更大的方案轻松击败。LSTM的精巧门控机制被Transformer的简单矩阵乘法替代了。CNN精心设计的局部感受野被ViT的全局注意力替代了。每一次,精巧都输给了规模。
Transformer就是这条规律最极致的体现——一个足够简单的架构,配合足够大的数据和算力,就能在几乎任何领域达到最好的效果。它不需要为每个领域定制不同的结构,只需要把数据喂进去,然后scaling up。这种"暴力但有效"的方式颠覆了之前AI研究追求精巧设计的传统范式。
同一年的另一个金矿:AlphaGo与强化学习
2017年不仅属于Transformer。同一年还有一个故事,从完全不同的角度预示了AI的未来——那就是AlphaGo的进化。
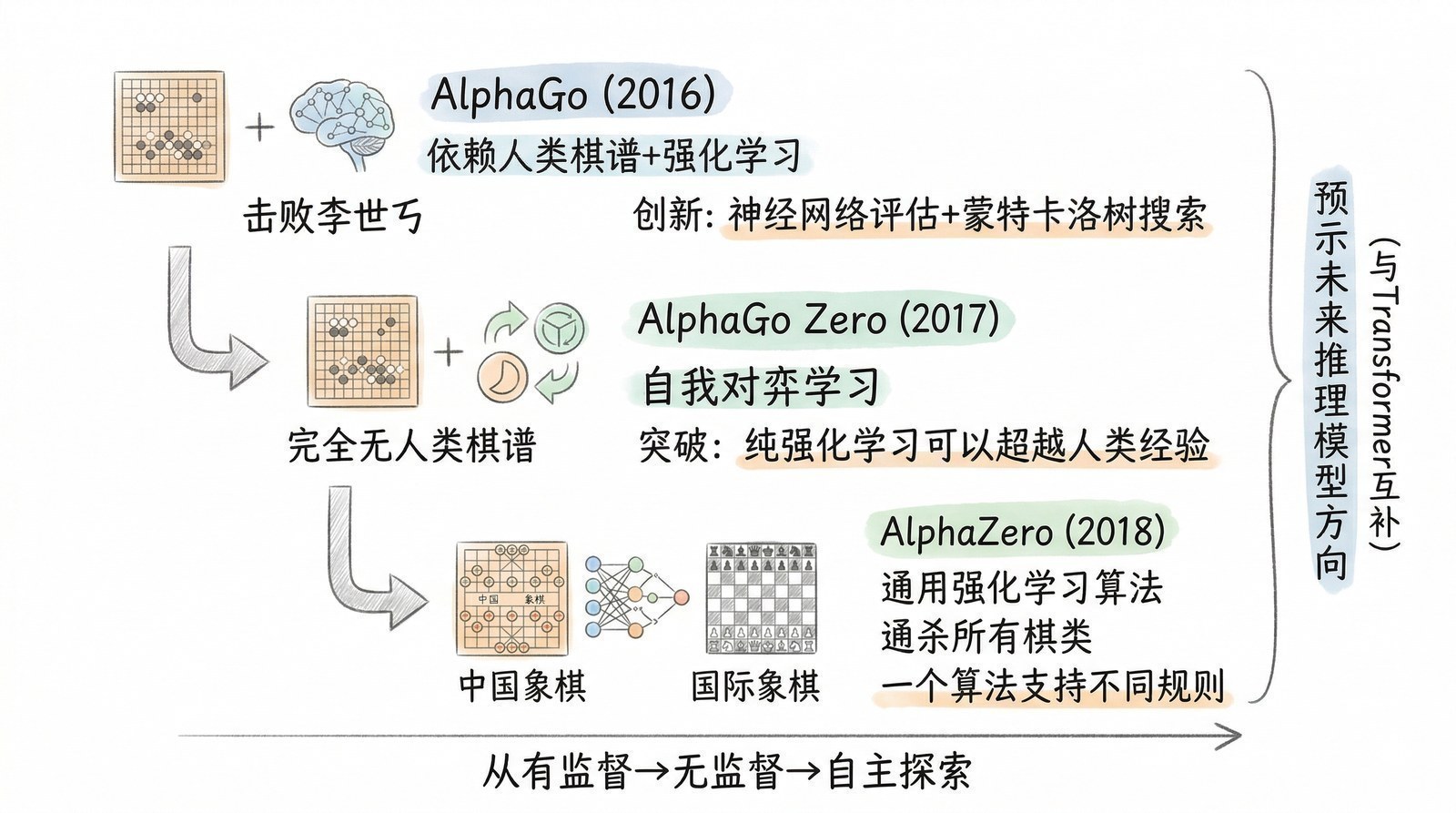
从AlphaGo到AlphaGo Zero:人类知识是必需的吗?
2016年3月,DeepMind的AlphaGo以4:1战胜围棋世界冠军李世石[3],全球超过2亿人观看了这场比赛的直播。
AlphaGo的训练分两步:第一步是"模仿学习"——从人类高手的16万盘棋谱中学习如何下棋(监督学习);第二步是"自我提升"——让学会了人类棋路的AlphaGo和自己对弈,通过胜负反馈不断改进(强化学习)。可以这样理解:第一步相当于一个围棋学徒先看了所有大师的棋谱把基本功打好,第二步相当于这个学徒关起门来和自己反复练习,不断发现并纠正自己的弱点。
2017年10月,DeepMind发表了AlphaGo Zero[4]——它做了一件看起来不可思议的事:彻底跳过了第一步。AlphaGo Zero从零开始,没看过任何一盘人类棋谱,只知道围棋的规则(哪里可以落子、什么算赢),然后纯粹通过自我对弈来学习下棋。
结果令人震惊:AlphaGo Zero在短短3天内就超越了战胜李世石的AlphaGo版本,21天后超越了后来以3:0横扫柯洁的AlphaGo Master,40天后成为围棋史上最强的"棋手"——以100:0碾压了所有之前的AlphaGo版本。
从AlphaGo到AlphaGo Zero的进化,区别不在于算法细节,而在于一个根本性的问题:AI需要人类知识作为起点吗?
AlphaGo的回答是"需要"——它从人类棋谱开始学习。AlphaGo Zero的回答是"不需要"——它完全靠自我探索就超越了人类。而且,恰恰因为没有被人类棋谱"污染",AlphaGo Zero发现了很多人类几千年围棋史上从未出现过的下法——它不受人类思维定式的束缚。
这个发现具有里程碑价值,因为它打破了一个根深蒂固的假设:人类专家的知识不是AI学习的天花板,而可能是一种地板——甚至是一种限制。
强化学习:大模型的第二引擎
AlphaGo和AlphaGo Zero背后的核心方法——强化学习(Reinforcement Learning)——和监督学习有什么区别?用一个日常例子来说明。
想象你在教一个孩子下象棋。监督学习的方式是:给他看100万盘大师棋谱,每一步告诉他"这里应该走马""这里应该走车"——孩子通过模仿大师来学习。强化学习的方式完全不同:不给他看任何棋谱,只告诉他规则,然后让他自己下棋。赢了奖励一颗糖(正反馈),输了什么都没有(负反馈)。通过成千上万次试错,孩子自己摸索出什么走法容易赢——而且他摸索出的走法可能和任何大师都不一样。
AlphaGo Zero证明了第二种方式可以超越第一种——因为自我探索不受人类知识的局限,能发现人类专家的盲区。
强化学习的研究历史比深度学习更长——从1950年代的动态规划,到1990年代的Q-learning和TD-learning,到2013年DeepMind用深度Q网络(DQN)在Atari游戏上超越人类,到2016-2017年AlphaGo系列的巅峰。但在大模型出现之前,强化学习主要应用在游戏和机器人控制这些"规则清晰、反馈即时"的领域——因为它需要明确的奖励信号,而现实世界的很多任务(比如"写一篇好文章""回答一个开放性问题")很难给出精确的奖励。
然而,AlphaGo Zero的核心原理——"不依赖人类专家的示范,通过自我探索和试错反馈来学习"——在几年后被证明对大模型同样适用,而且同样有效。
2022年,OpenAI用RLHF(基于人类反馈的强化学习)训练出了ChatGPT(第七章)——让大模型学会"说人话"。但RLHF还依赖大量人类标注的偏好数据——某种意义上还是"看了大师棋谱"。
2024-2025年,真正的突破来了。OpenAI的o1和DeepSeek的R1(第十章)用强化学习让大模型"学会推理"——不是教它一步步怎么推理,而是设定目标(比如"解对这道数学题"),让模型自己探索推理策略,做对了给奖励,做错了给惩罚。DeepSeek-R1更是直接验证了AlphaGo Zero的哲学:不用任何人类编写的思维链样本,只靠纯强化学习,大模型就能"涌现"出推理能力——和AlphaGo Zero不用人类棋谱就学会下棋,逻辑上完全一致。
这条从AlphaGo(2016)→ AlphaGo Zero(2017)→ RLHF/ChatGPT(2022)→ o1/R1(2024-2025)的线索,构成了大模型发展的第二引擎:如果说Transformer + Scaling Law是第一引擎(通过扩大模型规模来积累知识),那么强化学习就是第二引擎(通过自我探索来获得推理和逻辑能力)。第一引擎给了大模型"博学",第二引擎给了大模型"善思"。第十章会详细展开这个故事。
Transformer为什么能"统一一切"
Transformer最初是为翻译设计的。但在随后几年里,它像一种适应力惊人的"物种",迅速入侵并占领了AI的每一个领域。
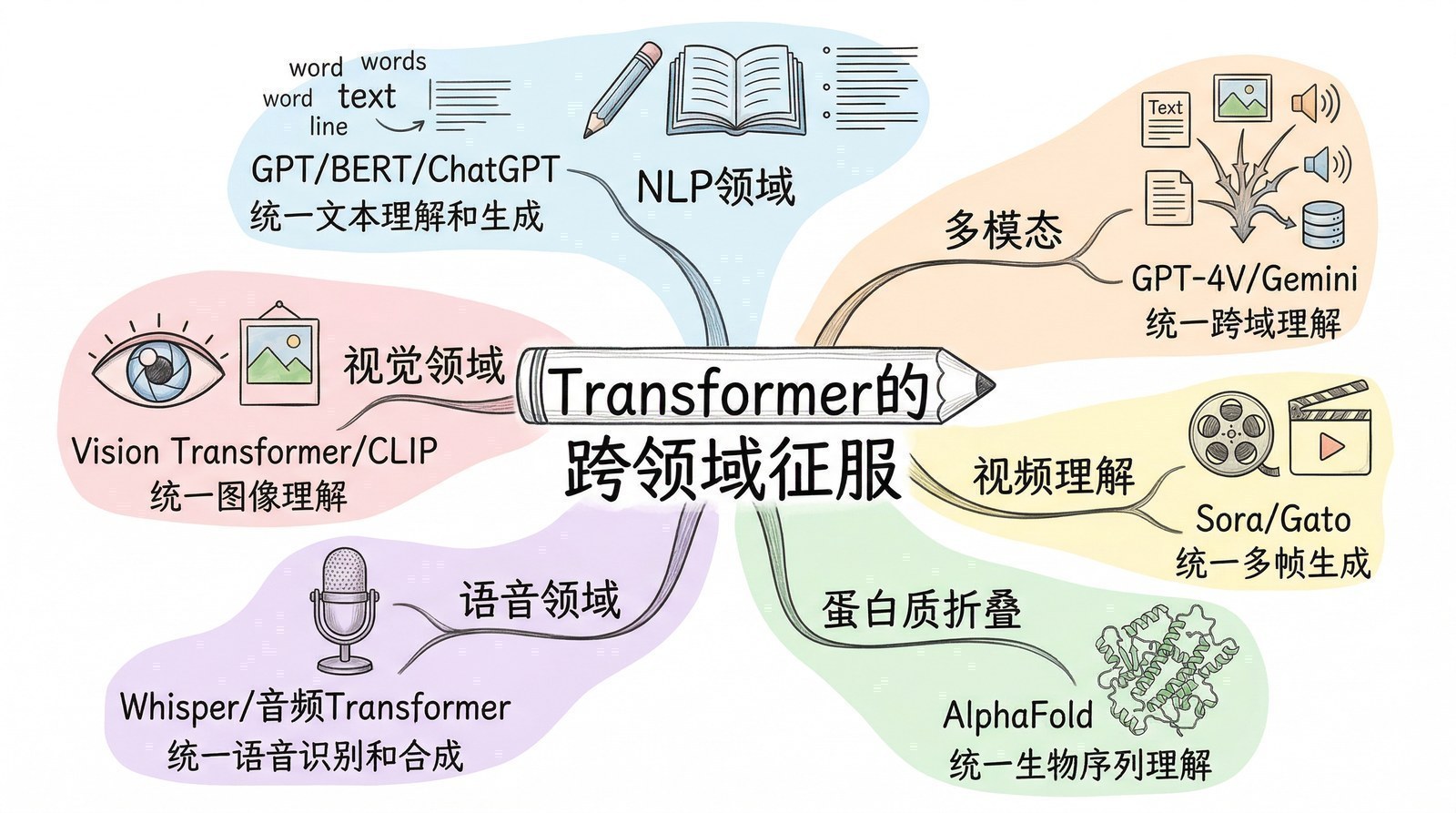
2018年:统一NLP。 OpenAI的GPT-1用Transformer的解码器做文本生成,Google的BERT用Transformer的编码器做文本理解。两条路线都全面抛弃了RNN。从此Transformer成为NLP的唯一主流架构。
2020年:入侵计算机视觉。 Google的ViT证明:把一张图片切成16×16的小块(patch),排成一个序列,然后用标准的Transformer处理——效果不输甚至超过了统治CV十年的卷积神经网络。Meta的DETR用Transformer做目标检测,TimeSformer用Transformer做视频理解。
2021年:攻入生命科学。 DeepMind的AlphaFold 2用一种改良的Transformer预测蛋白质结构,解决了困扰生物学界五十年的问题。
2021-2024年:打通一切模态。 OpenAI的CLIP用Transformer同时处理图像和文本;DALL-E、Stable Diffusion用Transformer生成图像;Sora用Transformer生成视频。Transformer成了AI世界的"通用语言"——无论什么类型的数据,都可以变成序列,用同一种架构处理。
这种"一统天下"的能力,建立在三个前提之上:
前提一:足够通用的输入格式。 任何数据都可以被表示成"token序列"——文字天然是词的序列;图片可以切成patch变成序列;音频可以按帧切成序列;视频是图片帧的序列;蛋白质是氨基酸的序列;甚至化学分子式都可以变成序列。这种"万物皆可序列"的表示方式,给了Transformer处理一切数据的基础。
前提二:足够大的数据和算力。 ViT的论文明确指出:在小数据集上ViT不如CNN,因为CNN自带的"局部性"假设在数据少时是有用的先验。但当数据量够大时,Transformer反超——它不受假设限制,能学到更丰富的模式。这就是为什么Transformer统一各领域是在2020年之后而非2017年——因为到那时候,数据集和算力(A100级别)才大到让Transformer在各领域都能充分发挥。
前提三:Scaling的可预测性。 Transformer独特的价值在于,它的性能随规模增长的曲线是可预测的(第六章的Scaling Law)。研究者可以根据小模型的表现推断大模型的效果,从而敢于投入千万甚至上亿美元去训练更大的模型。RNN/LSTM从来没有展现出这种可预测的scaling行为——你不知道把LSTM做大10倍是否会有效果。Transformer给了研究者和投资人信心:只要继续投入,效果就会继续提升。 这种信心是大模型军备竞赛的心理基础。
一篇论文与一场围棋赛
2017年的AI历史可以浓缩为两个画面:一篇论文和一场比赛。它们各自代表了大模型时代的一个引擎。
"Attention Is All You Need"——AI世界的"集装箱"
Transformer对AI的意义,可以类比集装箱对全球贸易的意义。
1956年之前,全球货物运输靠的是人工装卸——不同形状、不同尺寸的货物需要不同的搬运方式,效率极低。1956年马尔科姆·麦克莱恩发明了标准化集装箱——一个简单的金属盒子,尺寸统一。它本身没有什么技术含量,但它让装卸流程标准化了:所有货物(无论是电视机还是衣服还是汽车零件)都被塞进同一规格的箱子,用同样的吊车装到同样的船上。这个简单的标准化使全球贸易效率提升了数十倍,催生了今天的全球化供应链。
Transformer就是AI领域的"集装箱"。它本身的设计并没有超出2015-2016年已有知识的范围——自注意力、多头注意力、残差连接、位置编码,每一个组件单独拿出来都不是全新的。它的革命性在于:把这些组件用最简单的方式组合在一起,形成了一个标准化的、可无限扩展的"容器"。 任何类型的数据都可以被塞进这个容器,用同样的训练流程、同样的硬件、同样的扩展方式来处理。
Transformer之前,做NLP的模型和做CV的模型完全不同——不同的架构、不同的训练技巧、不同的工程栈。Transformer之后,一切数据都变成了序列,一切模型都用同样的"注意力+前馈网络+残差连接"来搭建,一切训练都在同样的GPU集群上运行。这种标准化使得AI领域的"规模化生产"成为可能——就像集装箱使全球贸易的规模化成为可能一样。
AlphaGo对李世石——强化学习进入公众视野的那一天
2016年3月9日至15日,首尔四季酒店。这场五番棋对决,让"强化学习"这个原本只存在于学术论文中的概念,第一次以一种全世界都能理解的方式进入了公众视野——通过一场围棋比赛。
绝大多数观众并不知道什么是"策略网络""价值网络""蒙特卡洛树搜索"。但他们看到了一个事实:一个AI程序,通过反复和自己下棋来提升(这就是强化学习的通俗表述),最终打败了人类最强的围棋选手。这个故事简单到每个人都能理解,震撼到每个人都会记住。
第一局,AlphaGo以稳健棋风获胜,观众惊讶但尚能接受。第二局第37手,AlphaGo下出一步让所有围棋专家目瞪口呆的棋——落在一个没有人类棋手会考虑的位置,解说员沉默了十几秒。事后分析证明这是一步极其精妙的战略性布局——这就是强化学习"自我探索"的力量,它发现了人类几千年围棋史从未想到的下法。
第四局,李世石在第78手下出了被后来称为"神之一手"的妙招,让AlphaGo出现了判断失误,李世石赢下了人类唯一的一场胜利。这一局的象征意义远大于技术意义——它代表了人类智慧最后的闪光,也让这场比赛从"人类被碾压"变成了"人类虽败犹荣"的叙事。
这场比赛之后,全球对AI的关注度急剧上升。在中国,"人工智能"成为年度热词,投资机构开始疯狂寻找AI标的,政府把AI写进国家战略。第一章提到的AI四小龙获得天量融资、第二章中李志飞的出门问问获得大众汽车1.8亿美元投资,很大程度上都受益于AlphaGo引发的这波热潮。可以说,AlphaGo用一场围棋比赛完成了AI历史上最成功的一次"公众科普"——它让全世界第一次相信,AI不是科幻,而是现实。
2017年:一切就绪
回头看,2017年是AI历史上的"枢纽之年"——三件事同时就位,为大模型时代的到来准备好了所有条件。
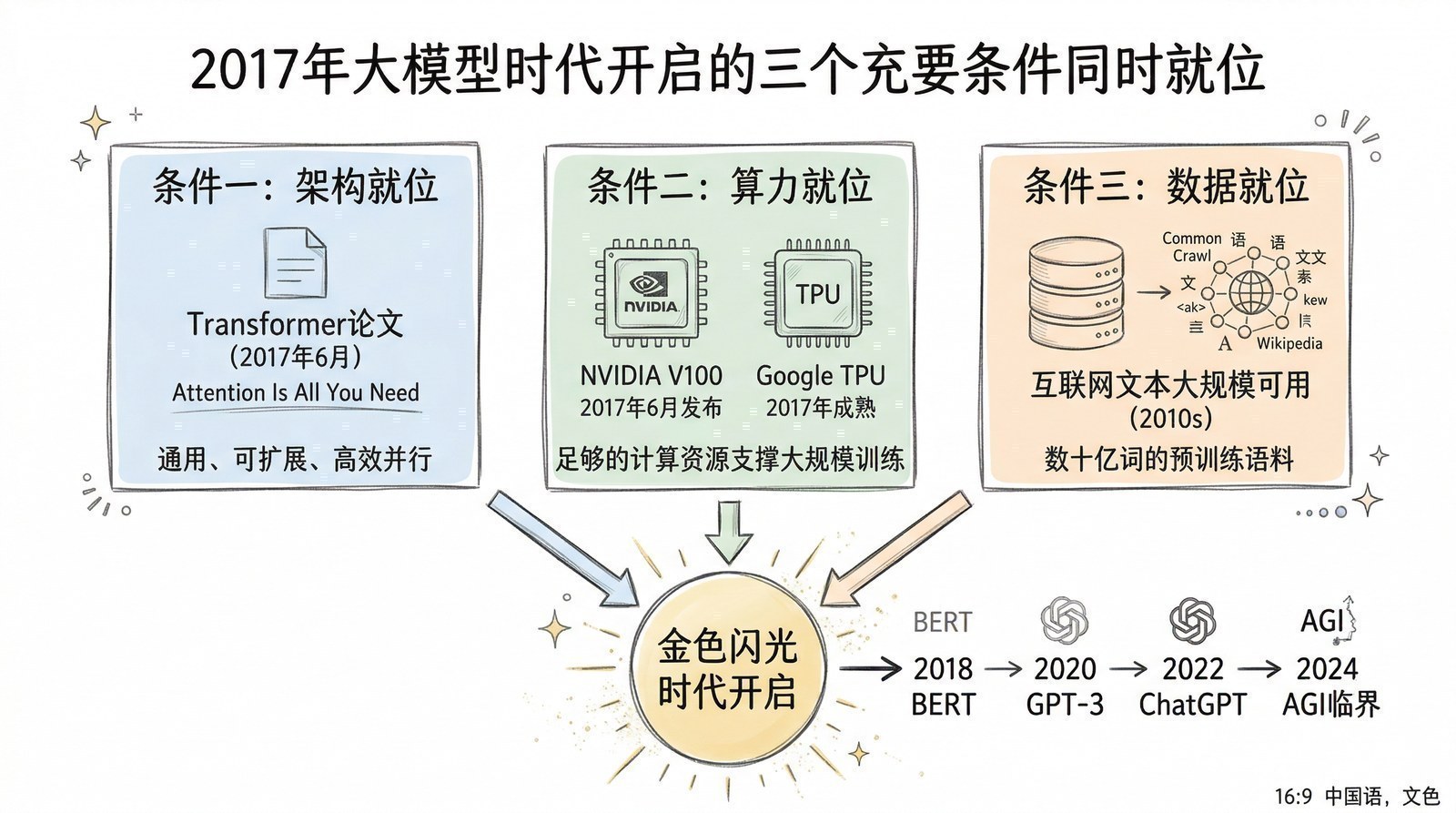
架构就位:Transformer提供了一个足够通用、足够简单、可以无限扩展的"容器"。它不对数据做任何假设,只要把数据变成序列就能处理。
算力就位:同一年NVIDIA发布了V100和Tensor Core(第三章),Transformer的核心计算——矩阵乘法——恰好是Tensor Core最擅长的运算。架构和硬件完美匹配。
理念就位:AlphaGo Zero证明了"规模+自我学习"可以超越人类专家。这个思想预示了后来大模型的两个核心策略——用Scaling扩大知识(第六章),用强化学习提升推理(第十章)。
但一个"空容器"造出来之后,下一个问题是:往里填什么? 怎么训练这个Transformer?让它学什么任务?用什么数据?
2018年,两个团队分别给出了截然不同的答案。一个来自Google,方案叫BERT——让模型做"完形填空",用双向注意力理解文本。另一个来自OpenAI,方案叫GPT——让模型做"续写",从左到右一个词一个词地生成文本。
BERT在当年赢了所有排行榜。但GPT赢了未来。
本章引用论文
[1] Attention Is All You Need (Transformer), 2017, Google (Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser, Polosukhin) — NeurIPS 2017
[2] The Bitter Lesson, 2019, Richard Sutton
[3] Mastering the Game of Go with Deep Neural Networks and Tree Search (AlphaGo), 2016, DeepMind (Silver et al.) — Nature
[4] Mastering the Game of Go Without Human Knowledge (AlphaGo Zero), 2017, DeepMind (Silver et al.) — Nature
[5] Non-local Neural Networks, 2017, FAIR/CMU (Wang, Girshick, Gupta, He)
第五章:两条路线之争——BERT vs GPT,理解还是生成?
同一个Transformer,两种截然不同的信仰,引发了大模型时代最重要的路线之争
一个容器,两种填法
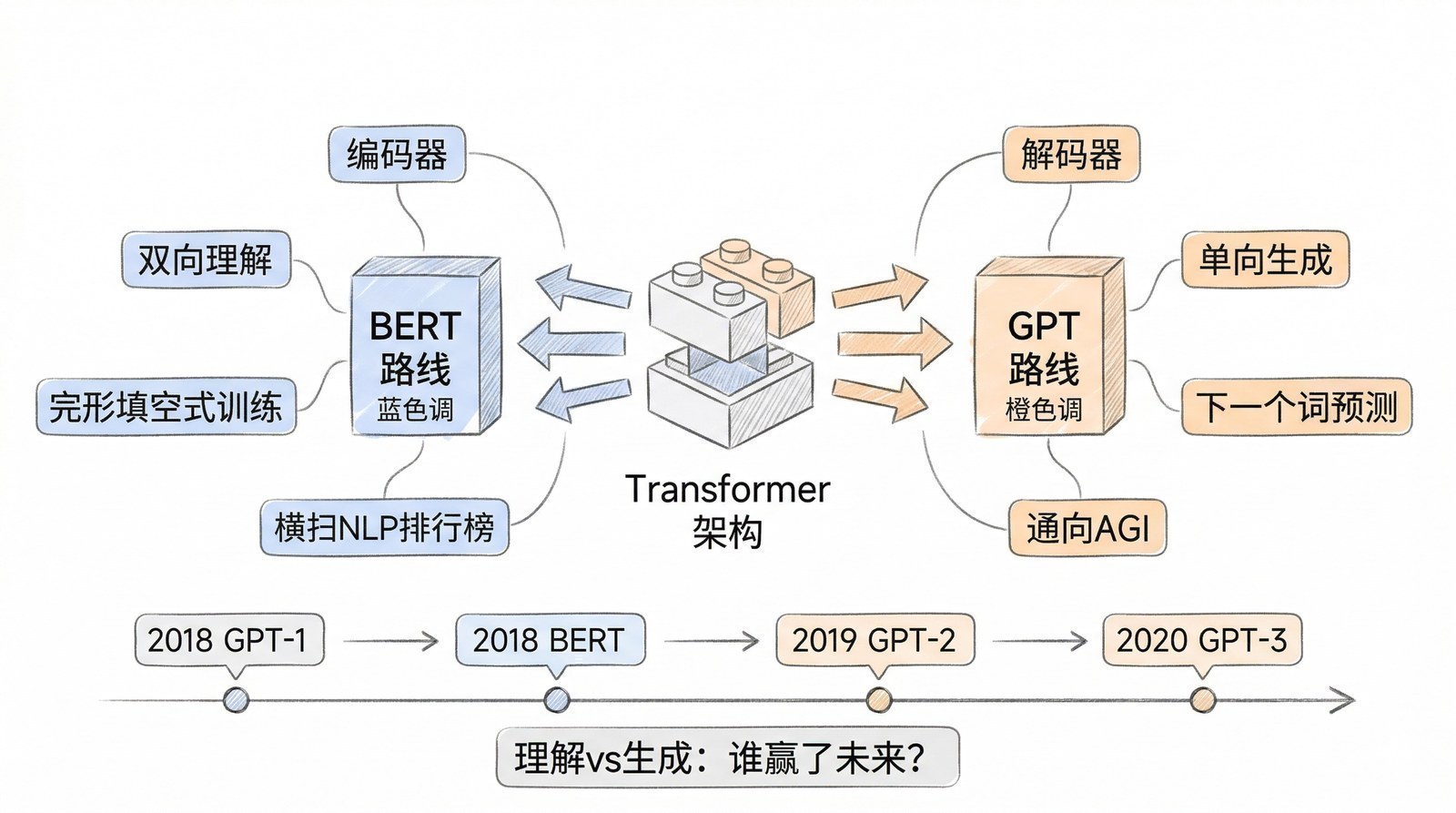
2017年Transformer诞生后(第四章),整个NLP领域面对一个兴奋又迷茫的局面:我们有了一个前所未有的强大架构,但它只是一个"空容器"。怎么用它?用什么数据训练?让它学什么?这些问题的答案将决定AI的走向。
先搞清楚:编码器和解码器有什么不同
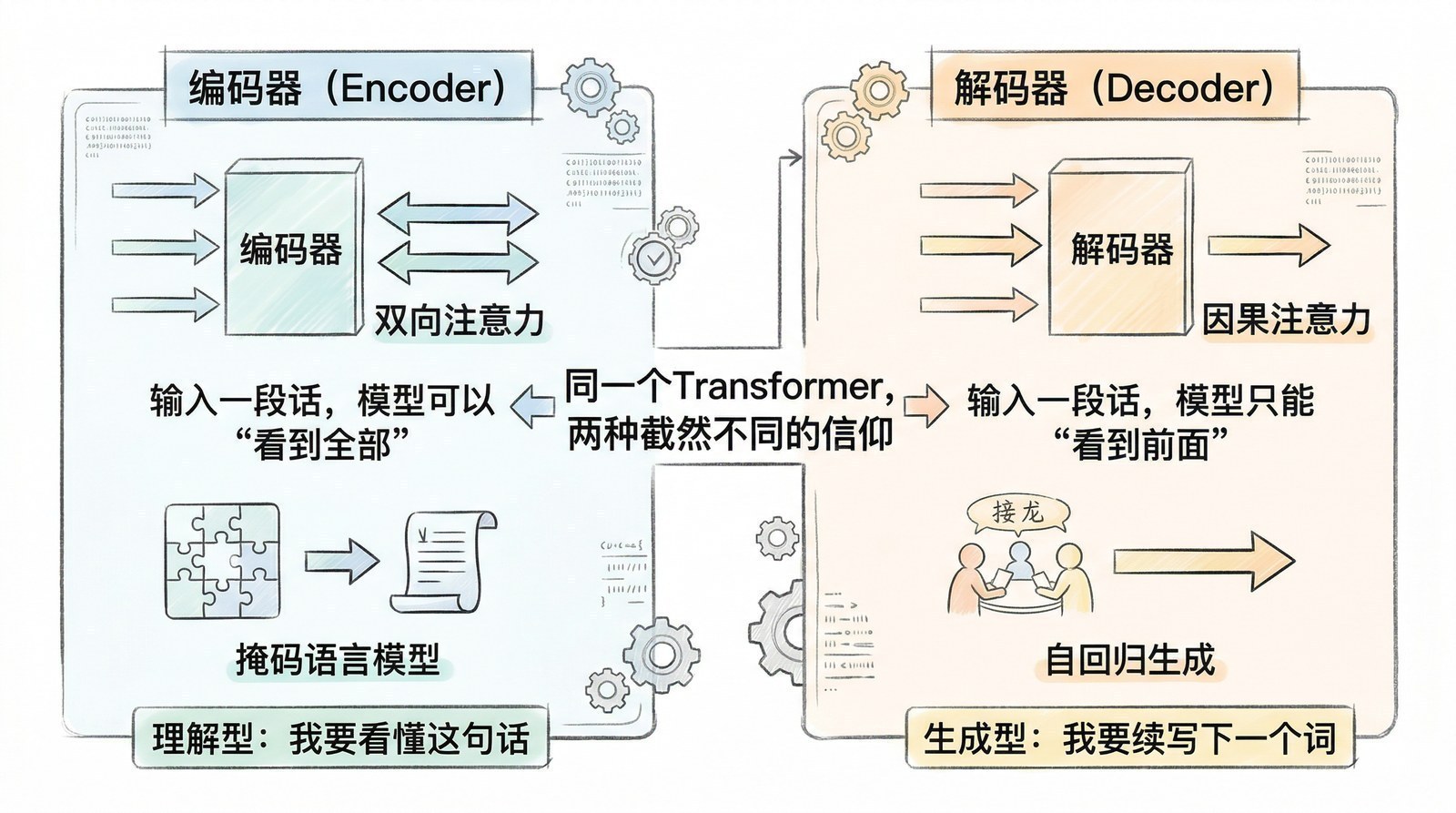
Transformer原论文有两个核心组件——编码器和解码器。它们的分工和能力有本质区别。
编码器负责"读"。 它处理每个位置时可以同时看到句子中所有其他位置的信息——既能看前面也能看后面。读"我今天在北京吃了牛肉面"时,处理"北京"时它既能看到"我今天在"也能看到"吃了牛肉面"。这种"全知全能"的双向视野让编码器非常擅长理解——因为它拥有最完整的上下文。
解码器负责"写"。 它生成每个词时只能看到已经生成的词,不能偷看后面还没生成的内容。写到第10个字时,只知道前9个字是什么,不知道第11个字会是什么。这种"只看过去"的限制恰好让解码器天然适合生成文本——因为真实的写作就是一个字一个字往下写的。
一个类比:编码器像阅卷老师——看到完整的答案后理解含义、判断对错。解码器像写作文的学生——一个字一个字往下写,每个字都基于已经写好的部分来决定。
为什么只用解码器就能做"语句续写"?因为续写的本质就是"根据已经写好的内容预测下一个词"——给出"今天天气很",模型预测下一个词是"好"。解码器的"只看过去"限制恰好匹配这个任务。
为什么只用编码器就能做"完形填空"?因为完形填空的本质是"根据上下文推断空缺"——给出"我今天在____吃了牛肉面",模型要综合前后文推断空格是"北京"。编码器的"双向视野"恰好提供了这种能力。
2018年,两个团队各取了Transformer的一半,走向了截然不同的方向:OpenAI只用解码器做续写,Google只用编码器做填空。
"预训练+微调":一个改变NLP范式的思想
在展开GPT和BERT的具体设计之前,需要先理解它们共同的核心创新——"预训练+微调"范式。这个思想的重要性不亚于Transformer架构本身。
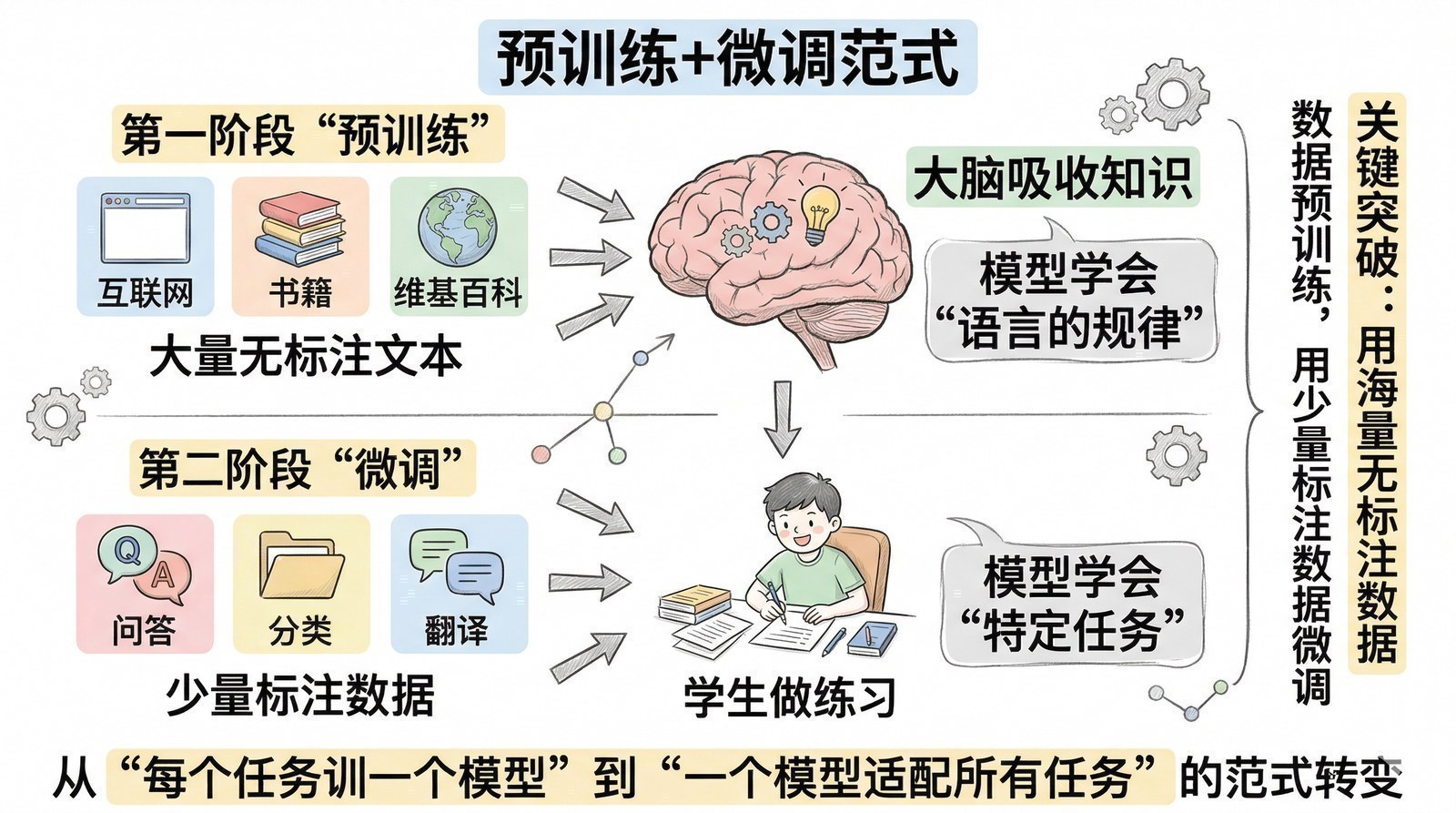
在2018年之前,做一个NLP应用的标准流程是:确定任务(比如情感分析)→ 收集该任务的标注数据(10万条标注了"正面/负面"的评论)→ 设计专用模型架构 → 从零开始训练。这个流程有三个致命问题:标注数据贵(人工标注10万条评论需要大量时间和金钱)、每个任务从头来(做完情感分析想做问答?得重新收数据、重新训练)、小数据训练能力有限(10万条数据训练出的模型不可能具备广泛的语言知识)。
"预训练+微调"反转了这个逻辑,分两步走:
第一步:预训练(Pre-training)。 在海量无标注文本上让模型自己学习语言的通用规律。互联网上有几乎无限的文本,不需要任何人工标注——每一段文本本身就包含了丰富的语法、语义、常识知识。让模型在这些文本上反复做"预测下一个词"或"完形填空",它就会逐渐建立起对语言的深层理解。这个过程像是让一个孩子从小大量阅读——不是为了某次考试,而是为了积累广博的语言底蕴。
第二步:微调(Fine-tuning)。 在预训练好的模型基础上,用少量任务相关的标注数据做最后的专门训练。相当于博览群书的孩子在考前做几套模拟题——因为有了深厚的底蕴,少量训练就能快速适配新任务。
为什么之前没人这么做?三个原因。第一,架构不支持——RNN/LSTM的顺序瓶颈让它们很难在超大规模文本上高效训练(第二章)。第二,算力不够——预训练需要在几十亿词上训练巨大的模型,2017年之前的GPU做不到(第三章)。第三,没有先例——在GPT和BERT之前,没人证明过无标注文本上的预训练能产生如此强大的迁移效果。
GPT和BERT的成功让"预训练+微调"成为NLP的新范式。从此几乎所有NLP工作都不再从零训练,而是在预训练模型基础上微调。这个范式转变也为后来的scaling打下了基础——预训练阶段可以利用无限的无标注数据和不断增长的算力来扩大模型规模,而模型越大、预训练越充分,微调后的效果就越好。这种"规模带来收益"的特性,正是大模型时代的底层逻辑(第六章)。
而"如何更好地预训练"和"以微调为代表的后训练(post-training)技术",后来成为了大模型领域研发的两大核心技术轴线——预训练决定了模型的"基础能力上限",后训练决定了模型能否"听话"并适配具体场景。第六章和第七章会分别展开这两条线。
GPT-1:一个"不被看好"的开始
2018年6月,OpenAI的Alec Radford、Karthik Narasimhan、Tim Salimans和Ilya Sutskever发表了《Improving Language Understanding by Generative Pre-Training》[1]——GPT(Generative Pre-Training,生成式预训练)由此得名。
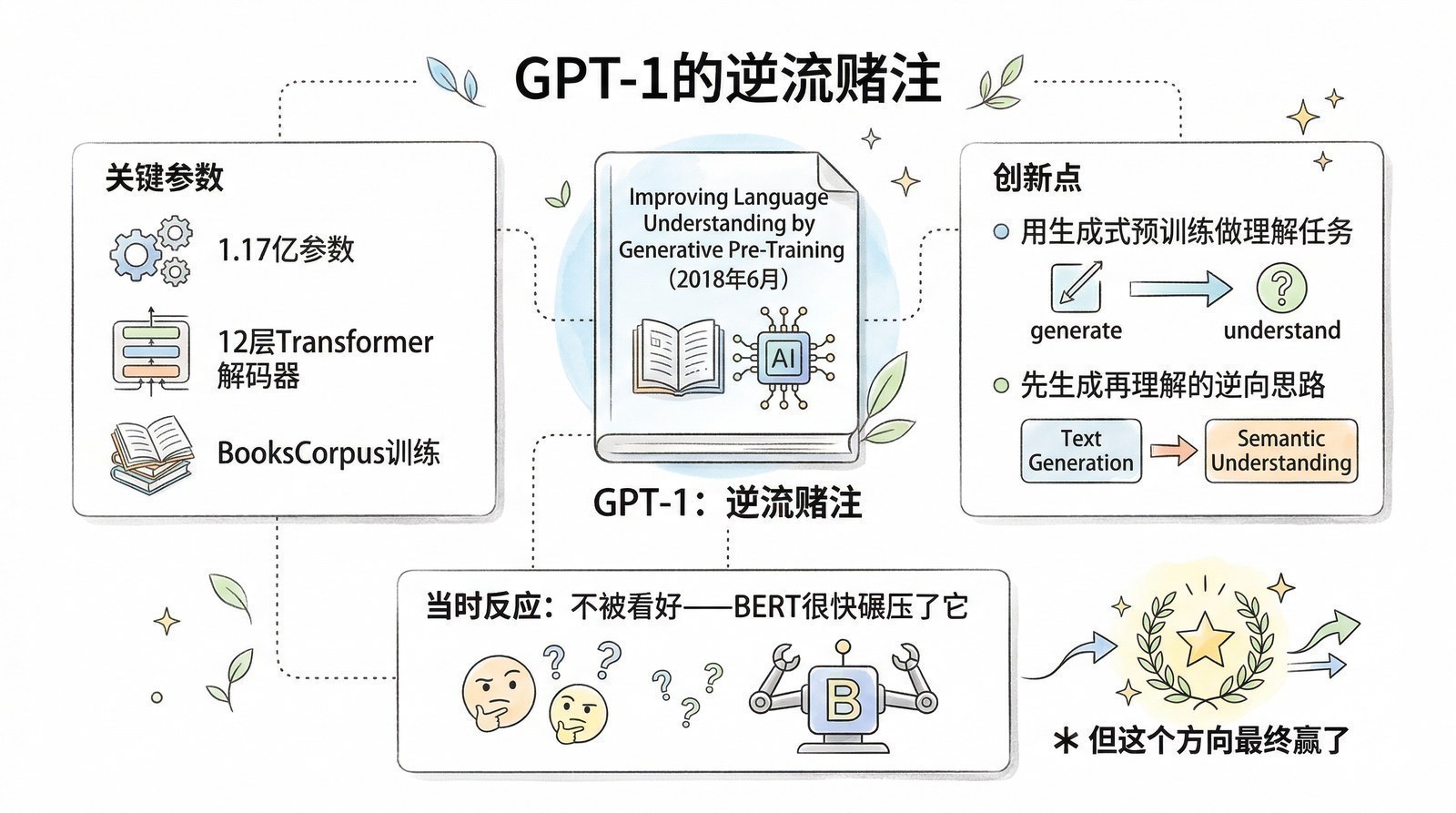
GPT-1的设计极其简洁:12层Transformer解码器,768维隐藏状态,12个注意力头,总参数约1.17亿。训练数据是BooksCorpus——约7000本未出版的电子书,共约8亿词。用8块GPU训练约30天。训练任务只有一个:从左到右预测下一个词——一种最朴素的语句续写训练。
这个选择在当时看起来既大胆又有些"笨"。"预测下一个词"是语言建模中最古老的任务——从1950年代Shannon的信息论就开始了。很多研究者认为这太简单,学不到深层的语言理解能力。更何况GPT-1只用了Transformer的解码器——等于放弃了双向理解能力,只让模型看"左边"的内容。在学术圈看来,这像是一个自我设限的选择。
但GPT-1的结果出人意料:预训练后只需少量微调,就在12个NLP基准中的9个上取得了当时最好的成绩。一个只学了"猜下一个词"的模型,居然能做文本分类、语义相似度判断、问答等一系列不相关的任务。
这暗示了一个深刻的可能性:为了准确预测下一个词,模型被迫学习了远比表面看起来深刻得多的知识。 预测"他去了"后面是什么需要语法知识,预测"医生给病人开了"后面是什么需要语义知识,预测"地球绕着"后面是什么需要世界知识,预测"下雨了但他没带伞所以他"后面是什么需要常识推理。看似简单的续写练习,实际上迫使模型建立了一个关于语言和世界的内部模型。
但在2018年,几乎没人把GPT-1当回事。1.17亿参数,效果还行但不够惊艳。学术圈的注意力很快被另一个名字吸引——因为几个月后,Google的BERT带着一份碾压级的成绩单来了。
BERT:横扫排行榜的"学霸"
2018年10月,Google的Jacob Devlin、Ming-Wei Chang、Kenton Lee和Kristina Toutanova发表了BERT[2]——Bidirectional Encoder Representations from Transformers。如果说GPT-1是一个不被看好的起步,BERT就是一场碾压式的亮相。
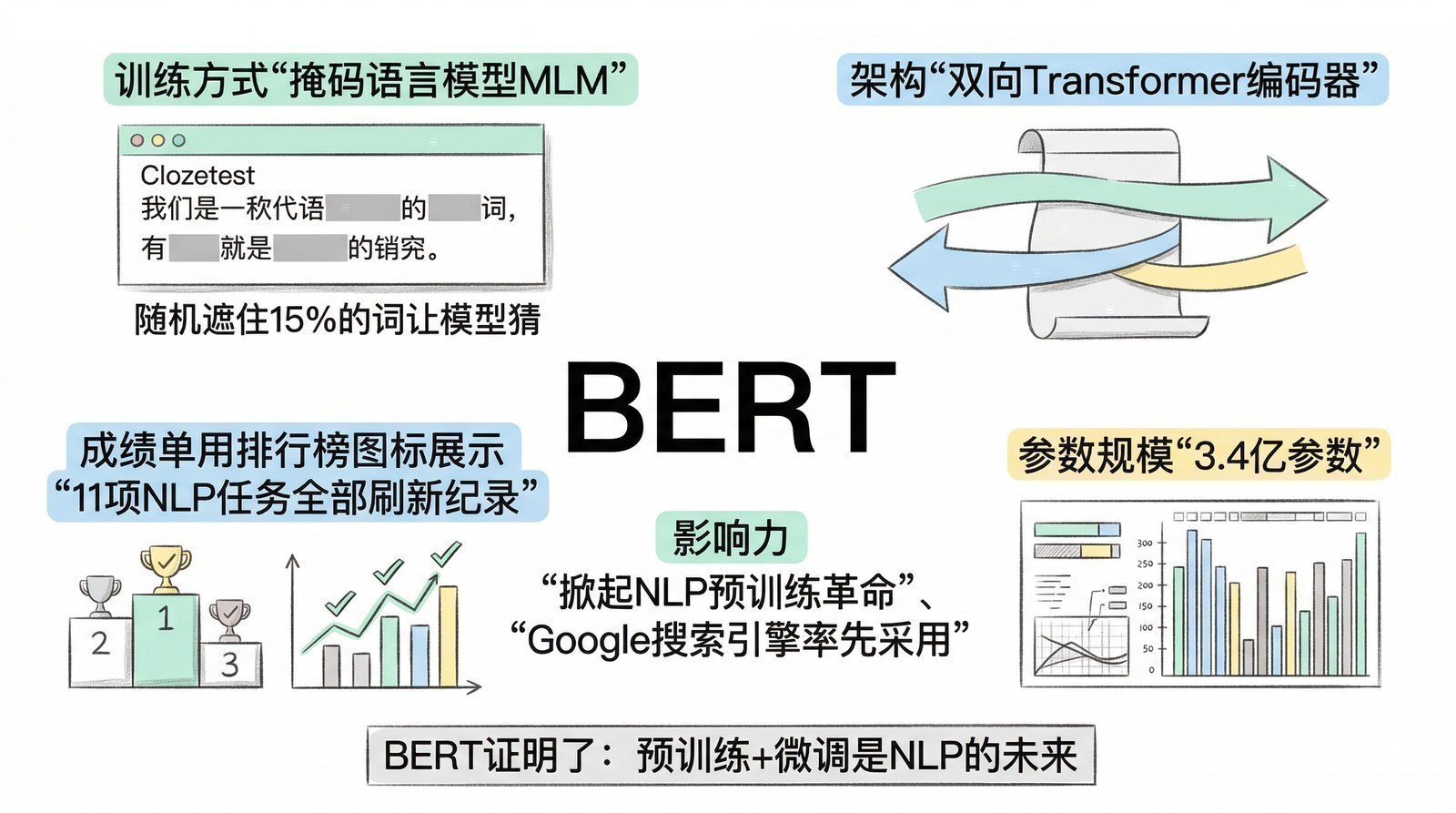
BERT只用Transformer的编码器,核心训练任务是完形填空(论文中叫Masked Language Model, MLM):随机遮住句子中15%的词,让模型根据上下文猜被遮住的是什么。同时还有一个辅助任务——下一句预测(NSP):给两个句子判断第二句是否是第一句的真正后续。
BERT有两个版本:Base(12层,1.1亿参数)和Large(24层,3.4亿参数)。训练数据是BooksCorpus加英文Wikipedia,共约33亿词——比GPT-1的数据量大约4倍。训练用了Google的TPU:16块TPU训练Base模型需要4天,64块TPU训练Large模型也需要4天。
BERT发表后的效果是核弹级的。它在11个NLP基准测试上同时刷新了最佳纪录——GLUE基准(当时NLP最重要的综合评测)上BERT-Large得分80.5,大幅领先之前的最佳成绩。SQuAD问答测试上甚至超过了人类标注者的表现。到2019年7月,基于BERT改进的模型在GLUE上的得分(88.4)已经超过了人类基线(87.1)。
2019年10月,Google宣布在搜索引擎中使用BERT来理解用户查询——这是Transformer首次被部署到影响十亿级用户的产品中。
在2018-2019年,如果你问NLP研究者"GPT和BERT谁更好",绝大多数人会毫不犹豫地回答BERT——效果更好、理论上更合理(双向总比单向强)、在学术界影响更大。GPT-1看起来只是BERT的一个弱化版本。
GPT-2:"太危险了,不能发布"
2019年2月,OpenAI发表了GPT-2[3]——论文标题《Language Models are Unsupervised Multitask Learners》本身就是一个大胆宣言。
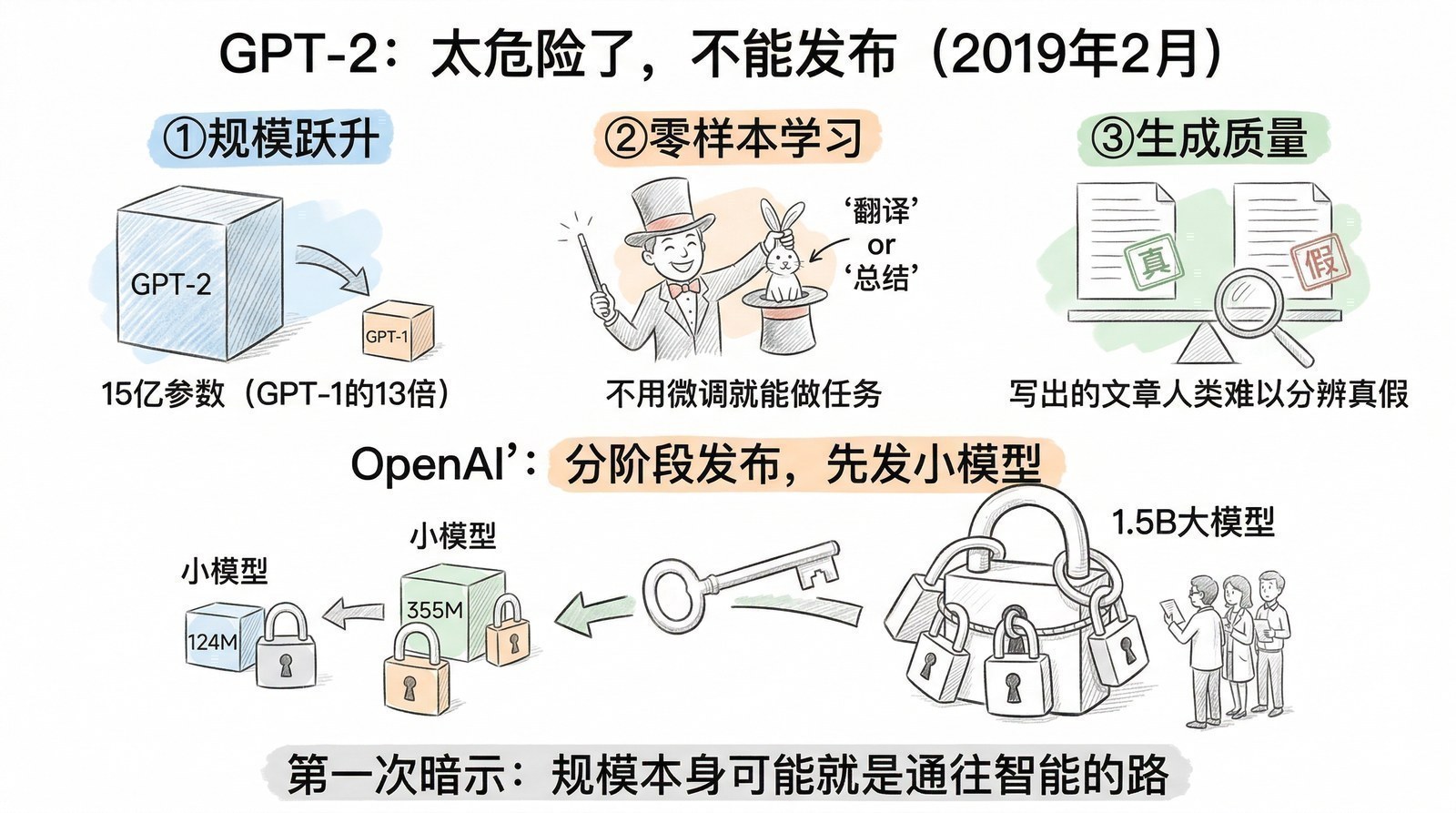
GPT-2是GPT-1的直接放大版:从12层到48层,参数从1.17亿增长到15亿(约13倍),训练数据从BooksCorpus换成WebText——从Reddit上高赞链接指向的约800万网页中爬取的40GB文本。架构完全不变,还是decoder-only Transformer,还是"预测下一个词"。唯一的变化就是更大。
但"更大"带来了质变。
GPT-2生成的文本质量达到了新水平——给一个开头,它能生成连贯、有逻辑、读起来像人写的几段话。更重要的是,它展现了一种GPT-1没有的能力——零样本学习(Zero-shot Learning):在没有对任何特定任务微调的情况下,GPT-2可以直接做翻译、做摘要、做问答——只要把任务描述成"续写"的形式。比如输入"把以下英文翻译成法文:Hello, how are you? →",GPT-2就能"续写"出法文翻译。
零样本学习的意义极其深远——它意味着你不需要为每个任务收集标注数据、训练专门的模型,只需要用自然语言"描述"你想做什么,模型就能理解并执行。这正是后来"提示词工程"(Prompt Engineering)的原型。 今天人们使用ChatGPT时写的每一条提示词,本质上都在利用GPT-2首次展示的零样本能力——用自然语言告诉模型"你要做什么",模型把你的指令当作"开头"来续写"答案"。从零样本学习到提示词工程,是同一种能力的不同表述:模型把所有任务理解为"续写",而你通过设计开头(提示词)来引导续写的方向。
OpenAI因此做出了一个前所未有的决定:以"太危险"为由延迟发布完整模型。 先发布小版本(1.24亿参数),之后分批发布更大版本,完整的15亿参数模型直到2019年11月才公开。这是AI领域第一次因为"模型能力太强"而限制发布,开启了至今仍在持续的AI安全辩论。
胜负已分:为什么GPT赢了未来
到2019年底,排行榜上BERT仍然领先。但GPT-2展示的生成能力和零样本能力暗示了一条BERT走不通的路。
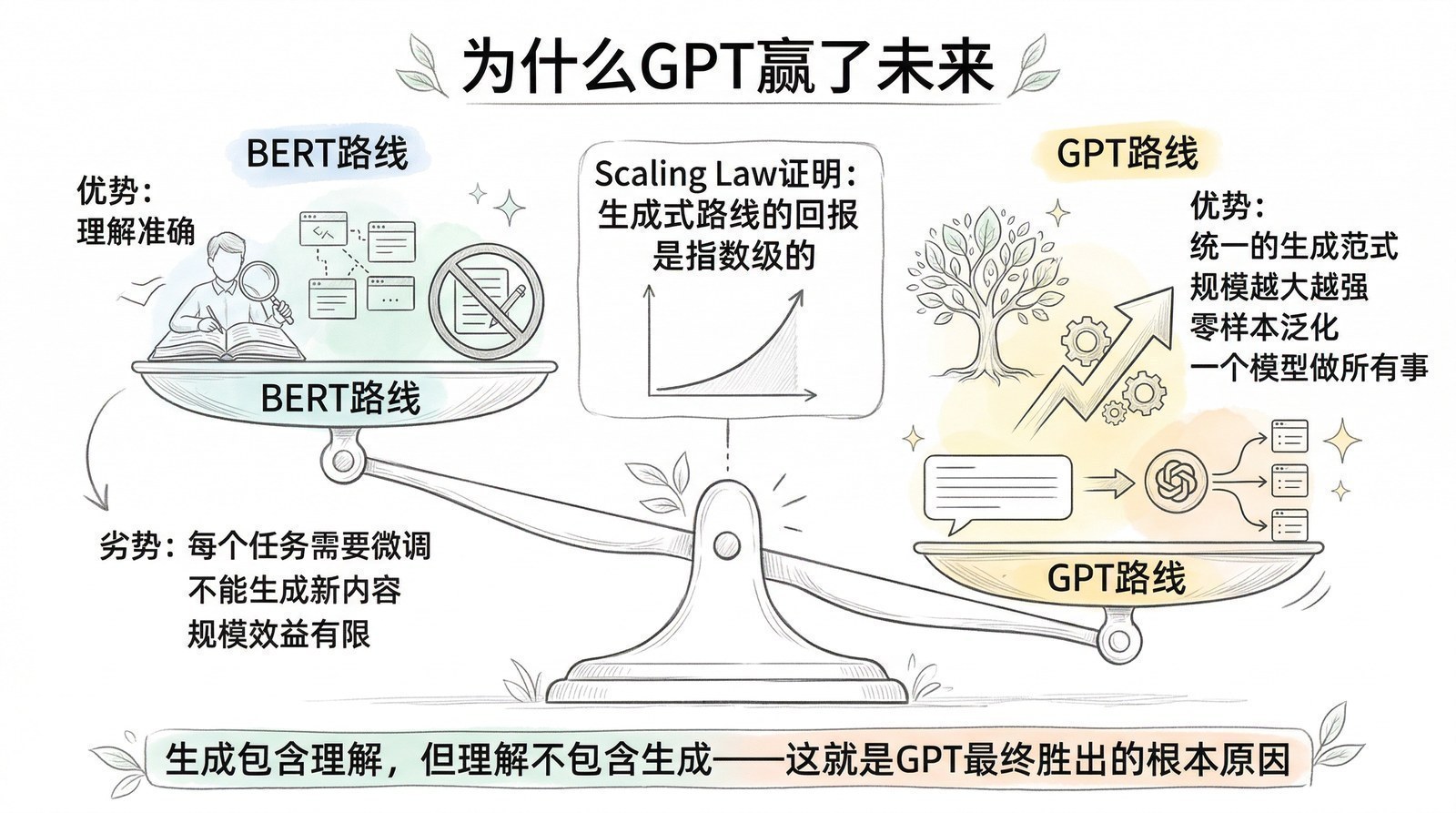
GPT最终赢得路线之争,有三个关键原因。
第一,生成比理解更通用。 BERT能理解但不能创造。GPT能创造——而创造天然包含理解。一个能写出正确答案的模型,必然已经理解了问题;但一个能理解问题的模型,不一定能写出答案。后来ChatGPT把所有任务都统一成了"生成":问答是生成答案,翻译是生成译文,编程是生成代码。
第二,GPT天然适合scaling。 "预测下一个词"极其简单,不需要人工标注,互联网上有近乎无限的文本作为训练数据。而BERT的"完形填空"每次只学习被遮住的15%的词,浪费了85%的计算。当规模从几十亿词扩展到几千亿词时,GPT更容易受益。
第三,GPT路线能"涌现"。 GPT-1只是不错的语言模型,GPT-2开始展现零样本能力,GPT-3(第六章)出现了让研究者震惊的涌现现象。这种"规模增长→新能力涌现"在BERT路线上从未出现过。
BERT像学霸——每门课都考高分,但只能做卷子上的题。GPT像会讲故事的人——开始讲得不太好,但随着积累,它学会了讲关于任何主题的故事——包括考试题的答案。 学霸赢了考试,讲故事的人改变了世界。
从GPT-1到GPT-2:一个被忽视的scaling信号
GPT-1到GPT-2的进化看似简单——"就是做大了"——但藏着一个当时几乎没人注意到的深刻信号。
GPT-1有1.17亿参数,GPT-2有15亿——规模增加约13倍。OpenAI发现:模型性能随参数规模呈现平滑的对数线性增长——参数每增加10倍,性能提升是可预测的、稳定的。
这意味着可以根据小模型的表现推断大模型的效果。2020年,OpenAI的Jared Kaplan等人把这个发现系统化为Scaling Laws for Neural Language Models[4]——证明大语言模型的性能与参数量、数据量、计算量之间存在可预测的幂律关系。这条Scaling Law给了行业前所未有的信心:只要投入更多算力和数据,模型就会变得更好,而且"更好"的程度可预测。 这种信心是后来数十亿美元级大模型投资的理论基础。第六章会展开这个故事。
这场路线之争留下的标志性事件
(1) BERT:从搜索引擎到"幕后英雄"
2019年10月,Google宣布在搜索排序中使用BERT,称其为"过去五年、也许是搜索历史上最大的一次飞跃"。BERT帮助搜索引擎理解自然语言中的细微差别——例如"can you get medicine for someone pharmacy"中的"for someone"到底指什么。
虽然BERT没有成为大模型时代的主角,但它活得很好——只是退到了"幕后"。今天BERT及其变体仍然广泛应用在搜索排序、广告匹配、垃圾邮件过滤、情感分析、语义匹配等"理解型"任务中。这些场景有一个共同特点:不需要生成文本,只需要理解文本的含义然后做判断。BERT的编码器架构恰好适合这类任务——速度快、部署成本低、效果好。
一个有趣的例子是Google翻译。Google翻译在2020年将原来的GNMT系统替换为Transformer编码器+RNN解码器的混合架构。Google的研究发现,翻译质量的提升主要来自Transformer编码器(理解输入),而Transformer解码器相比RNN解码器并没有显著优势,但RNN解码器的推理速度更快。所以他们做了一个务实的工程选择:用Transformer编码器来"理解",用更快的RNN解码器来"生成"。到2023-2024年,Google又开始用PaLM 2等大语言模型来提升翻译质量,并新增了110种语言的支持。Google翻译的技术演进本身就是BERT vs GPT路线之争的一个微缩版——"理解"和"生成"各有所长,工程实践中往往需要务实的组合。
(2) 从"Open"到"Close":OpenAI的身份变迁
GPT-2的"分阶段发布"是AI安全辩论的起点——但回头看,它也是OpenAI身份转变的起点。
2015年OpenAI成立时,名字中的"Open"就是承诺——Elon Musk、Sam Altman等人创办它的初衷是做一个开放的、非营利的AI研究机构,对抗Google等巨头对AI的垄断。GPT-1的论文和代码完全公开。GPT-2首次以"安全"为由限制发布,引发争议但最终还是公开了。到GPT-3(2020年),论文公开了但模型只通过付费API提供。到GPT-4(2023年),OpenAI不再公布模型参数量、训练数据、架构细节——论文变成了一份"系统卡",技术细节几乎为零。
AI社区开始戏称它为"CloseAI"。Elon Musk更是公开批评OpenAI违背了创立初衷,并在2024年起诉了OpenAI。与此同时,Meta走向了完全相反的方向——2023年开源LLaMA系列,2024年开源LLaMA 3,成为开源大模型的旗手。2025年初DeepSeek-R1的开源更是搅动了整个行业——一家中国公司用开源策略对抗美国的闭源巨头,让"开源vs闭源"的辩论又增加了中美竞争的维度。
这场从GPT-2开始的辩论至今没有定论:闭源可以保护商业利益和安全,开源可以加速创新和普惠。但可以确定的是,OpenAI从"Open"到"Close"的转变,深刻改变了整个AI产业的竞争格局——它逼出了Meta的LLaMA、Mistral的开源路线、DeepSeek的高效路线,某种意义上反而加速了AI技术的扩散。
(3) HuggingFace:"抱抱脸"——从青少年聊天机器人到AI界的GitHub
HuggingFace的故事本身就是一个精彩的"创业转型"案例。2016年,法国创业者Clément Delangue、Julien Chaumond和Thomas Wolf在纽约创办了一家公司,产品是面向青少年的AI聊天机器人——公司名字取自🤗(拥抱脸)这个表情。聊天机器人一度有10万日活用户,但增长遇到了天花板。
2018年Google发布BERT后,HuggingFace团队在一周之内就做出了BERT的PyTorch开源实现——这个速度让整个NLP社区震惊。他们意识到:真正的机会不在聊天机器人,而在于为AI开发者提供基础设施。2019年,HuggingFace正式转型,推出Transformers开源库——几行代码就能下载和使用BERT、GPT等预训练模型。
这次转型的成功程度超乎想象。Transformers库迅速成为GitHub上最受欢迎的AI项目之一(超过13万颗星),HuggingFace Hub成为全球最大的AI模型托管平台——截至2025年,托管超过100万个模型、50万个应用、19万个数据集,服务超过5万家企业用户(包括Intel、Pfizer、Bloomberg等)。2023年HuggingFace完成2.35亿美元D轮融资,估值45亿美元,投资方包括Google、NVIDIA、Salesforce等AI巨头。2024年营收约1.3亿美元。
Sequoia Capital的Pat Grady评价说:"他们把采用率放在了变现之前……他们看到Transformer从NLP扩展到所有领域,抓住了成为整个机器学习领域的GitHub的机会。"HuggingFace的成功验证了一个规律:在技术范式变革期,做"卖铲子"的平台往往比做"挖金子"的产品更有持久价值——就像第三章中NVIDIA在AI算力领域的故事一样。
这场路线之争告诉我们什么
为什么Google选择了编码器路线?
Google选择BERT的编码器路线,不是一个随意的技术决策——它深深扎根于Google的商业基因和技术传统。
Google最核心的产品是搜索。搜索的本质是"理解"——理解用户查询的意图,理解网页的内容,然后做匹配和排序。这是一个典型的"理解型"任务,不需要生成文本。编码器的双向注意力恰好完美匹配搜索需求——它能同时看到查询中所有词的上下文关系,全面理解用户想要什么。
同时,Google在2018年时已经拥有全球最强的AI基础设施——TPU集群、海量数据、顶尖人才。BERT的双向注意力在计算上比GPT的单向注意力更"重",但对Google来说这不是问题——它有的是算力。Google的思路是:既然我们有充足的算力,为什么不选一个理论上更"正确"的方向(双向理解确实比单向更全面),把它做到极致?
更深层的原因是Google的学术文化。Google Research/Brain的研究者们追求的是"学术上最优雅的方案"——双向理解在理论上比单向更完备、更符合语言学直觉。BERT的论文发表在学术顶会、横扫了所有排行榜,这正是Google研究文化所追求的"学术影响力"。
Google的选择在当时是完全合理的。BERT让Google搜索变得更好,让学术界拥抱了Transformer,推动了整个NLP的发展。只是后来的历史证明,"理解"不是AI的终点,"生成"才是通向通用智能的路——而这恰好不是搜索巨头的第一直觉。
为什么OpenAI选择了解码器路线?
OpenAI选择GPT的解码器路线,同样扎根于它独特的组织基因。
OpenAI成立于2015年,使命是实现"通用人工智能"(AGI)。这个目标决定了它必须寻找一条能"无限扩展"的路线——不是在某个特定任务上做到最好,而是找到一条通向通用能力的路。
"预测下一个词"这个训练目标看似简单,但它有一个其他方案不具备的特性:它是开放式的。情感分析有"正面/负面"两个答案,问答有标准答案,翻译有参考译文——这些都是"封闭"任务,做得再好也只是在特定范围内变强。但"预测下一个词"没有上限——因为准确预测下一个词需要的知识是无限的(语法、语义、常识、逻辑、世界知识……)。一个把这件事做到极致的模型,理论上需要"理解一切"——这恰好是AGI的方向。
另一个关键因素是Ilya Sutskever的直觉。Sutskever是OpenAI的首席科学家、GPT系列的核心推动者,也是深度学习先驱Geoffrey Hinton的学生。他在2016年就坚信"足够大的语言模型会展现出令人惊讶的通用能力"——这在当时是一个非常孤独的判断。大多数研究者认为"预测下一个词"太简单了,不可能产生真正的智能。但Sutskever看到了第四章"苦涩的教训"所揭示的规律:简单的方法配合大规模计算,总是最终胜出。
OpenAI的选择在2018年并不被看好——GPT-1在排行榜上输给了BERT。但他们坚持了下来,把GPT做大到GPT-2再到GPT-3,每一次scaling都验证了这条路线的潜力。最终GPT路线通向了ChatGPT和大模型时代——证明了Sutskever那个孤独的直觉是对的。
两个团队的选择都合乎各自的逻辑。Google从搜索出发,选了"理解"——这让搜索变得更好。OpenAI从AGI出发,选了"生成"——这通向了通用智能。路线的"对错"取决于你要去哪里。如果你的目标是让搜索更准确,BERT是正确答案。如果你的目标是创造一个能做一切事情的AI,GPT才是正确答案。
2019年底,路线之争还没有定论。真正的判决需要一次更大规模的实验——一个大到足以让"涌现"发生的模型。
2020年5月,OpenAI在1万块V100上训练了一个1750亿参数的模型——GPT-2的100多倍。它在零样本下就能做翻译、写代码、解数学题——很多能力从未被专门训练过,像是从规模中自发"涌现"出来的。
这个模型叫GPT-3。让它成为可能的不仅是更大的模型——还有一条关于"规模与能力的关系"的定律,重要到配得上一个独立的章节。
本章引用论文
[1] Improving Language Understanding by Generative Pre-Training (GPT-1), 2018, OpenAI (Radford, Narasimhan, Salimans, Sutskever)
[2] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, 2018, Google (Devlin, Chang, Lee, Toutanova)
[3] Language Models are Unsupervised Multitask Learners (GPT-2), 2019, OpenAI (Radford, Wu, Child, Luan, Amodei, Sutskever)
[4] Scaling Laws for Neural Language Models, 2020, OpenAI (Kaplan, McCandlish, Henighan et al.)
第六章:GPT-3的规模信仰——数据与算力的Scaling Law定律
当参数从15亿暴增到1750亿,AI不只是变得"更好"了——它开始做一些从未被专门训练过的事情,仿佛智能从规模中自发涌现
1750亿参数:一次改变AI历史的豪赌
2020年5月,OpenAI发表了论文《Language Models are Few-Shot Learners》[1],向世界展示了GPT-3——一个拥有1750亿参数的语言模型。
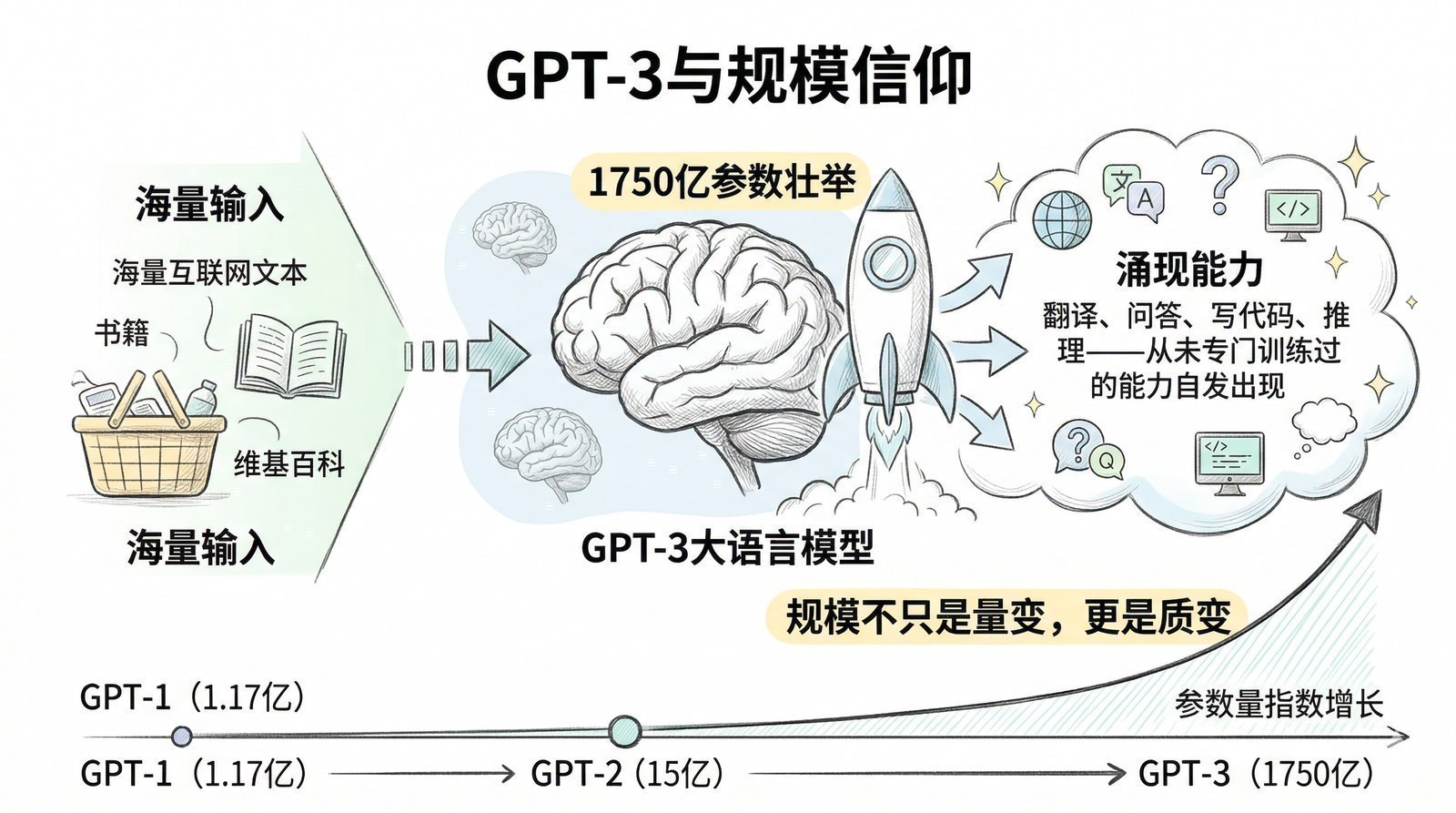
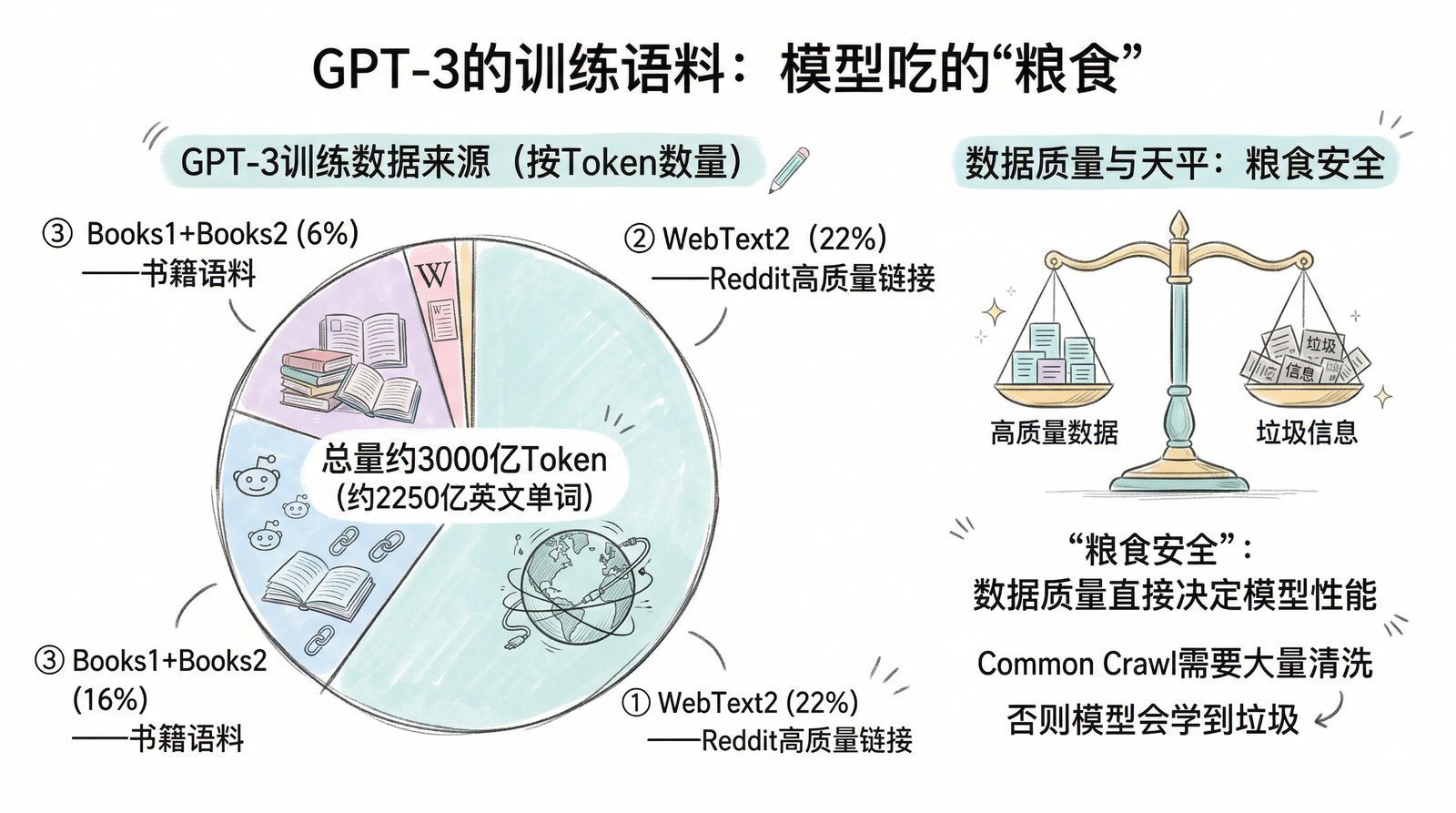
这个数字意味着什么?GPT-2是15亿参数,GPT-3是它的117倍。这个模型有96层Transformer解码器,12288维隐藏状态,96个注意力头。仅存储模型参数就需要350GB(FP16精度)——远超任何单块GPU的显存。微软为OpenAI专门打造了一台超级计算机——超过28.5万个CPU核心、1万块V100 GPU、每台GPU服务器400Gbps的网络带宽。
预训练语料:大模型吃的是什么"粮食"?
GPT-3的训练数据来自五个来源,总计约4990亿token。但"token"和"训练语料"这些概念对非技术读者可能不太直观,值得花点篇幅解释。
大模型的预训练语料,就是模型"读"的书——只不过它读的不是精选的教科书,而是互联网上能找到的几乎一切文本。GPT-3的五个数据来源分别是:
Common Crawl(4100亿token,占比最大)——一个非营利组织从2008年开始做的事:用爬虫程序系统性地下载互联网上的网页,打包存档。到2020年它已经积累了数十TB的原始网页数据——新闻、博客、论坛、百科、商品页面、政府文件……几乎涵盖了互联网上的一切。但原始数据充满了垃圾——广告、导航栏、Cookie提示、重复内容、乱码——OpenAI用一个质量分类器过滤掉了大量低质量内容,只保留了"看起来像人写的正经文章"的部分。
WebText2(190亿token)——GPT-2时代发明的数据集的升级版。核心思路是用Reddit的投票机制作为质量过滤器:只爬取Reddit上获得3个以上赞的链接所指向的网页。逻辑是:如果真人觉得这个链接值得点赞,那它指向的内容大概率是有质量的。
两个图书语料库(共670亿token)——大量电子书的文本,提供长篇连贯的叙事和论述,弥补网页数据碎片化的不足。
英文维基百科(30亿token)——结构化的百科知识,覆盖广泛的事实性信息。
为什么这些数据能成为大模型的训练语料?因为大模型的预训练任务是"预测下一个词"——给定前面的文本,猜下一个词是什么。要完成这个任务,模型需要从文本中学习语法规则、语义关系、常识知识、推理模式。而互联网文本恰好包含了人类知识的一个巨大横截面——从烹饪食谱到量子物理,从小说对话到法律条文。模型通过"读"这些文本来"预测"下一个词,就像一个孩子通过大量阅读来理解世界。
训练过程:什么叫"看了3000亿token"?
GPT-3在这4990亿token的语料上训练了3000亿token。这是什么意思?
一个"token"大约相当于英文中的一个常用词或词的一部分(比如"understanding"可能被拆成"under"和"standing"两个token)。中文中一个token大约对应1-2个汉字。
"训练了3000亿token"的意思是:模型总共做了3000亿次"预测下一个词"的练习。每次练习是这样的——从语料中取出一段连续文本(比如"今天天气很好适合出去散步"),模型看到"今天"后要预测"天气",看到"今天天气"后要预测"很",看到"今天天气很"后要预测"好"……每预测一个token就算一次练习,预测对了奖励(损失函数降低),预测错了调整参数。3000亿次这样的练习,模型的参数就从随机初始值逐渐调整到了能够准确预测各种文本的状态。
但语料总量是4990亿token,为什么只训练了3000亿?因为不同来源的数据被赋予了不同的采样权重——高质量数据(如维基百科和图书)被重复采样多次,低质量数据(如Common Crawl)只被采样一小部分。这意味着有些训练样本被模型"看"了不止一次(比如维基百科的内容可能被看了3-4遍),而有些只被看了不到一次(比如Common Crawl中大量内容只被看了0.4遍就跳过了)。平均下来,每个token大约被看了0.6次。这种差异化采样是刻意的——让模型在高质量数据上学得更深,在低质量数据上浅尝辄止。
粮食安全:训练语料直接决定模型性能
大模型吃什么"粮食"训练,直接决定了它有多"聪明"。这不只是"数据越多越好"那么简单——数据的质量、多样性和清洗程度同样关键。
GPT-3的经验暴露了一个严峻问题:互联网上的原始数据大部分是"垃圾食品"。Common Crawl的原始数据中,真正高质量的内容可能不到十分之一——其余都是广告、垃圾邮件、自动生成的内容、重复的模板页面。如果不做过滤直接喂给模型,就像让一个孩子只吃垃圾食品长大——可能长得很快(损失函数下降很快),但学到的"知识"充满了错误和偏见。
2023年,阿联酋Technology Innovation Institute发布的RefinedWeb数据集证明了:对同样的Common Crawl原始数据,如果用更严格的清洗流程(精确去重、模糊去重、URL黑名单过滤、文本质量评分等),处理出来的数据集训练出的模型性能可以显著提升。基于RefinedWeb训练的Falcon系列模型达到了接近LLaMA的性能——证明了精心清洗的互联网数据就足以训练出一流大模型,不需要昂贵的版权数据。
在图文数据方面,2022年一个由志愿者组成的非营利组织LAION发布了LAION-5B——包含58亿图文对的开放数据集。这是当时最大的公开图文数据集,对Stable Diffusion等AI绘画模型的训练至关重要(第八章)。LAION用一群志愿者的协作证明了开源社区的力量可以与科技巨头的数据资源竞争。
训练语料的质量和规模,是大模型的"粮食安全"问题。Chinchilla论文(本章后文详述)进一步证明了数据量甚至比模型参数更重要——如果数据不足,即使把模型做得再大也无法充分发挥。对于从业者而言,在构建大模型的竞争中,数据的获取、清洗和管理能力是一种容易被低估但至关重要的核心竞争力。
"涌现":规模带来的质变
GPT-3展示了一种被后来称为"涌现"(Emergence)的现象——模型在没有被专门训练过的任务上,突然表现出很强的能力,而且这些能力是在模型达到一定规模后才出现的。
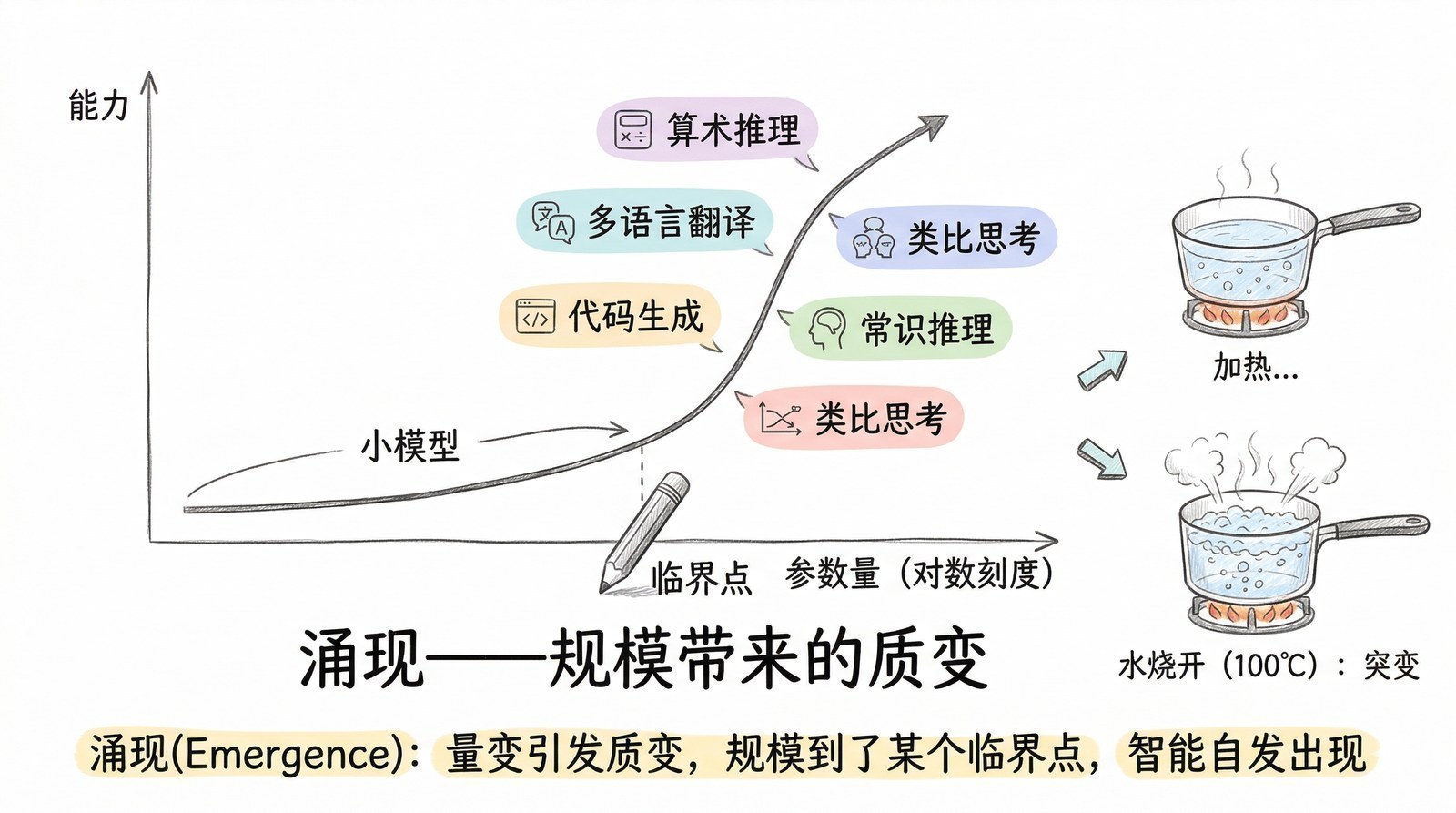
GPT-2有一些零样本能力但不稳定。GPT-3不一样——它在完全没有微调的情况下就能做到:写出人类几乎无法分辨的新闻文章(人类判断者只有52%的准确率分辨真假)。做三位数加减法——从未被训练过做算术。把自然语言描述翻译成代码。在没有任何翻译训练的情况下做出不错的翻译。回答常识推理问题。
更令人震惊的是GPT-3的少样本学习(Few-shot Learning)能力。举一个具体例子:你在输入中写下三个"英文→法文"的翻译对——"sea otter → loutre de mer, peppermint → menthe poivrée, cheese → fromage"——然后写"plaid shirt →",GPT-3就能续写出"chemise à carreaux"(格子衬衫的法文)。你没有修改模型的任何参数,没有做任何微调——只是在输入中给了几个"示范",模型就学会了这个模式。
这和传统的机器学习完全不同。传统方式下,要让模型做翻译需要收集百万级的平行语料然后训练几周。GPT-3只需要看三个例子——几秒钟——就能做出合理的翻译。这种能力被称为"上下文学习"(In-Context Learning)——模型在推理过程中"学习"了输入中的模式,而不需要更新自身参数。
泛化,泛化,还是泛化
GPT-3论文的标题精确地概括了这个发现:语言模型是少样本学习者。不需要微调,不需要针对每个任务收集标注数据。一个模型,通吃一切。
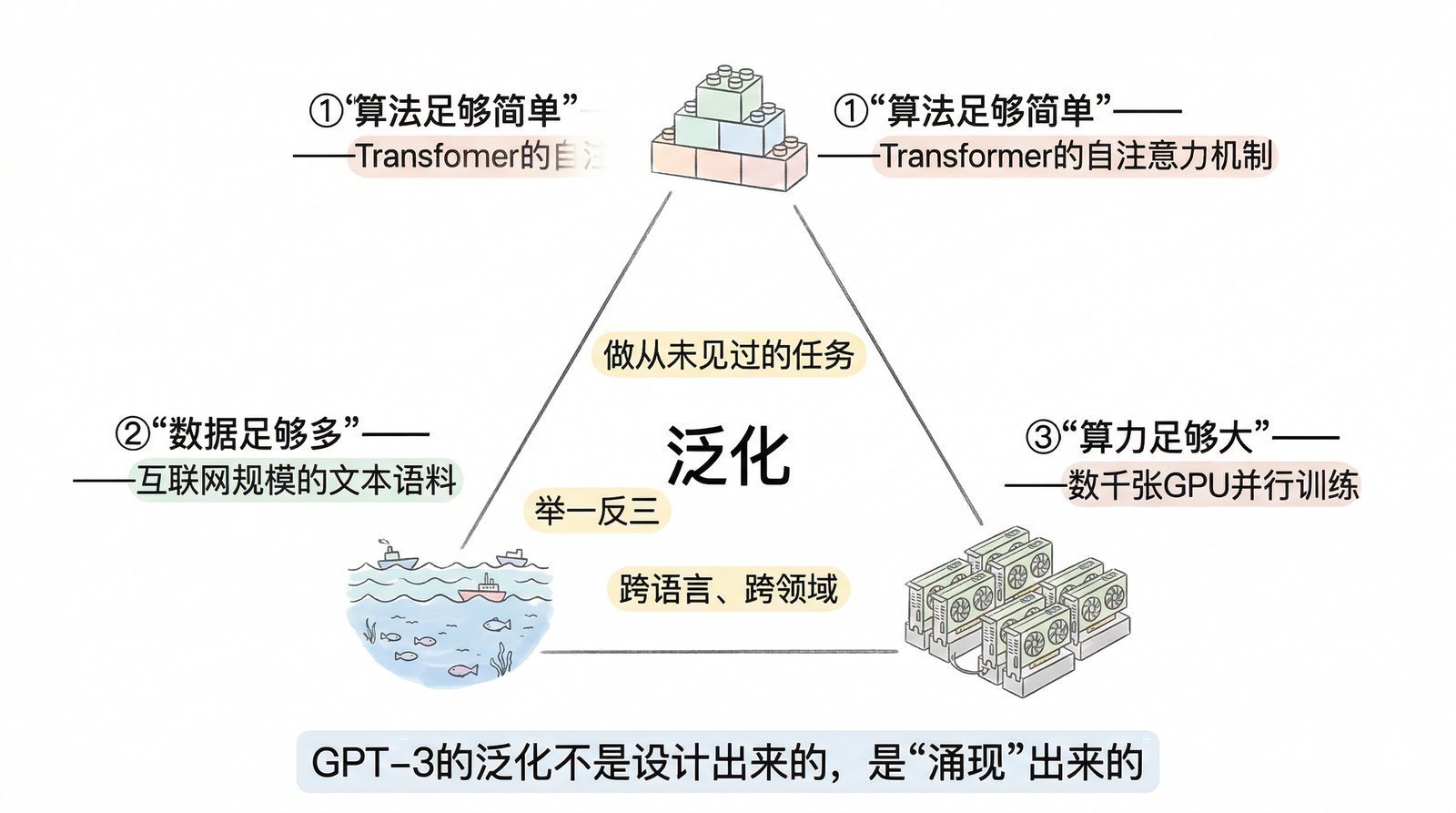
这个"通吃一切"的能力有一个更准确的技术名称——泛化性(Generalization)。泛化性指的是模型在从未见过的新任务上也能表现良好的能力。GPT-3的泛化性之强,在2020年是前所未有的:它能做翻译、做算术、写代码、做问答、做摘要、做类比推理、做常识判断——这些任务从未出现在它的训练目标中(训练目标只有一个:"预测下一个词"),也从未被专门训练过。
是什么创造了如此强大的泛化性?
GPT-3的泛化性来自三个条件的叠加——它们缺一不可:
第一,足够简单的算法。GPT-3的架构就是标准的Transformer解码器(第四章的"榫卯结构"),训练目标就是"预测下一个词"。没有为翻译设计专门的模块,没有为算术设计专门的损失函数,没有为代码理解设计专门的注意力头。极致的简单性意味着模型不会被任何特定任务的假设所限制——它被迫从数据中自己学习一切。正是因为没有被"教"如何翻译,它才能通过"预测下一个词"这个简单任务,自发地从海量文本中"领悟"翻译的规律。
第二,海量的数据。4990亿token的训练语料覆盖了人类知识的巨大横截面——其中自然包含了翻译的例子(互联网上有大量双语内容)、算术的例子(网页和教材中有大量数学表达式)、代码的例子(GitHub上的开源代码被Common Crawl爬取了大量)、常识推理的例子(问答网站和百科全书中充满了因果推理)。模型不是凭空"发明"了翻译或算术的能力——它是从数据中"统计性地学到"了这些模式。数据越多、越多样,模型能学到的模式就越丰富,泛化性就越强。
第三,极致的算力规模。1750亿参数的模型在1万块V100上训练数月——这需要的算力在2020年是天文数字。但正是这个规模让模型有足够的"容量"来存储和组织从海量数据中学到的知识。一个1亿参数的模型可能知道"cat"是"猫",但要理解"一只慵懒的猫躺在温暖的阳光下"和"A lazy cat was lying in the warm sunshine"之间的对应关系——需要的不仅是词汇对应,还有语法结构、时态转换、修辞风格的理解——这需要几百亿甚至上千亿参数的容量。
简单的算法 × 海量的数据 × 极致的算力 = 强大的泛化性。
这个公式是大模型时代最重要的"配方"。而它的精确数学表达,就是下一节要讲的Scaling Law。
Scaling Law:从直觉到定律
2020年1月(比GPT-3论文早了4个月),OpenAI的Jared Kaplan等人发表了《Scaling Laws for Neural Language Models》[2]。这篇论文把"模型越大效果越好"这个直觉变成了精确的数学定律。
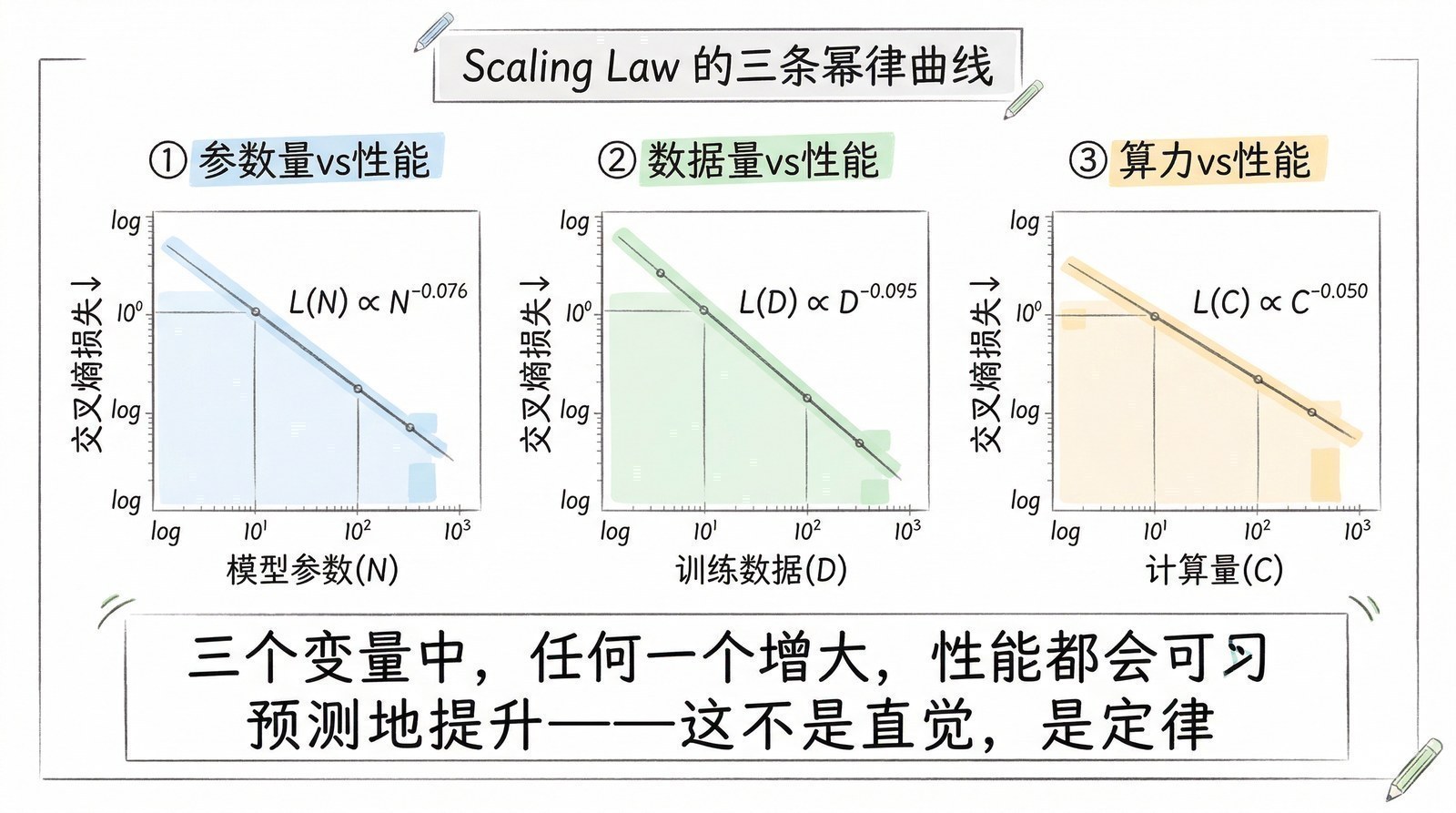
三条幂律曲线
Kaplan等人系统地训练了不同规模的语言模型(从几千个参数到数十亿参数),发现了三条惊人稳定的规律:
第一条:模型越大,效果越好。当训练数据和计算量充足时,模型的预测准确度随参数量的增加而平滑提升。参数每增加10倍,模型的错误率大约降低一个固定的比例——而且这条曲线跨越了好几个数量级(从百万参数到十亿参数)都保持稳定,没有出现"天花板"。也就是说,你有充分的理由相信从十亿到千亿参数,这条曲线还会继续保持。
第二条:数据越多,效果越好。当模型足够大且计算量充足时,训练数据量每增加10倍,错误率的降低幅度甚至比增加参数还大。这暗示了一个重要信号:在某种意义上数据可能比参数更重要——后来的Chinchilla论文证实了这一点。
第三条:算力越多,效果越好。把参数和数据综合考虑,总计算量(用FLOPS衡量)每增加10倍,模型的错误率降低一个可预测的比例。
三条曲线的共同特征是:它们是平滑的、可预测的、跨越多个数量级保持稳定的。这意味着你可以用小规模实验来预测大规模结果——在花几百万美元训练大模型之前,先花几万美元训练小模型,就能合理推断大模型会达到什么水平。
一个改变行业的发现
Scaling Law的产业意义是革命性的。在此之前,训练大模型是一场豪赌——你不知道花1000万美元训练的模型是否会比花100万的好多少。Scaling Law之后,它变成了一次可计算的投资。你知道多花10倍的钱大概能带来多少提升,你可以做成本收益分析,你可以向投资人展示一条清晰的"投入→产出"曲线。
Scaling Law给了整个行业一种前所未有的信心:只要你愿意投入更多的算力、数据和参数,模型就会变得更好——而且"更好"的程度是可预测的。这种信心是后来数十亿美元级别大模型投资的理论基础。没有Scaling Law,没有人敢花几亿美元训练GPT-4。
Chinchilla:Scaling Law的重要修正
Kaplan的2020年论文有一个偏差:它认为在固定计算预算下应优先把模型做大,而不是用更多数据训练。GPT-3正是基于这个思路设计的——1750亿参数只用了3000亿token训练。
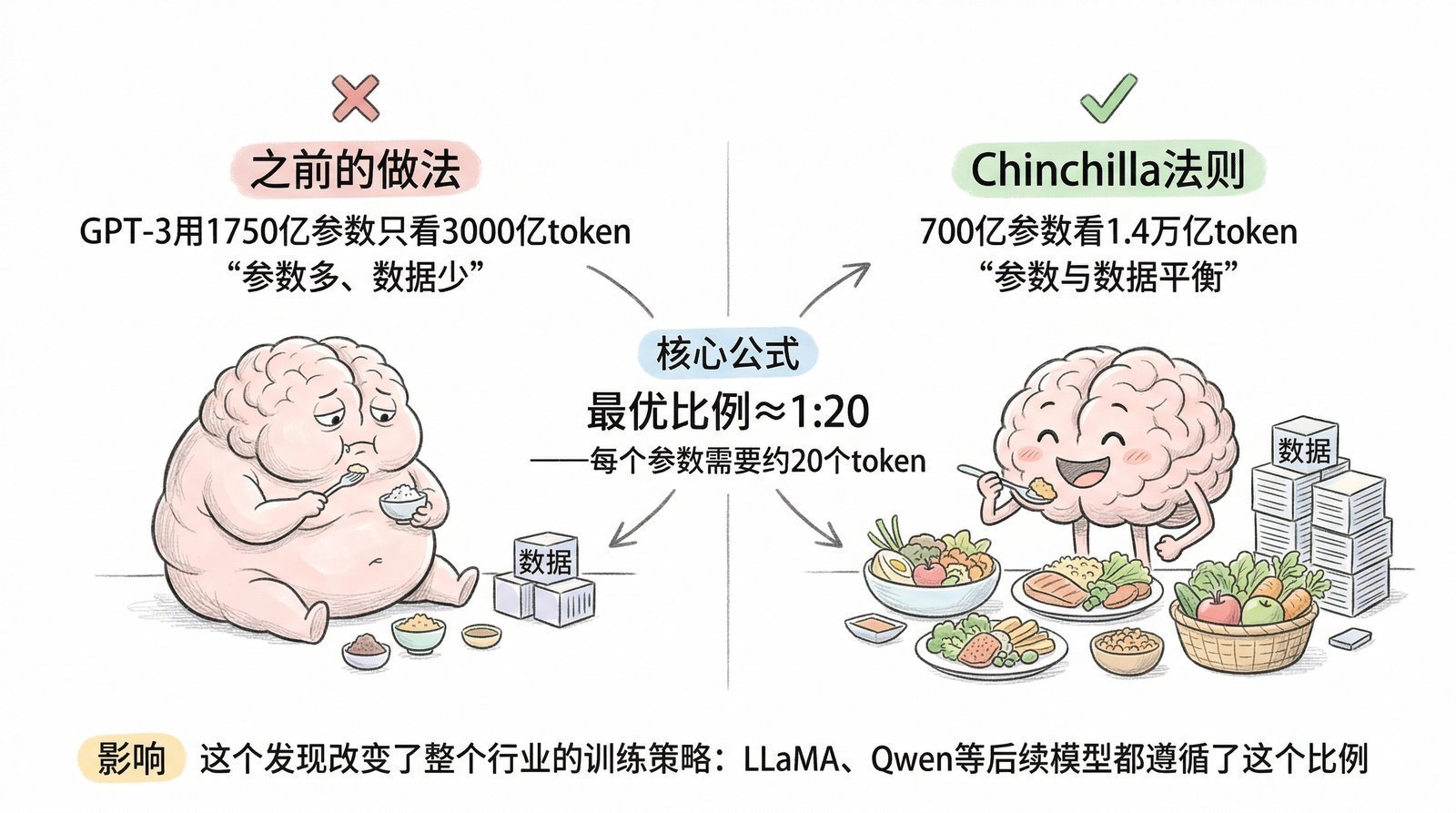
2022年,DeepMind的Jordan Hoffmann等人发表了Chinchilla论文[3],做了关键修正。
Chinchilla团队训练了400多个不同规模的模型(从7000万到160亿参数),每个规模都用不同数据量训练,系统地测量了最优的参数-数据比。核心发现是:最优的参数量和训练数据量应该等比例增长,大约1:20的比例——每10亿参数需要约200亿token的训练数据。
按这个标准,GPT-3的数据严重不足。1750亿参数理论上需要约3.5万亿token的训练数据,但实际只用了3000亿token——差了一个数量级以上。
DeepMind训练了700亿参数的Chinchilla,用了1.4万亿token——虽然参数只有GPT-3的40%,但数据量是4.7倍。结果Chinchilla在几乎所有基准测试上都超过了GPT-3。这个反直觉的结果——更小的模型用更多数据训练反而更好——深刻影响了后续的技术路线。Meta的LLaMA(650亿参数,1.4万亿token)和DeepSeek系列都采用了Chinchilla的"数据优先"哲学。
Chinchilla把"越大越好"修正为更精确的表述:模型大小和数据量要匹配,两者都不能偏废。算力应该被均衡分配给"更大的模型"和"更多的数据"。
让万卡集群跑起来:算力基础设施(Infra)的进化
GPT-3需要1万块GPU协同工作数月。让这件事从"理论上可行"变成"工程上可行",需要一系列算力基础设施的创新。
算力基础设施为什么越来越重要?
很多人直觉上认为AI发展的优先级是"算法>数据>算力"——最聪明的算法才是核心竞争力。但在Transformer统一架构之后(第四章),这个优先级正在发生逆转,变成了"算力>数据>算法"。
为什么?因为当所有人都在Transformer框架下做小修小改时,算法层面的差异化越来越小——而且大多数算法创新都会通过论文公开。数据是资源,虽然各家的数据配比和清洗方式有差异,但核心语料(Common Crawl、维基百科、GitHub代码等)大家基本都能拿到。真正拉开差距的,是算力基础设施的效率——同样的GPU数量,不同的集群架构、通信优化、容错机制,在单位时间内能完成的模型迭代次数可能差出一个数量级。
这个差距在当前最新的强化学习范式(第十章)下会更加明显。预训练是"一次性"的大规模训练,强化学习则需要模型反复试错、反复迭代——对算力基础设施的吞吐能力和稳定性提出了更极致的要求。
四面"墙"的突破
ZeRO[4]解决了显存墙——把训练时的内存需求在数据并行的各GPU之间分摊,让GPT-3规模的模型训练成为可能(详见第三章)。
Megatron-LM[5]解决了通信墙——让单层Transformer的矩阵乘法可以切分到多块GPU上并行,结合流水线并行形成"3D并行"标准配方(详见第三章)。
FlashAttention[6]解决了速度墙——2022年斯坦福大学Tri Dao发表的这篇论文,解决了自注意力计算中GPU在"搬数据"而不是"算数据"的效率问题。核心思路是把注意力计算分成小块(tiling),每块在GPU片上的高速SRAM中完成,避免把巨大的注意力矩阵反复搬入搬出慢速的HBM。效果立竿见影:速度提升2-4倍,显存降低数倍。2023年的FlashAttention-2[7]在H100上达到了理论FLOPS的72%。FlashAttention后来成为从GPT-4到LLaMA到DeepSeek几乎所有大模型的标准组件。
MegaScale[8]解决了容错墙——当集群达到万卡规模,硬件故障是必然事件。字节跳动2024年的论文披露:万卡集群每训练约100小时就会遇到一次需要重启的故障。他们建立了自动故障检测、自动踢除故障GPU、自动从检查点恢复的完整容错体系。这些看似不"性感"的工程细节,实际上是大模型训练能力的硬门槛。
算力决定命运:为什么是量化基金孵化了DeepSeek
如果说算力基础设施越来越成为大模型竞争的核心变量,那么一个看似匪夷所思的事实就变得可以理解了——全球最具效率的开源大模型DeepSeek,竟然诞生于一家量化对冲基金。
幻方量化由梁文锋于2015年创立,2016年率先将深度学习用于股票交易——用GPU计算交易仓位,这在当时的中国量化圈几乎是独一份。到2017年底,幻方的所有量化策略都已经全面AI化。
算法建模和算力基础设施,恰好是量化交易最核心的两种能力。量化基金每天要处理海量的市场数据、运行复杂的模型、在毫秒级别做出交易决策——这对算力的需求极其苛刻。幻方很早就遇到了算力瓶颈:2019年,他们自研"萤火一号"AI集群,初始搭载约500块GPU,2020年正式投用时扩容至约1100块。2021年,又斥资10亿元建设"萤火二号",配备上万块NVIDIA高性能加速卡,200Gbps高速网络互联和自研分布式文件系统(3FS)。2022年萤火二号算力扩容翻倍,全年运行任务135万个,累计5674万GPU时,平均占用率96%。
到2022年ChatGPT横空出世之前,幻方已经悄悄成为中国算力储备最深厚的民营机构之一——国内拥有超过1万块GPU的企业不超过5家,而幻方是其中唯一的量化基金。
2023年5月,梁文锋将幻方的技术团队独立出来,成立深度求索(DeepSeek),进军通用人工智能。DeepSeek继承了幻方两方面的核心积累:一是强大的算力基础设施运营能力(如何让万卡集群稳定高效地运行),二是极致的效率意识(量化交易出身的团队天然追求"用最少的资源做最多的事")。
这就解释了为什么DeepSeek-V3只用2048块H800 GPU就完成了训练(Meta的LLaMA 3.1用了超过16000块H100),为什么DeepSeek-R1的训练成本只有OpenAI o1的一个零头。这种极致效率不是一朝一夕练出来的——它是从2019年萤火一号开始、历经五年万卡级集群运营积累出来的深厚"基建能力"。
算力基础设施的重要性,在幻方/DeepSeek的故事中得到了最生动的体现:决定大模型竞争胜负的,不仅是谁的算法最聪明、谁的数据最多——更是谁能在单位时间内、用同样的GPU做出最多次高质量的模型迭代。
从GPT-3到Scaling Law:规模信仰的三重验证
2020-2022这三年,GPT-3、Scaling Law和Chinchilla从三个不同角度验证了同一个结论,形成了一条完整的逻辑链——这条逻辑链是理解整个大模型时代的钥匙。
第一重验证来自GPT-3本身:规模带来涌现。GPT-2(15亿参数)有模糊的零样本能力,GPT-3(1750亿参数)的零样本和少样本能力强到可以直接使用——而且多出来的能力(算术、代码、推理)不是被教会的,是在规模增长中自发出现的。这证明了"把模型做大不只是量变,到一定规模会产生质变"。
第二重验证来自Scaling Law:这种涌现是可预测的。Kaplan等人证明了模型性能随参数、数据和算力的增长遵循平滑的幂律曲线——跨越多个数量级保持稳定。这意味着涌现不是偶然的"撞大运",而是一种有规律的物理现象:你投入了多少资源,就能预期获得多少回报。
第三重验证来自Chinchilla:最优的资源分配方式已经被找到。不是盲目做大模型,而是模型参数和训练数据要按比例匹配。700亿参数的Chinchilla用更多数据训练后超越了1750亿参数的GPT-3——说明Scaling的关键不是单一维度的"堆参数",而是参数、数据、算力三者的均衡配置。
三重验证叠加的结论是:大模型的发展不是玄学,而是一门可以精确规划的工程学科。你知道该做多大的模型(Scaling Law),该用多少数据(Chinchilla),该投入多少算力(幂律曲线),以及预期能达到什么效果(可预测的性能提升)。这种确定性是大模型产业化的基础——它把AI研发从"天才的灵感"变成了"工程师的规划"。
而支撑这一切的基础设施——从ZeRO到FlashAttention到万卡容错——让这些规划可以被执行。幻方/DeepSeek的故事则证明了:在这个"规模决定命运"的时代,谁能最高效地运营算力基础设施,谁就拥有最大的竞争优势。
这一章告诉我们什么
算法、数据、算力:优先级的逆转
AI发展的三要素是算法、数据和算力。在大模型之前,多数从业者的直觉排序是"算法>数据>算力"——最聪明的算法是核心竞争力,数据和算力只是辅助。
但在Transformer统一架构之后,这个排序正在发生深刻的逆转。
算法的差异化在缩小。当所有人都在Transformer框架下做变体时,算法层面的创新空间已经被压缩了——而且绝大多数算法创新会通过论文公开,几周内就被全行业复现。MoE、GQA、RoPE这些重要的架构改进,发明者和使用者之间的时间差越来越短。
数据是资源,大家基本都能获取。核心语料(Common Crawl、GitHub、维基百科、学术论文)是公开的,各家的差异主要在数据清洗和配比上——这是有价值的know-how,但不是不可逾越的壁垒。Chinchilla和RefinedWeb证明了:用好公开数据,就能训练出一流的模型。
真正拉开差距的,是算力基础设施。同样是1万块GPU,不同团队的集群在单位时间内能完成的有效模型迭代次数可能差出数倍。这取决于互连网络的拓扑和带宽、分布式训练框架的通信效率、容错和恢复机制的成熟度、GPU利用率的优化水平。这些"工程能力"没有论文可以复现——它们是在长期运营万卡集群的过程中积累出来的隐性知识。
幻方/DeepSeek的故事就是这个趋势的最佳注脚:一家量化基金之所以能做出比肩OpenAI的大模型,不是因为它的算法比Google更聪明,而是因为它从2019年开始就在积累万卡集群的运营能力——而这种能力,在大模型时代的价值远超人们的直觉预期。
规模不是蛮力,而是一种可计算的策略
GPT-3的成功不是"暴力堆参数"——Scaling Law提供了数学基础,Chinchilla修正了最优配比,ZeRO/FlashAttention/MegaScale提供了工程手段,RefinedWeb/LAION-5B提供了数据基础。每一个环节都是必要条件,缺一不可。
对从业者和投资人而言,Scaling Law最大的启示是"投入产出关系可预测"。这把AI研发从"碰运气"变成了"做规划"——你可以估算训练什么规模的模型需要多少资源、会达到什么性能,然后做理性的投资决策。这种可预测性是大模型产业化的基础。
但GPT-3也暴露了一个严重问题——它虽然能力惊人,但不可控。它会"幻觉"(编造不存在的事实),会说出有偏见或有害的内容,不遵循用户指令。一个强大但"不听话"的模型,无法变成产品。
如何让GPT-3"听话"?这个问题的答案催生了2022年最重要的AI事件——ChatGPT的诞生。
本章引用论文
[1] Language Models are Few-Shot Learners (GPT-3), 2020, OpenAI (Brown et al.)
[2] Scaling Laws for Neural Language Models, 2020, OpenAI (Kaplan, McCandlish, Henighan et al.)
[3] Training Compute-Optimal Large Language Models (Chinchilla), 2022, DeepMind (Hoffmann et al.)
[4] ZeRO: Memory Optimizations Toward Training Trillion Parameter Models, 2019, Microsoft (Rajbhandari et al.)
[5] Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism, 2019, NVIDIA (Shoeybi et al.)
[6] FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness, 2022, Stanford (Dao et al.)
[7] FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning, 2023, Stanford (Dao)
[8] MegaScale: Scaling Model Training to More Than 10,000 GPUs, 2024, ByteDance (Jiang et al.)
第七章:让AI听话——人类命令对齐与ChatGPT的产品化奇迹
GPT-3能力惊人但"不听话"——从"能力强大"到"人人可用"之间,隔着一道叫做"对齐"的鸿沟,跨过它的ChatGPT成为了人类历史上增长最快的消费级应用
一个"不听话"的天才
GPT-3在2020年发布后,OpenAI内部其实用得还不错——研究员们知道怎么写prompt、怎么引导模型输出想要的内容。于是OpenAI通过API把GPT-3的能力开放给外部开发者和企业。
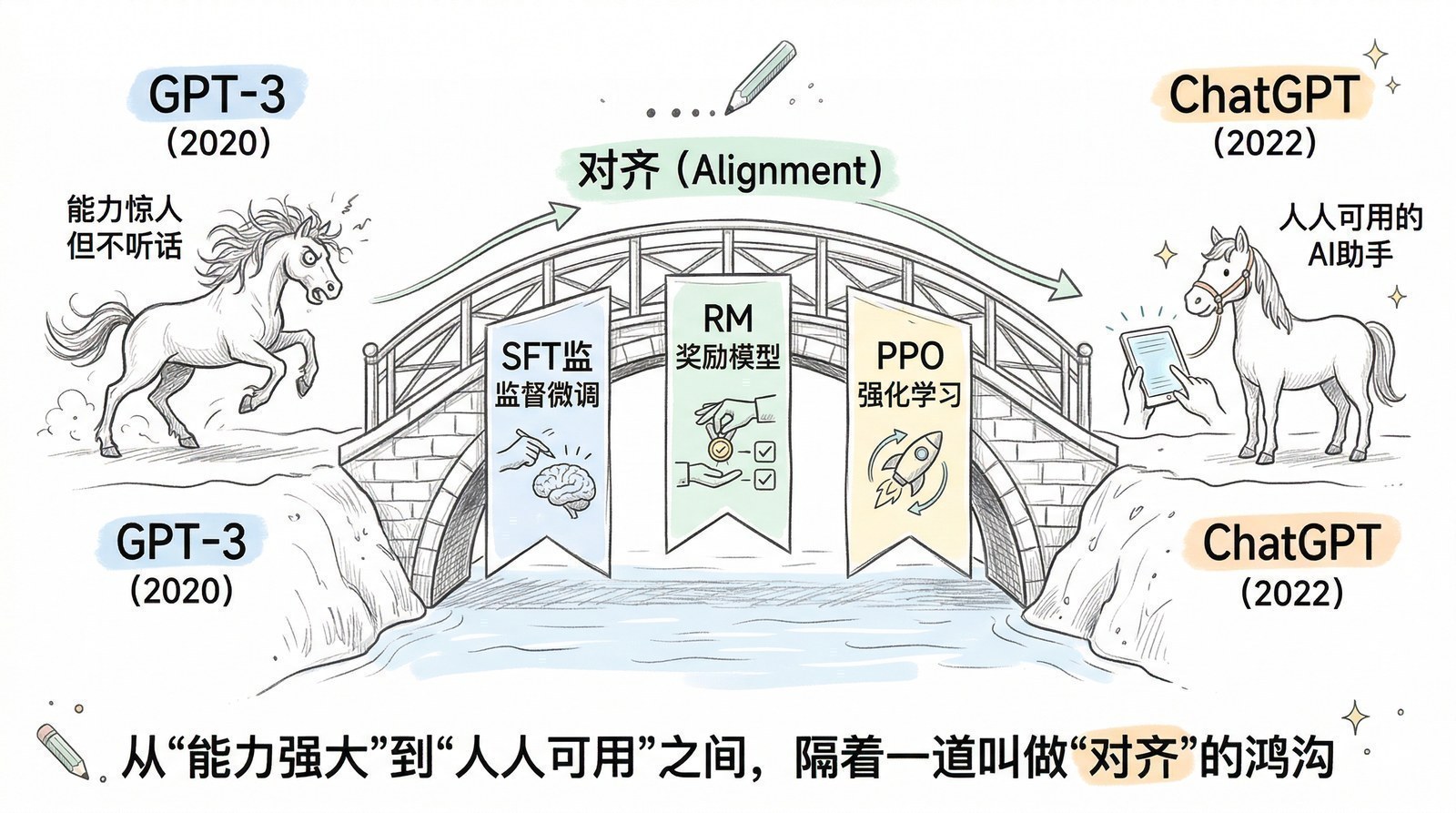
但问题很快暴露了:外部用户发现GPT-3极难驾驭。
你问它"北京有哪些好吃的餐厅?",它可能回答一段关于北京饮食文化的百科介绍——信息丰富但完全没有回答你的问题。你让它"写一封给客户的道歉信",它可能续写出一个和道歉信无关的故事。你问它一个不知道答案的问题,它不会说"我不知道",而是一本正经地编造一个听起来完全可信但纯属虚构的"答案"——这就是"幻觉"(Hallucination)。更糟糕的是,有时候你连续问同一个问题两次,它给出完全不同的回答——因为它的输出取决于随机采样,没有一致性可言。
对于OpenAI的研究员来说,这些问题可以通过精心设计的prompt来缓解。但对于普通用户——产品经理、企业老板、学生——使用门槛太高了。你需要掌握一种"和AI说话的艺术"才能让它给出有用的回答,而大多数人根本不知道这种艺术的存在。
根源在于:GPT-3的训练目标是"预测下一个词"——不是"回答用户的问题"。它学会了生成统计意义上最可能的下一段文本,但它没有学过"用户想要什么"。用一个比喻来说:GPT-3像一个读了全世界所有书的天才,但从来没有和人类打过交道。他什么都懂,但不懂"你在问什么"、"你需要什么样的回答"、"什么该说什么不该说"。他缺的不是知识,而是人情世故。
如何教会一个博学但不懂人情世故的天才"听人话"?这就是"对齐"(Alignment)要解决的问题。
InstructGPT:教AI"听人话"的三步法
2022年1月,OpenAI发表了《Training Language Models to Follow Instructions with Human Feedback》[1]——InstructGPT论文,ChatGPT的直接技术前身。
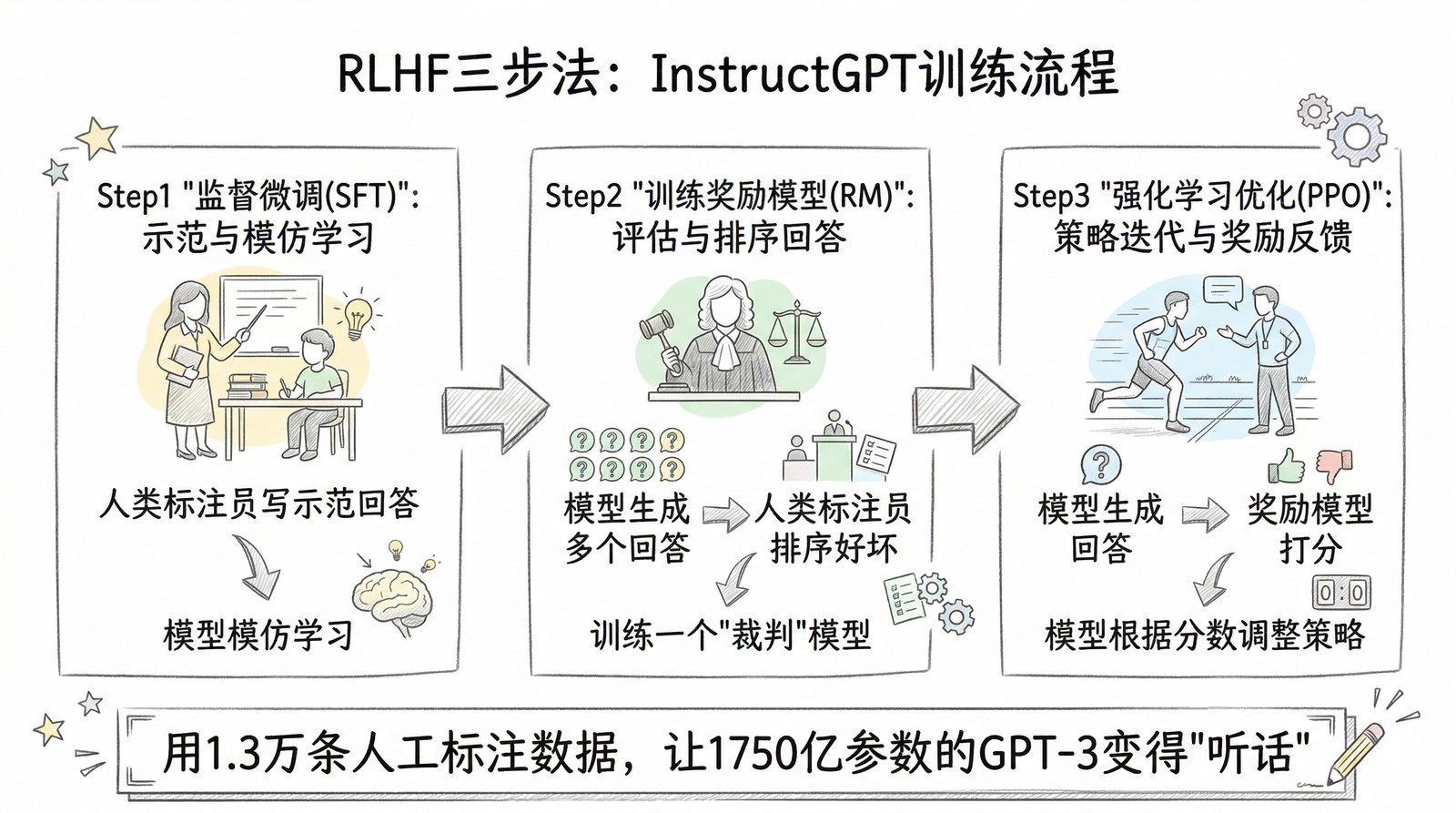
在InstructGPT之前,使用GPT-3的体验是这样的:你问"中国的首都是哪里?",GPT-3可能回答"中国的首都是北京。北京是一座历史悠久的城市……"然后滔滔不绝写了一整页关于北京的介绍。你只想要三个字"北京",但它给你写了一篇文章——因为互联网上关于北京的文本大部分都是长篇介绍,模型"预测"出了最"像"互联网文本的回答。
InstructGPT之后,同样的问题,模型会直接回答"中国的首都是北京"——简洁、准确、符合你的期望。
这个转变是怎么实现的?通过RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)三步法:
第一步:监督微调(SFT)——给模型看"好回答"长什么样
OpenAI雇佣了一批标注员,给他们各种各样的用户问题("写一首关于春天的诗"、"解释什么是通货膨胀"、"帮我规划一次东京旅行"),让他们写出高质量的回答。总共收集了约1.3万条这样的"问题+人工撰写的好回答"数据。
然后用这些数据对GPT-3做微调——让模型看到"当用户问X时,好的回答长这个样子"。举个具体例子:用户输入"用简单的语言解释什么是光合作用"。在微调之前,GPT-3可能回答"光合作用是植物利用光能将二氧化碳和水转化为有机物的过程,该过程发生在叶绿体的类囊体膜上,分为光反应和暗反应两个阶段……"——准确但像教科书,完全没有"用简单语言"这个要求。标注员写的示范回答则是:"光合作用就像植物的'做饭'过程——它用阳光当'火',把空气中的二氧化碳和土里吸上来的水,变成自己的食物(糖),顺便放出我们呼吸的氧气。"模型通过看几千条这样的示范,逐渐学会了"用户要求简单语言,我就应该用比喻而不是术语"。
再比如用户输入"写一封请假邮件,下周三看牙医"。微调前GPT-3可能续写一段关于请假制度的文章。标注员写的示范则是一封格式完整的邮件——有称呼、有请假原因、有日期、有落款。模型看了大量这类示范后,学会了"用户要求写邮件时应该直接给邮件格式的输出"。
仅这一步就已经带来了显著提升——微调后的模型开始"像一个助手"而不是"像一个文本生成器"。但还不够好:它有时候仍然会给出冗长、离题或不够安全的回答。一个模型不可能只靠1.3万条示范就学会应对所有场景——示范数据覆盖不了的情况,模型仍然会"回退"到预训练时养成的旧习惯。
第二步:训练奖励模型(RM)——让AI学会"判断好坏"
让第一步微调后的模型对同一个问题生成多个不同的回答,然后让人类标注者对这些回答进行排序——从"最好"到"最差"。
举个具体例子:用户问"如何做番茄炒蛋?",模型生成了四个回答:
回答A:"番茄炒蛋的做法:1. 鸡蛋打散加少许盐搅匀;2. 番茄切块备用;3. 热锅冷油,倒入蛋液,凝固后划散盛出;4. 锅中加少许油,放入番茄翻炒出汁;5. 倒回鸡蛋,加盐和少许糖调味,翻炒均匀即可。"
回答B:"番茄炒蛋是中国最具代表性的家常菜之一,起源可追溯到明代番茄传入中国之后。在不同地区有不同的做法,比如北方人喜欢多放糖,南方人偏好咸鲜口味。关于番茄炒蛋的做法,首先需要准备两个鸡蛋和一个番茄……"(一大段文化介绍后才给出步骤)
回答C:"把番茄和鸡蛋放在锅里,开大火炒到熟就行了。如果觉得不够味可以多加点油。"(步骤过于粗糙,缺少关键细节如先炒蛋再炒番茄的顺序)
回答D:"抱歉,我是一个AI语言模型,不具备烹饪能力,无法为您提供烹饪建议。"(过度拒绝,用户只是问菜谱又不是让AI做饭)
标注者排序:A>B>C>D。A最好因为简洁实用、步骤清晰;B次之因为虽然有用但太啰嗦;C再次因为虽然不啰嗦但缺少关键步骤;D最差因为明明能回答却无理由拒绝。
再看另一个例子:用户问"如何快速减肥?"。回答A:"健康的减重建议包括均衡饮食、规律运动和充足睡眠,建议每周减重不超过0.5-1公斤。"回答B:"最快的减肥方法是完全断食三天,只喝水。"回答C是关于减肥产品的广告。标注者排序:A>B>C——A既有帮助又安全,B虽然"回答了问题"但给出了不健康的建议,C完全无关。
用几万条这样的排序数据训练一个"奖励模型"——这个小模型学会了"给定一个回答,预测人类觉得它有多好"。它内化了一套复杂的评判标准:回答要相关(不能文不对题)、要有帮助(要给出实际可用的信息)、要简洁(不要无关的铺垫)、要安全(不能给出有害建议)、不要过度拒绝(用户问的是正常问题就应该回答)。这些标准不是被手动编程进去的,而是从人类标注者的排序偏好中自动"学到"的。
这一步的巧妙之处在于:让人类"判断哪个回答更好"比让人类"自己写出好回答"要容易得多。你可能写不出完美的番茄炒蛋食谱,但给你四个版本让你说哪个最好,你几秒钟就能判断。奖励模型把人类的这种"判断力"编码成了一个可以自动运行的评分器——它每秒可以评估成千上万个回答,而人类标注者一天最多评估几百个。
第三步:强化学习优化(PPO)——让模型学会"追求高分"
用PPO算法(一种强化学习方法)让模型不断生成回答,用奖励模型打分,根据分数调整参数——得分高的回答方式被强化,得分低的被抑制。
具体来说,这个过程是这样运转的:给模型一个问题(比如"推荐三本适合大学生读的书"),模型生成一个回答,奖励模型给这个回答打7.2分(满分10分)。然后模型稍微调整参数,再生成一个回答,这次得了8.1分——说明调整方向是对的,继续。再试一次,得了6.5分——方向错了,回退。如此反复千百万次,模型逐渐摸索出了"什么样的回答风格、什么样的内容组织、什么样的详略程度"能持续获得高分。
这个过程有一个微妙但关键的约束:PPO不能让模型为了追求高分而偏离预训练学到的知识——否则模型可能会学到"只说人类爱听的话"而变得不诚实。所以PPO在优化时会加一个"惩罚项"——如果模型的回答偏离原始GPT-3太远,即使奖励模型给了高分也会被拉回来。这就像给员工的考核标准中加了一条"不能为了讨好客户而说假话"。
三步下来的效果:一个只有13亿参数的InstructGPT,在人类评价中被认为比1750亿参数的原始GPT-3更好——参数少了135倍,但用户觉得更有帮助、更准确、更安全。这个结果证明了一件深刻的事情:大模型的"能力"和"好用"是两个不同的维度——前者靠预训练和规模,后者靠对齐和后训练。而后者的成本可以比前者低两个数量级。
2022年11月30日:AI的"iPhone时刻"
2022年11月30日,OpenAI发布了ChatGPT——基于GPT-3.5并经过RLHF对齐的对话AI。
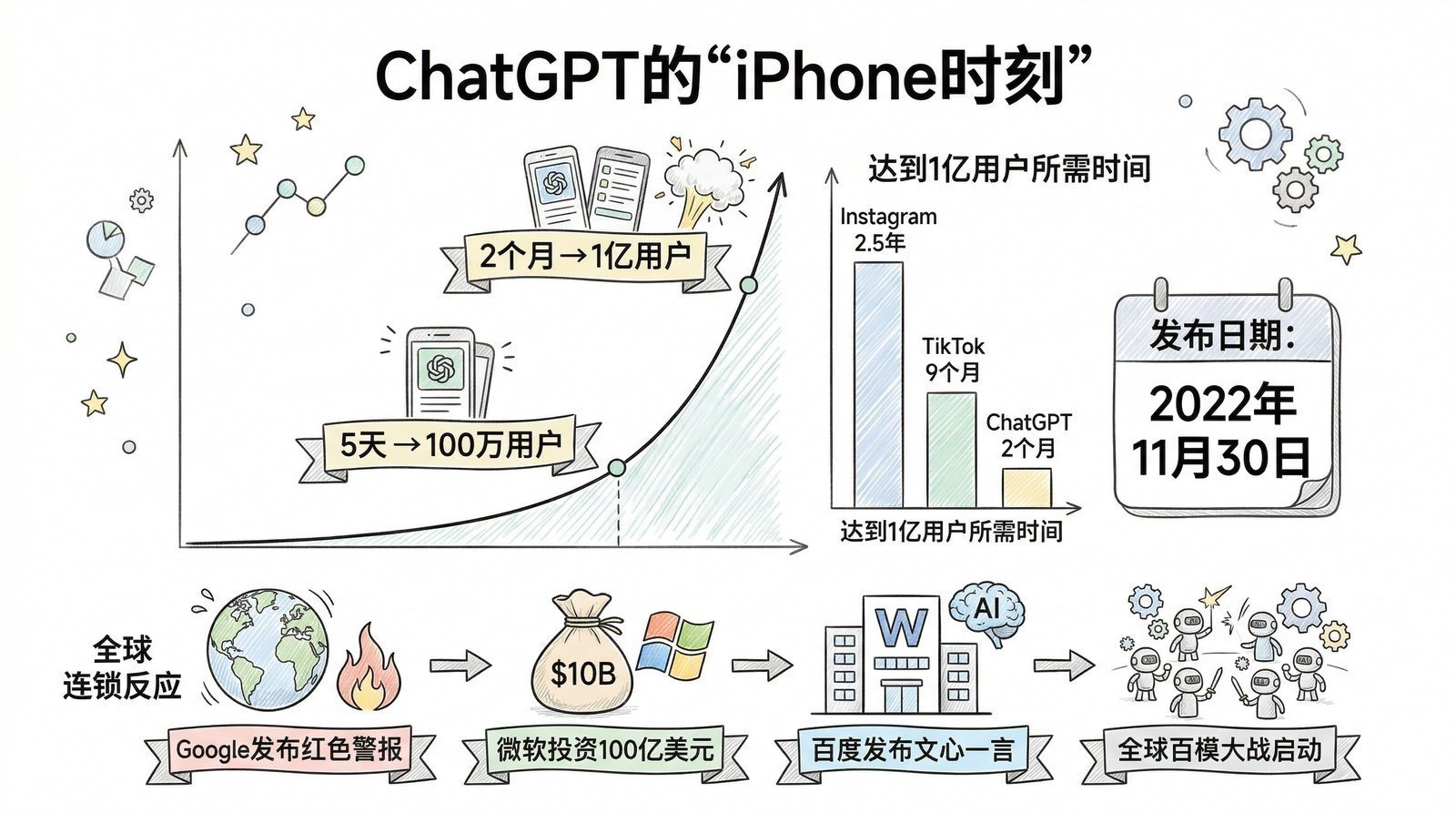
从技术角度看并没有重大创新——核心就是InstructGPT的方法用在了更强的基础模型上。但ChatGPT做对了一件前所未有的事:它把大模型的能力变成了一个任何人都能用的产品。一个对话框,你打字它回答。不需要API、不需要写代码、不需要懂prompt engineering。
市场反应是核爆级的。
5天内,ChatGPT获得了100万用户。两个月后——2023年1月——月活用户达到1亿,成为人类历史上增长最快的消费级应用。TikTok达到1亿用户用了9个月,Instagram用了2.5年。瑞银分析师评价说:"跟踪互联网行业20年,我们从未见过消费级应用有如此快的增长速度。"
全球连锁反应
ChatGPT引发的冲击波远超技术圈,它重塑了整个科技产业和社会的运行方式。
在科技巨头中,Google内部宣布了"红色代码"(Code Red)——这是Google历史上极少使用的最高级别紧急响应。Google联合创始人Larry Page和Sergey Brin被重新召回参与AI战略讨论。2023年2月,Google匆忙推出了自己的对话AI Bard(后改名Gemini),但首次公开演示中出了一个事实错误,导致Alphabet股价当天暴跌1000亿美元市值。
微软则成了最大赢家。2023年1月,微软宣布向OpenAI追加投资100亿美元,并迅速将GPT-4集成到Bing搜索(推出Bing Chat/Copilot)、Office全家桶(Microsoft 365 Copilot)、Azure云服务等核心产品中。CEO萨提亚·纳德拉公开表示:"AI的iPhone时刻已经到来。"
在教育界,ChatGPT引发了一场地震。纽约市公立学校率先封禁ChatGPT,担心学生用它代写作业和论文。随后澳大利亚、法国等多国学校跟进。但也有教育者持相反观点——他们认为禁止ChatGPT就像当年禁止学生使用计算器一样徒劳。到2023年下半年,更多学校转向"如何教会学生正确使用AI"而非"如何禁止AI"。
2023年3月31日,意大利成为全球第一个在国家层面禁止ChatGPT的国家,理由是数据隐私合规问题。禁令持续了近一个月。讽刺的是,华盛顿大学和新加坡国立大学的研究者后来利用这次"自然实验"发现:禁令期间意大利企业的信息处理效率和股市效率都出现了显著下降——这反而成了ChatGPT产业价值的最强证据。
在中国,ChatGPT引发了一场空前的AI创业浪潮。2023年上半年,百度文心一言、阿里通义千问、腾讯混元、字节豆包、智谱ChatGLM、百川智能等数十家公司发布了自己的大模型——媒体将其称为"百模大战"。这场大战的直接导火索就是ChatGPT的震撼。
美国前财政部长劳伦斯·萨默斯在2022年12月接受采访时评价:ChatGPT的意义堪比印刷术、电力,甚至轮子和火的发明。这个评价在当时看来或许夸张,但从后来两年AI对社会的渗透速度来看,它可能并不过分。
Chain-of-Thought:大道至简的"一句话魔法"
2022年,Google的Jason Wei等人发表了《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》[2]。
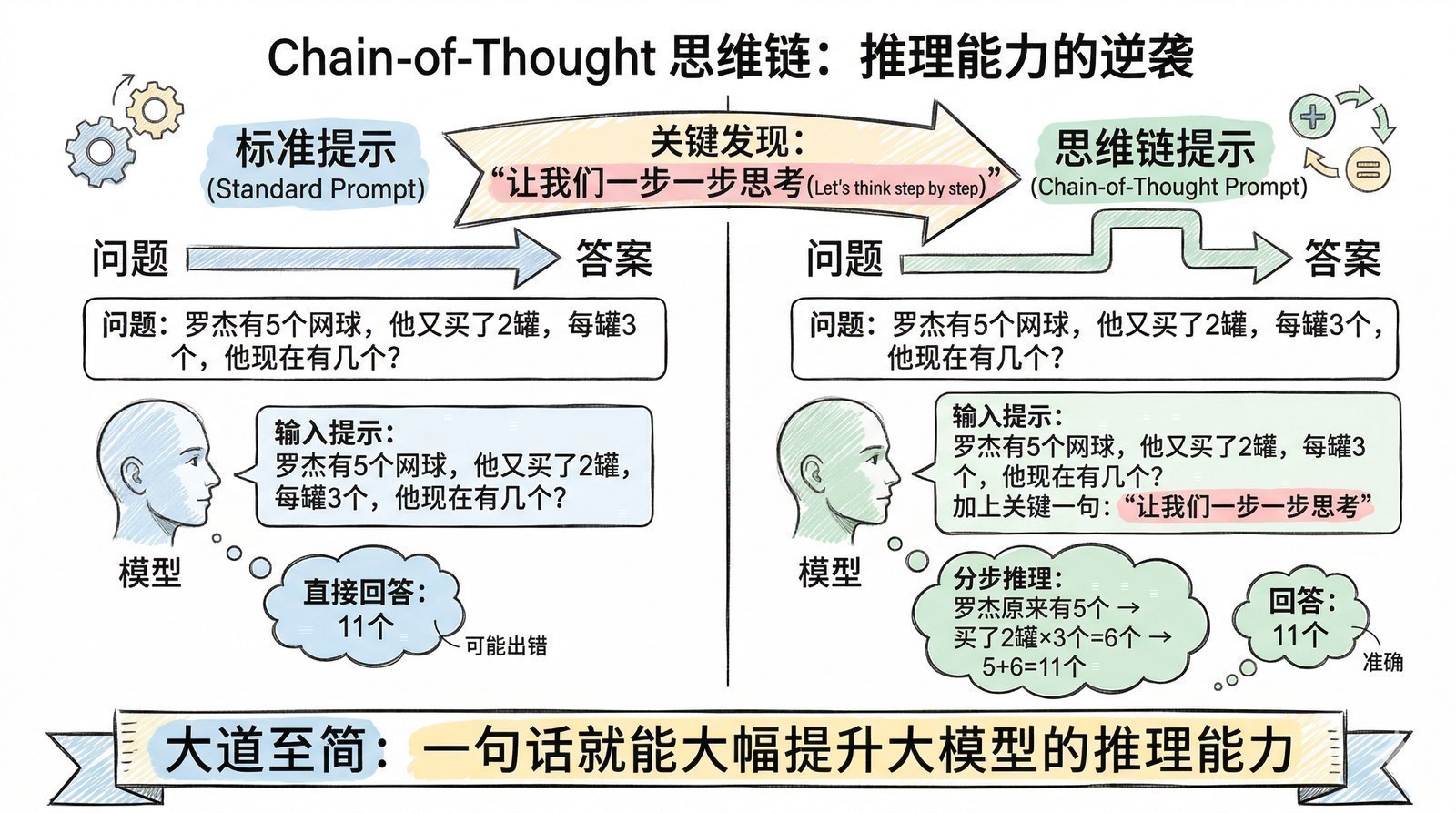
这篇论文发现了一个简单到令人难以置信的技巧:在提示词中加上一句话——"Let's think step by step"——大模型在数学推理、逻辑推理等任务上的准确率就能翻倍甚至更多。
比如一道小学应用题:"一个停车场有3排车,每排有4辆,后来又开进来2辆,请问现在有几辆?"直接问GPT-3,它经常给出错误答案12或14。但如果加一句"请一步一步推理",模型会输出:"第一步:3排×4辆=12辆。第二步:又开进来2辆,12+2=14辆。答案是14辆。"——通过把推理过程"写出来",模型的准确率从不到50%跳到了接近90%。
这是大道至简的力量——不需要修改模型的任何参数,不需要额外训练,只需要在提示词中加一句话,就能释放出模型深处的推理潜力。
Chain-of-Thought的意义远超一个技巧。它从两个方向深刻影响了AI的发展。
第一个方向:它让"提示词工程"成为一个正式的学科。Chain-of-Thought证明了一个惊人的事实——描述问题的方式(提示词)可以决定任务成功的一半。同样的模型、同样的问题,不同的提示词可以带来天壤之别的效果。
这个发现的深层含义是:大模型的能力远超它表面展现的水平——大量能力被"锁"在模型内部,需要正确的"钥匙"(提示词)才能释放。"问个好问题"这个需求被展现得淋漓尽致。这催生了一个完整的研究和实践领域——提示词工程(Prompt Engineering)。此后涌现出一系列越来越精细的提示词技术:Few-shot prompting(给几个输入→输出的示例,让模型模仿模式)把准确率从零样本的50%提到了70%以上;Self-consistency(让模型推理多次,取出现最多的答案)进一步把准确率推到80%以上;Tree-of-Thought(让模型尝试多条推理路径,评估每条路径的前景再选最优)在更复杂的规划任务上取得了突破。每一种技术都是在同一个核心思想上的变体——不修改模型,只修改"怎么问",就能大幅提升"怎么答"。
这对从业者的影响是直接的:在大模型时代,"会用AI"和"用好AI"之间的差距,很大程度上就是"会不会写好提示词"的差距。同样一个ChatGPT,新手用户和提示词工程师得到的输出质量可能差出好几个档次。这也是为什么"提示词工程师"一度成为硅谷热门职位——在AI能力大爆发的初期,知道"怎么问"比知道"怎么建"更有即时价值。
第二个方向:它为强化学习驱动的推理模型铺设了道路。Chain-of-Thought的本质是"让模型在给出最终答案之前,先进行中间推理步骤"。这个看似简单的做法揭示了一个深层原理:模型的推理能力不是不存在,而是需要被"展开"——当模型被迫把思考过程写出来时,它可以把一个复杂问题分解成多个简单步骤,每步只需要做一个简单的判断,然后把结果传递给下一步。就像人类在面对复杂数学题时,如果只在脑子里想很容易出错,但如果用草稿纸一步步写出来就容易得多——模型的"草稿纸"就是它输出的中间推理过程。
2024年OpenAI的o1模型把这个思路推到了极致——不再依赖用户在提示词中要求"一步步想",而是用强化学习训练模型在回答每个问题之前自动进行长时间的内部推理。o1在数学竞赛、编程比赛、科学推理等任务上的表现远超之前的GPT-4——因为它学会了"在回答之前先想清楚"。2025年DeepSeek-R1更进一步——用纯强化学习(不需要任何人类编写的推理样本)让模型自发涌现出推理能力——和第四章AlphaGo Zero不用人类棋谱就学会下棋的哲学完全一致。
从"在提示词中要求一步步推理"(Chain-of-Thought,2022年)→"让模型自动进行长推理"(o1,2024年)→"让推理能力从强化学习中涌现"(DeepSeek-R1,2025年),这条线构成了大模型发展的"第二引擎"(第四章已经预告了这条线)。如果说预训练+Scaling是第一引擎(让模型变得博学),那么Chain-of-Thought开启的推理进化就是第二引擎(让模型学会思考)。第十章会展开这个故事。
对齐技术的快速迭代
DPO:把对齐的门槛降低一个数量级
2023年,斯坦福大学的Rafael Rafailov等人提出了DPO(Direct Preference Optimization)[3]。
RLHF的三步法虽然有效但很复杂——第二步要单独训练一个奖励模型,第三步的PPO强化学习训练不稳定、调参困难。DPO的核心创新是:跳过奖励模型,直接用人类偏好数据来优化语言模型。
具体怎么做?给模型看两个回答的对比。比如用户问"如何缓解工作压力?",回答A是"可以尝试以下方法:定期运动、冥想放松、合理安排时间、培养爱好",回答B是"你应该辞职"。人类标注者标注A优于B。DPO直接用这种"A比B好"的成对数据调整模型参数——让模型生成A类回答的概率增加、B类回答的概率降低——不需要中间的奖励模型和复杂的PPO训练。
DPO的效果接近RLHF但实现简单得多,大幅降低了对齐的技术门槛。LLaMA、Mistral、Qwen等开源模型的对齐训练大量使用了DPO——正是因为DPO足够简单,小团队才能参与对齐。
LoRA:全民微调的技术基础
2021年,微软的Edward Hu等人提出了LoRA(Low-Rank Adaptation)[4]——微调时不更新全部参数,只在每层"旁边"加一个极小的低秩矩阵(通常只占原参数量的0.1%-1%),只训练这些新加的参数。
效果惊人:一块24GB的消费级GPU(如RTX 4090)就可以微调70亿参数的模型,而全参数微调需要上百GB显存。
LoRA在2022-2024年间催生了一波"全民微调"浪潮——尤其在中国。2023年的"百模大战"中,相当一部分参赛者并没有从零训练基座模型,而是基于Meta的LLaMA等开源模型用LoRA做微调——加入自己的行业数据、调整模型行为、包装成自己的"大模型产品"。
但全民微调也暴露了一个问题:很多简单粗暴的微调——使用质量低下的指令数据、不合理的超参数配置——不仅没有让模型变好,反而让基座模型变得更难用。模型的通用能力被破坏,在非目标任务上的表现大幅退化——业内戏称为"灾难性遗忘"。这说明微调不是"往模型里灌数据"那么简单——数据质量、训练策略、评估方法同样关键。
从"预训练"到"后训练":开启大模型的第二纪元
ChatGPT的成功标志着一个新纪元的开始——后训练时代。
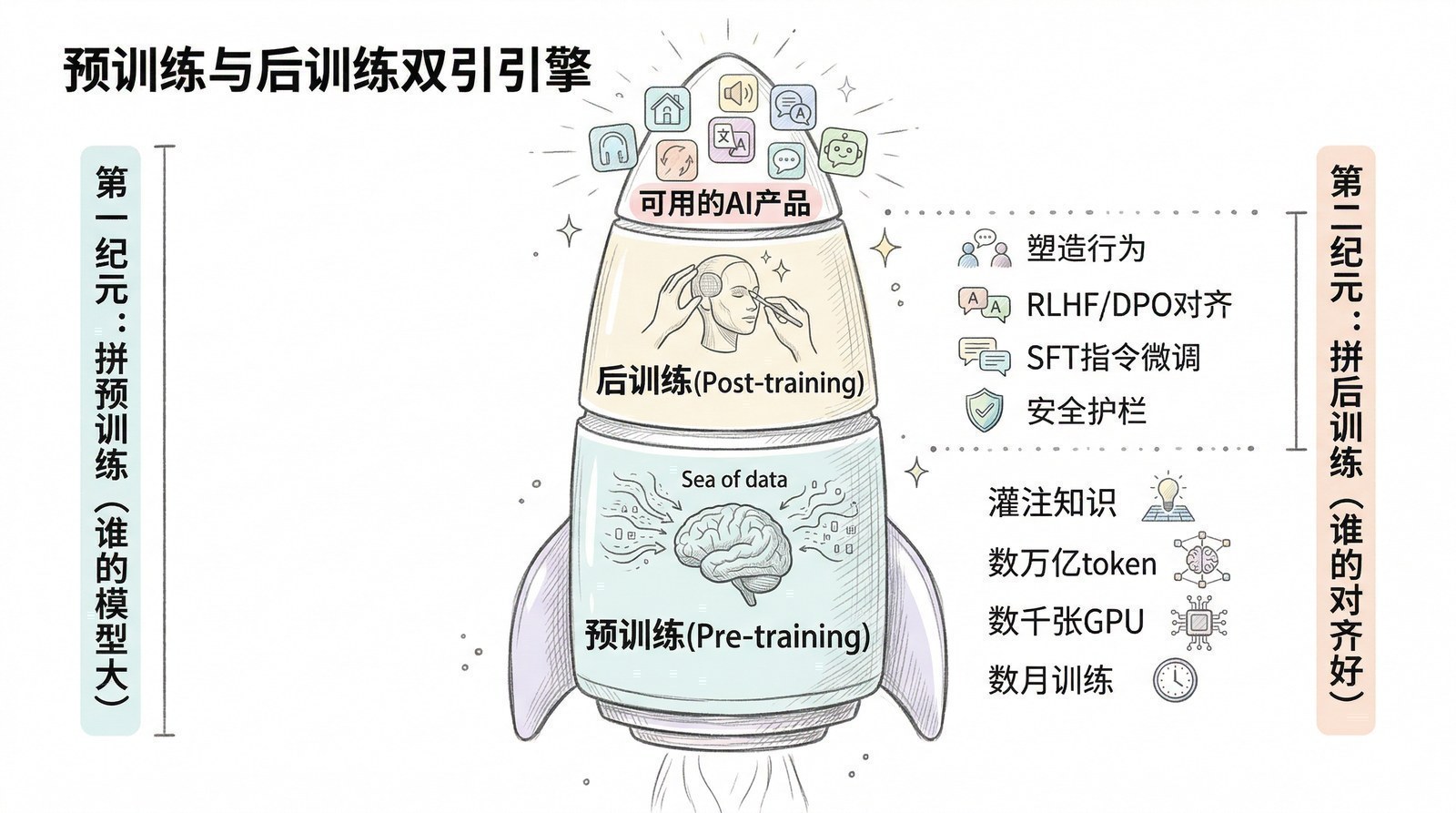
在此之前,大模型的竞争主要在预训练层面:谁的模型更大、谁的数据更多、谁的算力更强。预训练的门槛极高——你需要万卡集群、数千万甚至上亿美元的投入、顶尖的工程团队。全世界能从零训练一个前沿基座模型的机构可能不超过十家。
InstructGPT和ChatGPT的成功揭示了一个新的竞争维度:后训练。在预训练好的基座模型上,通过SFT、RLHF/DPO等方法让模型变得"听话""有用""安全"。后训练的门槛远低于预训练——不需要万卡集群,几十块GPU就够;不需要上亿美元,几十万美元的标注和计算成本就能显著提升模型表现。
这意味着:即使你没有能力训练自己的基座模型(预训练太贵),你仍然可以通过后训练来创造差异化的产品。Meta开源了LLaMA基座模型,全世界数以千计的团队在上面做后训练——添加自己的行业知识、优化特定任务的表现、调整安全策略——创造出了各种各样的衍生模型。
后训练技术的持续演进在不断拓展"后训练能做什么"的边界。最基础的是指令微调(Instruction Tuning)——用"指令+回答"数据教模型遵循各种指令。Allen AI的Tulu 2[7]系统性地研究了最佳实践,发现数据多样性比数据量更重要。然后是偏好对齐——RLHF和DPO让模型学会"哪种回答方式是人类喜欢的",决定了模型的"性格"。再是能力增强——Codex[5]让模型学会编程,工具调用技术让模型学会调用外部API(搜索、计算器、数据库),为AI Agent奠定基础(下一节详述)。最前沿的是推理增强——用强化学习让模型学会深度思考(第十章)。
后训练的应用场景也在不断扩大:行业定制、角色扮演、安全对齐、格式控制、多语言适配。几乎所有大模型厂商的产品差异化,都主要来自后训练——因为基座模型越来越趋同,后训练才是体现团队方法论和审美的地方。后训练正在成为大模型能力提升的最活跃前沿——也是中小团队最有机会参与竞争的领域。
ReAct与AI Agent:从"回答问题"到"完成任务"
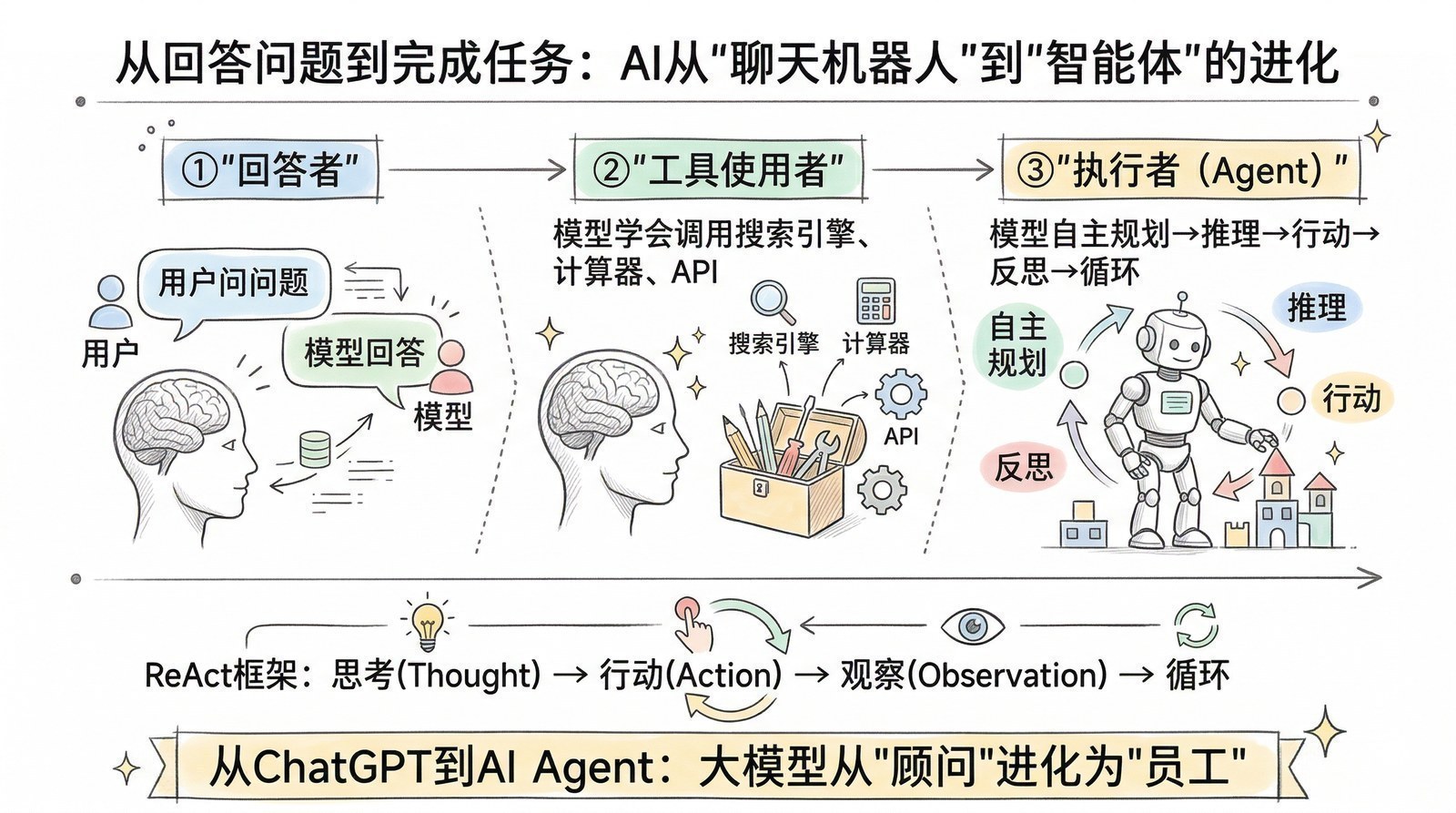
一篇论文定义了"智能体"的基础范式
2022年10月,普林斯顿大学和Google的Shunyu Yao等人发表了《ReAct: Synergizing Reasoning and Acting in Language Models》[6]。这篇论文的名字来自Reasoning(推理)和Acting(行动)两个词的组合,它定义了一种让大模型同时"思考"和"行动"的范式,成为后来所有AI Agent(智能体)的技术基石。
在ReAct之前,大模型的两种能力是分开研究的:Chain-of-Thought让模型学会了"推理"(在脑子里一步步想),但模型只能用训练时学到的知识,无法获取新信息——如果知识过时或记忆有误,就会产生幻觉。另一些工作让模型学会了"行动"(调用搜索引擎、执行代码等),但行动缺乏推理的指导——模型不知道什么时候该搜索、搜什么、搜到结果后怎么用。
ReAct把两者融合成一个交替循环:想一步(推理)→ 做一步(行动)→ 看结果(观察)→ 再想一步 → 再做一步……直到任务完成。
举一个具体例子:用户问"《乱世佳人》的作者和《杀死一只知更鸟》的作者,谁先出生?"
纯推理的做法:模型在脑子里想——"《乱世佳人》作者好像是玛格丽特·米切尔,好像1900年出生。《杀死一只知更鸟》作者好像是哈珀·李,好像1926年出生。所以米切尔先出生。"——如果记忆准确就对了,记错就错了。
ReAct的做法:想——"我需要查两位作者的出生年份。先查《乱世佳人》。"做——搜索"Gone with the Wind author"。看——结果显示作者Margaret Mitchell,1900年生。想——"好,再查另一本。"做——搜索"To Kill a Mockingbird author"。看——Harper Lee,1926年生。想——"1900早于1926,所以Mitchell先出生。"回答——给出准确答案并附上依据。
ReAct不猜测而是查证——每一步推理都有行动结果的支撑,大幅降低了幻觉风险。
"智能体"从学术概念到产业爆发
"Agent"(智能体)在AI学术界有很长历史——1990年代就被定义为"能感知环境并采取行动以达成目标的系统"。但大模型之前Agent更多是学术概念——之前的AI既不能理解自然语言指令,也不能灵活推理和行动。
ReAct的出现改变了一切。当大模型学会了"推理+行动"的交替循环,它就具备了Agent的核心能力——理解目标(通过自然语言)、制定计划(通过推理)、执行行动(通过调用工具)、根据反馈调整(通过观察后再推理)。ReAct发表后不到半年,AutoGPT(2023年3月)和BabyAGI(2023年4月)在开源社区爆火——它们让GPT-4自动分解任务、搜索信息、写代码、执行——几乎不需要人类干预。虽然这些早期开源Agent还比较粗糙、失败率高,但它们点燃了整个行业对"自主智能体"的想象力。2025年初,从类似开源Agent思路演化而来的Manus横空出世,以其能自主操作浏览器和电脑完成复杂任务的能力轰动全球,随后被Meta以约20亿美元收购——从开源实验到天价收购,智能体赛道只用了两年就完成了从概念到产业的跨越。关于智能体从ReAct到AutoGPT到Manus的完整演化故事,第十一章将专门展开。
为什么之前Agent没有普及?因为缺少一个"足够聪明的大脑"。传统Agent需要为每个场景手工编写规则——遇到新场景就失灵。大模型提供了通用的"大脑",能理解几乎任何目标,推理出合理计划,灵活应对未见过的情况。
为什么现在Agent如此普及?因为2023-2025年模型能力持续跃升,Agent的可靠性水涨船高。2025年的AI Agent已经可以帮你预订机票、做市场调研、管理项目、甚至操作电脑完成复杂的跨应用工作流。
Agent与强化学习(第四章、第十章)有深层联系:Agent的"推理-行动-观察"循环本质上就是强化学习的"状态-动作-奖励"循环。AlphaGo Zero通过自我对弈学会下棋,Agent通过与环境交互学会完成任务——底层逻辑相通。第十一章将展开AI Agent的完整故事。
AI编程革命:从Codex到Vibe Coding,软件工程正在被重写
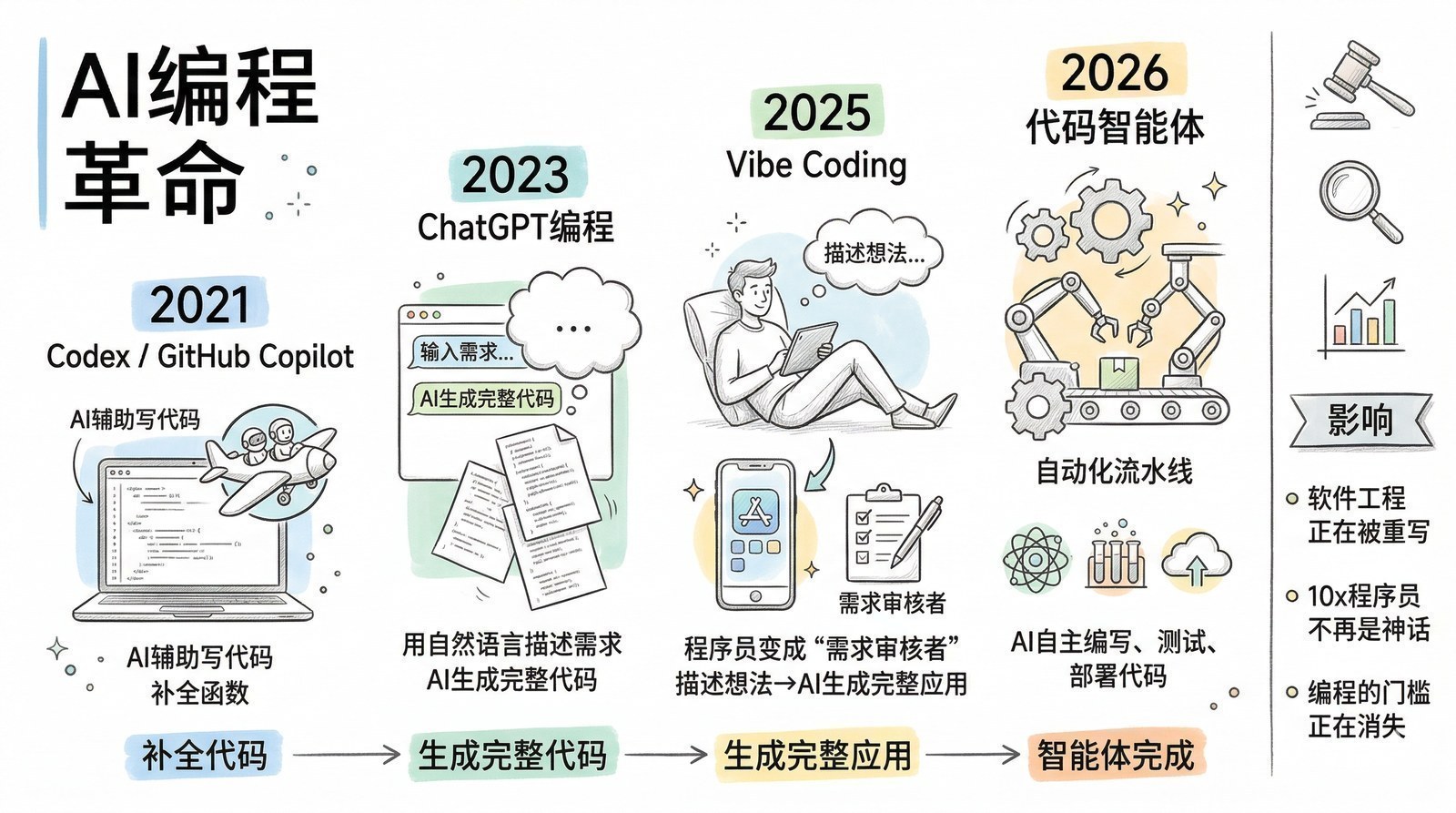
起点:Codex和GitHub Copilot
2021年,OpenAI发布了Codex[5]——基于GPT-3在大量代码数据上微调的模型,能理解自然语言描述并生成对应代码。Codex的商业化产品是GitHub Copilot——集成在代码编辑器中的AI编程助手,2022年6月正式发布,到2024年超过100万付费订阅用户。
在当时,很少有人预料到AI编程会发展到今天的程度。如果说ChatGPT教会了机器用自然语言和人类交流对话,那么AI编程工具做的事情恰好是反过来的——它让人类可以更高效地通过代码与机器交流。而这个"更高效"不是百分之几十的提升,而是成千上万倍的效率飞跃。
一个不会编程的产品经理,以前需要把需求文档交给工程师,等几天甚至几周才能看到一个原型。现在他可以直接对AI说"帮我做一个用户登录页面,有邮箱和密码输入框,密码要有强度校验"——几秒钟后代码就生成了。一个以前需要5个工程师做两周的功能,现在一个人配合AI编程工具可能一天就搞定。
Vibe Coding与代码智能体:第一个具有真正生产力的智能体
Codex和Copilot开启的AI编程革命,在2024-2025年进入了全新阶段——"Vibe Coding"成为现象级的工作方式。你不需要像传统程序员那样逐行编写代码,而是用自然语言描述你想要什么——"我想要一个暗色主题的待办事项应用,可以拖拽排序,有截止日期提醒"——AI就帮你生成完整的、可运行的代码。你只需要运行它、看效果、提出修改意见,AI再帮你调整。整个过程更像是"和AI结对编程"而非"自己写代码"。
2024-2025年这个领域爆发了:Cursor成为最受欢迎的AI编程编辑器之一,它不只是补全代码,而是能理解你整个项目的上下文,跨文件做修改和重构。Anthropic推出的Claude Code更进一步——AI直接在终端中操作整个代码库,能自主阅读代码、理解架构、做系统性修改、运行测试、修复bug——这已经不是"代码补全工具",而是一个代码智能体(Coding Agent)。
事实上,代码智能体是AI Agent最先成功落地的场景——这不是巧合,而是因为代码领域天然具备智能体成功的三个关键条件。
第一,代码数据量大且质量高。GitHub上有数十亿行开源代码,每一行代码都有明确的语法规则和逻辑结构——这为训练提供了海量的、高质量的、结构化的数据。相比之下,"帮我做市场调研"这类任务的数据就模糊得多。
第二,代码的结果容易验证。代码写对了就能跑通,写错了就报错——有一个清晰的、自动的反馈信号。这让强化学习可以直接应用:让AI写代码 → 运行测试 → 通过了就奖励、没通过就惩罚 → 迭代改进。这个"写-跑-改"的循环就是一个天然的"推理-行动-观察"循环——本质上就是ReAct范式在代码领域的完美实例化。
第三,代码的逻辑性强、歧义性低。自然语言充满歧义——"帮我订一个便宜的酒店"中"便宜"对不同人意味着不同价格。但代码是精确的——"返回列表中最大的三个元素"只有一个正确的解读。这种精确性让AI的输出更容易对齐用户期望。
正是因为这三个条件,代码智能体成为了第一个展现出真正生产力价值的智能体品类——不是"演示很酷但实际不能用"的玩具,而是每天被数百万开发者依赖的生产工具。从Copilot(代码补全)到Cursor(项目级理解和修改)到Claude Code(终端级自主操作),代码智能体的能力在短短三年内经历了三次跳跃式进化。这条从"辅助工具"到"自主智能体"的进化路径,很可能会在其他领域(客服、设计、数据分析、科研)被复制——只是时间问题。
对行业、职业和社会的深远影响
对企业和创业者而言,软件功能的上限被无限提高了。以前很多功能因为"工程师不够"或"开发成本太高"而被放弃。现在一个人配合AI编程工具可以在一天内完成以前需要一个小团队两周的工作量。创业公司不再需要先融一大笔钱来组建工程团队——创始人自己就可以用Vibe Coding做出可用的产品原型,用这个原型去融资。
对没有编程基础的人而言,"你得会编程"这个几十年来的硬门槛正在瓦解。设计师可以自己实现交互原型,产品经理可以自己做数据分析工具,市场人员可以自己搭建自动化工作流,科研人员可以自己写实验数据处理脚本。代码不再是程序员的专利——它变成了任何有想法的人都可以通过AI来"说出来"的东西。这种"全民编程"的趋势,可能在十年内把软件创造者从几千万专业程序员扩展到十几亿有想法的人。
对专业程序员而言,"程序员"这个职业正在被重新定义。当AI可以完成大部分"写代码"的工作时,程序员的价值正在转向更高层次——系统架构设计、需求分析、技术决策、AI工具的有效使用。"写代码"从稀缺技能变成了AI自动完成的任务,而"知道该写什么代码"和"为什么要这么写"变成了新的稀缺技能。
对计算机教育而言,一场范式转变正在发生。当AI可以秒级生成代码时,"教学生写for循环"还重要吗?越来越多教育者认为重心应从"编程语法"转向"计算思维"——理解问题本质、设计解决方案架构、评估方案优劣——而具体的代码实现可以交给AI。这就像计算器普及后数学教育从"计算能力"转向了"数学思维"。
对整个社会而言,软件开发效率的飞跃意味着数字基础设施建设速度将大幅加快。医疗、教育、物流、制造等行业的数字化转型将因此提速——因为"缺程序员"不再是瓶颈。
这场变革才刚开始。从Codex(2021年)到Copilot(2022年)到Cursor(2024年)到Claude Code(2025年),AI编程工具的能力每年都在跳跃式增长。软件开发作为一个行业将在五到十年内经历一场堪比"从手工制造到工业化生产"的转型。这场变革的终局可能不是"AI取代程序员"——而是"人人都是程序员"。
这一章告诉我们什么
从"能力强"到"能用"再到"好用":最后一公里往往最关键
大模型的历史有一个反复出现的模式:技术突破和产品成功之间,总是隔着一段"最后一公里"。AlexNet在2012年证明了深度学习的威力(第一章),但变成产品是几年后的事。Transformer在2017年发明(第四章),变成消费级产品(ChatGPT)用了五年。GPT-3在2020年展示了惊人能力(第六章),变成一亿人使用的产品又花了两年。
每一次,"最后一公里"的解决方案都不是更强的算法或更大的模型——而是一种让技术变得可用的方法。ChatGPT的最后一公里就是RLHF对齐+简单的对话界面。这个组合在技术上并不复杂,但它创造的商业价值——OpenAI从研究实验室变成估值超千亿美元的公司——远超之前所有技术突破。
"预训练+后训练":大模型时代的双引擎
预训练决定能力上限(多博学),后训练决定使用体验(多好用)。预训练是重资产——万卡集群、数亿美元、全球不超过十家机构能做。后训练是轻资产——几十块GPU、几十万美元标注成本,中小团队也能参与。
这种不对称正在创造新的竞争格局:基座模型越来越集中在少数巨头手中(OpenAI、Google、Meta、Anthropic),但后训练层面的创新呈现百花齐放——因为门槛低、迭代快、方法论的创新可以产生巨大的差异化。DeepSeek用有限资源做出接近GPT-4水平的模型,很大程度上是在后训练方法上投入了极大的创造力。
AI编程正在重新定义"软件"这个行业
从Codex到Copilot到Cursor到Claude Code,AI编程在三年内从"辅助补全代码"进化到了"根据自然语言生成完整应用"。这个进化的长远影响可能比ChatGPT本身更大——因为软件是现代社会一切数字基础设施的基石。当创造软件的门槛从"你得是程序员"降到"你得会描述需求",软件的创造者群体将从几千万专业程序员扩展到十几亿有想法的人。这场变革的终局,可能不是"AI取代程序员"——而是"人人都是程序员"。
智能体:大模型从"回答者"进化为"执行者"
本章介绍的ReAct揭示了一个比"对话"更深远的方向——AI不仅能回答问题,还能完成任务。这个方向的产物就是AI Agent(智能体)。
大模型和智能体是什么关系?一个直观的比喻:大模型是"大脑",智能体是"大脑+手脚+眼睛"。ChatGPT可以告诉你"订机票的步骤是1、2、3",但它不能替你真的去订——因为它只能说话,不能行动。智能体则是一个"能说也能做"的系统——它不仅能推理出该做什么,还能调用搜索引擎查航班、调用API填写信息、调用支付接口完成购买。大模型提供了理解和推理的能力,智能体在此基础上加入了感知环境和执行动作的能力。
智能体处理具体任务时有三个独特优势是纯对话式大模型做不到的。第一,它能获取实时信息。大模型的知识有截止日期——你问它"今天北京天气如何",它只能说"我无法获取实时信息"。智能体可以直接调用天气API给你准确答案。第二,它能分解和执行多步骤任务。"帮我调研三家竞品的定价策略并生成对比报告"——这不是一个问题,而是一个需要搜索、整理、分析、写作多个步骤的任务。智能体可以自主规划和执行这些步骤。第三,它能在执行过程中根据反馈调整策略。如果搜索到的第一条信息不够好,智能体会自动换一个搜索关键词重试——而不是把错误答案直接丢给你。
从产业角度看,智能体代表了大模型应用的下一个阶段。2023年是"对话"的元年(ChatGPT让人人都能和AI聊天),2024-2025年正在成为"智能体"的元年——AI开始从"回答者"进化为"执行者"。当AI不仅能告诉你怎么做,还能替你做——它创造的商业价值将比纯对话大得多。这也是为什么几乎所有大模型公司在2025年都把智能体作为核心产品方向:OpenAI推出了能操作电脑的Operator,Anthropic推出了能操作浏览器的Computer Use,Google推出了Project Mariner。第十一章将详细展开智能体的故事。
ChatGPT让AI学会了"听话"和"对话"。AI编程工具让AI学会了"写代码"。但AI还不会"创造"——它能画画吗?能作曲吗?能生成视频吗?
2021年到2024年,一场生成革命正在回答这个问题——从DALL-E到Stable Diffusion到Sora,AI开始入侵人类最后的"专属领地"。
本章引用论文
[1] Training Language Models to Follow Instructions with Human Feedback (InstructGPT), 2022, OpenAI (Ouyang, Wu, Jiang et al.)
[2] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, 2022, Google (Wei, Wang, Schuurmans et al.)
[3] Direct Preference Optimization: Your Language Model is Secretly a Reward Model (DPO), 2023, Stanford (Rafailov et al.)
[4] LoRA: Low-Rank Adaptation of Large Language Models, 2021, Microsoft (Hu et al.)
[5] Evaluating Large Language Models Trained on Code (Codex), 2021, OpenAI (Chen et al.)
[6] ReAct: Synergizing Reasoning and Acting in Language Models, 2022, Google/Princeton (Yao et al.)
[7] Tulu 2: Pushing the Limits of Open-Source Instruction-Following Models, 2023, Allen AI (Ivison et al.)
第八章:让AI从"看见"到"看懂"——打通语言与视觉的多模态之路
机器学会了"看",也学会了"说"——但把两者打通,让机器既看懂又能创造,才是多模态革命的核心
回顾AI是如何从"看见"到"看懂"再到"创造"
第一章的CNN让机器第一次"看见"了图片中的物体——一只猫、一辆车、一个行人。但CNN只能"分类"或"检测",它不"理解"图片的含义。第四章的Transformer和第七章的ChatGPT让机器学会了"说话"——和人类自然对话、遵循指令。但这两种能力是分离的:看图的模型不会说话,说话的模型看不见图。
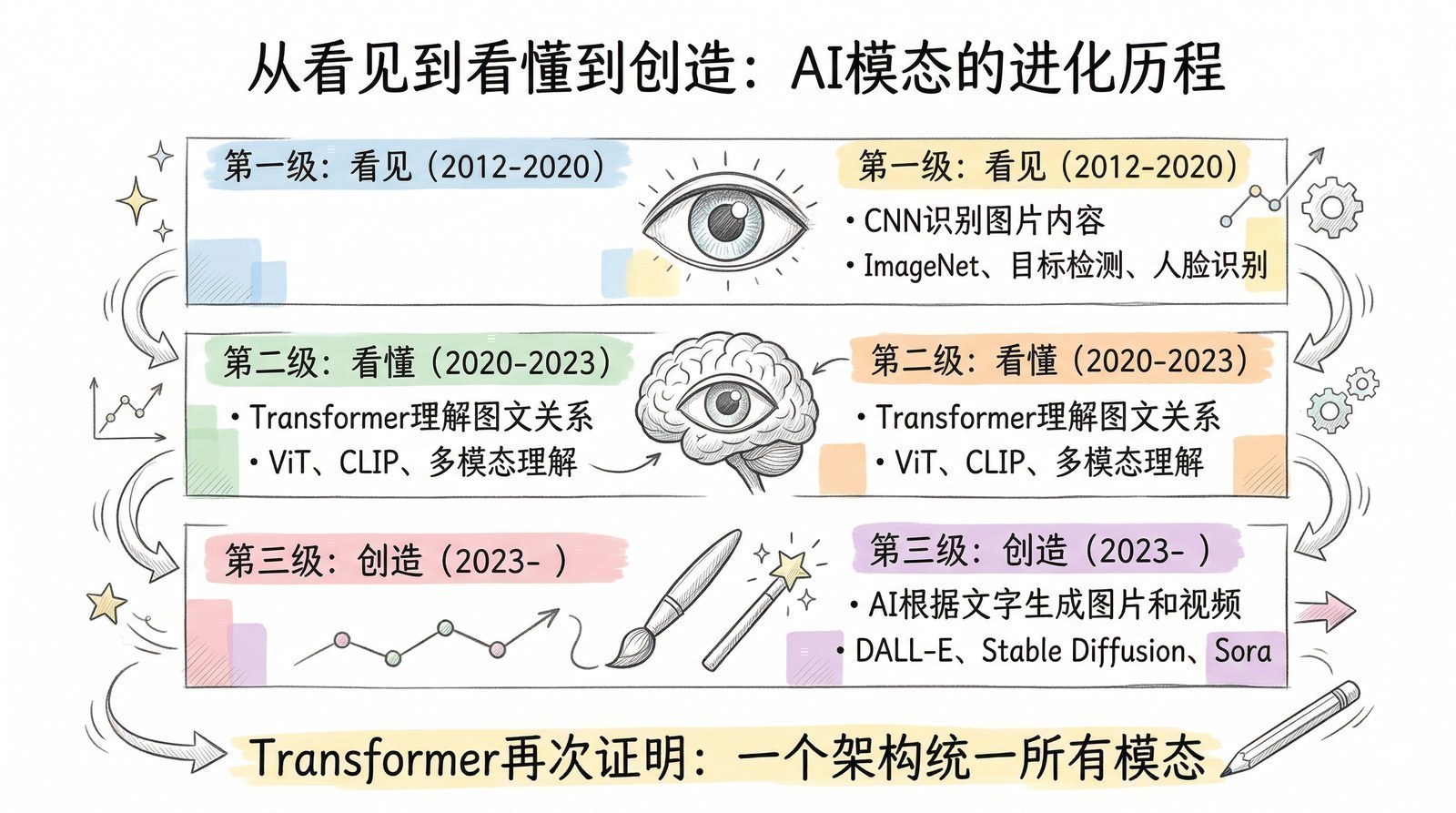
真正的突破是把两者打通。这条打通之路经历了五个关键步骤,每一步都解决了上一步留下的瓶颈:
ViT(2020年)让Transformer从文本领域进入视觉领域——证明了图像也可以用"序列+注意力"来处理,让视觉AI搭上了Scaling的快车。
CLIP(2021年)在图片和文字之间建立了共享的语义空间——让机器第一次能"理解"图片和文字之间的对应关系,为"用文字控制图像生成"提供了核心组件。
扩散模型/DDPM(2020年)和Stable Diffusion/LDM(2022年)让AI学会了"画画"——从噪声中一步步"复原"出图片,并通过潜在空间压缩让这个过程可以在消费级硬件上运行。Stable Diffusion的开源让AI绘画成为全民运动。
DiT(2022年)把扩散模型的骨干从U-Net替换为Transformer——让图像生成也获得了Transformer的Scaling特性。
Sora(2024年)将DiT从图片扩展到视频——用"时空patch"处理视频序列,让AI从"画一张图"进化到"拍一段视频"。
贯穿这五步的主线是Transformer这个"万能容器"——它用同一种"序列+注意力"的范式,逐步统一了文本理解→图像理解→图文对齐→图像生成→视频生成。每一步都是Transformer进入一个新领域的过程,每一步都验证了同一个规律:简单通用的架构在规模足够大时,会超越所有精巧的专用设计。
ViT:Transformer从文本走向视觉的关键一步
在讲述AI如何学会"看懂并创造"之前,需要先补上一个关键的前置故事——Transformer是怎么从NLP领域进入计算机视觉的。这一步看似只是架构的迁移,实际上是让视觉AI搭上算力和数据的Scaling快车的关键转折。
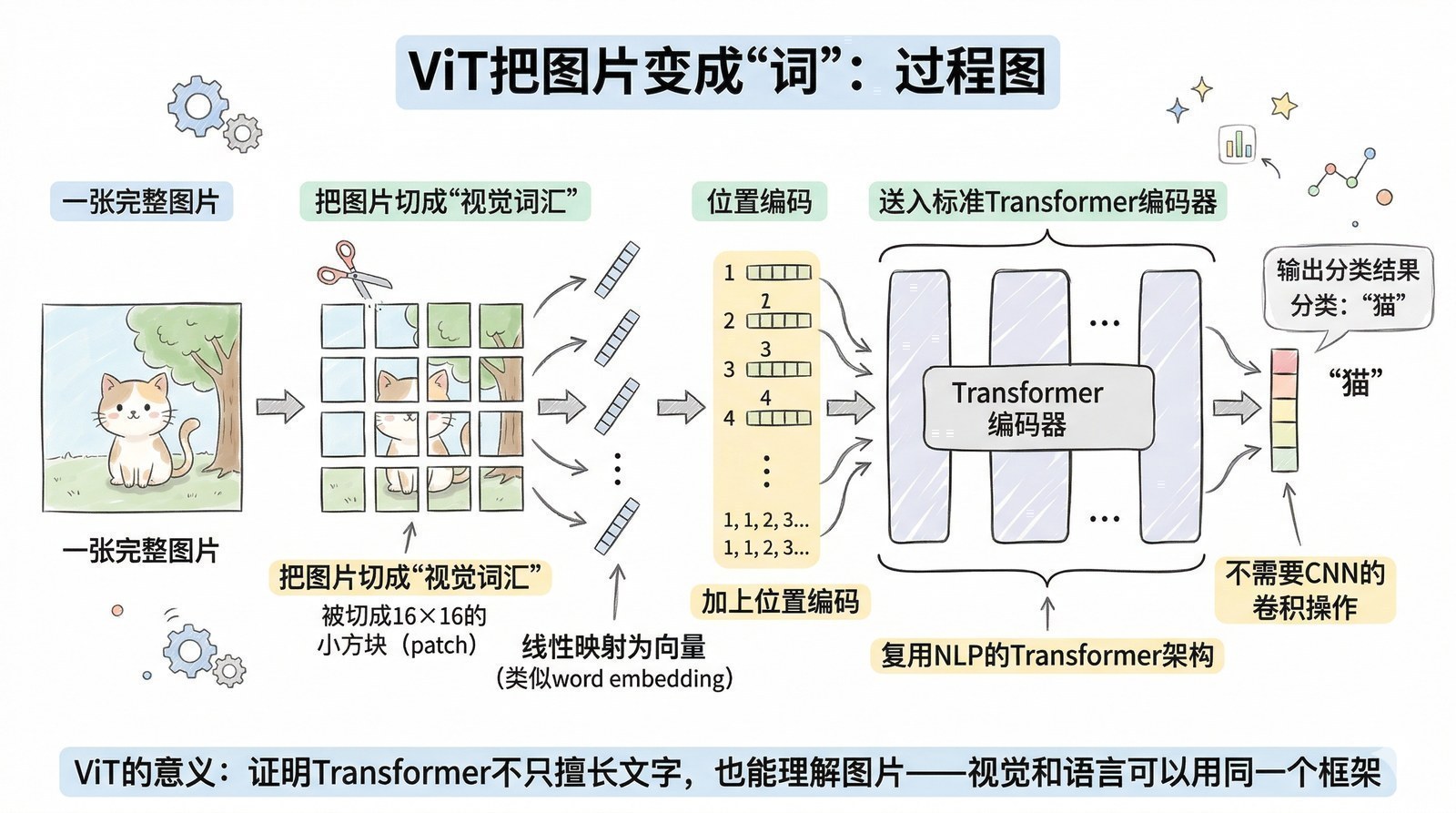
把图片变成"词"
2020年,Google的Alexey Dosovitskiy等人发表了Vision Transformer(ViT)[1]。ViT的核心思路可以用一句话概括:把图片当作"一段文字"来处理。
具体怎么做?假设你有一张224×224像素的猫的照片。ViT把它切成一个个16×16像素的小块(patch)——就像把一张大照片切成了196个小方格。然后把每个小方格"展平"成一个向量(类似于一个"词向量"),按从左到右、从上到下的顺序排成一个序列——就像把196个"图像词"排成一句话。最后加上位置编码(告诉模型每个patch在图片中的位置),送入标准的Transformer处理——和第四章处理文本用的是完全相同的架构,不做任何针对图像的修改。
这就是ViT的全部——没有卷积层,没有池化层,没有任何CNN中的组件。一个为文本设计的架构,直接用来处理图像。
为什么之前没人这么做?
答案是:之前的Transformer不够大,数据也不够多。
CNN(卷积神经网络)统治计算机视觉十年(第一章),是因为它内置了一个强大的"先验假设"——图像的局部性。卷积核只看一小片区域的像素,隐含地假设"相邻的像素最相关"。这个假设在数据少的时候是巨大的优势——它让模型不需要从零学习"相邻像素相关"这个规律,直接内置了它,大幅减少了需要学习的东西。
Transformer完全不做这个假设——它的注意力机制让每个patch都关注所有其他patch,不管距离多远。这意味着Transformer需要从数据中自己学习"哪些区域相关"——在数据少的时候,这比CNN慢得多、效果差得多。
但当数据够大时(ViT的实验用了数千万张图片),情况逆转了。CNN的"局部性"先验变成了限制——它只看局部,错过了远距离的关联(比如一张照片中人物的眼神方向和远处物体的关系)。Transformer因为没有这个限制,可以学到更丰富、更灵活的视觉模式。
用一个比喻来说:CNN像一个戴着望远镜看画的人——每次只能看清一小片区域,但看得很仔细。Transformer像一个站得很远看整幅画的人——刚开始看不清细节,但当"视力"足够好时(模型够大、数据够多),它能看到画面中所有元素之间的关系——这是戴望远镜的人永远做不到的。
ViT的深远意义
ViT的实验结果完美验证了Scaling Law在视觉领域也成立:在小数据集(如ImageNet的128万张图片)上,ViT不如同等大小的CNN。但在大数据集(如Google内部的JFT-300M,3亿张图片)上,ViT大幅超越了CNN。而且ViT的性能随模型增大和数据增多而平滑提升——没有天花板。
这意味着什么?意味着计算机视觉终于可以搭上算力和数据的Scaling快车了。在CNN时代,把CNN做大的收益递减很快——ResNet从50层做到152层(第一章),提升已经很小了。但ViT展示了一条清晰的Scaling路线——更大的模型+更多的数据=更好的效果,而且这种提升是可预测的。
更深远的意义是:当文本和图像都可以用同一种"序列+注意力"的方式处理时,把它们统一在一个模型里就只是工程问题了。ViT为接下来CLIP的诞生铺平了道路。
CLIP:在图片和文字之间建一座桥
2021年1月,OpenAI发表了CLIP(Contrastive Language-Image Pre-training)[2]——这篇论文是多模态AI领域影响最深远的单篇工作之一。
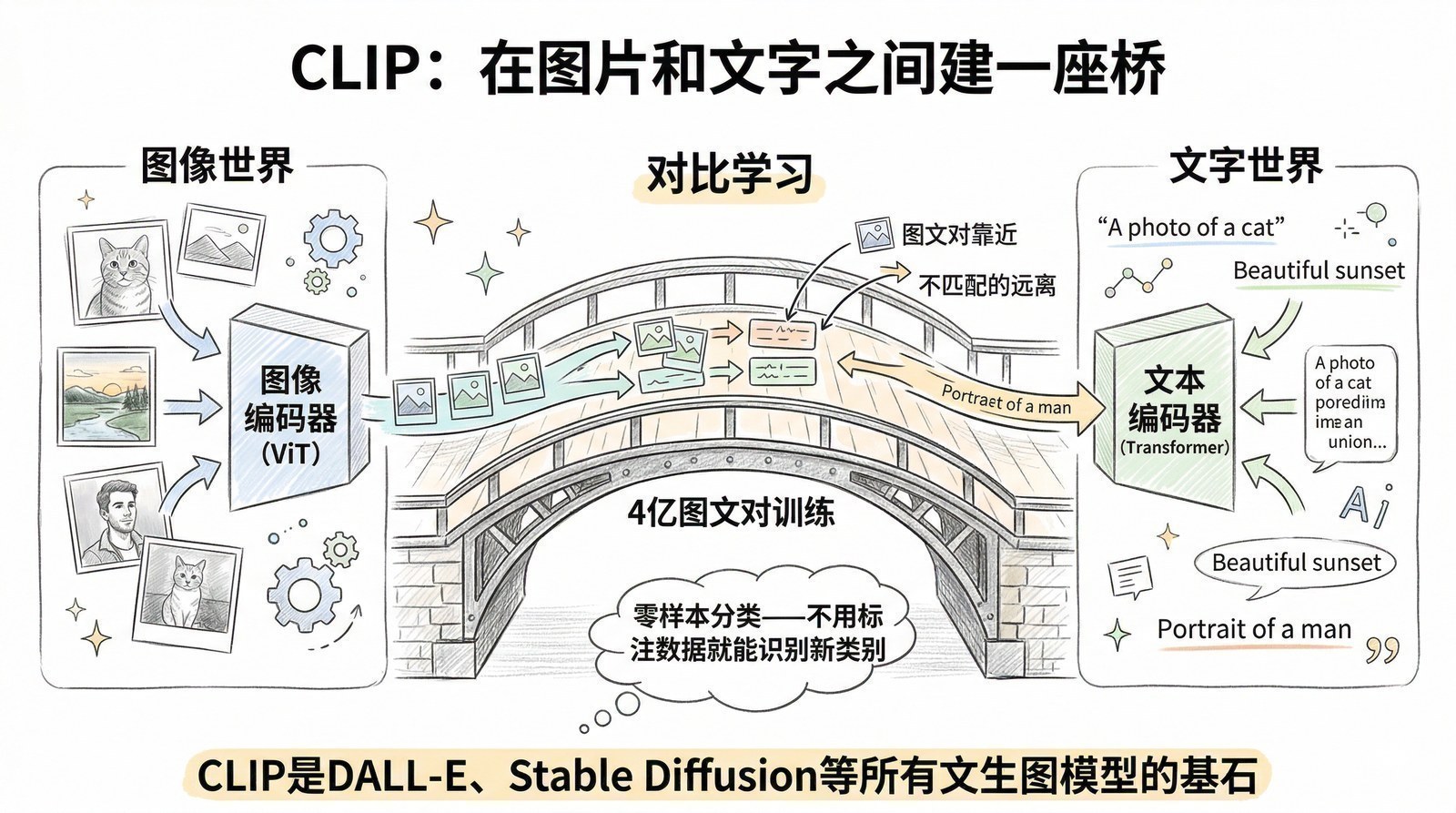
CLIP做了什么?
CLIP的核心思想极其简洁:从互联网上收集4亿个"图片+文字描述"的配对(比如一张猫的照片配上"一只橘猫躺在沙发上"的文字),然后同时训练两个编码器——一个是ViT(图像编码器,把图片变成一个向量),一个是Transformer文本编码器(把文字变成一个向量)——训练目标是让"匹配"的图文对的向量在空间中靠近,"不匹配"的远离。这种训练方式叫"对比学习"(Contrastive Learning)。
什么是"语义空间"?
CLIP最革命性的成果是建立了一个图文共享的"语义空间"——这个概念值得详细解释。
想象一个巨大的多维空间(实际上是512维或更高,但我们可以简化为三维来理解)。在这个空间中,每个"概念"对应一个点。"橘猫"这个文字被映射到空间中的某个位置,而一张真实橘猫照片也被映射到附近的位置——因为它们表达的是同一个概念。"黑猫"的文字和黑猫的照片在另一个附近的位置——和橘猫距离不远(因为都是猫),但和"卡车"的文字和照片距离很远(完全不同的概念)。
这个空间的神奇之处在于:文字和图片共享同一个空间。传统方法中,图片的特征空间和文字的特征空间是分开的——图片有图片的编码,文字有文字的编码,两者无法直接比较。CLIP把两者"对齐"到了同一个空间——一张猫的照片和"一只猫"这段文字在空间中的距离很近。这意味着你可以用文字来"搜索"图片(找到空间中距离最近的图片),也可以用图片来"搜索"文字(找到最匹配的描述)。
CLIP的零样本能力从何而来?
CLIP展现了惊人的零样本图像分类能力——你给它定义任意的分类标签(比如"猫""狗""汽车""飞机"),它就能用这些标签来分类图片,不需要见过任何这些类别的标注训练样本。
这是怎么做到的?原理其实很简单:把每个标签("猫""狗""汽车")变成文字向量,把待分类的图片变成图像向量,然后计算图像向量和每个标签向量的距离——距离最近的标签就是分类结果。
这里的"距离"是什么意思?可以这样理解:每个向量就像一个人在一间巨大房间里的位置。CLIP训练的结果是——表达相似含义的文字和图片会被"推"到房间的同一个角落,而含义不同的会被"推"到不同的角落。你拿一张橘猫的照片进来,它的图像向量会落在"猫角"附近;"猫"这个文字标签的向量也在"猫角"附近;而"汽车"的文字向量在房间对面的"车辆角"。计算"距离"就是看这张照片的位置离哪个标签的位置最近——在数学上这通常是计算两个向量之间的余弦相似度(方向越一致,相似度越高),直觉上就是"在房间里谁离谁最近"。
因为CLIP在训练时已经从4亿个图文对中学到了"猫的图片和'猫'这个词应该在房间的同一个角落",所以它自然就能做分类——虽然它从来没有被"教"过分类任务。
这和传统图像分类的区别是本质性的。传统方法(如第一章的ResNet)需要为每个具体任务收集标注数据、训练专门的分类器。你要分类猫和狗,就得收集几千张标注好的猫狗图片来训练。换一个任务(分类花的品种),就得重新收集、重新训练。CLIP只需要训练一次,就能做任意类别的分类——因为它学到的是图片和文字之间的通用关系,而不是某个特定任务的规则。
CLIP之所以能做到这一点,两个关键因素缺一不可:第一是训练数据的规模——4亿个图文对覆盖了人类视觉经验的巨大横截面,模型从中学到了几乎所有常见概念的图文对应关系。第二是Transformer架构——ViT让图像编码器具备了强大的全局理解能力(不像CNN只看局部),文本Transformer让文字编码器能理解复杂的语义描述。两个Transformer分别处理图像和文字,然后在语义空间中"会合"——这正是Transformer"万能容器"特性的完美体现。
CLIP对后续产业的奠基作用
CLIP建立的共享语义空间成为了后来整个"文生图"、"文生视频"技术栈的核心组件。当你在Stable Diffusion中输入"一幅梵高风格的星空下的城市"时,CLIP(或其变体)负责把这段文字变成一个语义向量——这个向量携带了"梵高风格""星空""城市"等所有语义信息——然后扩散模型根据这个向量来生成图片。没有CLIP提供的"文字→语义向量"的桥梁,文生图就无从谈起。
CLIP的影响还远超文生图。它催生了一系列跨模态应用:图文搜索(用文字搜索图片库)、图像问答(给图片提问并用文字回答)、视觉导航(用自然语言指令引导机器人)、甚至视频理解(把CLIP扩展到视频帧序列)。可以说CLIP是"多模态AI"这个赛道的基石——后来的GPT-4 Vision、LLaMA 3.2 Vision等多模态大模型,都在不同程度上继承了CLIP的图文对齐思想。
从GAN到扩散模型:生成范式的两次跃迁
CLIP解决了"如何理解图文关系"的问题。但要让AI"画画",还需要一个"生成引擎"——给定一个描述向量,如何生成对应的图片?这个问题的解决经历了两次范式跃迁。
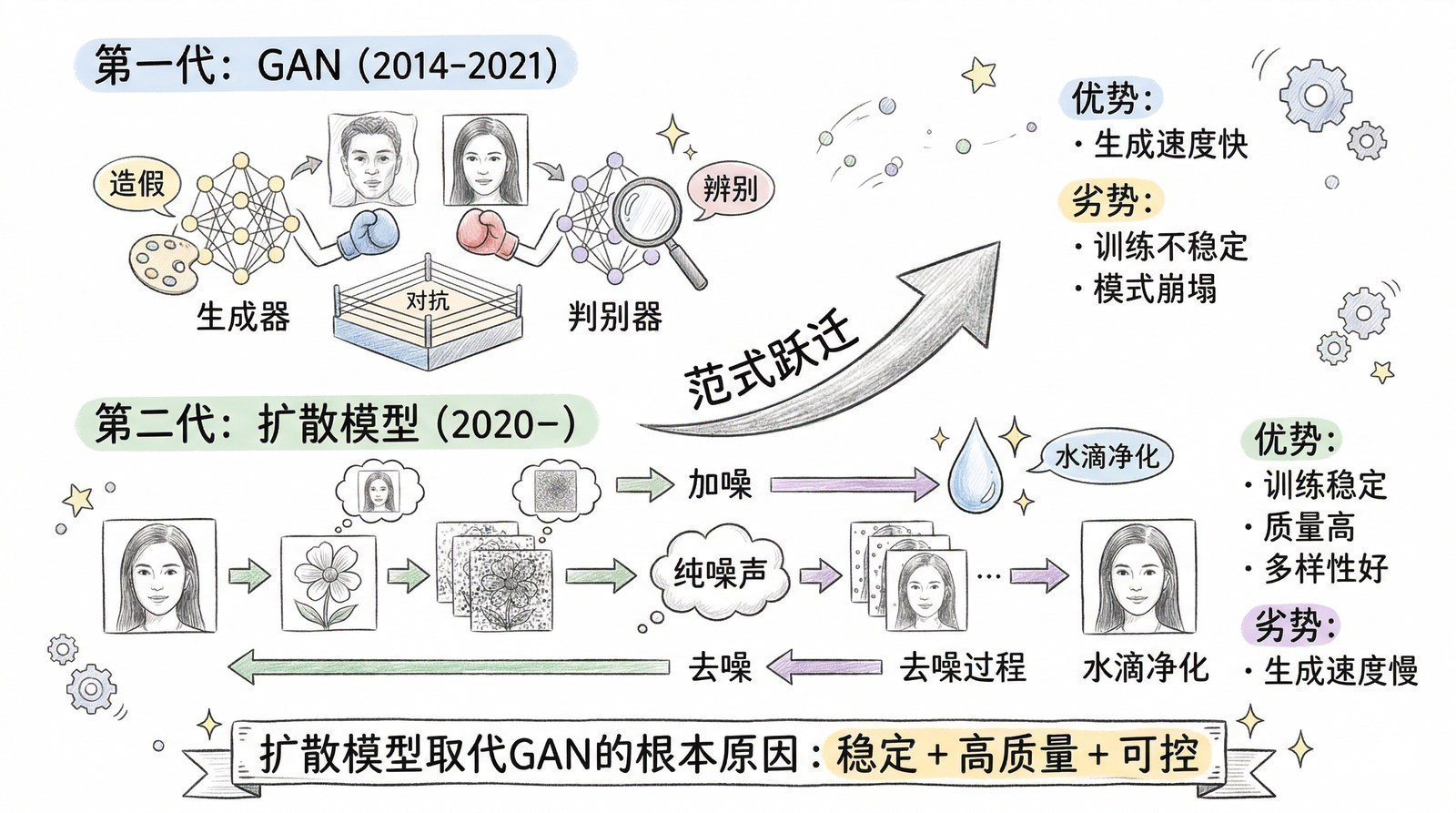
第一代:GAN——对抗中学会创造
2014年,Ian Goodfellow等人提出了GAN(Generative Adversarial Networks,生成对抗网络)[3]——一种让两个神经网络"对抗"来学习生成的方法。一个"生成器"负责从随机噪声生成假图片,一个"判别器"负责判断图片是真是假。生成器不断提高造假水平,判别器不断提高鉴别能力,两者在对抗中共同进步——最终生成器能生成以假乱真的图片。
GAN在2014-2020年间是图像生成的主流范式。NVIDIA的StyleGAN系列能生成极其逼真的人脸照片(著名的"thispersondoesnotexist.com"网站就是基于StyleGAN)。但GAN有几个顽固的问题:训练不稳定(生成器和判别器的平衡很难维持,经常出现一方"碾压"另一方的情况)、模式崩塌(生成的图片多样性不够,模型学到了几个"安全"的生成模式后就不再探索新的可能性)、难以控制(很难让GAN精确生成你想要的特定内容——你只能随机生成然后挑选)。
第二代:扩散模型——从噪声中"复原"出图片
2020年,Jonathan Ho等人发表了DDPM(Denoising Diffusion Probabilistic Models)[4]——扩散模型开始崭露头角。
扩散模型的核心思想反直觉但极其优雅:不是直接学"怎么画图",而是学"怎么从噪声中恢复出图片"。
训练过程是这样的:取一张真实图片,逐步往里加噪声——第1步加一点点,图片还能看清;第10步加了很多,图片变得模糊;第100步加到极致,图片变成了纯随机噪声。然后训练一个神经网络,让它学会"反向操作"——给一张加了噪声的图片,预测并去除噪声,恢复出原图。
生成图片时怎么做?从一张纯随机噪声开始,让模型一步一步去除噪声——每一步都让图片变得更清晰一点——经过几十到几百步,一张清晰的图片就从噪声中"浮现"出来了。这就像一个雕塑家从一块粗糙的石头开始,一刀一刀去除多余的部分,最终露出里面的雕像。
从GAN到扩散模型:为什么范式跃迁发生了?
和GAN相比,扩散模型有三个决定性的优势:训练更稳定(只有一个网络需要训练,不需要维持两个网络的对抗平衡)、生成更多样(不容易模式崩塌,因为每次从不同的随机噪声出发会生成不同的图片)、更容易和条件结合(在去噪的每一步都可以加入文字、类别等条件信号来引导生成方向)。
第三个优势尤其关键——它让扩散模型可以和CLIP完美结合。你用CLIP把文字描述变成语义向量,然后在扩散模型的每一步去噪过程中用这个向量做"引导"——让去噪的方向朝着"和文字描述匹配的图片"进行。这种"文字引导的扩散"就是所有文生图系统的核心机制。GAN从未实现过如此灵活和精确的文字控制。
DDPM证明了扩散模型在图像质量上可以和最好的GAN媲美——从此生成范式开始不可逆转地从GAN向扩散模型转移。但DDPM有一个严重的实用问题:它在原始像素空间中做扩散,计算量巨大——生成一张高分辨率图片需要在几十万维的空间中做数百步迭代,速度极慢。这个问题的解决催生了下一个里程碑——Stable Diffusion。
Stable Diffusion:AI绘画的"民主化时刻"
2022年,慕尼黑大学的Robin Rombach等人发表了Latent Diffusion Models(LDM)[5]——Stable Diffusion的技术基础。
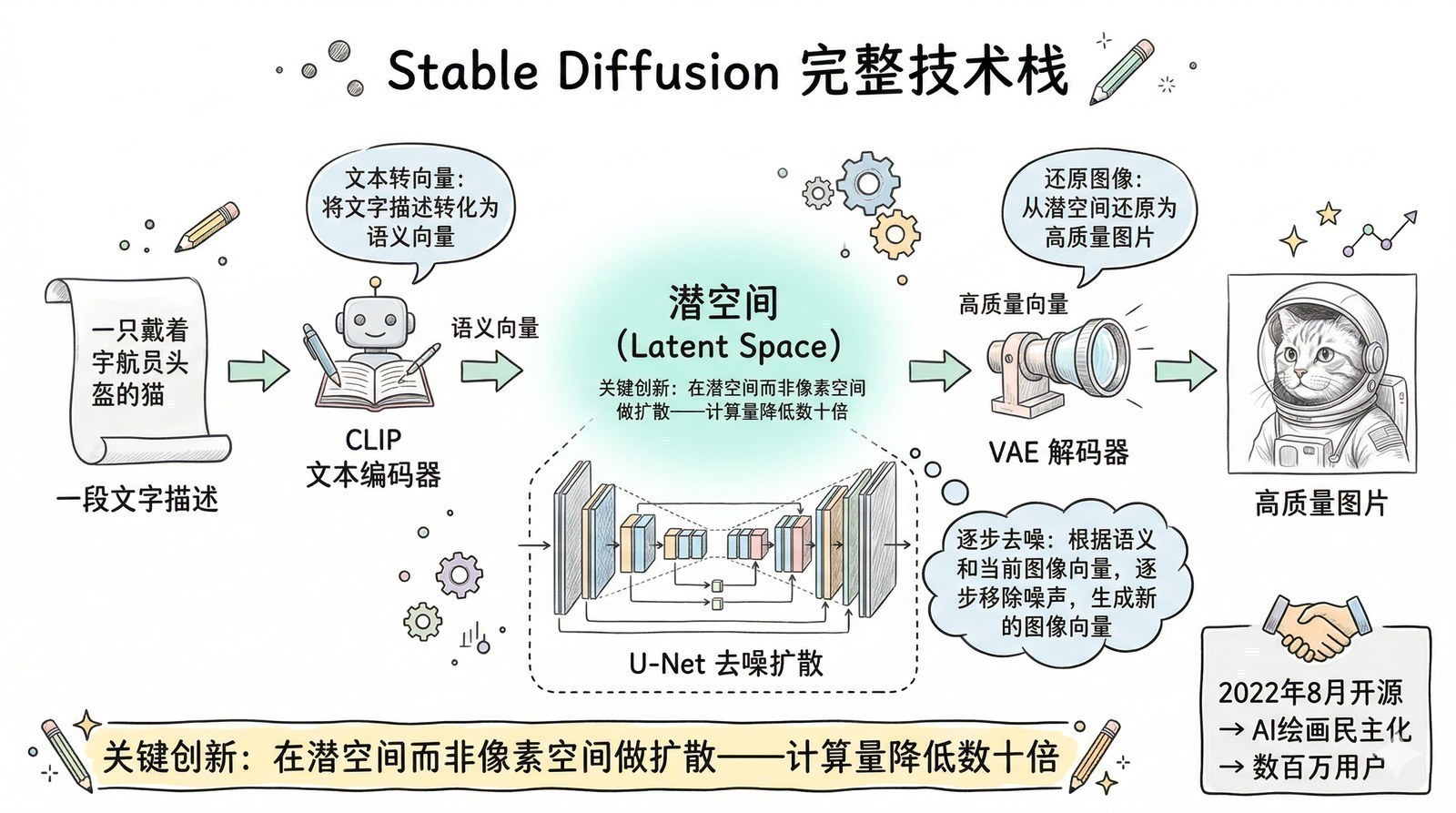
LDM的关键创新是:不在像素空间做扩散,而是先用一个自编码器把图片压缩到低维的"潜在空间"(Latent Space),在潜在空间中做扩散,最后再解压回像素空间。一张512×512的图片有约78万个像素值,但压缩到潜在空间后可能只有几千个数值——扩散过程的每一步计算量降低了几十倍。
2022年8月,Stability AI基于LDM发布了Stable Diffusion——并做了一个改变行业格局的决定:完全开源。任何人都可以下载模型权重,在自己的电脑上运行,甚至在一块消费级GPU上就能生成高质量图片。
Stable Diffusion的开源引发了一场堪比Linux运动的生态爆发。几周内,社区开发出了数千个微调模型——动漫风格、油画风格、写实风格、科幻风格。Civitai等平台成为分享和下载这些模型的中心。"AI绘画"从技术概念变成了全民参与的创作运动——设计师用它做概念草图,游戏开发者用它生成场景素材,普通人用它创作个人艺术作品。
与此同时,OpenAI在2022年4月发布了DALL-E 2[7]——结合CLIP和扩散模型的闭源文生图系统。效果惊艳,但通过API付费使用。Stable Diffusion用开源策略打破了壁垒——让AI绘画从"少数人付费使用"变成了"任何人免费使用"。
从技术到产品:文生图的完整技术栈
回顾整条技术链的迭代路径:GAN(2014年)证明了神经网络可以"生成"图片,但控制力差→DDPM(2020年)用扩散范式解决了GAN的不稳定和模式崩塌问题,但太慢→CLIP(2021年)建立了文字和图片的共享语义空间,让"文字引导生成"成为可能→LDM/Stable Diffusion(2022年)通过潜在空间压缩解决了扩散模型的速度问题,让文生图可以在消费级硬件上运行。
每一步都解决了上一步留下的关键瓶颈。四项技术的叠加,让"用一句话画一幅画"从科幻变成了现实。
但这条链也留下了一个重要的技术局限。扩散模型在潜在空间中的骨干网络是U-Net——一种专为图像设计的卷积架构。U-Net工作得不错,但面临一个根本性问题:它的Scaling特性远不如Transformer——把U-Net做大,效果的提升很快就趋于平缓。而我们在第四章和第六章已经反复看到,Transformer的Scaling曲线可以持续很远。这个局限最终催生了DiT的诞生。
DiT与Sora:熟悉的味道,熟悉的配方——用Transformer统一一切
2022年,纽约大学的William Peebles和Saining Xie发表了DiT(Diffusion Transformer)[6]——做了一件和ViT完全对称的事:把扩散模型的骨干网络从U-Net替换为Transformer。
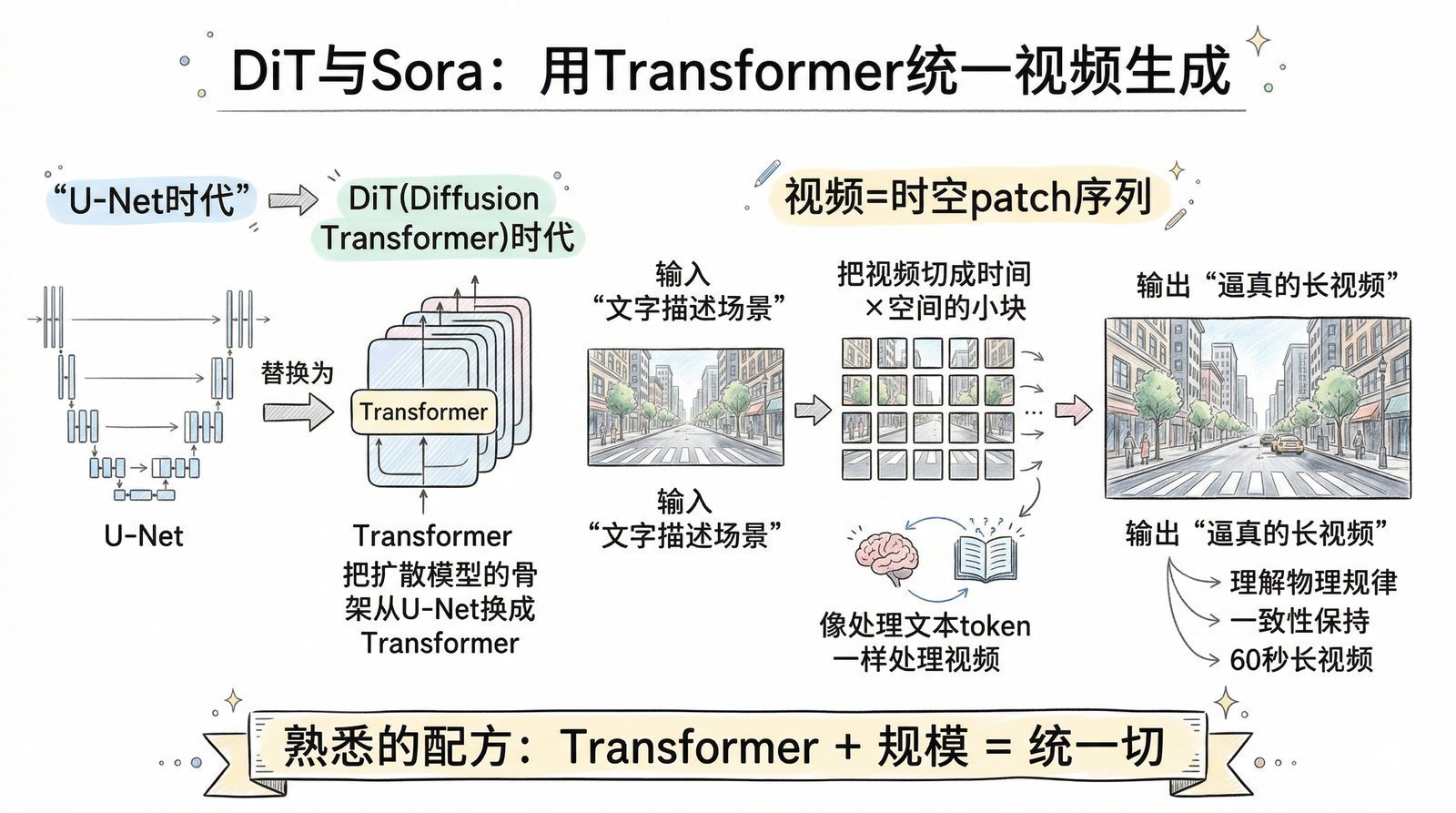
这个替换的逻辑和ViT替换CNN完全一致——U-Net是为图像专门设计的架构,自带卷积先验,在小规模上效果不错,但不够通用、不够容易Scaling。Transformer则是"万能容器"——可以处理任何序列化的数据,而且Scaling特性在文本(GPT系列)和图像分类(ViT)上已经被反复验证。
DiT的价值在于:它证明了Transformer在图像生成任务上也具有优越的Scaling特性——在小规模上DiT和U-Net差不多,但规模增大后DiT的提升曲线更加平滑和持续。这和ViT在图像分类上的表现如出一辙——Transformer的优势总是在规模足够大时才显现出来。
单个任务上Transformer未必比专用架构好——但它胜在通用性和可扩展性。当你需要把系统做得越来越大时,Transformer能搭上GPU并行化的快车(它的注意力计算天然可并行),而U-Net的卷积结构在并行化上受限更多。
DiT的论文发表时没有引起太大关注。但它的第一作者William Peebles随后加入了OpenAI,成为了Sora项目的联合负责人——DiT的思路成了Sora的技术基础。
Sora:"视频数据的世界模拟器"
2024年2月15日,OpenAI发布了Sora的预览——一个能根据文字描述生成长达一分钟高清视频的模型。Sora展示的视频令人震惊:一辆SUV沿着蜿蜒山路行驶、扬起尘土;一个毛茸茸的小怪物在蜡烛旁开心地看着火焰;两个人在东京的雪中漫步——画面流畅、物理效果逼真、镜头运动自然。
Sora的技术核心是"Diffusion Transformer"——把视频压缩到潜在空间,分解成"时空patch"(既有空间维度也有时间维度的小块),然后用Transformer来处理这些patch的序列。这和ViT把图片切成空间patch、用Transformer处理的逻辑一脉相承——只是从二维(图片的宽×高)扩展到了三维(视频的宽×高×时间)。
OpenAI在技术报告中写道,Sora是一个"视频数据的世界模拟器"——它不只是在"画动画",而是在学习物理世界的运行规律:光影如何变化、物体如何运动、空间如何延展。
图像生成 vs 视频生成:不只是多了一个"时间维度"
从技术角度看,视频生成和图像生成共享同一套底层范式(扩散模型+Transformer),但视频生成面临的挑战远比"给图像加上时间轴"复杂得多。
第一个挑战是时间一致性。生成一张图片只需要保证空间上的协调(物体的形状、比例、光影要合理)。但生成视频还需要保证帧与帧之间的连贯——同一个人在不同帧中不能突然变脸,一辆行驶中的车不能在下一帧突然消失。这种"时间一致性"是视频生成中最难解决的问题——Sora的很多"穿帮"(物理不合理、物体突然变形)都源于此。
第二个挑战是计算量的爆炸。一段5秒24帧的视频有120帧,每帧相当于一张图片——计算量是单张图片的120倍。而且帧之间不是独立的,每一帧都需要"关注"前面所有帧以保持一致性——这让注意力计算的复杂度随视频长度快速增长。Sora能生成一分钟视频(约1440帧)所需的算力是惊人的。
第三个挑战是物理理解。一张静态图片不需要"理解"物理——画一辆停着的车不需要知道重力。但视频需要——一辆行驶的车应该扬起灰尘、转弯时应该倾斜、刹车时前轮应该下压。Sora在这方面展现了令人惊讶的"物理直觉"——虽然它从未被"教"过物理定律,但从海量视频数据中"学到"了物体运动的大致规律。
这些挑战使得视频生成的技术门槛远高于图像生成——这也是为什么文生图在2022年就已经"民主化"(Stable Diffusion可以在笔记本上跑),而文生视频到2025年仍然主要是少数大公司的领地。
Transformer统一之路:从文本到图像到视频的五步进化
从ViT到Sora,Transformer用同一种"序列+注意力"的范式逐步统一了所有视觉任务。这条统一之路值得从技术、产品和产业三个维度来完整梳理。
第一步:Transformer统一文本处理(2017-2020年,第四章)。GPT和BERT证明了Transformer在NLP任务上的统治力。这一步的产品影响是搜索引擎(Google将BERT集成到搜索)和文本生成(GPT-3的API),产业影响是NLP从学术研究走向大规模商用。
第二步:Transformer统一图像理解(ViT,2020年)。ViT证明了同一个Transformer架构可以直接处理图像——把图片切成patch序列即可。产品影响是图像分类、目标检测等视觉任务开始用Transformer替代CNN,Google在搜索图片理解中逐步采用ViT架构。产业影响是计算机视觉搭上了Scaling快车——视觉模型可以像语言模型一样,通过增大规模来持续提升。
第三步:Transformer打通文本和图像的语义空间(CLIP,2021年)。两个Transformer(一个处理图像、一个处理文字)在共享语义空间中"会合"。产品影响是零样本图像分类、图文搜索成为可能,为后来所有文生图系统提供了核心组件。产业影响是"多模态"从学术概念变成产品方向——CLIP证明了图文融合不只是实验室的玩具,而是可以大规模部署的技术。
第四步:Transformer统一图像生成(DiT,2022年)。把扩散模型的骨干从U-Net替换为Transformer。产品影响是图像生成的质量和可控性持续提升——Stable Diffusion 3.0等后续版本都采用了DiT架构。产业影响是文生图从"可用"走向"好用"——DiT的Scaling特性意味着只要投入更多算力和数据,生成质量就能持续提升。
第五步:Transformer统一视频生成(Sora,2024年)。把DiT从二维(图片)扩展到三维(视频)。产品影响是文生视频从"科幻"变成"现实"——一句话就能生成一分钟的高清视频。产业影响是影视、广告、教育等内容产业面临深刻重构——视频内容的生产成本和门槛被大幅降低。
五步进化中,每一步都是同一个架构的自然延伸,不需要为新数据类型发明新架构。每一步都验证了同一个规律:简单通用的架构在单任务小规模上可能不如专用设计,但规模足够大时,它的可扩展性让所有专用架构望尘莫及。这就是第四章"榫卯结构"的论点在视觉领域的完整验证——Transformer不是在某一个任务上做到了最好,而是在所有任务上做到了"足够好并且还能持续变好"。
多模态生成的产业版图
AI从"理解"走向"创造",对产业的冲击比对话AI更直接、更猛烈。到2024-2025年,一批标杆公司和产品定义了这个赛道的格局,全新的产业机会和深刻的行业震动同时发生。
AIGC产业的爆发:从文生图到文生视频
文生图领域,Stable Diffusion(Stability AI,开源)和Midjourney(闭源,通过Discord使用)是两大支柱。Midjourney的故事尤其传奇——由David Holz(Leap Motion联合创始人)于2022年在旧金山创立,没有接受任何风险投资,没有发表过学术论文,零营销支出,纯靠产品质量和口碑增长。到2025年,Midjourney的Discord注册用户超过2100万,年收入达到5亿美元,团队只有约107人——人均年收入产出超过500万美元,是全球最高效的AI公司之一。Midjourney占据了全球AI图像生成市场约26.8%的份额,领先于DALL-E的24.4%。2022年8月公司就已经实现盈利——在绝大多数AI公司还在亏损的时候。Adobe也迅速入局,推出了Firefly系列,将AI生成能力集成到Photoshop等设计师日常使用的工具中。
文生视频领域竞争更为激烈。OpenAI的Sora在2024年2月预览后轰动全球,但直到2024年12月才正式对公众开放。在这段等待期中,竞争者迅速跟进:Runway(美国初创,从Gen-1迭代到Gen-3,是最早做文生视频的公司之一)、Pika(美国初创,斯坦福系,以简洁界面和快速迭代著称)。中国公司在文生视频赛道上表现尤其亮眼——字节跳动的即梦(Dreamina/Seedance)和快手的可灵(Kling)都在2024年发布,在视频质量、运动一致性和可控性上迅速追赶甚至在部分指标上超越了Sora。2025年9月Sora 2发布时,可灵和即梦已经在中国市场建立了先发优势。这是中国AI公司在多模态生成领域第一次展现出和硅谷正面竞争的实力。
AIGC(AI-Generated Content)正在成为一个数百亿美元规模的市场。营销和广告领域,AI生成的产品图、海报和短视频正在替代传统摄影和设计——成本降低了一到两个数量级。游戏和影视领域,AI生成的概念设计和特效镜头改变了内容生产流程。电商领域,AI生成的商品展示图和虚拟模特试穿已成标配。教育和科普领域,AI插图和演示视频让知识传播更加直观。
行业震动:创作的门槛在坍塌,规则在重写
全新的产业机会背后,是对传统创意行业的深刻震动。
Stable Diffusion发布后的几个月里,设计社区经历了从兴奋到焦虑的快速转变。概念艺术家发现AI可以在几秒钟内生成他们需要几小时才能完成的草图。游戏公司开始用AI生成概念设计。广告公司尝试用AI生成营销素材。2022年9月,AI生成的画作《太空歌剧》在科罗拉多州博览会的数字艺术比赛中获得一等奖——提交者Jason Allen使用Midjourney生成图像后在Photoshop中修饰并打印在画布上参赛。这一事件引发了艺术界关于"AI创作是否算艺术"的激烈争论。
版权问题是更深层的震动。生成模型的训练数据来自互联网——其中包含大量版权作品。2023年,多位艺术家对Stability AI、Midjourney和DeviantArt提起集体诉讼,指控未经许可使用版权作品训练模型。LAION-5B数据集(第六章)也面临法律挑战。这些诉讼到2025年仍在进行中——AI生成内容的版权归属问题是这场革命中最大的法律灰色地带。
影视行业同样感到不安。一个一分钟的高质量AI视频,传统制作可能需要几十万预算和数周时间。AI视频生成把成本和时间压缩了几个数量级。一个共识正在形成:AI不太可能完全取代人类创作者,但它会深刻改变创作的门槛和流程——从"从零创作"变成"在AI生成基础上精炼",创作者的核心价值从"执行能力"转向"审美判断和创意方向"。
多模态的革命与一个全新产业的诞生
从"看见"到"看懂"到"创造":三级跳
第一章的CNN让机器"看见"了物体,但不理解含义。ViT和CLIP让机器"看懂"了——不只是识别一只猫,还能理解"一只慵懒的橘猫躺在温暖的阳光下"。扩散模型和Sora让机器学会了"创造"——从文字描述生成逼真的图片和视频。每一级跳跃都依赖于前一级的成果:没有"看见"就无法"看懂",没有"看懂"就无法"创造"。
Transformer"万能容器"的最终验证
从文本到图像分类到图文对齐到图像生成到视频生成,Transformer用同一种范式统一了所有任务。只要数据可以被序列化(文本天然是序列,图片可以切成patch序列,视频可以切成时空patch序列),Transformer就能处理它。这种通用性在小规模上未必占优,但在大规模上的Scaling特性让所有专用架构都无法与之竞争。
开源定义了赛道格局
Stable Diffusion的开源是这场革命最重要的产业事件之一。它让AI绘画从"少数人的工具"变成了"全民的创作手段",催生了庞大的社区生态。这个教训在LLaMA开源(第九章)和DeepSeek开源(第十三章)中被反复验证——在AI领域,开源不仅是技术共享,更是定义赛道格局的战略武器。
一个全新产业的爆发
文生图和文生视频不仅是技术突破——它们催生了一个全新的产业。2023-2025年间,"AI生成内容"(AIGC)从实验室概念变成了一个数百亿美元规模的市场。在营销和广告领域,AI生成的产品图、海报和短视频正在替代传统摄影和设计——成本降低了一到两个数量级。在游戏和影视领域,AI生成的概念设计和特效镜头正在改变内容生产流程——小团队用AI工具可以完成以前需要大型制作公司才能做的视觉效果。在电商领域,AI生成的商品展示图和虚拟模特试穿已成标配。在教育和科普领域,AI插图和演示视频让知识传播更加直观。从Stable Diffusion开源(2022年8月)到AIGC成为资本市场广泛认可的赛道,只用了不到两年。随着视频生成能力持续提升,这个产业的天花板远未到达。
AI从"看见"进化到了"看懂"并学会了"创造"——多模态大模型打通了语言、图像和视频之间的壁垒。但在2023-2024年,行业发现了一个更紧迫的问题:全球数十家公司同时涌入大模型赛道,开源vs闭源、效率vs规模、中国vs美国的竞争全面展开。谁会活下来?大模型的竞争格局正在以前所未有的速度重塑。
本章引用论文
[1] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (ViT), 2020, Google (Dosovitskiy et al.)
[2] Learning Transferable Visual Models From Natural Language Supervision (CLIP), 2021, OpenAI (Radford et al.)
[3] Generative Adversarial Nets (GAN), 2014, Montreal (Goodfellow et al.)
[4] Denoising Diffusion Probabilistic Models (DDPM), 2020, UC Berkeley (Ho, Jain, Abbeel)
[5] High-Resolution Image Synthesis with Latent Diffusion Models (LDM/Stable Diffusion), 2022, LMU Munich (Rombach et al.)
[6] Scalable Diffusion Models with Transformers (DiT), 2022, NYU/UC Berkeley (Peebles, Xie)
[7] DALL-E 2: Hierarchical Text-Conditional Image Generation with CLIP Latents, 2022, OpenAI (Ramesh et al.)
[8] Sora Technical Report: Video Generation Models as World Simulators, 2024, OpenAI
第九章:百家争鸣——开源运动、效率革命与全球竞争
ChatGPT点燃了火种,接下来的两年,全世界都在问同一个问题:我怎么才能做出自己的大模型?
LLaMA:一次改变行业格局的"泄露"
2023年2月24日,Meta发布了LLaMA(Large Language Model Meta AI)[1]——一组从7B到65B参数的语言模型。论文报告了一个令整个行业震惊的数字:LLaMA-13B(130亿参数)在大多数NLP基准上的表现与GPT-3(1750亿参数)相当甚至更好——参数量只有GPT-3的十三分之一。
这个结果是Chinchilla哲学(第六章)的完美验证:不是盲目做大模型,而是用更多高质量数据来训练规模适当的模型。LLaMA在1.4万亿token上训练——是GPT-3的3000亿token的近5倍——这才是它能以小博大的关键。
Meta最初的计划是有限开放——研究者需要申请才能获得模型权重。但发布不到一周,2023年3月3日,LLaMA的完整权重被泄露到4chan论坛,并迅速在网络上扩散。全世界的开发者第一次可以免费下载并使用一个GPT级别的大模型。
开源社区的"寒武纪大爆发"
这次泄露引发了一场堪比生物学寒武纪大爆发的连锁反应——短短几周内,数十个基于LLaMA的衍生模型如雨后春笋般涌现。
最先亮相的是斯坦福大学的Alpaca(2023年3月13日)。斯坦福的研究者用GPT-3.5(text-davinci-003)自动生成了5.2万条"指令+回答"的训练数据,然后用这些数据在LLaMA 7B上做微调。整个训练在8块A100 GPU上只花了3小时,总计算成本不到600美元。效果令人震惊——在定性评估中,Alpaca的表现和OpenAI的text-davinci-003相当。这意味着:一个斯坦福研究组用600美元和3小时,就做出了接近OpenAI数百万美元产品水平的模型。
紧接着是UC Berkeley的Vicuna(2023年3月30日)。Vicuna走了一条不同的数据路线——不用AI生成数据,而是从ShareGPT网站收集了7万条用户与ChatGPT的真实对话记录。基于LLaMA 13B微调,训练成本约300美元。研究者用GPT-4做评判,声称Vicuna达到了ChatGPT约90%的质量。Vicuna相比Alpaca的一个重要改进是支持多轮对话——上下文长度从512扩展到2048,让模型可以进行更自然的连续对话。
然后是Nomic AI的GPT4ALL(2023年3月底)——这个项目的目标不是做"最强的模型",而是做"人人都能运行的模型"。GPT4ALL对LLaMA做了量化压缩,让模型可以在普通笔记本电脑的CPU上运行——只需要8GB内存,不需要GPU。虽然质量不如Alpaca和Vicuna,但它把大模型的使用门槛从"你需要一块价值万元的GPU"降到了"你只需要一台普通电脑"。
此后还有更多衍生模型接踵而至:微软的WizardLM用一种叫"Evol-Instruct"的技术自动生成越来越复杂的指令数据;Databricks的Dolly完全用人工标注数据来避免GPT-3.5生成数据的版权争议;Together AI的RedPajama项目则直接复现了LLaMA的整个训练数据集——1.2万亿token的开源训练语料。
这些衍生模型的异同点很有意思。Alpaca和Vicuna的核心差异在数据来源——Alpaca用AI生成的指令数据,Vicuna用真实用户对话。实践证明后者的质量更高,因为真实对话包含了人类交互的自然模式(追问、纠正、澄清),而AI生成的指令数据往往过于"工整"。GPT4ALL则走了完全不同的路——不追求最强效果,而是追求最低的运行门槛。这三个方向——更好的数据、更好的效果、更低的门槛——后来成为了开源大模型社区发展的三条主线。
仅2023年一年,社区就在HuggingFace上发布了超过7000个基于LLaMA的衍生模型。2023年5月,Google内部一份匿名备忘录泄露,标题引人注目:"我们没有护城河,OpenAI也没有。"这位工程师认为:开源社区正在以惊人的速度追赶闭源模型,大公司在AI领域的技术优势正在瓦解。
LLaMA的发展历程:从巅峰到被追赶
LLaMA的故事不止于第一次泄露——它后来经历了完整的产品化迭代,也经历了从领先到被追赶的过程。
LLaMA 2(2023年7月)是Meta主动拥抱开源的标志——这一次完全开放商用(月活超过7亿的公司需要单独授权),提供7B/13B/70B三个版本,在2万亿token上训练。LLaMA 2同时发布了Chat版本(经过RLHF对齐),是第一个开源的、可商用的、经过对齐的大语言模型。
LLaMA 3(2024年4月)进一步扩大了训练数据规模——15万亿token,是LLaMA 2的7.5倍。8B和70B两个版本在同等参数量级上都是当时最强的开源模型。
LLaMA 3.1(2024年7月)增加了405B版本——这是当时参数量最大的开源模型,在多项基准上接近闭源的GPT-4。它的发布被视为开源模型第一次真正逼近闭源前沿。
LLaMA 3.2(2024年9月25日)是LLaMA系列第一次进入多模态领域。它包含两个视觉模型(11B和90B,支持图片+文字输入)和两个轻量文本模型(1B和3B,可以在手机和边缘设备上运行)。视觉模型基于LLaMA 3.1的文本模型加装了视觉适配器,能理解图表、图像描述和视觉推理——标志着开源模型也开始具备GPT-4级别的多模态能力。
然而LLaMA 4(2025年4月)的发布却令人失望。LLaMA 4采用了MoE架构(Scout版本17B激活/109B总参数,Maverick版本17B激活/400B总参数),支持原生多模态。但在多项评测中,LLaMA 4的表现不如同期的DeepSeek-V3、Qwen 2.5等竞争对手,社区反馈也相对冷淡。
为什么Meta最初能做出领先的开源模型,却没能持续保持优势?
LLaMA的核心团队来自Meta的FAIR(Fundamental AI Research)实验室——由图灵奖得主Yann LeCun于2013年创立。LeCun不是LLaMA的直接技术负责人(论文第一作者是Hugo Touvron等FAIR研究员),但他是Meta整体AI开源哲学的精神领袖和最坚定的公开倡导者——他在社交媒体上持续为开源辩护、批评闭源路线,对Meta决定开放LLaMA起到了关键的推动作用。
但FAIR在Meta内部的处境并不轻松。2023-2024年,Meta的战略重心在元宇宙和虚拟现实(Reality Labs年亏损超过160亿美元)——AI虽然重要,但不是唯一焦点。LLaMA团队的核心成员在成功后开始流失——这在硅谷是常态,但对一个需要持续迭代的项目来说是致命的。更深层的原因是:FAIR的文化是学术研究导向(鼓励发论文、追求新方法),而不是产品工程导向(追求极致效率和用户体验)。当竞争进入工程优化的深水区时——比如DeepSeek在万卡集群效率和MoE架构上的极致优化——研究导向的团队就会显得力不从心。
还有一个讽刺的因素:开源本身是一把双刃剑。Meta开源了LLaMA,全世界的团队就可以站在LLaMA的肩膀上继续迭代——而这些团队中最优秀的(如DeepSeek、阿里Qwen),可能在特定方向上做得比Meta自己更好。当你把"地基"免费分享给所有人,最终在上面盖出最好的房子的可能不是你自己。
这个故事揭示了AI竞争的残酷本质:在这个领域,领先优势可能只维持几个月。每一次重大模型发布都可能重新洗牌。没有任何一家公司——无论是OpenAI、Google还是Meta——可以确保自己持续领先。
大模型"开源"到底开源了什么?
LLaMA引发的开源运动让"开源大模型"成为一个热门话题。但很多人——包括很多从业者——对大模型的"开源"和传统软件的"开源"有一个根本性的误解。
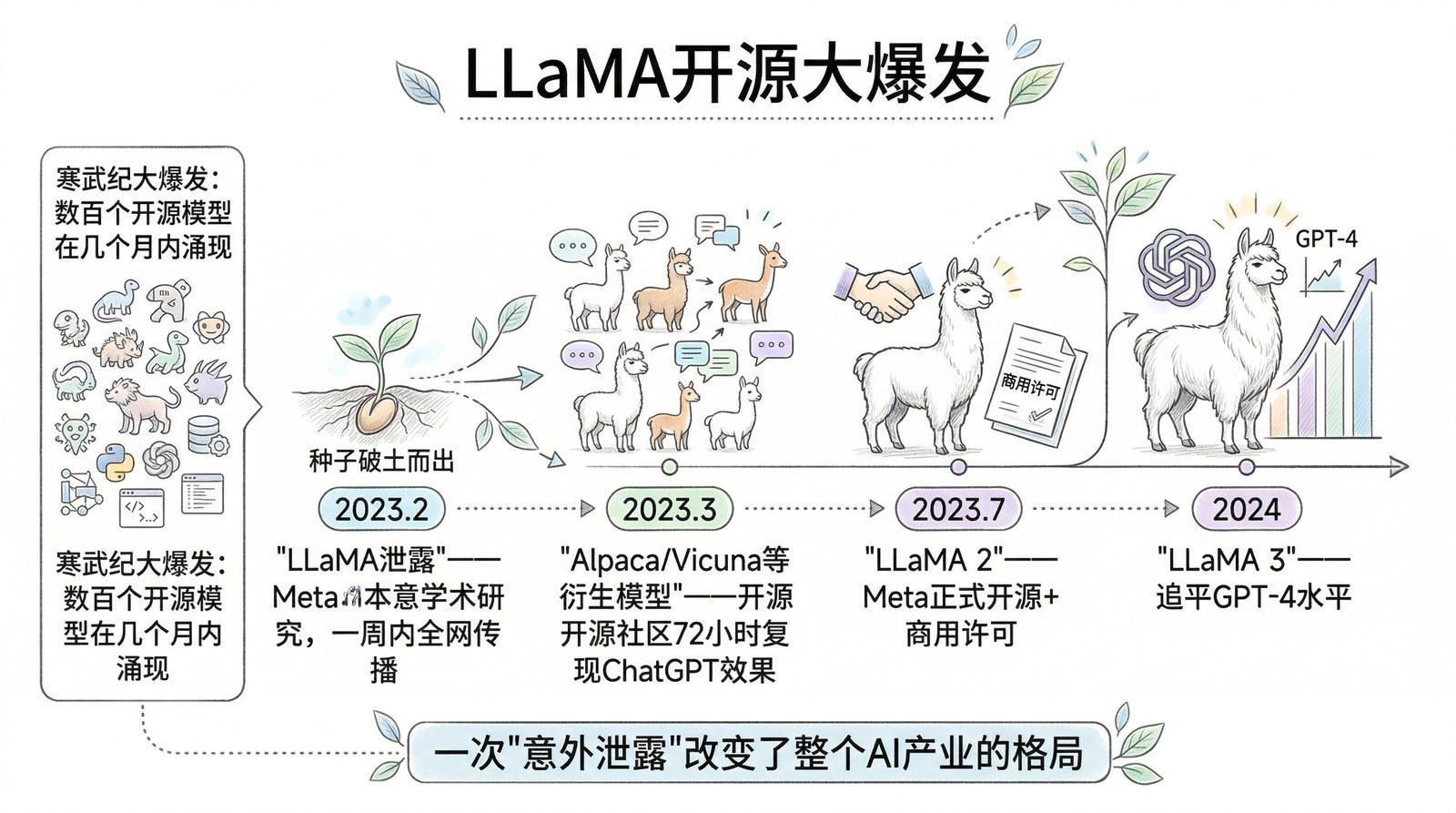
传统的开源(如GitHub上的开源项目)开放的是源代码——人类可以阅读的文本文件。你可以打开一个Python文件,逐行阅读代码,理解它在做什么,修改它的逻辑,然后重新运行。源代码是"透明"的——你能完全理解它。
大模型的"开源"开放的是模型权重——一个几十GB到几百GB的二进制文件,里面包含数十亿甚至数千亿个浮点数。这些数字是模型在训练过程中自动学到的参数——你不能"阅读"它们(看到的只是一串串无意义的数字),你不能理解它们为什么是这个值,你也无法通过修改个别数字来改变模型的行为。你能做的是:用这些权重来运行模型(推理)、在这些权重的基础上做微调(后训练)。
开源大模型通常还包括推理代码、微调代码和tokenizer配置。但通常不包括训练数据(涉及版权)、完整的训练代码和超参数配置。
所以大模型的"开源"更像是一个连续光谱,而非一个二元状态:最封闭的一端是只提供API(如GPT-4),中间是开放模型权重但不开放训练细节(如LLaMA 2/3),再往前是开放权重加上详细的训练代码和数据配方(如DeepSeek-V3/R1的技术报告),最开放的一端是开放一切包括训练数据——但这在实践中极为罕见,因为训练数据几乎必然涉及版权问题。
理解这个区别很重要,因为它决定了"开源大模型"的真正价值:你可以使用它、微调它、部署它——但你很难从零复现它。这也是为什么开源模型的出现并没有让大模型公司"失业"——"做出一个好的基座模型"仍然需要巨大的资源和know-how。
GPT-4:闭源标杆与"CloseAI"的最终确认
2023年3月14日,OpenAI发布了GPT-4[4]——一个在几乎所有基准上都大幅领先的模型。但更引人注目的是它的技术报告:只有98页,却几乎不包含任何有意义的技术细节——不公布参数量(外界根据各种线索猜测约1.8万亿参数,可能采用8个专家的MoE架构)、不公布训练数据的组成、不公布架构的具体设计。OpenAI的理由是"安全考虑和竞争格局"——但AI社区普遍认为这标志着"OpenAI"到"CloseAI"的转变彻底完成(第五章已讨论过这个趋势)。
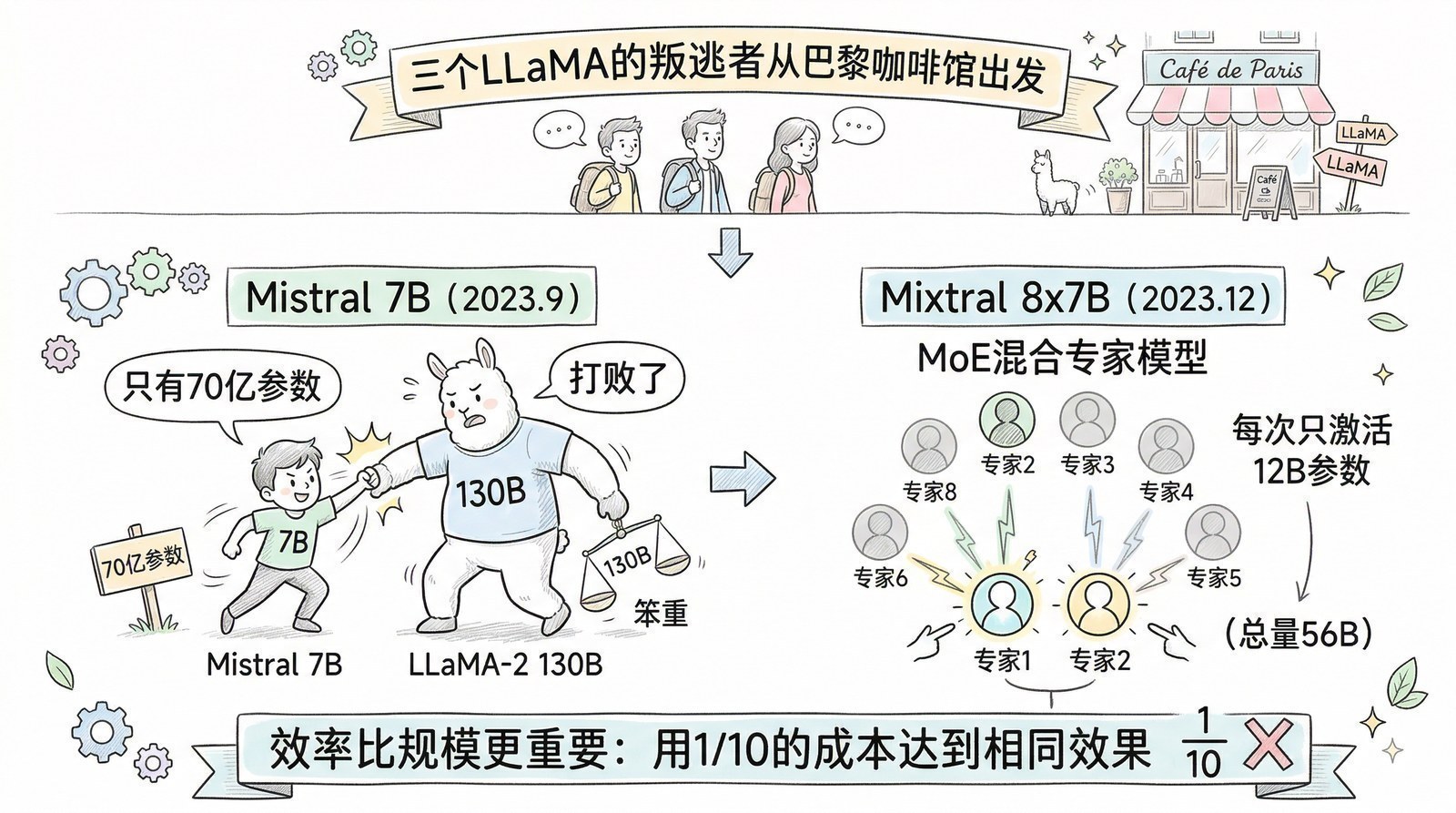
GPT-4的能力跃升
尽管技术细节保密,GPT-4展示的能力是实打实的。
在标准化考试上,GPT-4的表现让很多人第一次真正感到"AI可能比我聪明":模拟律师资格考试(Uniform Bar Exam)得分在前10%——大多数法学院毕业生一次通过的比例只有约60-80%。SAT数学拿到了约700/800(前7%左右),SAT阅读写作约710/800。多项AP考试(生物、化学、环境科学、宏观经济学、心理学、统计学、美国历史、美国政府等)获得了4-5分(满分5分)。GRE写作4/6。
更重要的突破是多模态能力——GPT-4不仅能处理文本,还能理解图片。你可以给它一张手绘的网页草图,它能生成对应的HTML代码。给它一张图表,它能分析数据趋势并用文字描述。给它一张菜单照片,它能推荐菜品。这是大模型第一次真正把"看"和"说"融合到了产品级别——CLIP(第八章)在技术上打通了图文语义空间,GPT-4把这种融合变成了每个用户都能体验的产品功能。
GPT-4也有明显的局限——它仍然会产生幻觉(编造事实),在复杂数学推理上还会犯错,而且它的"多模态"最初只是单向的(能理解图片但不能生成图片)。但作为一个产品,GPT-4把"AI助手"的能力天花板又提高了一个档次——从GPT-3.5的"还行"到GPT-4的"相当好用"。
GPT-4与具身智能:当机器真正"看懂"世界
GPT-4的多模态能力还有一个深远影响——它为具身智能(Embodied Intelligence)提供了关键的感知基础。
具身智能不是简单的"能走能跳能翻跟头的机器人"——那只是机械运动能力。真正的具身智能是指拥有人类感知和理解能力的机器人——它不仅能看到一个物体,还能理解这个物体是什么、有什么用途、在当前场景中意味着什么。
在GPT-4之前,计算机视觉的主流方法是深度学习分类模型(第一章的CNN系列)。这类模型可以"识别"一张图片中有一只狗——输出"狗,置信度98%"——但它不"理解"这只狗。它不知道这只狗在做什么、心情如何、和周围环境是什么关系。你问它"这只狗在干什么?",它回答不了——因为它只被训练了"分类"任务。
GPT-4式的多模态大模型则完全不同。你给它一张照片——一只金毛犬蹲在门口,嘴里叼着一双拖鞋——它能告诉你:"这只金毛看起来在门口等主人回家,嘴里叼着拖鞋,可能是在表达欢迎。"它不仅"看到"了图片中的物体,还"理解"了场景的语义、物体之间的关系、甚至隐含的情感和意图。
当机器通过GPT-4这样的多模态大模型获得了对图像和视频的"语义理解"能力——不只是识别物体,而是理解场景——传统机器人的感知系统就会发生质的变化。一个搭载了多模态大模型的机器人走进一间乱糟糟的卧室,它能"理解":这是一间卧室,床上的衣服需要叠好,地上的杯子需要放回桌上,窗帘需要拉开。它不需要为每个物体和每个动作编写专门的识别规则——多模态大模型给了它一种通用的、泛化的场景理解能力。
这正是长期困扰计算机视觉领域的瓶颈——传统的视觉感知需要为每个场景、每种物体单独训练模型,泛化能力极差。GPT-4的多模态能力第一次展示了一种真正通用的视觉理解方案——这为具身智能的感知层带来了革命性的提升。具身智能的完整故事将在后续章节展开。
Mistral:从巴黎咖啡馆走出的效率革命
2023年的开源大模型故事中,最引人注目的不仅是Meta的LLaMA,还有一家来自法国的初创公司——Mistral AI。
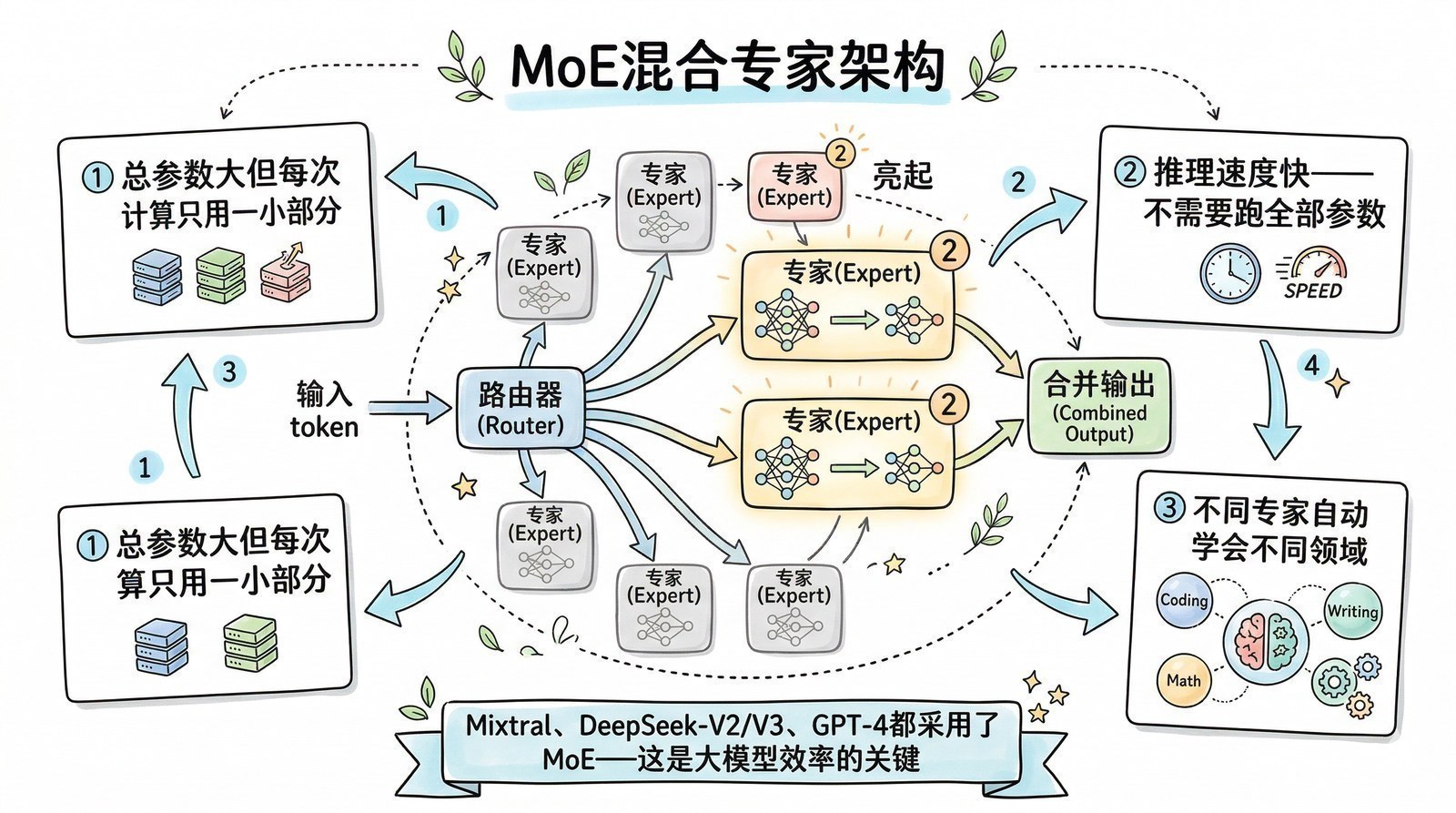
三个LLaMA的"叛逃者"
2023年4月,Arthur Mensch(前Google DeepMind研究科学家,曾是Chinchilla论文的核心作者)、Guillaume Lample和Timothée Lacroix(两人都是前Meta FAIR研究员,Lample是LLaMA论文的共同作者)在巴黎联合创立了Mistral AI。三位创始人在法国顶级理工院校(巴黎综合理工和巴黎高等师范学院)结缘,都是大模型领域的一线研究者——他们不仅懂论文中的理论,更懂训练大模型的工程细节。
Mistral成立仅两个月后的2023年6月就完成了1.05亿欧元(约1.17亿美元)的种子轮融资——创下了当时欧洲AI初创公司的融资记录。到2024年,Mistral的估值已超过60亿美元。这家公司成为了"欧洲AI"的旗帜——证明不只有美国和中国能做前沿大模型。
Mistral 7B:小而强
2023年9月,Mistral发布了Mistral 7B——一个只有70亿参数的模型,在多项基准上超越了LLaMA 2的13B版本。参数量小了近一倍,效果却更好。Mistral 7B的成功证明了:在模型设计和训练策略上的精细优化,可以弥补甚至超越参数量的差距。
Mixtral和MoE:激活"对的参数"
2024年1月,Mistral发布了Mixtral 8x7B[2]——一个基于MoE(Mixture of Experts,混合专家)架构的模型。
MoE不是Mistral发明的——它最早由Google的Noam Shazeer等人在2017年提出[3]。有趣的是,Shazeer也是2017年Transformer论文"Attention Is All You Need"的共同作者之一——同一个人在同一年贡献了大模型时代两项最重要的技术基础。
MoE的核心思想是:模型包含多个"专家"子网络,但每次推理只激活其中一小部分。Mixtral有8个专家,每次输入一个token时只激活2个——所以虽然总参数量约470亿,但每次推理只用到约130亿参数。这就像一家大公司有很多部门(法务、财务、技术、市场),但处理一个具体任务时只需要两三个相关部门参与——其他部门不用动,但公司的总体能力覆盖了所有方向。
为什么之前的大模型大多采用Dense(稠密)架构而不是MoE?因为MoE的工程实现比Dense复杂得多——路由机制(决定每个token激活哪些专家)的设计很精细,不同专家之间的负载均衡难以保证(如果所有token都涌向同一个专家怎么办?),多GPU之间的通信开销也更大。在模型规模还不太大的时候,MoE带来的效率优势不足以抵消工程复杂度的增加。但当模型规模增大到数百亿甚至数千亿参数时,MoE的优势开始显现——因为推理成本和激活参数量挂钩而非总参数量,你可以用"大容量但低推理成本"的方式来构建模型。
MoE和Dense的优劣可以简洁概括:Dense模型简单稳定,所有参数在每次推理时都被使用,训练和工程实现相对容易。MoE模型复杂但高效,总知识容量大(参数多)但推理成本低(只激活部分),适合规模极大的模型。MoE的劣势在于:虽然推理只激活部分参数,但所有参数都需要加载到内存中——所以内存占用并没有减少,只是计算量减少了。
Mixtral在多项基准上达到了和GPT-3.5相当甚至更好的水平——一个开源模型第一次在效果上追平了ChatGPT的底层模型。更重要的是,Mixtral证明了MoE在开源社区中是可行的——此前MoE主要被Google内部使用。Mixtral之后,DeepSeek的V2和V3模型将MoE架构推到了极致——DeepSeekMoE在路由机制、专家粒度和负载均衡上做了深度创新,效率远超Mixtral,成为2024-2025年最具影响力的架构创新之一。关于DeepSeekMoE的技术细节和它如何以极致效率挑战闭源巨头的故事,将在第十三章专门展开。
中国的"百模大战"
ChatGPT的冲击波在中国引发了一场空前的AI竞赛。2023年上半年,从互联网巨头到传统科技企业到高校实验室到创业公司,几乎所有有能力的机构都宣布了自己的大模型计划。媒体将这场竞赛称为"百模大战"。
大厂阵营
百度最先行动——2023年3月16日发布文心一言(ERNIE Bot),成为中国第一个对标ChatGPT的产品。文心一言的底层是百度从2019年开始积累的ERNIE(Enhanced Representation through Knowledge Integration)预训练模型系列,融入了知识图谱技术。
阿里巴巴于2023年4月发布通义千问(Qwen),后来走向开源路线,Qwen系列成为中国国际竞争力最强的开源大模型之一——Qwen 2.5在多项国际基准上和LLaMA 3.1等国际顶级开源模型正面竞争。
腾讯于2023年9月发布混元大模型(Hunyuan),侧重于和腾讯自身的产品生态(微信、QQ、企业微信、腾讯云)集成。
字节跳动的豆包(Doubao,前身为云雀大模型)于2023年内测,2024年全面爆发,凭借字节的产品能力和流量优势迅速成为中国C端用户量最大的AI助手之一。
华为的盘古大模型侧重行业应用和政企市场,利用华为在运营商和政府客户中的渠道优势。科大讯飞的星火大模型(Spark)于2023年5月发布,利用讯飞在语音和教育领域的积累。商汤的日日新(SenseNova)和360智脑也在同一时期发布。
创业公司阵营
这波浪潮中涌现了一批引人注目的创业公司,很多创始人来自中国顶级高校和研究机构。智谱AI(清华系)推出ChatGLM系列,基于清华自研的GLM架构,是最早的中国开源大模型之一。百川智能由前搜狗CEO王小川创办,于2023年6月发布Baichuan系列。月之暗面(Moonshot AI)由清华NLP实验室的杨植麟创办,主打长上下文能力的Kimi Chat于2023年10月发布,支持20万字的上下文窗口——在当时是一个突破性的特性。MiniMax由前商汤科技副总裁闫俊杰创办,推出了海螺AI。零一万物(01.AI)由创新工场创始人李开复创办,发布了Yi系列开源模型。深度求索(DeepSeek)由幻方量化的梁文锋创立,从2023年11月开始发布DeepSeek系列(第六章已详细介绍了幻方/DeepSeek的算力故事)。此外还有阶跃星辰(StepFun,前微软亚洲研究院副院长姜大昕创办)、面壁智能(ModelBest,清华系,CPM系列)、昆仑万维的天工AI等。
学术机构
高校也积极参与——清华大学(与智谱合作的ChatGLM)、复旦大学(MOSS,中国较早的开源对话模型)、哈工大和科大讯飞(中文BERT/RoBERTa系列,更早期的预训练工作)都做出了贡献。
百模大战的深层问题与积极意义
这场大战暴露了几个深层问题。第一,真正从零训练基座模型的团队很少——相当一部分"大模型"实际上是在LLaMA等开源模型基础上做微调,换一层皮加一些中文数据就包装成自己的产品。第二,同质化严重——绝大多数团队的技术路线几乎相同(Transformer架构、公开数据集、RLHF/DPO对齐),差异化有限,竞争变成了资源竞争。第三,商业模式不清晰——烧钱速度远超收入增长。到2024年,大量中小玩家已经退出或转型。
但百模大战的积极意义同样巨大:它让中国在极短时间内积累了大量的大模型工程经验和人才储备,为2025年DeepSeek的爆发提供了人才和技术土壤。
Anthropic与Claude:为什么"安全优先"的公司做出了最强的代码模型
在OpenAI和Meta的"闭源vs开源"对立之外,Anthropic走出了第三条路。
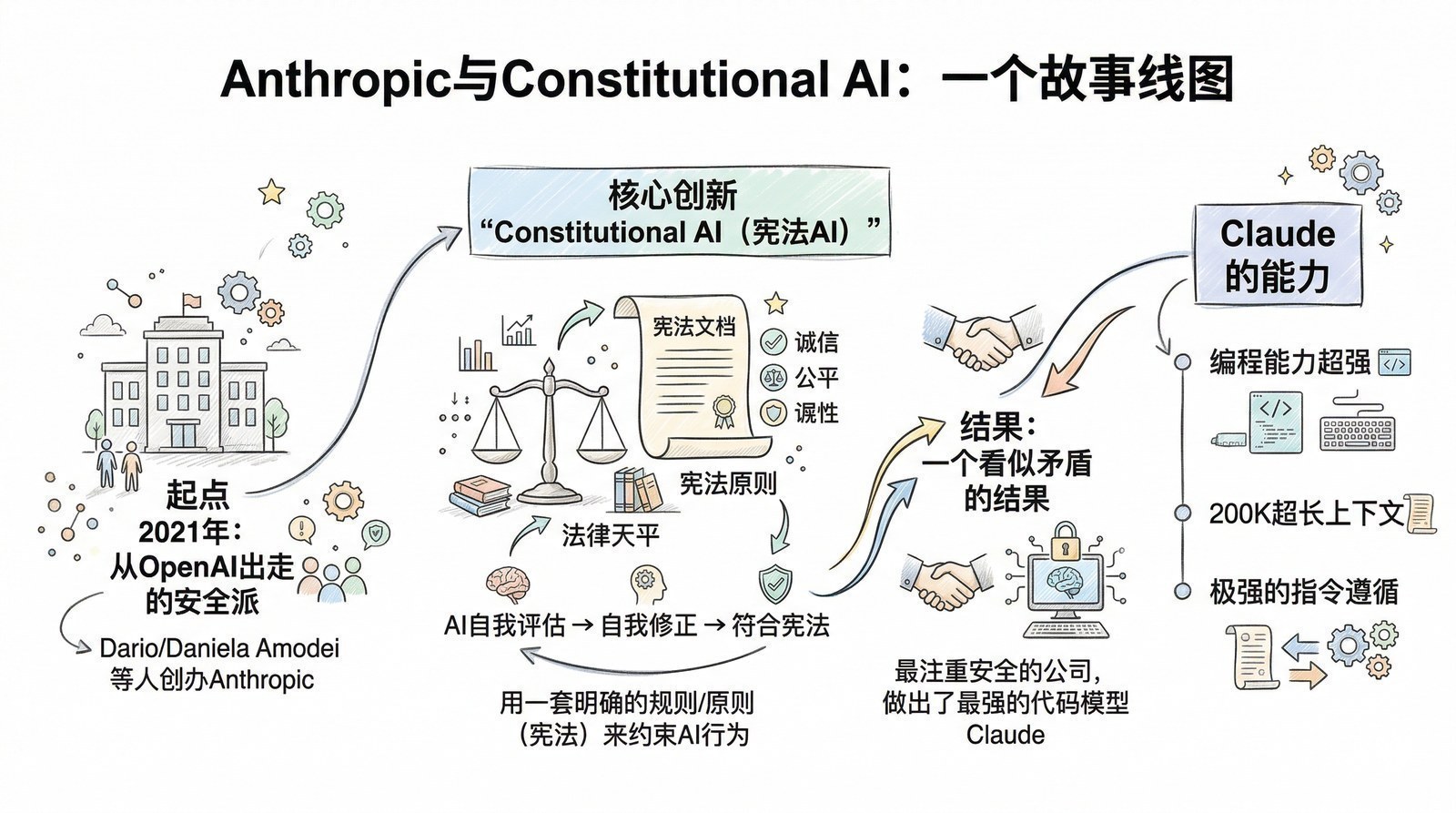
从OpenAI出走的"安全派"
Anthropic由OpenAI前研究副总裁Dario Amodei和其妹妹Daniela Amodei,以及其他几位前OpenAI核心成员于2021年创立。他们离开OpenAI的核心原因是对AI安全的关切——他们认为OpenAI在追求能力(更大的模型、更强的产品)的过程中,没有给安全研究足够的优先级和资源。
Constitutional AI:用"宪法"来约束AI
Anthropic提出了一种独特的对齐方法——Constitutional AI("宪法AI")。
传统的RLHF(第七章)需要大量人类标注者来判断"哪个回答更好"——成本高、标准因人而异、难以规模化。Constitutional AI的核心思路是用AI来评判AI:
首先,Anthropic的研究者编写了一套明确的"宪法原则"——比如"回答应该是有帮助的""不应该鼓励暴力""应该诚实,不确定时应承认不知道""不应该帮助用户做违法的事"等。然后,让模型生成回答后,再让另一个AI(或同一个模型的另一个实例)根据这些原则来评判和修改回答。修改后的回答作为训练数据,用来进一步优化模型。
这种方法的优势是:原则可以被明确写出、公开审查和迭代更新——就像一个国家的宪法可以被公民讨论和修正。相比之下,RLHF中人类标注者的判断标准是隐含的、因人而异的、难以审查的。
一个看似矛盾的结果
Claude系列模型在安全性上的表现一直是业界标杆。但令很多人意外的是,到2024-2025年,Claude在代码能力和深度推理上同样成为了顶级模型——Claude 3.5 Sonnet和Claude 4 Opus在编程任务、长文本分析和复杂推理上获得了开发者社区的广泛好评,Anthropic的Claude Code成为了AI编程领域的标杆工具之一(第七章)。
"安全优先"的公司为什么能做出最强的代码和推理模型?这看似矛盾,但深层逻辑是相通的。
要让模型"安全",你首先需要理解模型为什么会给出不安全的回答——这需要深入理解模型的内部推理过程。Anthropic在"可解释性"(Mechanistic Interpretability)研究上投入了大量资源——试图打开模型的"黑箱",理解每个神经元在做什么、信息在模型内部如何流动。这些研究不仅帮助了安全对齐,还为能力提升提供了独特的洞察——因为你越理解模型怎么"想",就越能让它"想"得更好。
打一个比方:一个医生如果对人体运作机制了解得非常深入(为了治病),他同时也能给出更好的健康建议和训练方案。Anthropic对模型内部机制的深入理解,反过来帮助他们训练出了更强的推理和代码能力——安全研究和能力研究不是矛盾的,而是相互促进的。
竞争格局:从"一家独大"到"多极世界"
到2024年底,大模型的竞争格局已经从ChatGPT发布时的"OpenAI一家独大"演变为多极世界。
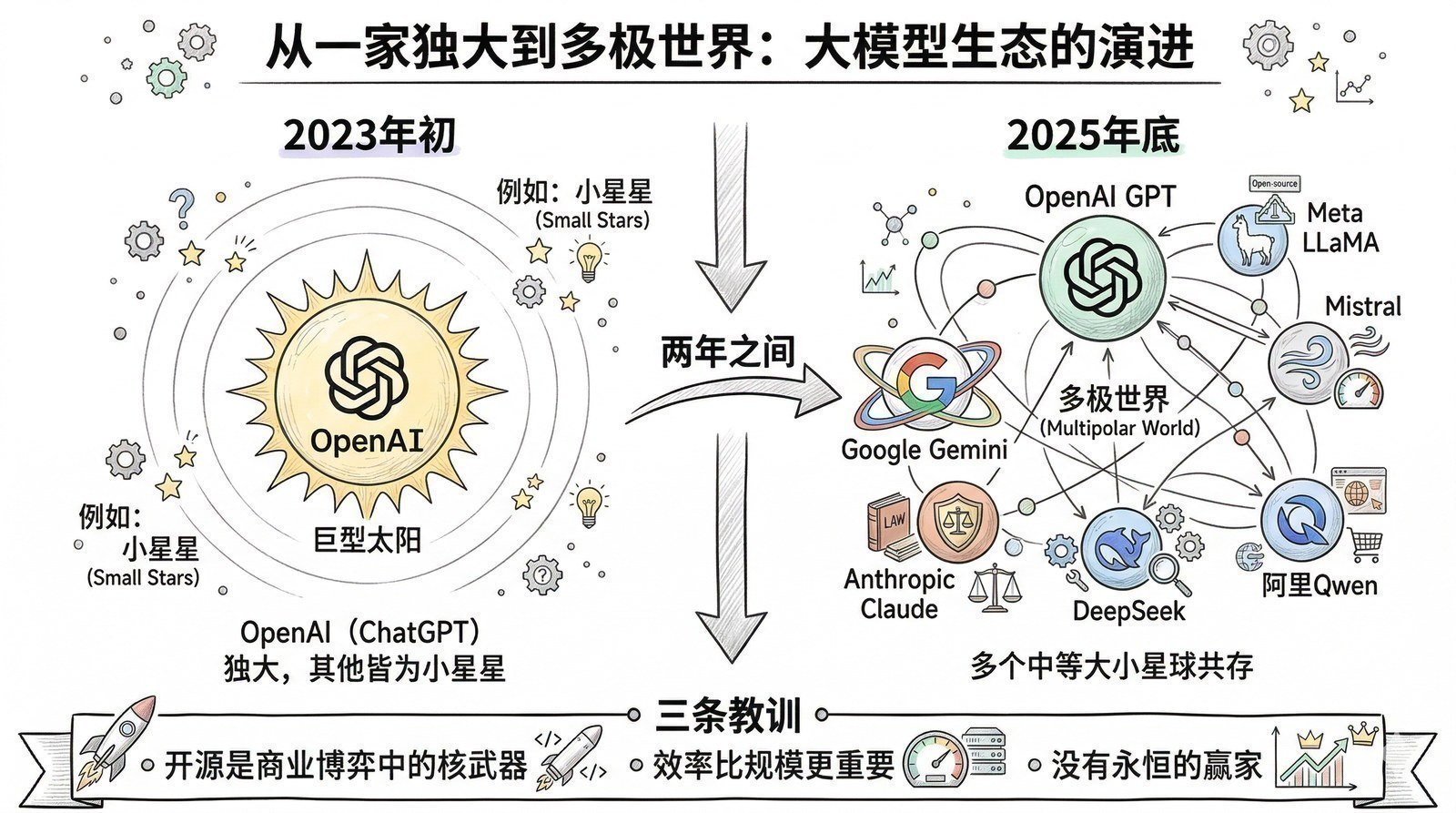
闭源阵营形成了三强——OpenAI(GPT-4/4o/o1)、Google(Gemini系列)和Anthropic(Claude系列)。三者各有侧重:OpenAI追求最强能力和最广用户覆盖,Google追求多模态和搜索集成,Anthropic追求安全、推理和代码能力。
开源阵营以Meta的LLaMA为开创者,但最强的开源模型不再只来自Meta——阿里的Qwen、DeepSeek、Mistral都在各自的方向上达到了前沿水平。开源模型的能力在2023-2024年以惊人速度追赶闭源模型——LLaMA 3.1 405B在多项基准上已接近GPT-4。
中国形成了独立的竞争格局——字节豆包、阿里通义千问、DeepSeek、智谱ChatGLM是头部玩家。其中DeepSeek以极致效率路线脱颖而出,到2025年初凭借DeepSeek-V3和R1震动全球。
这个多极格局的形成,本质上是开源运动的结果。LLaMA把"进入门槛"从数十亿美元降到了几百万美元,让全世界的创新者都有机会参与竞争。
这一章告诉我们什么
开源不是理想主义,是商业博弈中的核武器
Meta开源LLaMA的战略逻辑是清晰的商业计算——和Android打破iOS垄断的逻辑完全一致。当全世界都在用LLaMA生态时,OpenAI和Google的闭源API就不再是唯一选择。但开源也是双刃剑——你开源的东西可能被别人用来超越你自己。
Scaling Law遇到了"实用性"的瓶颈
从GPT-3到ChatGPT是质变(不可用→可用),从ChatGPT到GPT-4是显著提升,但从GPT-4到GPT-4o/4.5的提升对普通用户已经很难感知。继续在预训练阶段堆规模的边际收益在递减。行业需要新的方向来实现下一次质变——这个方向就是"推理"。第十章将展开这个故事。
效率比规模更重要
LLaMA-13B以GPT-3十三分之一的参数达到了相当水平。Mixtral用MoE让推理成本大幅降低。DeepSeek-V3用2048块GPU做到了接近16000块GPU才能做到的事情。这些案例都指向同一个结论:在大模型竞争中,效率比规模更有战略价值——因为效率的提升可以让更多人参与竞争、创造更多应用、服务更多用户。规模是少数巨头的游戏,效率是所有人的机会。
GPT-4代表了"越大越强"的顶峰。LLaMA和Mixtral代表了"更小更高效"的反击。但到2024年,两条路线都遇到了一个共同问题:仅靠预训练的Scaling,模型在推理、数学和复杂任务上的进步开始放缓。
行业需要一个新的突破口。2024年9月,OpenAI发布了o1模型——不是更大的模型,而是一个"会思考"的模型。大模型时代最重要的范式转移正在发生。
本章引用论文
[1] LLaMA: Open and Efficient Foundation Language Models, 2023, Meta (Touvron et al.)
[2] Mixtral of Experts, 2024, Mistral AI (Jiang et al.)
[3] Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer, 2017, Google (Shazeer et al.)
[4] GPT-4 Technical Report, 2023, OpenAI
第十章:让AI思考——推理模型与强化学习的爆发
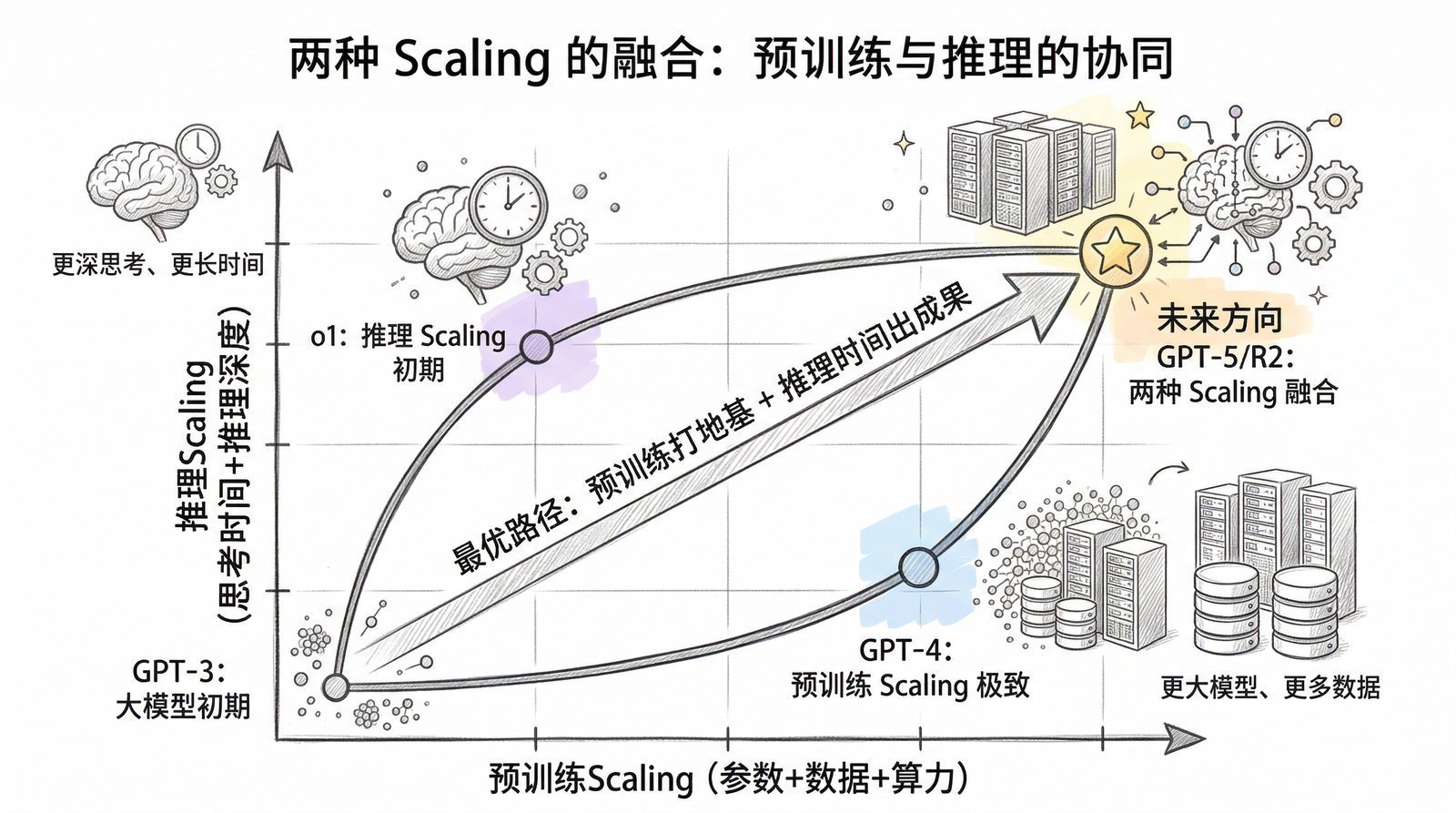
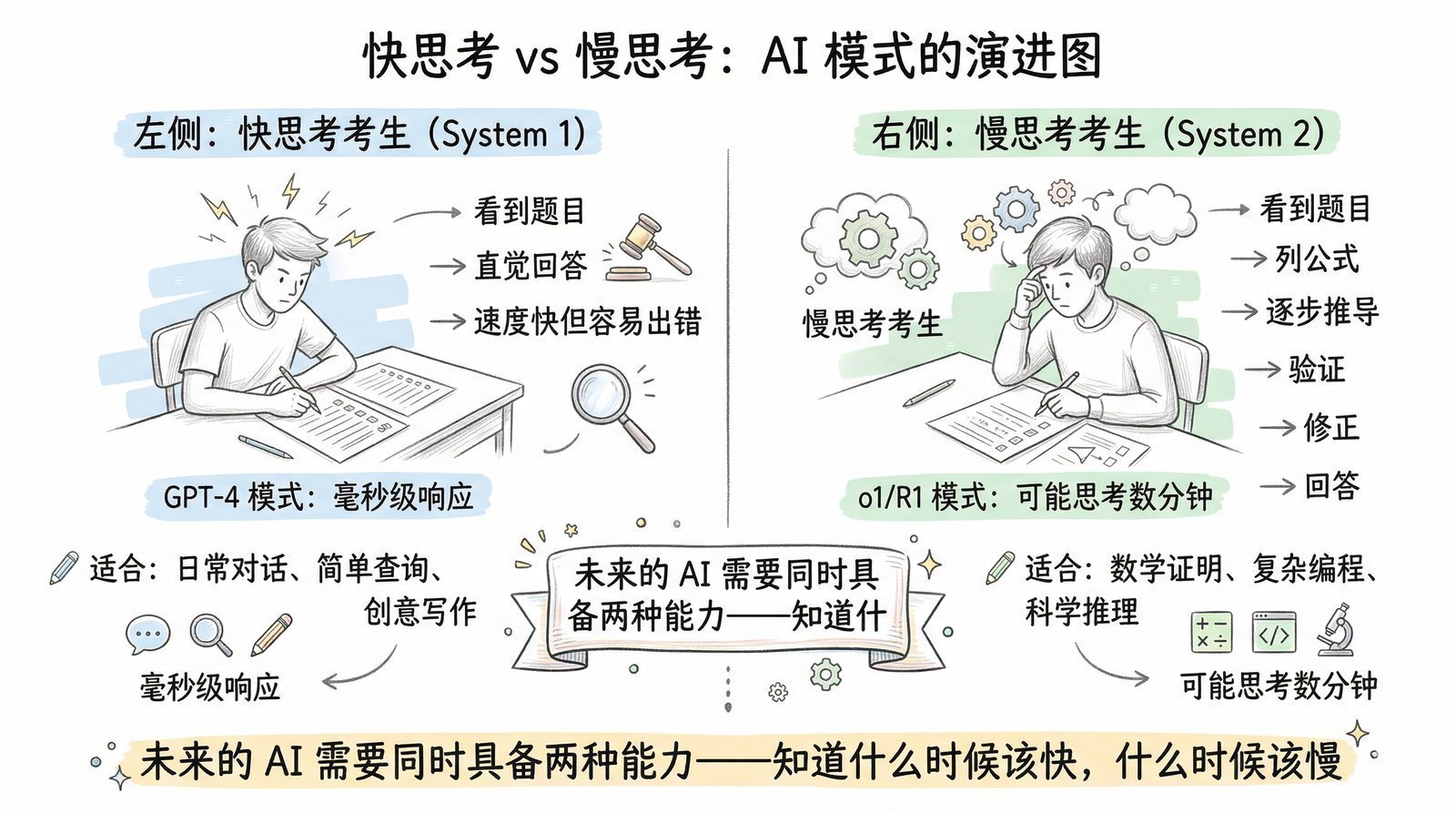
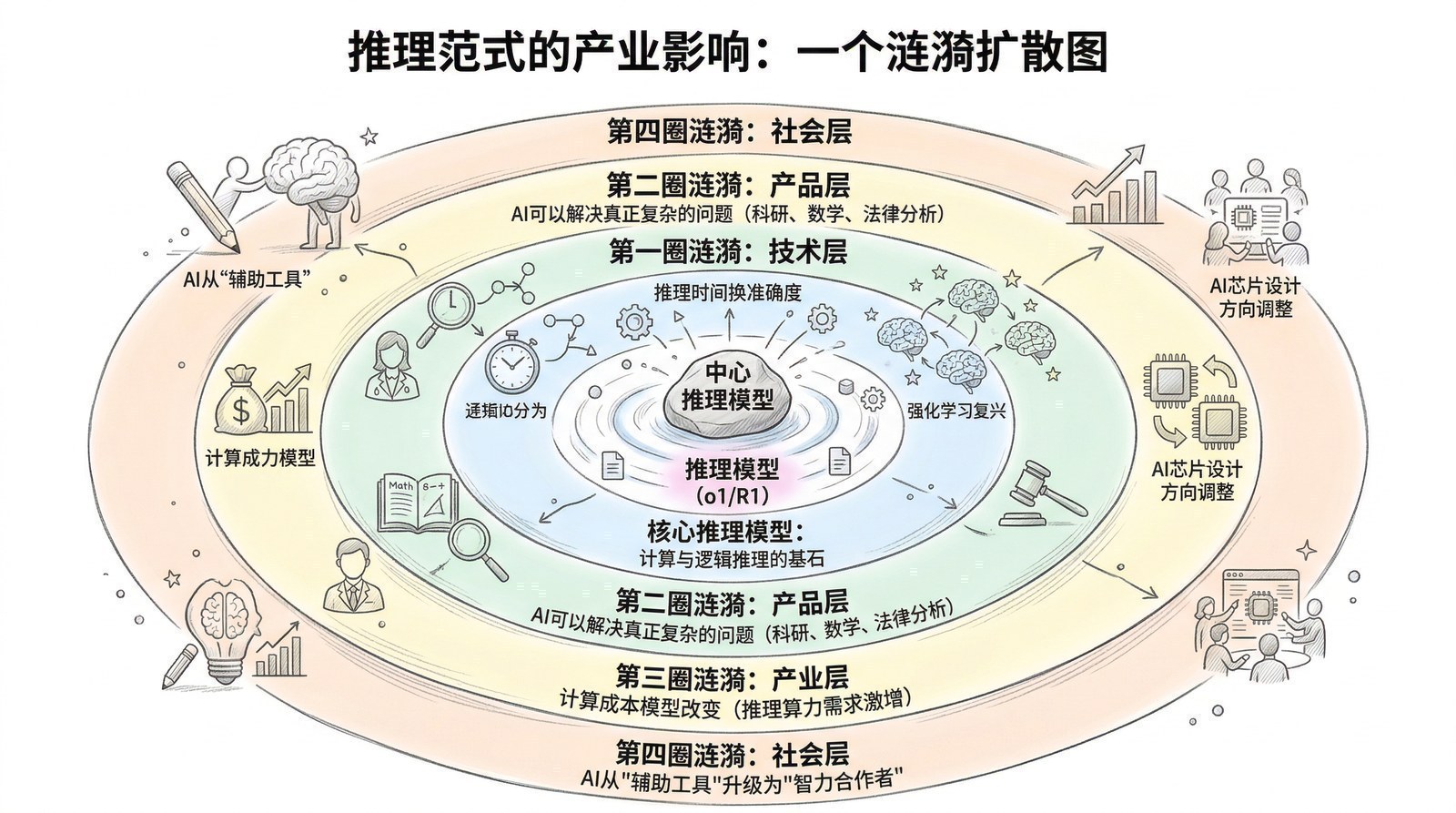
以前让AI更大,现在让AI更会想——这可能是比Transformer更重要的范式转移
预训练Scaling撞墙:GPT-4之后发生了什么
从GPT-2到GPT-3到GPT-4(第五章到第九章),大模型的进步遵循一条清晰的路线:更多的参数+更多的数据+更多的算力=更强的模型。Scaling Law(第六章)给这条路线提供了理论保证——性能随规模增长是可预测的、平滑的。
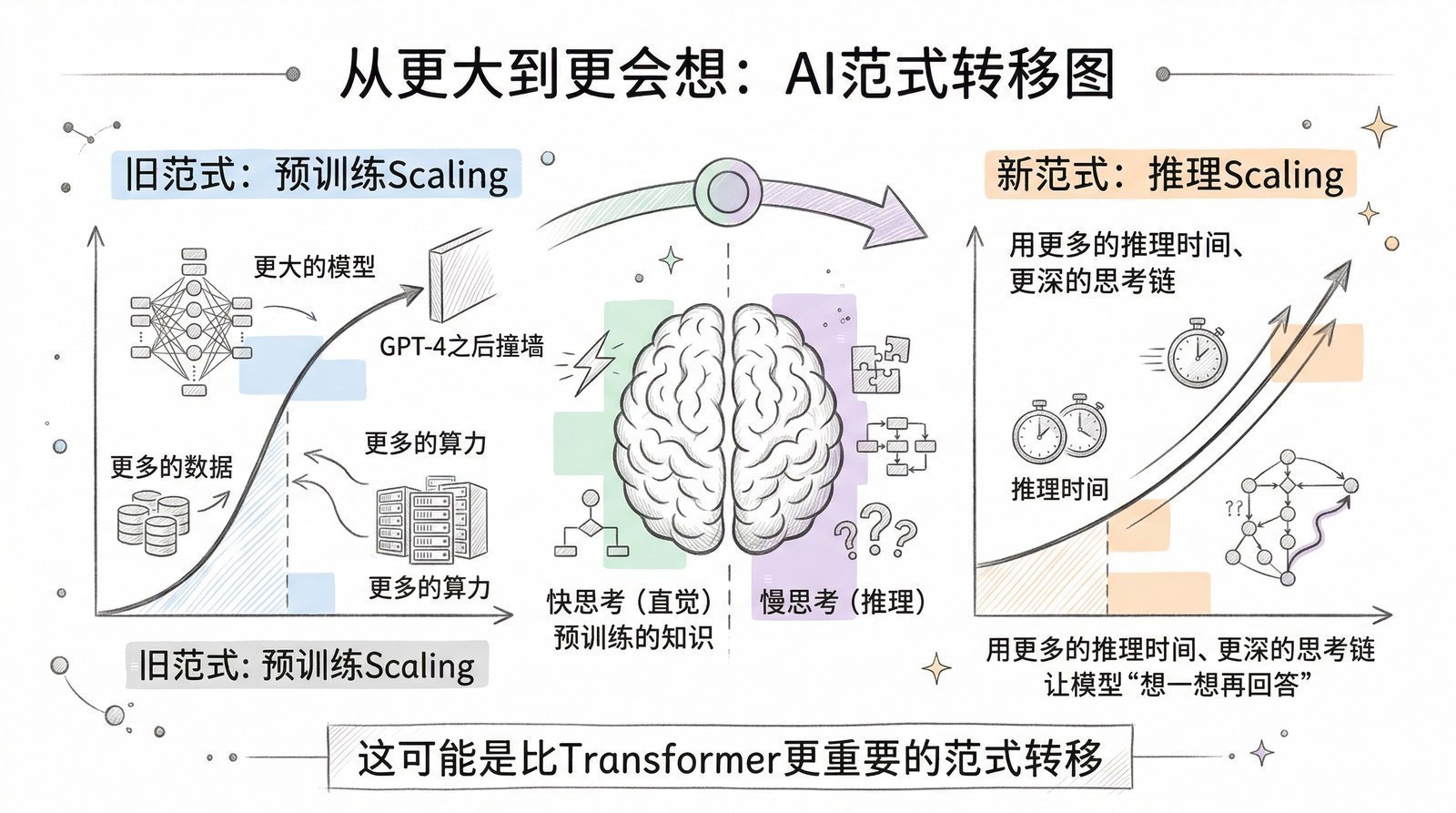
但2024年的现实开始偏离这条路线。
业内传闻OpenAI最初计划训练的"GPT-5"(内部代号Orion)在预训练阶段的表现没有达到预期——性能提升不够大、不够稳定,最终被降级为GPT-4.5发布。虽然OpenAI从未公开确认这一说法,但它反映了行业的一个共识:单纯在预训练阶段继续堆规模,边际收益正在递减。
为什么会撞墙?有几个可能的原因。第一,高质量数据正在枯竭——互联网上"有价值的文本"是有限的,当你已经用了十几万亿token来训练时,剩余可用的高质量数据越来越少。第二,算力成本的增长速度超过了性能提升的速度——从GPT-3到GPT-4的算力投入可能增长了10倍以上,但用户感知到的提升远没有10倍。第三,也是最根本的——预训练的"知识"和"推理"是两种不同的能力。你可以通过更多数据让模型"知道"更多事实,但这不会自动让它"推理"得更好。就像一个读了所有物理教科书的学生不一定能解物理竞赛题——他缺的不是知识,而是解题能力。
行业需要一种新的方法让AI变得更强——不是通过"学习更多知识",而是通过"学会更好地思考"。
OpenAI o1:让模型"想一想再回答"
2024年9月12日,OpenAI发布了o1模型[1]——内部曾代号"Q*"和"Strawberry"——这是一个和之前所有GPT模型都截然不同的产品。
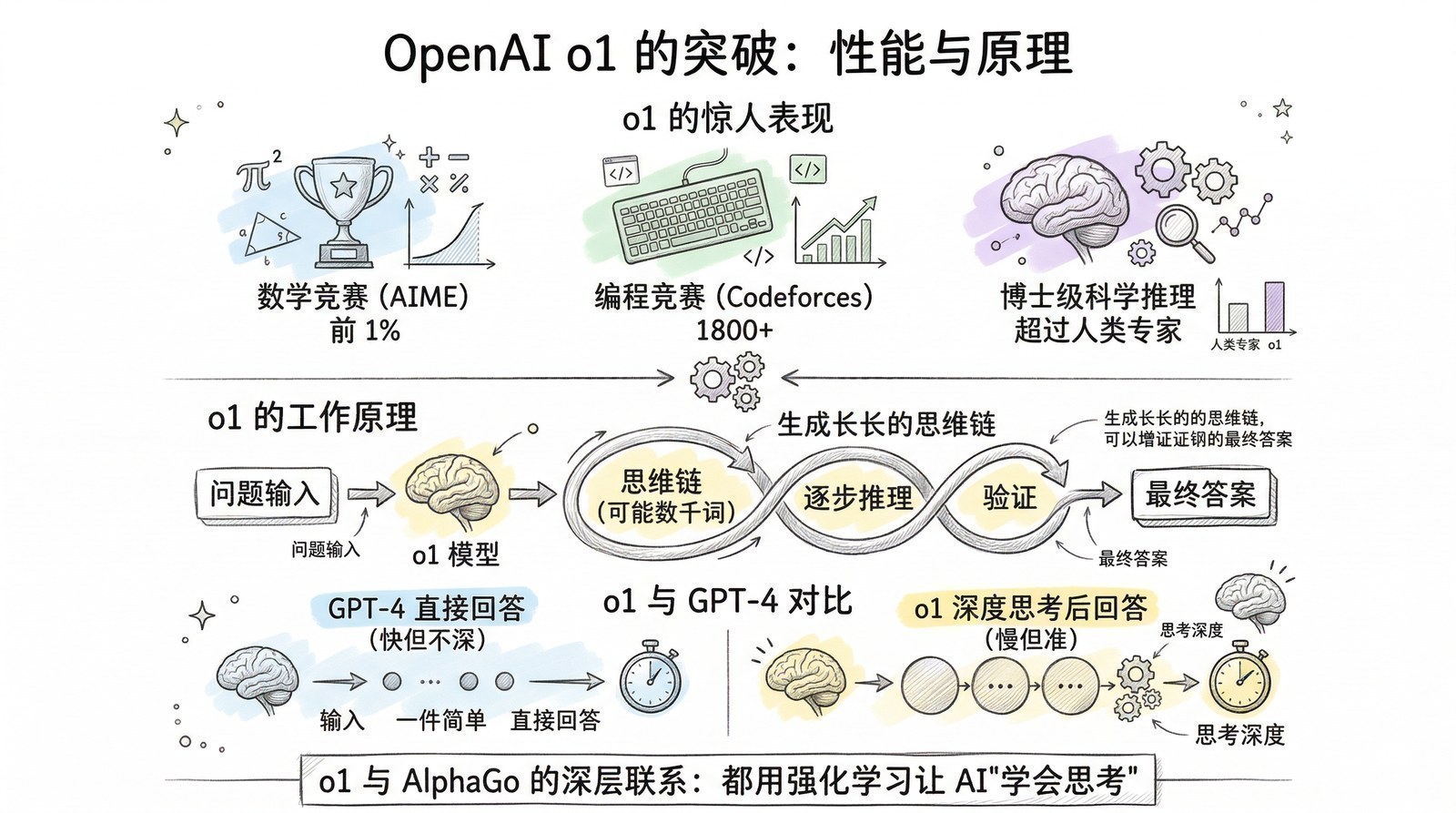
o1的核心创新可以用一句话概括:在回答之前先花时间"想"。
之前的GPT-4在收到问题后会立即开始生成回答——一个token接一个token往外"吐",速度很快但不会"停下来想一想"。o1则不同——它收到问题后会先进行一段很长的内部"思考"(Chain of Thought),这段思考过程用户看不到(OpenAI隐藏了推理token),只有最终答案会被输出。模型可能"想"了几百甚至几千个token之后才给出回答。
这个"想一想再回答"的机制不是靠提示词实现的(第七章的Chain-of-Thought是在提示词中要求"一步步想"),而是通过强化学习训练模型自动进行长时间的内部推理。OpenAI在技术报告中写道:"通过强化学习,o1学会了打磨自己的思维链、优化自己的推理策略。它学会了识别和纠正错误。它学会了把复杂的步骤分解成简单的步骤。它学会了在当前方法不奏效时尝试不同的方法。"
o1的惊人表现
效果是革命性的。在国际数学奥林匹克竞赛(IMO)的预选题上,GPT-4o只能正确解答13%的问题,o1的正确率达到83%。在Codeforces编程竞赛中,o1排名第89百分位——超过了89%的人类参赛者。在GPQA(研究生级别的物理、化学、生物问题基准)上,o1超过了人类博士的平均水平。
这些成绩的意义不在于绝对分数有多高,而在于它们展示了一种全新的Scaling维度:测试时计算(Test-time Compute)。传统的Scaling是在训练时投入更多计算——更大的模型、更多的数据、更长的训练时间。o1开辟了另一个维度——在推理时投入更多计算——让模型"想"更久来得到更好的答案。
OpenAI报告说,o1的性能随两个维度同时Scaling:随训练时的强化学习(train-time compute)增加而提升,也随推理时的"思考时间"(test-time compute)增加而提升。这意味着即使你不改变模型的大小,仅仅让它在每个问题上"想"更久,答案的质量就会持续提升。
OpenAI的Noam Brown——曾开发出在德州扑克中击败人类职业玩家的AI Libratus和Pluribus,是"搜索+博弈"领域的顶级专家——在o1发布当天说了一句引人深思的话:"o1现在思考几秒钟,但我们的目标是让未来版本思考几小时、几天、甚至几周。推理的成本会更高,但你愿意为一种新的癌症药物付出什么代价?为突破性的电池技术?为黎曼假设的证明?AI可以不仅仅是聊天机器人。"
这句话揭示了推理模型的深层愿景:ChatGPT让AI成为了"人人可用的助手"——帮你写邮件、翻译文档、回答日常问题。但o1指向的是一个更大的可能性:AI不只是做人类已经能做的事(只是做得更快更便宜),而是做人类做不到的事——解决目前无人能解的科学难题。当一个AI可以花几天甚至几周时间"思考"一个蛋白质折叠问题或一个数学猜想,它展现的就不再是"效率工具"的价值,而是"智力伙伴"的价值。
o1与AlphaGo的深层联系
o1的技术路线和第四章讲述的AlphaGo有深层的哲学联系。
AlphaGo在下每一步棋之前,会用蒙特卡洛树搜索(MCTS)模拟成千上万种走法,评估每种走法的胜率,然后选最优的一步。AlphaGo Zero更进一步——完全不用人类棋谱,纯靠强化学习的自我对弈来学习下棋。它在"推理时"(下每一步棋之前)花大量时间"搜索",在"训练时"用强化学习让搜索变得越来越高效。
o1做的事情在本质上是一样的:在"推理时"通过长链推理来"搜索"更好的答案,在"训练时"用强化学习让推理变得越来越有效。区别只是AlphaGo的搜索空间是棋盘(离散的、有限的),而o1的搜索空间是自然语言(连续的、无限的)。
从AlphaGo Zero(2017年)到Chain-of-Thought(2022年)到o1(2024年),这条线构成了一个完整的技术叙事:强化学习+搜索/推理=超越单纯的模式匹配。这就是第四章预告的"第二引擎"——如果预训练+Scaling是第一引擎(让模型变得博学),强化学习+推理就是第二引擎(让模型学会思考)。
DeepSeek-R1:"Aha Moment"——推理能力从强化学习中涌现
2025年1月20日,中国公司DeepSeek发布了DeepSeek-R1[2]——一个在多项推理基准上达到OpenAI o1水平的开源推理模型。但R1真正震动行业的,不是它的分数,而是它是怎么训练出来的。
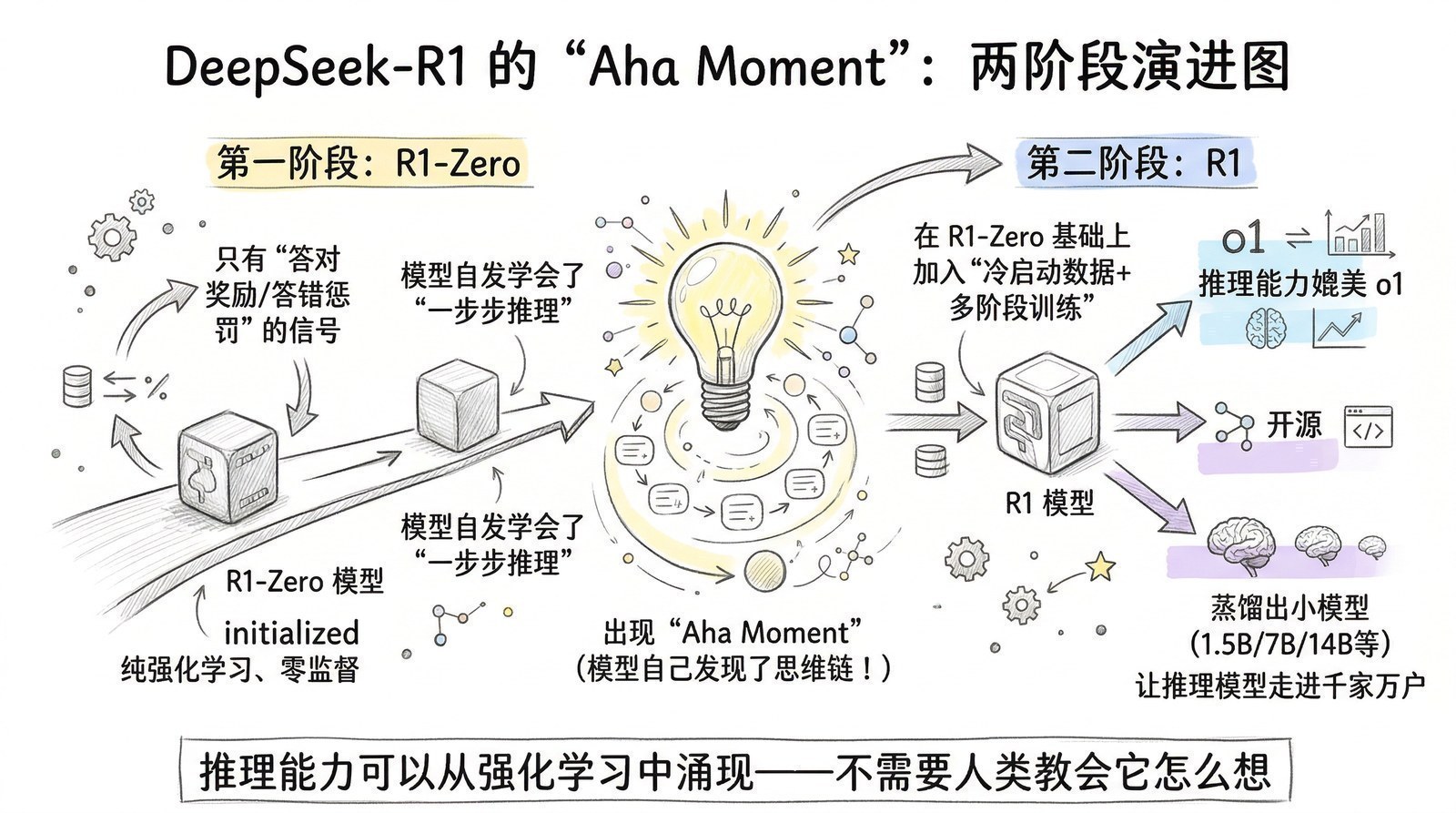
R1-Zero:纯RL,零监督
DeepSeek首先发布了一个叫R1-Zero的模型——直接在基座模型(DeepSeek-V3-Base,6710亿参数的MoE模型,每次推理激活约370亿参数)上做大规模强化学习,不做任何监督微调(SFT)。也就是说:不给模型看任何人类编写的推理样本,不告诉它"好的推理过程长什么样"——只给它问题,让它自己尝试回答,对了就奖励,错了就惩罚。
具体来说:给模型一道数学题(比如"证明根号2是无理数"),模型生成一段推理过程和最终答案。如果答案正确,就给正向奖励;如果答案错误,就给负向奖励。模型不知道"正确的推理过程"应该长什么样——它只知道答对了有奖励。通过数千步这样的强化学习,模型自己摸索出了"好的推理过程长什么样"。
结果令人惊叹。经过数千步训练后,R1-Zero自发涌现出了复杂的推理行为——自我验证(回过头检查自己的推理步骤)、反思(发现错误后回退重新思考)、动态策略切换(一种方法不奏效时自动尝试另一种)。在AIME 2024数学竞赛上,R1-Zero的准确率从训练前的15.6%跳到了71.0%——纯靠强化学习,没有任何人类示范。
DeepSeek的研究者记录了一个被他们称为"Aha Moment"的现象:在训练过程中的某个阶段,模型突然学会了一种全新的推理行为——在给出答案后停下来说"等等,让我重新想想",然后回退到之前的某一步重新推理。这种"自我纠错"能力不是被编程进去的,也不是从人类样本中学到的——它从强化学习的奖励信号中自发涌现。
这正是AlphaGo Zero的哲学在语言推理领域的完美复现——不需要人类棋谱(推理样本),纯靠自我博弈(强化学习),就能涌现出超越人类的策略。
从R1-Zero到R1:冷启动与实用化
R1-Zero虽然展现了惊人的推理能力,但有明显的实用性问题——输出格式混乱、中英文混杂、有时会无限重复同一段推理。为了解决这些问题,DeepSeek开发了完整版的R1。
关键的第一步是"冷启动"——在强化学习之前,先用少量高质量的推理样本做一轮监督微调(SFT)。这些样本是什么样的?比如一道数学题,配上一段结构化的推理过程:先明确已知条件和目标,然后一步一步推导,每步之后做一次检验,最后给出结论。冷启动数据量不大(几千条),但它给模型一个"格式模板"——让模型知道"推理过程应该有结构",而不是一团乱麻。
冷启动之后,再做两轮强化学习(第一轮侧重推理能力,第二轮侧重整体的有用性和安全性)+两轮SFT(用前一轮RL生成的好结果做SFT)。这个四阶段流程让R1既有R1-Zero的推理能力,又有实用产品的输出质量。
R1的蒸馏:让推理模型走进千家万户
R1最终在AIME数学竞赛上达到约79.8%(和o1水平相当),在MATH-500上达到97.3%,在Codeforces编程上Elo评分达到2029。它的论文后来被Nature发表——这对一篇AI系统论文来说是极为罕见的荣誉。
但R1对行业最大的影响不是分数——而是它的蒸馏策略和完全开源。
DeepSeek不仅开源了6710亿参数的完整R1模型权重(MIT许可证),还发布了6个蒸馏版本——从1.5B到70B参数。蒸馏的原理是:让一个小模型("学生")通过学习大模型R1("教师")生成的推理数据来获得推理能力。具体来说,先用R1对大量问题生成高质量的推理过程,然后用这些推理过程作为训练数据来微调小模型。DeepSeek的实验表明:通过蒸馏获得推理能力,效果远好于直接在小模型上做强化学习——7B的蒸馏模型甚至超过了32B的直接RL模型。
这个发现的产业意义是巨大的。它意味着:你不需要自己从零训练一个推理模型(那需要巨大的算力和顶尖的RL工程能力),你只需要用R1的蒸馏数据来微调一个小模型,就能获得相当强的推理能力。这大幅降低了推理模型的门槛——从"只有OpenAI和DeepSeek能做"变成了"有几十块GPU的团队就能做"。
2025年上半年,国内多家大模型厂商迅速跟进——阿里Qwen、智谱GLM等团队都或多或少地借鉴了R1的技术路线。一些团队直接使用R1的蒸馏数据来增强自己模型的推理能力。可以说,R1的开源对中国AI行业的推动作用,类似于LLaMA对全球开源大模型社区的推动作用——它把一项前沿能力从少数巨头的专利变成了行业的公共基础设施。
关于DeepSeek如何以极致效率挑战全球AI格局的完整故事——从幻方量化的算力积累到DeepSeek-V3的工程创新到R1的推理突破——将在第十三章专门展开。
强化学习的回归:从游戏到推理的二十年
o1和R1的成功让强化学习(RL)重新站到了AI舞台的中央。但RL并不是一项新技术——它有着漫长的历史和几次戏剧性的起落。理解这段历史,才能理解为什么RL在2024-2025年突然爆发出如此巨大的价值。
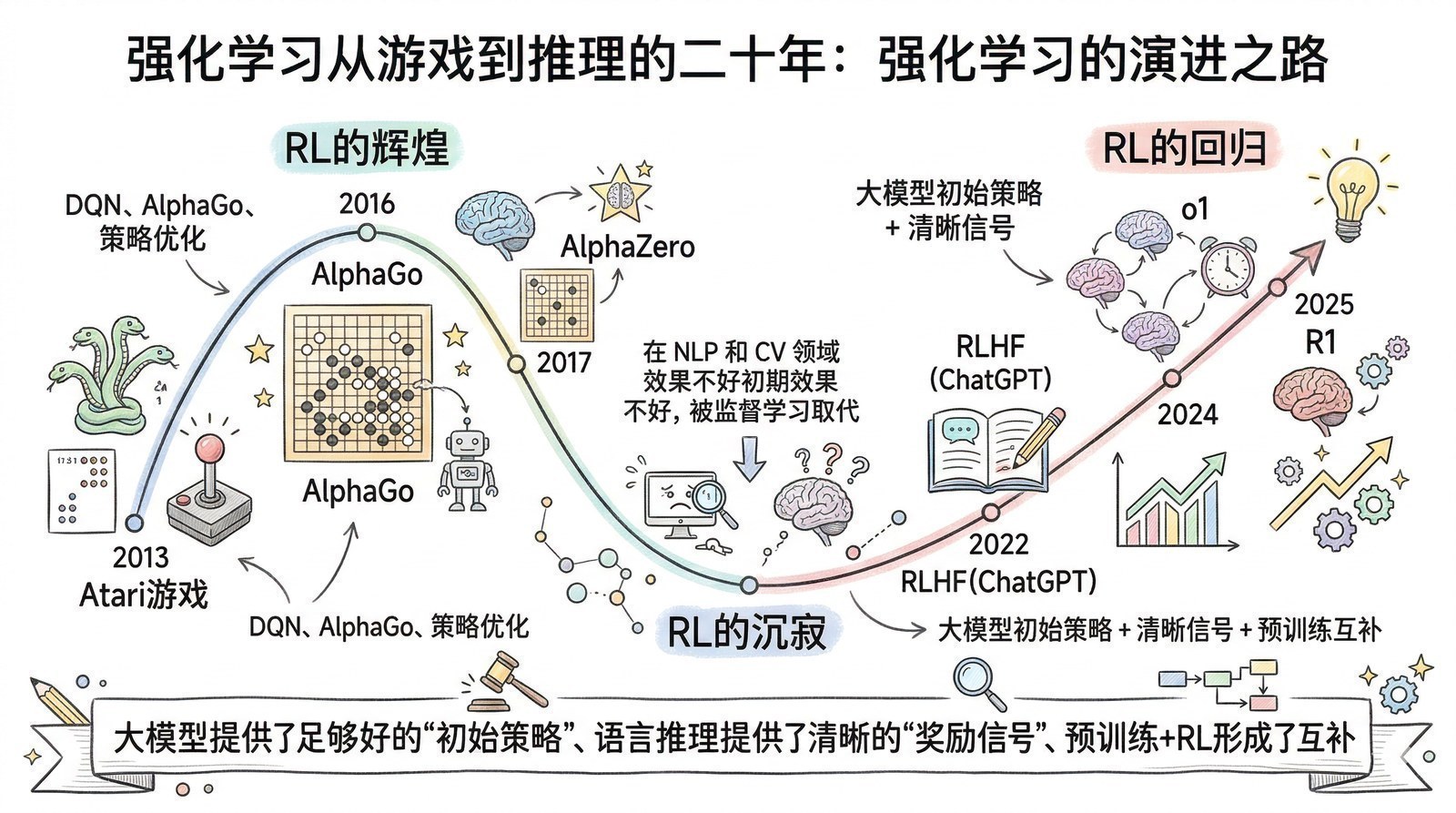
什么是强化学习?
强化学习的核心思想极其简洁:一个"智能体"(Agent)在一个"环境"中采取"行动",环境给出"奖励"或"惩罚"——智能体的目标是学会选择能获得最多累积奖励的行动序列。和监督学习(给正确答案让模型学)不同,强化学习不告诉智能体"正确答案是什么"——只告诉它"你的表现好不好",让它自己去探索和试错。
RL的几次高光时刻
2013-2016年,DeepMind用RL在Atari游戏上取得突破(DQN),然后用RL+搜索在围棋上击败人类世界冠军(AlphaGo,第四章)。这是RL第一次引起公众关注。
2016-2019年,OpenAI也在RL上投入了巨大的资源。2016年4月发布了OpenAI Gym——一个开源的RL实验平台。2016年底启动了OpenAI Five项目——用RL训练AI打Dota 2(一款极其复杂的团队对战游戏)。OpenAI Five使用PPO算法(Proximal Policy Optimization,也是后来RLHF的核心算法),在256块GPU和128000个CPU核上训练,每天自我对弈相当于180年的游戏时间。2019年4月,OpenAI Five在公开表演赛中击败了Dota 2的2018年世界冠军OG战队。
为什么选择游戏?因为游戏有清晰的奖励信号(赢了就是好、输了就是差)、可以无限次重复实验、环境规则明确——这些都是RL高效学习的前提条件。
为什么RL后来"沉寂"了?
2019年之后,RL在大模型领域的角色变得边缘化。原因很简单:GPT系列的预训练+Scaling路线太成功了——只需要收集海量文本数据、训练一个巨大的Transformer、让它预测下一个词——就能获得惊人的能力。这条路线简单、可预测、容易Scaling。相比之下,RL的训练不稳定、超参数难调、奖励设计困难。
在2017-2023年间,RL在大模型中唯一的重要角色是RLHF对齐(第七章)——用人类反馈作为奖励信号来微调模型的回答风格。但那只是RL的一个"辅助"应用——核心的能力提升仍然来自预训练。
OpenAI自己也经历了重心转移。OpenAI Five的成功证明了RL的潜力,但当GPT-2和GPT-3展示了语言模型Scaling的惊人效果后,公司的主要资源从RL游戏研究转向了语言模型预训练。这不是"裁掉了RL",而是战略重心的自然迁移——2019-2023年,预训练Scaling的投入产出比远高于RL研究。
2024年,RL为什么"回归"了?
答案是:RL需要一个足够强大的"基座"才能发挥推理能力。
在2016年,RL能教会AI下围棋——因为围棋的规则简单、状态空间虽大但结构明确。但当时RL没法教会AI做数学推理——因为数学推理需要的不仅仅是"搜索正确步骤",还需要模型本身"理解"数学概念。一个不知道什么是"质数"的模型,再怎么做RL也学不会证明素数无穷。
GPT-4级别的大模型解决了这个前提——它们通过预训练已经"知道"了大量的数学、逻辑、科学和编程知识。它们缺的不是知识,而是"怎么用这些知识来解题"的能力。这恰好是RL最擅长的——通过试错和奖励来学习"策略"。
所以RL的"回归"不是凭空发生的——它需要等到预训练模型足够强大,才能作为"基座"来支撑RL的推理训练。打个比方:RL是"教练",预训练模型是"选手"。一个知识渊博的选手配上一个好教练(RL),才能在比赛中获胜。如果选手本身太弱(2016年的语言模型),再好的教练也没用。2024年,"选手"终于足够强了,"教练"RL才得以大展身手。
两种Scaling的融合:推理模型的未来
o1和R1的出现标志着大模型时代的一个关键转折——从"单一Scaling"到"双重Scaling"。
第一重Scaling是训练时计算(让模型更博学)——这是前九章的主线,更大的模型+更多数据+更长训练,边际收益在递减但仍然有效。
第二重Scaling是测试时计算(让模型更会想)——这是本章的新发现,让模型在每个问题上花更多时间"思考",答案质量就持续提升。
两种Scaling不是替代关系而是互补关系。博学(预训练)提供了推理的"原材料"——你需要先知道物理定律才能推理物理问题。善于思考(强化学习+测试时计算)提供了使用原材料的能力——光知道定律不够,你还得会推导。未来的前沿模型很可能同时在两个维度上Scaling,而强化学习是连接两者的桥梁。
这场范式转移意味着什么
从"快思考"到"慢思考":考场上的两种考生
要理解这场范式转移,可以想象一个考场上的两种考生。第一种考生读完题目后立刻动笔——他反应快、写得多,但遇到难题经常犯粗心错误,因为他没有停下来想一想。这就是GPT-4——它快速给出回答,依赖训练数据中积累的"直觉",简单问题答得又快又好,但复杂推理题经常出错。
第二种考生读完题目后不急着动笔——他先在草稿纸上列出已知条件,画图分析,尝试一种解法走不通就换另一种,检查中间步骤有没有错误,最后才写出答案。他做题慢得多,但复杂题的准确率远高于第一种考生。这就是o1和R1——它们在回答之前先花大量时间"思考",用推理链一步一步推导,遇到错误会回退重试。
心理学家Daniel Kahneman在《思考,快与慢》中把这两种思维模式称为System 1(快速直觉)和System 2(慢速审慎)。AI正在从只有System 1进化到同时拥有System 1和System 2——简单问题用"快思考"秒级回答,复杂问题切换到"慢思考"花更长时间推理。
对产业的影响
推理模型对产业的影响是深远的。在数学和科学研究中,o1级别的推理能力已经可以解决研究生水平的问题——未来可能辅助甚至独立完成某些科学发现。在金融、法律、医疗等需要复杂分析的领域,推理模型的价值将逐步显现。
在编程领域,推理能力和强化学习的结合正在产生最直接、最具商业价值的落地成果。第九章介绍过的Anthropic就是一个典型案例——这家从OpenAI脱胎出来的、以AI安全为立身之本的公司,却做出了业界公认的最强代码模型之一。Claude 3.5 Sonnet和Claude 4 Opus在SWE-bench(软件工程基准,测试模型能否独立修复真实开源项目中的bug)上持续刷新记录。Anthropic推出的Claude Code让AI可以直接在终端中操作整个代码库——阅读代码、理解架构、编写新功能、运行测试、修复bug——这已经不是"代码补全",而是一个完整的代码智能体(第七章)。
Anthropic在代码领域的成功不是偶然的。编程是推理模型最天然的落地场景——代码有明确的对错标准(跑通就是对的,报错就是错的),这为强化学习提供了完美的奖励信号。你可以让模型写代码→运行测试→通过了就奖励、没通过就惩罚→迭代改进——这个"写-跑-改"的循环就是强化学习在代码领域的完美实例化。Anthropic在安全研究中积累的对模型内部推理机制的深入理解(可解释性研究),反过来帮助他们训练出了更强的推理和代码能力——安全研究和能力研究在这里形成了正向循环。
但推理模型也带来了新的成本结构。o1在每个问题上花费的"思考时间"意味着推理成本比GPT-4高得多——一个复杂问题可能需要几千个推理token,成本是普通回答的几十倍。这意味着推理模型不是GPT-4的替代品,而是面向复杂高价值任务的专用工具。"简单问题用GPT-4o,复杂问题用o1/Claude"成为了新的使用范式。
让AI学会"看见"(第一章)→ 学会"说话"(第四-五章)→ 学会"对话"(第七章)→ 学会"创造"(第八章)→ 学会"思考"(本章)。大模型用十年走完了从感知到理解到创造到推理的进化之路。
但这条路远没有结束。当推理能力和多模态能力开始融合,当AI从"回答问题"进化到"自主完成任务",当大模型开始渗透到科学研究、药物发现、机器人控制……一个更大的故事正在展开。
本章引用论文
[1] OpenAI o1 System Card, 2024, OpenAI
[2] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, 2025, DeepSeek-AI (Liang et al.)
[3] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, 2022, Google (Wei et al.) — 交叉引用第七章
[4] Mastering the Game of Go without Human Knowledge (AlphaGo Zero), 2017, DeepMind (Silver et al.) — 交叉引用第四章
[5] Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters, 2024, Google DeepMind / UC Berkeley (Snell et al.)
第十一章:当AI学会"看、听、说、想、做"——原生多模态与智能体的大融合
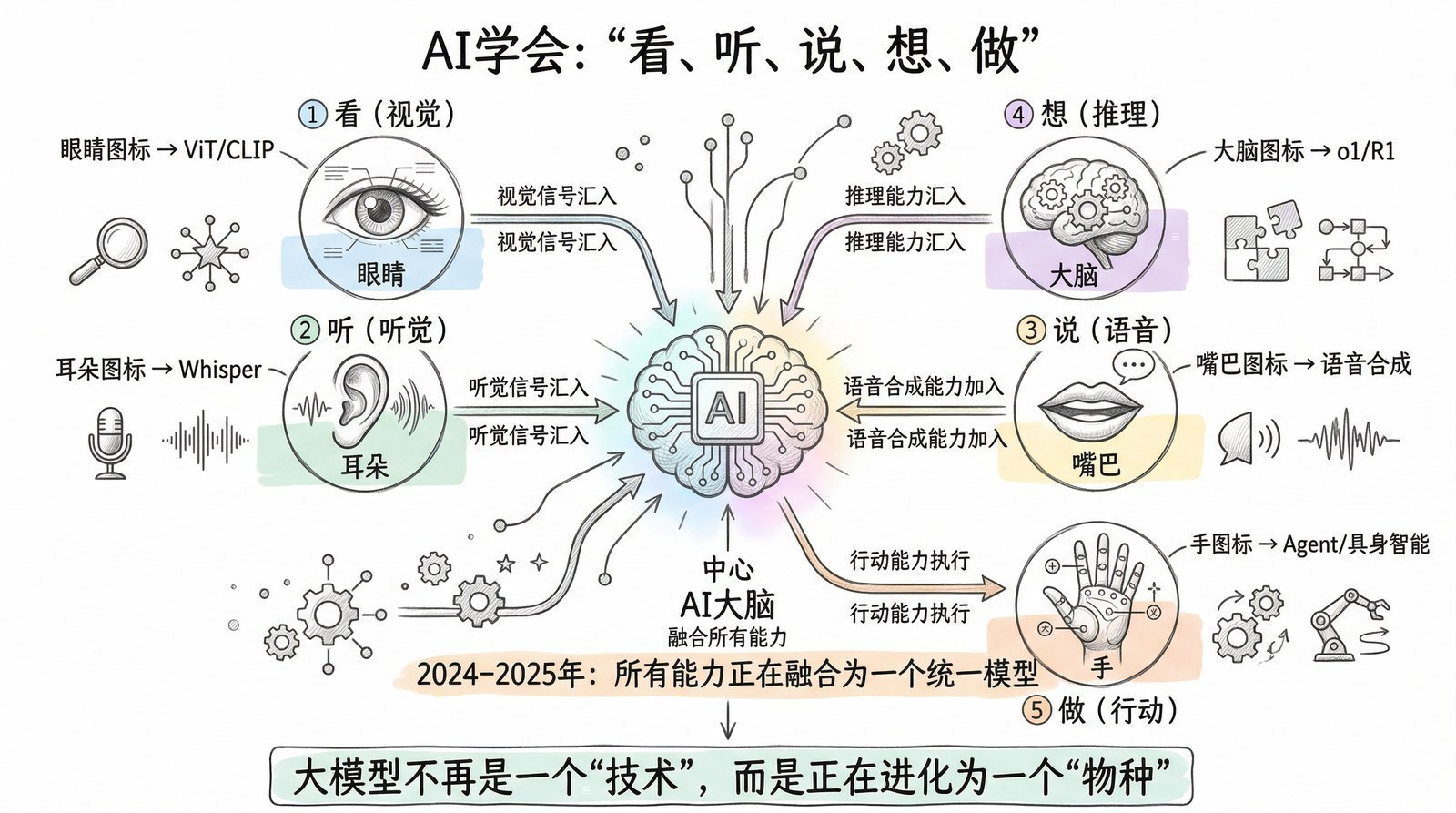
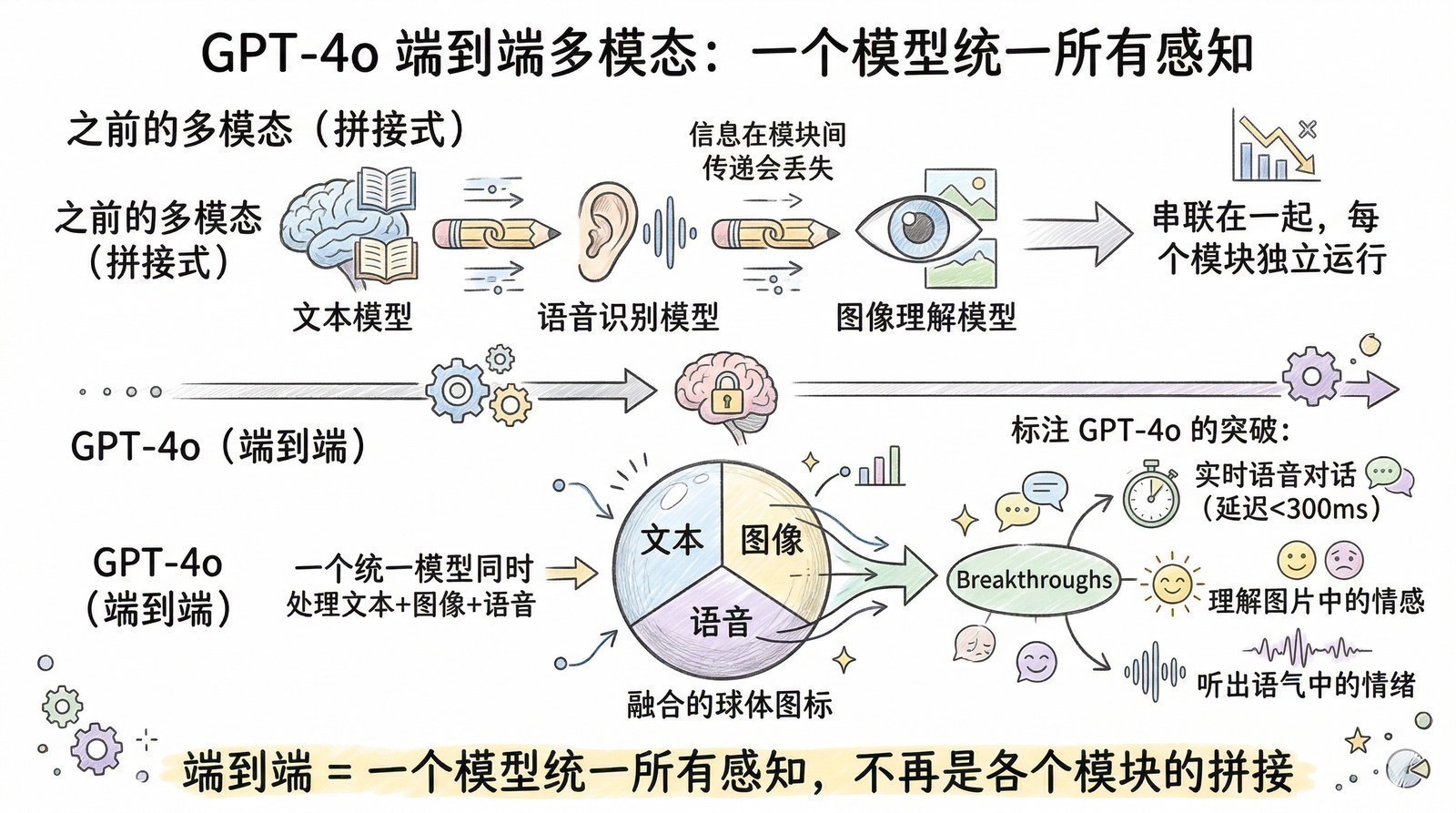
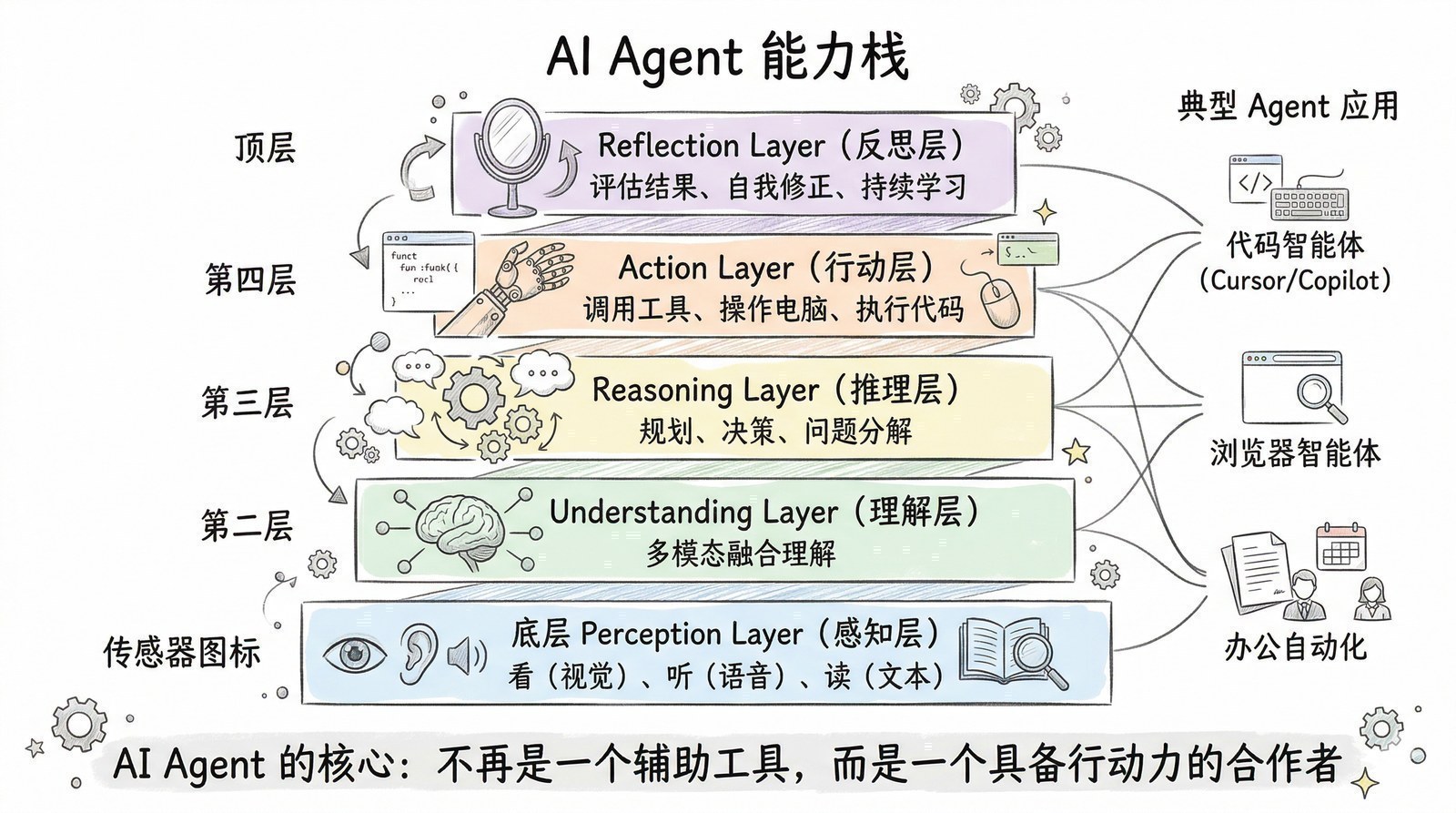
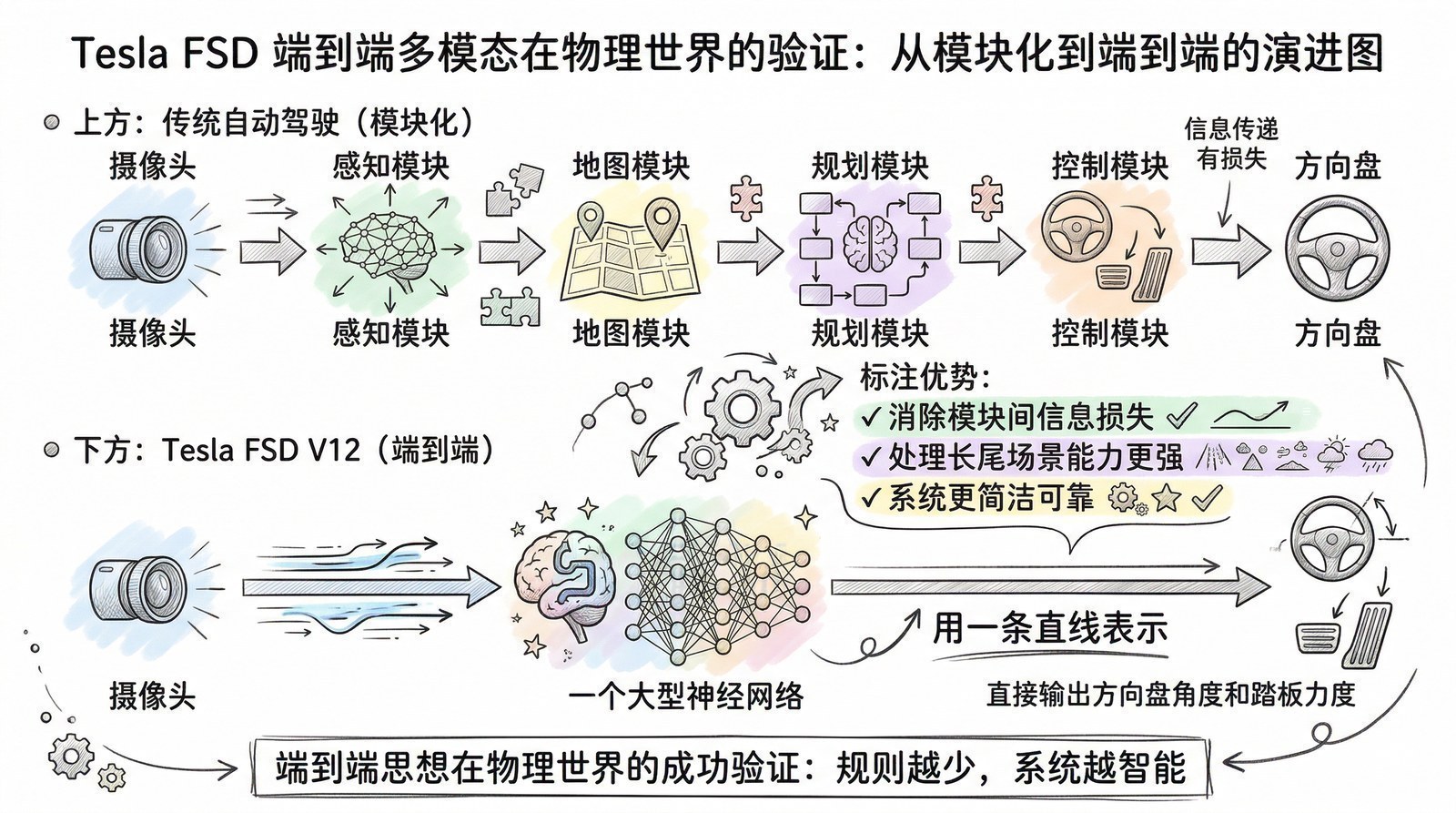
从感知到理解到创造到推理,前十章每一步都在给AI添加一种新能力。但这些能力一直是"分装"的——理解文本用一个模型,理解图片用另一个,生成语音再用一个,推理用又一个。真正的智能不是这样的:人类同时看、听、说、想,并且基于所有信息做出行动。2024-2025年,AI正在走向"大融合"——GPT-4o把文本、图像、语音融为一体,Agent将感知和思考转化为行动和反馈,AI逐步从数字世界走向物理世界。大模型不再是一个"技术",而是正在进化为一个"物种"。
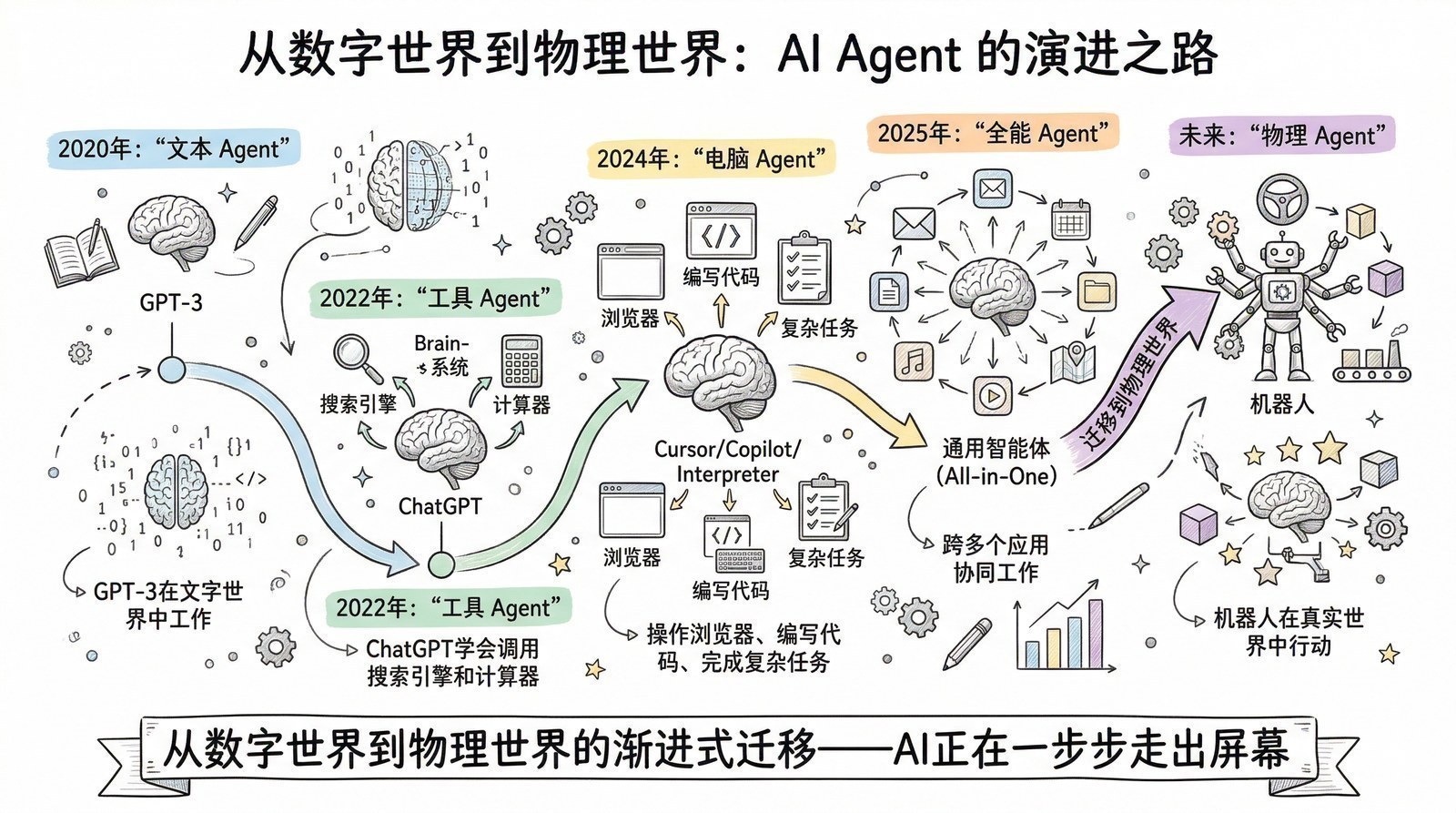
GPT-4o:当AI第一次"同时看、听、说"
2024年5月13日,OpenAI发布了GPT-4o[1]——"o"代表"omni"(全能)。这不是一个简单的版本升级,而是一次架构层面的根本性变革。
在GPT-4o之前,ChatGPT的语音交互需要三个独立的模型串联工作:一个语音识别模型把你说的话转成文字,GPT-4处理文字并生成回复文字,一个语音合成模型再把回复文字变成语音。三个模型像流水线一样依次工作——延迟高(通常几秒才能回复)、信息损失大(语音识别阶段就丢失了说话者的语气、情绪、停顿等信息)、体验不自然。
GPT-4o做了一件从根本上不同的事:用一个模型端到端处理所有模态。它接收文本、图像、音频、视频的任意组合作为输入,直接输出文本、图像或音频——中间不需要"翻译"步骤。语音输入不再被先转成文字再处理,而是直接被模型理解——包括语气、语速、情绪和背景声音。
效果是质变的。GPT-4o对语音输入的平均响应时间只有320毫秒——和人类在对话中的反应速度相当。你可以打断它正在说的话,它会自然地停下来听你说完再继续——就像和一个真人对话。
什么是"多模态"?什么是"端到端多模态"?
这两个概念贯穿了本章所有的技术讨论,值得做一次清晰的解释。
多模态(Multimodal)是指同时处理和理解多种类型的数据——文本、图像、音频、视频。之前的AI模型大多是"单模态"的:GPT-4处理文本,ViT处理图像,Whisper处理语音。当你需要一个系统同时处理图片和文字时,传统方案是"拼接"——用一个模型处理图片提取特征,用另一个模型处理文字,然后把两者的结果拼在一起交给第三个模型做融合。这种"拼接式多模态"能用,但每一次模块间的"翻译"都会丢失信息——语音被转成文字后语气和情绪就没了,图片被描述成文字后空间关系和视觉细节就丢了。
端到端多模态(End-to-End Multimodal)则是:从原始的多种输入直接到最终输出,中间不需要人工设计的模块拆分和"翻译"步骤。GPT-4o就是这样——从训练阶段就同时学习文本、图像和音频的联合表示。它不需要把图片"翻译"成文字才能理解,也不需要把语音"转录"成文字才能处理。就像人类看到一张照片时,不需要在脑子里先"用语言描述这张照片"才能理解它——你直接就"看懂了"。
端到端的优势是消除了模块间的信息损失和误差累积——所有信息都流经同一个网络,没有信息瓶颈。为什么之前没有做端到端?因为端到端需要模型自己从数据中学会"怎么拆分和处理任务",这比人工设计模块需要更大的模型和更多的数据。在Scaling Law充分验证、基座模型足够强大之后,端到端才变得可行且效果更好。
Tesla FSD:端到端多模态在物理世界的验证
GPT-4o在数字世界中验证了端到端多模态的威力。几乎在同一时期,Tesla的FSD(Full Self-Driving)在物理世界中做了一件极其相似的事——用端到端神经网络替代了传统的模块化自动驾驶方案。
在FSD v11及更早版本中,Tesla的自动驾驶系统由三个独立模块组成:感知模块(用计算机视觉检测车辆、行人、车道线)、规划模块(根据检测结果计算行驶路径)、控制模块(把路径转化为转向和刹车指令)。这三个模块由约30万行C++代码手工编写——每一个交通规则、每一种路口场景都需要工程师写专门的代码处理。
2024年初,Tesla发布了FSD v12——用一个端到端的神经网络替代了那30万行代码。8个摄像头的视频输入直接送入神经网络,网络直接输出转向、加速和制动指令——中间没有手写的规则,没有模块化的拆分。Tesla的工程师Dhaval Shroff这样描述这个转变:"我们不再用规则来决定车的正确路径,而是用神经网络从数百万人类驾驶样本中学习正确路径。"Musk说:"FSD v12就像汽车版的ChatGPT——从编程驱动变为数据驱动。"
Tesla做端到端自动驾驶有三个其他公司难以复制的优势。第一是数据规模:全球超过400万辆Tesla车辆组成了庞大的数据采集网络,每辆车都是行驶中的数据采集器——驾驶员接管自动驾驶时那一刻的视频会自动上传,成为改进模型的训练数据。FSD v12用超过1000万段真实驾驶视频训练。第二是数据闭环:"部署→收集数据→改进模型→重新部署"的闭环让系统可以持续快速进步——v12.5版本关键接管间距比v11提升了100倍。第三是纯视觉方案:不依赖昂贵的激光雷达,成本低,可大规模部署。
FSD的故事完美地说明了端到端多模态为什么比传统模块化方案强:在城市道路的复杂场景中(无标线路口、施工区域、不规范的行人行为),端到端模型从海量真实数据中学到了人类的"直觉判断",而这些判断几乎不可能用规则代码来穷举。
端到端驱动的多模态对产业的影响
端到端多模态正在重塑多个产业。在内容创作领域,字节跳动的即梦(Seedance)等多模态生成工具已经被用来制作短视频、网剧片段和广告素材——输入文字描述、参考图片和风格指令,输出完整的视频内容。在医疗领域,多模态大模型可以联合分析CT影像、病历记录和检验报告,给出比单一模态分析更准确的诊断建议。在教育领域,GPT-4o的原生多模态让AI家教成为可能——它看到学生手写的作业照片、听到学生的口头提问、用语音解释解题过程并在图片上标注关键步骤。在实时翻译领域,多模态模型可以同时分析说话者的口型和语音信号,实现比纯语音翻译更准确的跨语言翻译。
AI Agent的产业爆发:从"回答者"到"执行者"
第七章介绍了ReAct论文如何定义了"推理+行动"的Agent范式,以及AutoGPT、Manus等早期Agent产品。2024-2025年,AI Agent从实验和演示走向了大规模的产业落地。
什么在推动Agent的爆发?
三股力量的汇合让Agent在2024-2025年迎来了爆发。
第一股力量是基座模型能力的持续跃升。GPT-4o的原生多模态让Agent可以"看见"屏幕上的内容、"听到"用户的语音指令、"读懂"文档和表格。第十章的推理模型让Agent可以对复杂任务做多步规划——不是机械执行固定流程,而是根据中间结果灵活调整策略。
第二股力量是工具生态的成熟。Anthropic提出的MCP(Model Context Protocol)等标准协议让大模型可以无缝调用外部工具——搜索引擎、日历、邮箱、代码执行器、数据库——而不需要为每个工具写专门的集成代码。这就像USB接口标准化之后任何设备都可以即插即用。更进一步,Anthropic在Claude中引入了"Skill"机制——用自然语言编写的"技能卡"来定义Agent的行为模式。传统方式需要写代码来定义工具调用逻辑,Skill让用户用自然语言描述工作流程,AI自己把这段描述"编译"成可执行的工作流——进一步降低了Agent和工具之间协作的门槛。
第三股力量是用户需求的拉动。ChatGPT证明了"对话AI"的巨大市场,但用户很快发现对话只是起点——他们真正想要的不是"AI告诉我怎么做",而是"AI帮我做"。
代码智能体:Agent最成功的落地场景
第七章已经深入讨论了代码智能体为什么是Agent最先成功的领域——数据量大、结果可验证、逻辑性强。到2025年,代码智能体的能力已经从"补全几行代码"进化到了"理解整个代码库并自主完成复杂开发任务"。
Anthropic的Claude Code、Cursor的AI编辑器、GitHub Copilot的Workspace模式代表了代码智能体的不同形态——但核心逻辑都是"推理-行动-观察"的ReAct循环:理解任务→阅读代码→制定方案→写代码→运行测试→看结果→修复问题→再测试。代码智能体的成功验证了一个重要假说:当环境有明确的反馈信号时,Agent就可以通过"试错+强化学习"持续改进。
OpenClaw:当通用Agent走向大众
如果说代码智能体是"专用Agent"的标杆,那么2026年初爆火的OpenClaw则代表了"通用Agent"走向大众的关键一步。
OpenClaw(原名Clawdbot,后因Anthropic商标投诉更名为Moltbot,最终定名OpenClaw)由奥地利开发者Peter Steinberger于2025年11月发布。Steinberger此前创办的PSPDFKit被安装在超过10亿台设备上。OpenClaw是一个运行在你自己电脑上的AI智能体,通过WhatsApp、Telegram、Slack等消息应用来和你交互——你发一条消息,它就帮你做事:执行Shell命令、操作浏览器、读写文件、发送邮件、管理日历。
OpenClaw为什么突然爆火?它的技术亮点在于三个设计选择。第一是"本地运行+消息应用交互"——你不需要打开一个新的App或网站,而是直接在你每天已经在用的WhatsApp或Telegram里和它对话,它就在你自己的电脑上运行——数据不上传到云端,隐私有保障。第二是"Skill系统"——OpenClaw把Agent的能力模块化为一个个"技能",每个技能是一个包含SKILL.md文件的目录,用自然语言描述这个技能做什么、怎么做。社区可以像分享代码库一样分享和组合技能——这让Agent的能力可以像乐高积木一样快速拼装。第三是"心跳机制"——Agent可以设置定时任务,主动检查你的系统状态、监控邮件、处理日常事务——不需要你下指令它就会主动做事。
2026年1月25日公开发布后,72小时内GitHub star数突破6万,到3月初超过24.7万——超越React成为GitHub历史上star最多的项目。Nvidia CEO黄仁勋称其为"可能有史以来最重要的软件发布"。硅谷和中国的开发者同时涌入——阿里、腾讯、字节迅速推出基于OpenClaw的集成服务。2026年2月14日,Steinberger宣布加入OpenAI,OpenClaw项目移交给开源基金会。
但OpenClaw对行业最大的贡献,可能不在技术本身——而在于它给全球用户做了一次关于"AI智能体"的大规模科普和教育。在OpenClaw之前,"AI Agent"对绝大多数普通用户来说只是一个抽象的技术概念——他们知道ChatGPT可以聊天,但不知道AI可以帮你买车、帮你写申诉信、帮你清理磁盘、帮你监控服务器。OpenClaw让几百万用户第一次亲手体验了智能体的能力——发一条消息就能让AI替你完成一个真实的任务。这种"Aha Moment"(和DeepSeek-R1的"Aha Moment"异曲同工)让全球用户第一次真正理解了大模型不只是"聊天机器人",而是可以"做事"的智能体。从这个意义上说,OpenClaw对Agent赛道的推动作用——降低认知门槛、培育用户心智、激发开发者社区——远比它的技术和产品本身大得多。
当然,OpenClaw也暴露了通用Agent的巨大风险:安全研究人员发现超过4万个暴露在公网上的实例,2月披露了一个零点击漏洞(CVE-2026-25253)——任何网站都可以静默劫持本地运行的Agent。中国政府在3月限制国企和政府机关使用OpenClaw。OpenClaw的一位核心维护者警告:"如果你连命令行都不会用,这个项目对你来说太危险了。"
从代码智能体到OpenClaw,Agent的产业脉络已经清晰:当AI可以代替你发邮件、买东西、操作银行账户时,一个错误操作或安全漏洞的后果比"AI说错话"严重几个数量级。通用Agent的成熟还需要在安全性、可靠性和用户控制方面做大量工作。
具身智能:更多是一个AI问题
AI在数字世界中已经展现了从对话到行动的能力(Agent)。但人类生活在物理世界中——AI要真正融入人类生活,最终必须进入物理世界。这就是具身智能(Embodied Intelligence)的使命。
具身智能的本质是什么?
很多人听到"具身智能"会想到能走能跳能翻跟头的机器人——比如波士顿动力的Atlas做后空翻的视频。但这些炫酷的动作主要是机械工程和控制理论的成就——它们不需要"智能",只需要精确的电机控制和平衡算法。
真正的具身智能指的是完全不同的东西:让机器人具备感知、规划、策略和控制四种能力的融合。感知是"看懂"周围环境(这个房间有什么物体、布局如何、哪些物体可以交互)。规划是"想清楚"要做什么(要完成"整理房间"这个任务,需要先叠衣服、再收拾桌面、然后拖地)。策略是"决定"怎么做(先拿起地上的衣服→走到衣柜旁→打开柜门→叠好放入)。控制是"执行"具体动作(机械臂的轨迹规划和力度控制)。
在这四种能力中,前三者——感知、规划、策略——恰好是大模型最擅长的。多模态大模型可以"看懂"场景(第八章的ViT和CLIP,第九章GPT-4的视觉理解),推理模型可以做多步规划(第十章的o1和R1),Agent框架可以把规划转化为一步步的行动(本章的ReAct)。只有第四个——精细的运动控制——仍然主要依赖传统的机器人学方法。
这也是为什么具身智能的推动者主要是搞计算机视觉和AI的人,而不是搞自动化和机器人的人。传统机器人学已经解决了"让机器人动起来"的问题——工业机械臂可以以毫米级精度焊接汽车,波士顿动力的机器人可以在崎岖地形上奔跑。但这些机器人都在"预设好的任务"中工作——它们不"理解"环境,不"规划"任务,不"适应"新场景。具身智能要解决的恰恰是这些"智能"层面的问题——而这些问题的答案在AI领域,不在机器人学领域。
到2025年,硬件已经就绪——能翻跟头打武术的人形机器人已经存在。下一步的发展重点就是解决模型问题:让这些机器人不仅"能动",还"会想"。
但要做具身智能的"大脑"模型,数据是关键。
困在训练数据里的物理AI
GPT-4之所以强大,是因为它在几十万亿token的互联网文本上训练——人类几千年积累的文字知识几乎都可以被"爬取"。但机器人需要的是物理世界中的操作数据——"怎么抓住一个杯子""怎么在不平的地面上行走""怎么避开突然出现的障碍物"——这些数据不存在于互联网上,必须在真实物理环境中一次一次地收集。
这形成了一个恶性循环:没有足够的数据→训练不出好的模型→做不出好的产品→没有大规模部署→无法收集更多数据。大模型用互联网数据打破了这个循环(互联网上有近乎无限的文本),但具身智能还没有找到自己的"互联网时刻"。
自动驾驶是具身智能最先突破的场景——恰恰因为它最好地解决了数据问题。道路场景相对结构化(有车道线、交通灯、交通规则),比家庭环境或工厂车间简单得多。而Tesla用400万辆车组成的车队实现了数据闭环——这是目前唯一一个成功运转的"大规模部署→自动收集数据→改进模型→重新部署"的闭环系统。
但对于更广泛的具身智能——家庭服务机器人、仓储物流机器人、手术机器人——数据困境仍然严峻。要打破这个困境,需要一种全新的方法。
用AI来"创世纪":世界模型的诞生
为了解决具身智能的数据困境,一个大胆的想法正在成形:如果不能在真实物理世界中大量收集数据,那就用AI创建一个三维物理世界——在虚拟世界中生成无限的训练数据。这就是"世界模型"(World Model)的核心理念。
世界模型要解决什么问题?
GPT-4o和Seedance这样的多模态模型已经可以生成逼真的图片和视频。但它们生成的是"二维平面内容"——本质上是像素的序列。你看到一段AI生成的城市街景视频,画面很逼真,但你不能"走进"这个画面——不能转身看背后有什么,不能走到旁边那条街去看看,不能把画面中的杯子拿起来。
世界模型要生成的是完全不同的东西:一个三维的、可交互的、遵守物理规律的虚拟世界。你可以在这个世界中自由移动和探索,物体有重量和摩擦力,光影随视角变化而变化,你推倒一个杯子它会翻滚、液体会洒出来。
区别可以用一个直观的对比来理解:Seedance生成的视频就像一段录好的电影——你只能从导演选定的视角观看,不能改变镜头位置,画面中的物体不会响应你的操作。世界模型生成的场景则像一个电子游戏的关卡——你可以在里面自由行走、拾取物体、改变环境,场景会根据你的行动实时响应。
这种区别对具身智能的意义是决定性的。机器人需要在三维空间中导航和操作——它需要知道桌子在左边还是右边、杯子在桌子上还是桌子下、走过去的路上有没有障碍物。二维视频无法提供这些信息,但三维世界模型可以。如果你能用AI生成无限多的逼真三维场景,就可以在这些场景中训练机器人——"在虚拟厨房中练习做饭""在虚拟仓库中练习搬运货物""在虚拟街道上练习避开行人"——然后把学到的能力迁移到真实世界。
World Labs:李飞飞的"空间智能"
推动世界模型的领军人物是李飞飞——ImageNet的创造者(第一章),被称为"AI教母"的计算机视觉先驱。2024年9月,李飞飞从斯坦福请假,创办了World Labs,首轮融资2.3亿美元,估值10亿美元。2026年2月,World Labs完成了10亿美元的新一轮融资,投资者包括Nvidia、AMD、Autodesk(全球最大的3D设计软件公司)等,估值约50亿美元。
李飞飞的核心理念是"空间智能"(Spatial Intelligence)——她认为这是和"语言智能"同等重要的AI能力。她说:"如果AI要真正有用,它必须理解'世界',而不仅仅是'文字'。世界由几何、物理和动力学所支配。"
World Labs的第一个商业产品Marble于2025年11月发布——它可以从文字描述、图片或视频生成可导航的、持久的三维世界。和Seedance等视频生成工具的关键区别是:Marble生成的世界是"持久的"——你可以保存、再次进入、继续编辑。它可以导出为标准的3D格式(网格、高斯泼溅、视频),直接用于游戏开发、影视特效和建筑设计的工作流。
World Labs还推出了Chisel——一个混合3D编辑器,让用户先粗略勾画空间布局("这里放一张桌子,那里放一个书架"),然后AI填充视觉细节和物理属性。这种"结构与风格分离"的设计让创作者保持对空间的控制权,同时利用AI来处理繁重的视觉生成工作。
为什么是现在?
世界模型在这个时间点出现不是偶然。几条技术线的成熟为它创造了条件。
第一,互联网上存在海量的真实拍摄视频——人类日常上传的驾驶记录、旅行视频、运动录像、家庭影片——这些视频都遵循物理世界的规律(物体有重力、光线有反射、液体会流动)。虽然这些视频是二维的,但它们蕴含了三维物理世界的运行规律。Sora的"世界模拟器"已经从视频数据中"学到"了一些物理直觉——比如物体运动的连贯性和光影变化的规律。世界模型可以在此基础上更进一步,从海量视频中学习三维空间的几何结构和物理规律,然后把这些知识用于生成可交互的三维世界。
第二,Sora和DiT(第八章)证明了Transformer可以理解视频中的时空关系——这是从二维走向三维的基础。Sora的"世界模拟器"理念和World Labs的"空间智能"在哲学上异曲同工——都试图让AI理解物理世界的规律。
第三,NeRF(Neural Radiance Fields,神经辐射场,2020年)[7]和3D Gaussian Splatting(三维高斯泼溅,2023年)[8]等三维重建技术在2020-2024年间快速成熟——从少量照片就可以重建出可自由视角浏览的三维场景。这些技术为世界模型的"输出格式"提供了基础——World Labs的Marble就可以导出为Gaussian Splatting格式。
第三,也是最根本的——具身智能的数据瓶颈到了不解决不行的地步。当硬件已经就绪、AI模型已经具备了感知和规划能力时,唯一缺少的就是"在哪里训练"。世界模型提供了答案:在AI创建的虚拟世界中训练。
世界模型面临的挑战也很明显。处理三维数据需要的算力比文本和二维图像大几个数量级。高质量的三维训练数据(不同于互联网上海量的文本和图片)仍然稀缺。生成的三维世界在物理精度上还远未达到工业仿真的水平。但方向已经清晰——从ImageNet到CLIP到Sora,李飞飞和AI社区一次又一次地证明:当你给AI提供了足够的数据和正确的训练范式,它总能给你超出预期的结果。
从数字世界到物理世界:Agent发展的完整脉络
回看本章讲述的几条线,一个清晰的演进脉络已经形成。
从专用到通用:代码智能体(Claude Code、Cursor)是Agent在单一垂直领域的成功验证→OpenClaw把Agent能力扩展到了通用的数字任务→具身智能要把Agent能力从数字世界带入物理世界。每一步都在扩大Agent的"行动空间"——从代码编辑器到电脑桌面到物理环境。
从数字到物理:GPT-4o让AI具备了多模态感知→FSD v12把端到端多模态带入了自动驾驶→世界模型为更广泛的物理AI提供训练环境→具身智能的最终目标是让AI在真实物理世界中自主行动。
通用智能体和具身智能的深入讨论已经远超本章篇幅。我们将在后续章节单独展开这两个领域的完整故事。
大融合的底层逻辑:为什么一切都在2024年加速
回顾前十章的技术演进,2024年的"大融合"不是偶然的——它是多条独立发展的技术线在同一时间点汇合的结果。
第一条线是Transformer的统一(第四章→第八章):从文本到图像到视频,Transformer证明了自己可以处理任何模态的数据。GPT-4o把这个统一推到了极致——一个模型端到端处理所有模态。
第二条线是Scaling Law的持续验证(第六章→第九章):更大的模型+更多的数据=更强的能力。当基座模型足够强时,多模态融合、推理、Agent等能力自然涌现。
第三条线是以强化学习为代表的后训练技术的回归(第四章→第七章→第十章):从AlphaGo的强化学习,到RLHF对齐让模型"听话",到工具调用让模型"行动",到o1/R1用RL让模型"思考"——后训练技术的每一次进化都在扩展大模型能做的事情。强化学习从"辅助角色"升级为"核心引擎",蒸馏技术让强大能力可以传递给小模型——这些都降低了Agent和多模态应用的部署门槛。
三条线在2024年汇合——Transformer提供了统一的架构,Scaling提供了足够的基座能力,以RL为核心的后训练提供了推理、行动和对齐能力——AI从一个"对话工具"开始进化为一个"通用智能体"。
这场大融合意味着什么
从"工具"到"伙伴":AI角色的根本转变
前十章中的AI本质上是一个"工具"——你提问它回答,你下令它执行。但当AI同时拥有了看、听、说、想、做的能力后,它开始从"工具"向"伙伴"转变。OpenClaw的"心跳"功能就是一个例子——它定期主动检查你的系统状态,发现磁盘空间不足时主动清理并通知你,不需要你下指令。
"AI原生"应用的诞生
在大融合之前,AI是"嵌入"到现有产品中的一个功能——搜索引擎加上AI回答,Office加上AI助手。大融合之后,一种全新的"AI原生"产品形态正在出现——Cursor不是"一个编辑器加上AI",而是"AI就是编辑器";OpenClaw不是"一个工具集合加上AI",而是"AI就是你的数字管家"。
挑战与风险
大融合也带来了前所未有的挑战。当AI可以自主"行动"时——执行代码、发送邮件、操作浏览器、替你买东西——一个错误决策或安全漏洞的后果比"说错话"严重得多。AI安全从"防止输出有害内容"(第七章的RLHF对齐)升级为"防止有害行动"——行动的后果发生在真实世界中且可能不可逆。OpenClaw的零点击漏洞和中国政府的限制令是这种风险的早期预警。Anthropic(第九章)对安全的执念在Agent时代显得尤其有先见之明。
让AI学会"看见"(第一章)→ 学会"说话"(第四-五章)→ 学会"对话"(第七章)→ 学会"创造"(第八章)→ 学会"思考"(第十章)→ 学会"同时看、听、说、想、做"(本章)。
从感知到理解到创造到推理到行动,AI用十年走完了这条进化之路。但这条路是谁铺就的?哪些公司、哪些团队、哪些决策塑造了今天的AI格局?接下来两章将用"企业路径"的视角重新审视这段历史——第十二章聚焦OpenAI的七年GPT编年史,第十三章讲述DeepSeek如何用一条完全不同的路径震动世界。
本章引用论文
[1] GPT-4o System Card, 2024, OpenAI
[2] ReAct: Synergizing Reasoning and Acting in Language Models, 2022, Google/Princeton (Yao et al.) — 交叉引用第七章
[3] Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters, 2024, Google DeepMind / UC Berkeley (Snell et al.) — 交叉引用第十章
[4] GPT-4 Technical Report, 2023, OpenAI — 交叉引用第九章
[5] Highly Accurate Protein Structure Prediction with AlphaFold (AlphaFold 2), 2021, DeepMind (Jumper et al.)
[6] Video Generation Models as World Simulators (Sora Technical Report), 2024, OpenAI — 交叉引用第八章
[7] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis, 2020, UC Berkeley (Mildenhall et al.)
[8] 3D Gaussian Splatting for Real-Time Radiance Field Rendering, 2023, INRIA (Kerbl et al.)
第十二章:GPT编年史——一家公司如何定义一个时代
GPT系列的七年迭代,几乎就是整个大模型时代的缩影。从一篇不起眼的论文到价值数千亿美元的公司,从非营利实验室到全球AI竞赛的发令枪,OpenAI用GPT系列书写了AI历史上最跌宕起伏的企业故事。
前传:从机器人和Dota 2开始的OpenAI(2016-2017)
今天回顾OpenAI的故事,很多人会把它等同于"GPT的公司"。但OpenAI成立的头两三年,GPT连个影子都没有。这家公司最初的赌注押在一个完全不同的方向上——强化学习(Reinforcement Learning, RL)。
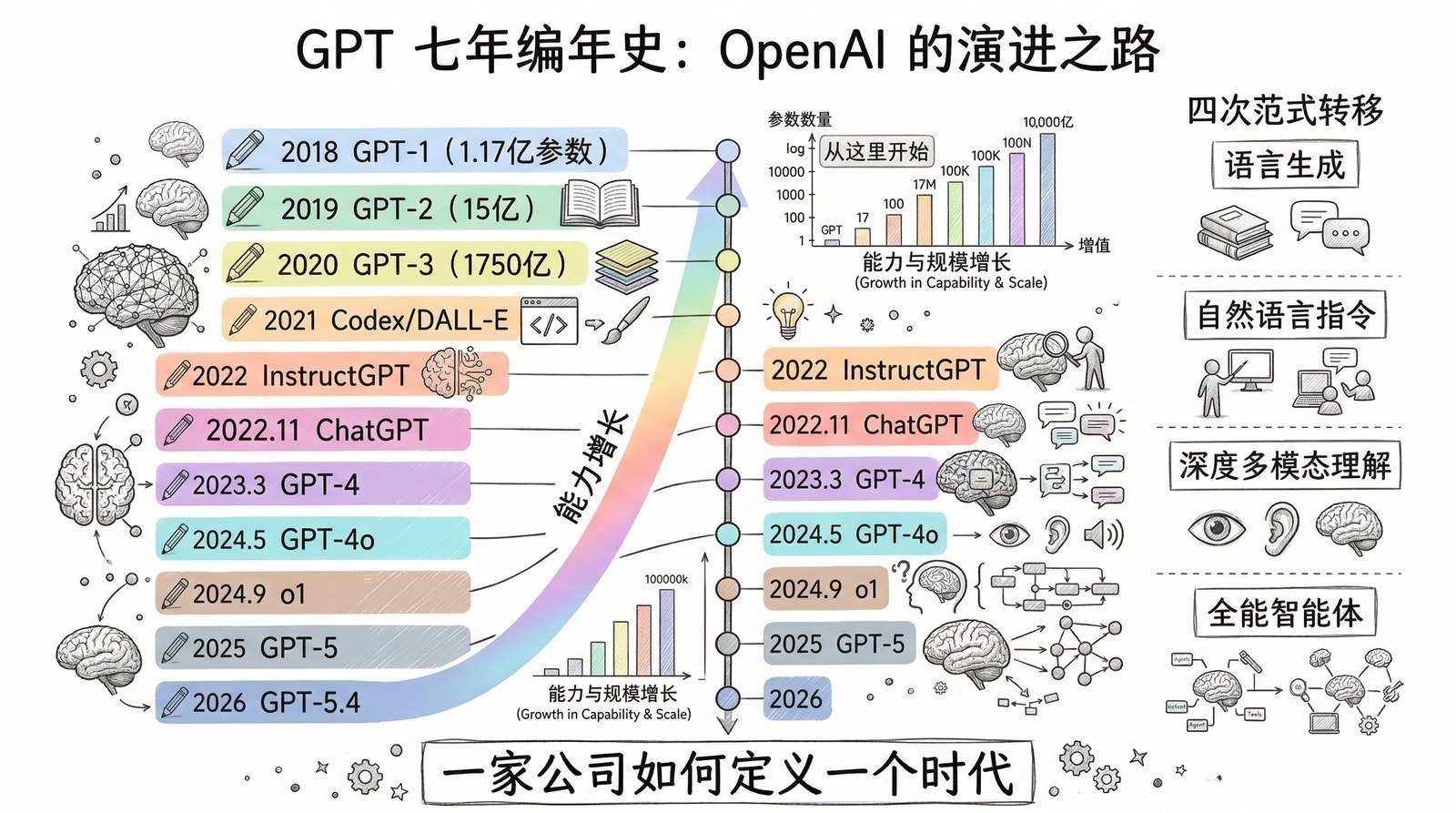
2015年12月成立后,OpenAI面临的第一个问题就是:一个立志实现通用人工智能(AGI)的实验室,到底应该从哪个方向开始?当时AI领域最耀眼的明星是DeepMind——2016年3月AlphaGo击败李世石的新闻传遍全球,强化学习被广泛视为通往AGI的最有希望的路线。OpenAI自然也选择了这条路。
2016年4月,OpenAI发布了OpenAI Gym——一个开源的强化学习工具包,为研究者提供标准化的实验环境。同年12月又推出了Universe——一个让AI在各种游戏和网页应用中进行训练的平台。2016年8月,NVIDIA将第一台DGX-1超级计算机赠送给OpenAI,这台机器可以将某些模型的训练时间从6天缩短到2小时。OpenAI的早期团队围绕RL构建了完整的研究基础设施。
接下来的两年,OpenAI在RL上投入了巨大的资源和精力。2016年底,由CTO Greg Brockman领导的团队启动了Dota 2项目——选择这款每天有数十万玩家在线的实时策略游戏作为AI研究的试验场。开发者们最初尝试用硬编码规则来制作游戏机器人,但很快发现规则系统无法应对职业级别的复杂度,于是彻底转向了强化学习。
2017年8月,在Dota 2国际邀请赛(TI7)的主舞台上,OpenAI的1v1 AI机器人击败了乌克兰职业选手Dendi——第一局不到10分钟就结束了,Dendi在第二局开始几分钟后就投降了,全程反复感叹"这家伙太可怕了"。这是RL在复杂实时策略游戏中击败职业选手的第一次公开展示,远比棋类游戏的回合制决策复杂。赛后,Brockman宣布:"下一步是5对5,明年再来。"
2018年的OpenAI Five(5v5版本)更加雄心勃勃。每个AI机器人使用一个4096单元的LSTM神经网络,通过PPO(近端策略优化)算法从零开始自我对弈学习。训练规模惊人:OpenAI从Google租用了128,000个CPU和256个GPU,连续运行数周,模型累计自我对弈了相当于180年的游戏时长。2017年,OpenAI全年预算的四分之一(790万美元)花在了云计算上——而同期DeepMind的总支出是4.42亿美元。一个非营利实验室在用远小于对手的资源做着同样量级的事情。
2018年8月的TI8(国际邀请赛)上,OpenAI Five在主舞台迎战世界顶级职业队伍——先后输给了paiN Gaming和一支中国明星队。尽管在前20-35分钟内AI保持了强劲的竞争力,但人类选手凭借更高超的后期战略决策和团队配合最终获胜。OpenAI坦然承认失败,并在赛后声明中说:"赢固然好,但输能让我们看清与最优秀的人类之间的差距。"
但OpenAI Five并没有就此止步。经过又一轮8个月的密集训练——累计自我对弈时长从180年增长到45,000年,模型参数从4000万扩大到1.6亿——2019年4月13日,OpenAI Five在旧金山的"OpenAI Five Finals"上迎战TI8冠军OG战队。这一次,AI以2:0横扫了世界冠军。第一局虽然艰苦,但第二局仅用不到20分钟就结束了——OG在金币劣势25,000、人头差31的情况下缴械投降。OG选手BigDaddy在赛后采访中说:"他们真的太强了。一旦你被卷入他们的节奏,就再也赢不了。"这是电子竞技历史上AI首次在公开直播中击败世界冠军。赛后,OpenAI向全世界开放了OpenAI Five Arena,让普通玩家也能与AI对战或组队。
同年,OpenAI还将Dota 2项目中开发的RL算法和训练代码复用到了机器人领域——发布了Dactyl项目,用强化学习训练一只机械手在模拟环境中学会操控物理物体,然后将学到的技能迁移到真实硬件上。这是"sim-to-real"(从模拟到现实)范式的早期验证。
从技术成果看,OpenAI的RL路线是成功的。但从AGI愿景看,一个根本性的问题正在浮现:这些能力都是"窄"的——Dota 2的AI不会做别的,机械手只会转魔方。强化学习每解决一个新任务,都需要从头设计奖励函数和训练环境,这和"通用智能"的目标之间似乎隔着一道难以逾越的鸿沟。
Ilya的直觉:从RL到语言模型的关键转向
正是在这个时刻,一个人的科研直觉改变了OpenAI的命运——这个人就是联合创始人兼首席科学家Ilya。
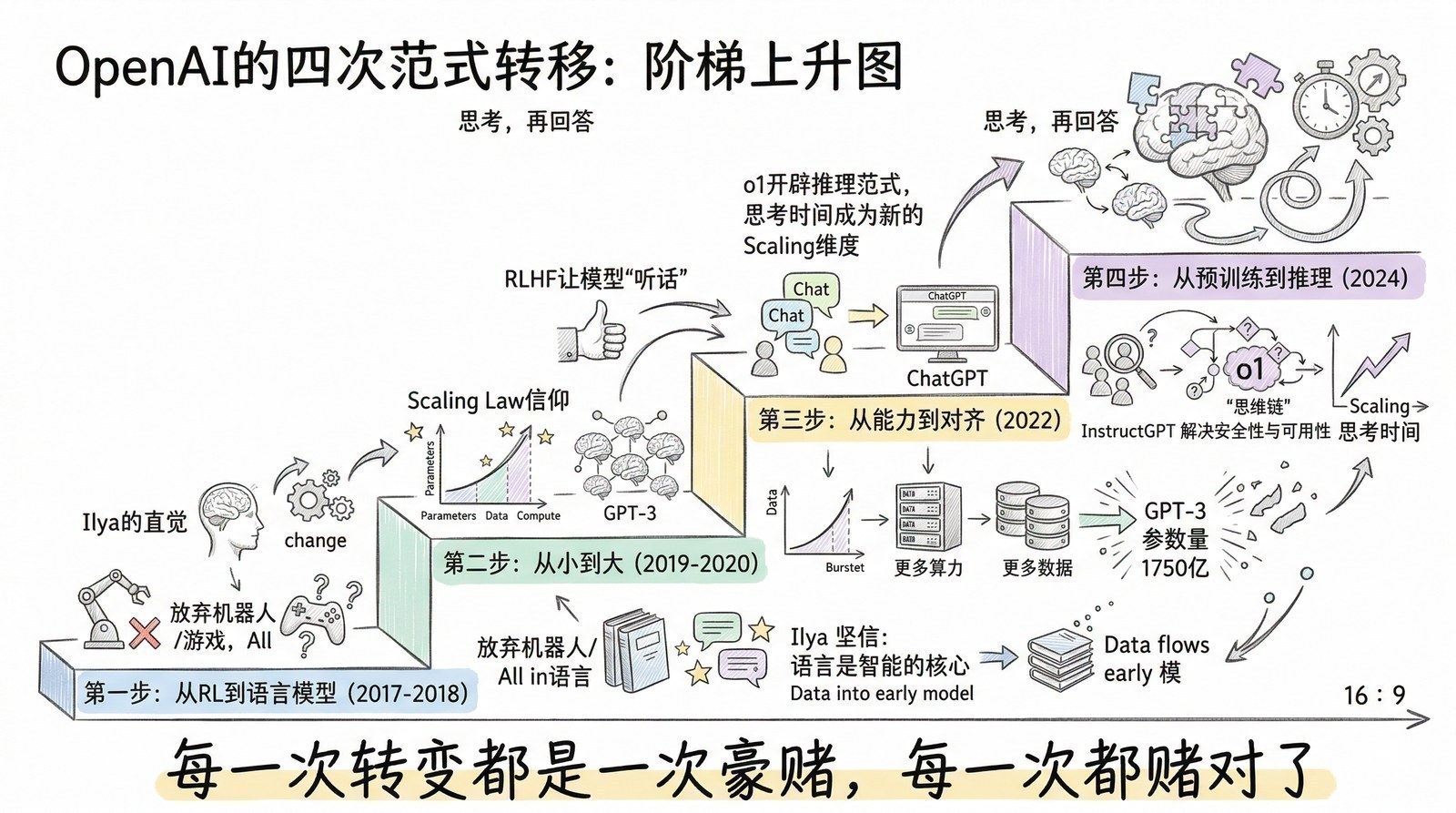
Ilya的背景决定了他看待AI的独特视角。他是Geoffrey Hinton的博士生,2012年和Alex Krizhevsky一起发明了AlexNet(第一章),亲手引爆了深度学习革命。在Google期间,他发明了序列到序列学习(Sequence to Sequence Learning),证明了神经网络可以完成机器翻译这样的复杂语言任务。他还参与了AlphaGo和TensorFlow的研发。2015年底离开Google加入OpenAI时,他同时拥有计算机视觉、自然语言处理和强化学习三个领域的深厚经验——这种跨领域视野在AI研究者中极为罕见。
Ilya从AlexNet中获得的核心直觉是:规模就是力量。当大多数研究者还在用几百个神经元的网络做实验时,他就坚信更大、更深的网络才是解锁真正能力的关键。在GPU算力支撑下,这个判断通过ImageNet竞赛被验证了。加入OpenAI后,Ilya把这个直觉带到了新的战场——他坚信同样的"规模法则"在语言领域也应该成立。
在OpenAI内部,Ilya推动了一个在当时看来相当反直觉的判断:与其继续在RL的每个任务上单独突破,不如把赌注押到大规模无监督语言预训练上——用海量文本训练一个通用的语言模型,让它通过"预测下一个词"来自动发现数据中的规律和结构。他后来在与NVIDIA CEO黄仁勋的对话中回忆说:"从一开始,OpenAI内部就有一种强烈的信仰——规模会带来突破。问题只是:把规模用在什么地方?"
Ilya在对话中坦言,当时OpenAI有两条并行的大想法:一条是强化学习(Dota 2和机器人就是这条线上的产物),另一条是他所说的"下一个东西的预测"——即后来的GPT路线。他的关键洞察是:足够好的"下一个字符预测"本质上就是在做数据压缩,而数据压缩天然要求模型理解数据中隐藏的结构和规律。"我们在GPT模型中看到的就是这样——你训练它预测下一个词,人们说这只是统计相关性。但到这个地步,对任何人来说都应该很清楚了"——好的预测意味着真正的理解。
这个判断在2017到2018年间是极具争议的。大多数AI研究者认为,无监督文本预训练充其量只能学到肤浅的语言模式——真正的推理和理解需要精心设计的任务和标注数据。一位前OpenAI研究员后来回忆说:"Ilya是OpenAI规模化哲学的总设计师。当其他人专注于算法创新时,Ilya一直在说:'就是把它做大。能力会自己涌现出来。'这在现在听起来像常识,但在2017-2018年是非常逆主流的。大多数研究者认为你很快就会遇到收益递减。"
Ilya为什么会有这样的直觉?他自己的解释涉及一种深刻的认知心理学观察:研究者长期和某个系统打交道,会对它的局限性形成强烈的直觉,从而系统性地低估神经网络的潜力。"我认为有非常强大的心理力量在起作用——如果你大量使用一个特定系统,你会如此尖锐地感受到它的局限,你的直觉会对你尖叫:这个东西有那么多事情做不了。我认为这就是AI研究者一直低估神经网络的原因。"而Ilya恰恰不是一个被单一范式锁住的研究者——从视觉到语言到强化学习,他的跨领域经历让他能够看到别人看不到的通用模式。
2018年6月GPT-1的发布,就是这次战略转向的第一个成果。而OpenAI的RL积累并没有被浪费——PPO算法后来成为InstructGPT和ChatGPT中RLHF训练的核心组件,强化学习从"主攻方向"变成了"对齐工具箱中的关键武器"。甚至到了2024年的o1模型,强化学习再次被赋予核心角色——这次不是用来打游戏,而是用来训练推理能力。
这段从RL到GPT的转向,揭示了AI发展中一个被低估的规律:技术路线的选择往往不是集体理性讨论的结果,而是由极少数拥有跨领域视野和逆向思考能力的科学家的直觉所决定的。从Jeff Hinton押注深度学习,到Ilya押注规模化语言预训练,再到后来DeepSeek团队押注强化学习驱动的推理能力——每一次AI核心范式的迁移,背后都站着一两个做出关键判断的人。技术民主化和开源社区可以加速已被验证的范式的扩散,但新范式的开辟,至今仍然属于全球极少数拥有最关键直觉的科学家。
GPT-1:一次逆流而上的赌注(2018)
2018年6月11日,OpenAI发表了一篇论文——《Improving Language Understanding by Generative Pre-Training》[1]。这篇论文介绍了GPT-1,一个只有1.17亿参数的语言模型。放在今天看,1.17亿参数连一个"小模型"都算不上,但这篇论文所确立的方法论,改变了整个NLP领域的走向。
GPT-1的核心思想是:先用大量无标注文本做"预训练"(让模型自行学习语言规律),再在特定任务上做少量"微调"。这在今天看来理所当然,但在2018年,主流NLP研究依赖的是大量人工标注数据来训练针对特定任务的专用模型。GPT-1的"预训练+微调"范式,等于在说——你不需要为每个任务从零开始建模型,一个通用的语言理解底座就够了。
GPT-1的架构选择也很关键:它使用的是Transformer的"解码器"部分(第四章),由12层Transformer堆叠而成,训练数据来自BookCorpus——一个包含约7000本未出版小说的文本语料库。在当时的多项基准测试上,GPT-1的表现超过了那些为特定任务精心设计的模型:在自然语言推理任务上提升了5.8%,在阅读理解基准RACE上提升了5.7%,在常识推理Story Cloze测试上提升了8.9%,综合评分GLUE达到72.8(此前最佳是68.9)。
但这些数字在当时几乎无人关注。同年10月,Google发布了BERT(第五章),以双向编码器的方式在11项NLP基准上全面刷新纪录,风头完全盖过了GPT-1。学术界的主流判断是:编码器路线更适合"理解"任务,解码器路线只适合"生成"——而生成在当时被认为价值有限。
回头看,GPT-1真正的价值不在于它的能力——而在于它确立了一个后来被反复验证的哲学:用同一个Transformer解码器架构,通过增大规模来获得更强的能力。OpenAI从这一刻起就押注了这条路线,并且在此后七年中从未偏移。
GPT-2:用"恐惧"让世界认识语言模型(2019)
2019年2月,OpenAI发布了GPT-2[2]——参数量从GPT-1的1.17亿跃升到15亿,增长了约13倍。训练数据也同步升级:不再使用小说语料BookCorpus,而是换成了WebText——一个从Reddit上高质量帖子(3分以上点赞的外链网页)中抓取的40GB互联网文本数据集,涵盖了约800万网页。
GPT-2的能力让研究者们第一次感到了"不安"。给它一段新闻开头,它能续写出段落连贯、逻辑自洽、风格一致的长文章——虽然仔细看仍有错误,但粗读起来几乎可以以假乱真。更让人惊讶的是GPT-2展现出了"零样本学习"(zero-shot learning)的能力——不需要在特定任务上做微调,仅凭预训练就能完成一些翻译、摘要和问答任务,虽然效果还比较粗糙。
OpenAI因此做出了一个在AI历史上空前的决定:以"安全风险"为由,最初只发布了较小的版本(124M参数),声称完整版本"太危险了,不能公开发布"。这是AI领域第一次有研究机构公开以"可能被滥用于生成虚假信息"为理由限制模型发布。
这个决定引发了巨大争议。很多研究者认为OpenAI是在"制造恐慌来营销"——一个15亿参数的模型能有多大危害?批评者指出,GPT-2生成的文本虽然读起来通顺,但仍然充满事实错误,远谈不上"危险"。但不可否认的是,这次"分阶段发布"策略让GPT-2获得了远超其技术价值的公众关注——它成为了第一个被主流媒体广泛报道的语言模型。OpenAI后来在数月内逐步开放了完整模型,同时监测实际的滥用风险。
从技术演进角度看,GPT-2的更深远意义在于一个初步信号:规模扩大带来了质变,而不仅仅是量变。GPT-1能写简单的段落,GPT-2能写连贯的长文。这为后来GPT-3的"涌现能力"埋下了伏笔。
GPT-3:规模化涌现的验证与商业化起点(2020)
2020年5月,OpenAI发表了可能是大模型时代最重要的论文之一——《Language Models are Few-Shot Learners》[3],介绍了GPT-3。1750亿参数,是GPT-2的100多倍。第六章已经详细讲述了GPT-3的技术故事——Scaling Law、few-shot learning、涌现能力。这里从企业视角补充几个关键决策。
GPT-3的训练数据包括经过过滤的Common Crawl(4100亿token)、WebText2(190亿token)、两个图书语料库(共670亿token)以及英文维基百科(30亿token),总计约5000亿token。模型架构仍然是Transformer解码器,但规模空前:96层,12888维隐藏状态,96个注意力头。训练使用了微软提供的超级计算集群,这标志着OpenAI和微软深度绑定的开端。2019年,微软向OpenAI投资10亿美元,获得了GPT技术的独家云计算授权——从此OpenAI的每一代模型都离不开微软Azure的算力支撑。
GPT-3是OpenAI从"发论文"转向"做产品"的转折点。它不再只是一篇论文——OpenAI同时推出了GPT-3的API,让开发者可以付费调用模型。这是OpenAI商业化的起点,也是"模型即服务"(Model as a Service)商业模式的开创。通过API调用而非开源模型,OpenAI找到了一种既能保持技术优势又能变现的路径。
GPT-3最重要的技术发现是few-shot learning——给模型几个示例,它就能执行从未被训练过的新任务。这种能力不是靠任何特殊设计获得的,而是"自然涌现"的——当模型大到一定规模,它就自动获得了这种能力。这验证了Scaling Law的核心预测:更大的模型确实更强,而且能力的增长有时是突变式的(第六章)。这给了OpenAI继续"All in Scaling"的信心和资本。
Codex、DALL-E与Whisper:GPT架构的多模态扩张(2021-2022)
2021年是OpenAI从"语言模型公司"向"多模态AI平台"转型的关键一年。这一年,OpenAI在三个不同方向上证明了GPT架构的通用性——代码、图像和语音。
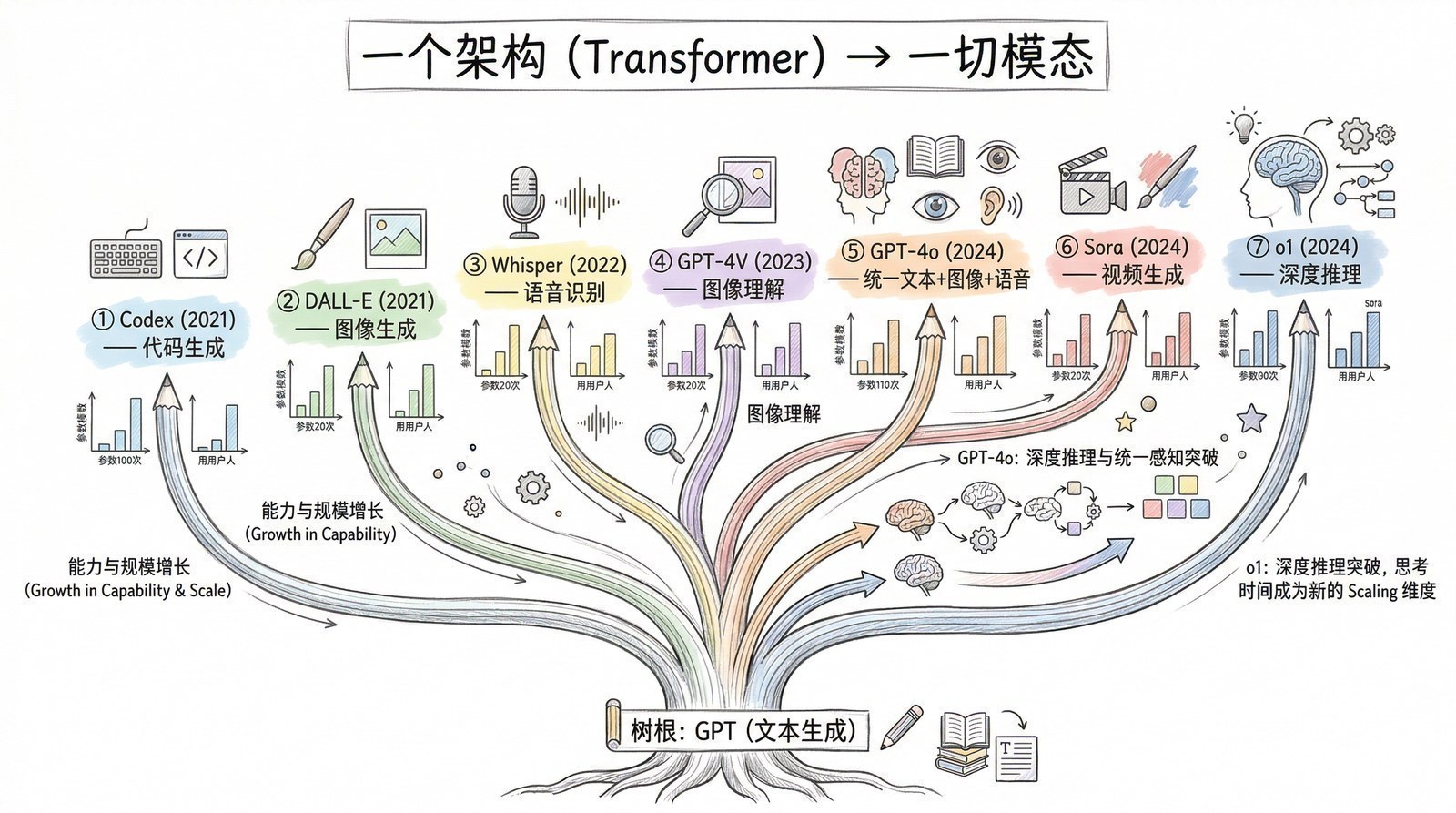
2021年1月5日,OpenAI发布了DALL-E——一个120亿参数的Transformer模型,能够根据自然语言描述生成图像。DALL-E本质上是GPT-3架构的一个变体,只不过它的"词汇表"不仅包含文本token,还包含图像token。这个看似简单的架构复用揭示了一个深刻的洞察:Transformer不仅能理解语言,还能理解视觉——只要你把图像"翻译"成token序列。DALL-E虽然生成的图像质量还比较粗糙,但它首次证明了"用文字描述来创造图像"这个方向是可行的。2022年4月,DALL-E 2发布,改用扩散模型替代了GPT-3的自回归方法,图像质量和分辨率实现了飞跃(第八章详述了从GAN到扩散模型的技术演进)。
2021年8月,OpenAI发布了Codex[4]——一个在GPT-3基础上用大量代码数据微调的模型。Codex论文的标题是《Evaluating Large Language Models Trained on Code》,但其影响远超一篇学术论文。
Codex的训练数据来自GitHub上公开的代码仓库,涵盖159GB的Python代码(来自5400万个公开代码库),以及十几种编程语言。它能够理解自然语言描述并将其转化为可运行的代码——本质上是让语言模型跨越了"自然语言"和"编程语言"之间的鸿沟。
Codex最重要的商业价值是催生了GitHub Copilot——这是第一个被大规模商业化部署的AI编程助手。2021年GitHub Copilot以技术预览的形式上线时,还没有ChatGPT,AI辅助编程对大多数开发者来说还是全新概念。Copilot能在开发者写代码时实时提供上下文相关的代码补全建议——函数体、代码块、甚至整个方法。GitHub报告称,Copilot的自动补全在Python函数中首次尝试准确率约为43%,十次尝试后准确率达到57%。这个数字看似不高,但在实际开发中已经足以显著提升效率。
2022年9月,OpenAI发布了Whisper——一个通用语音识别模型。Whisper使用68万小时的多语言音频数据进行训练,能够实现语音转录、语言识别和翻译。它的特别之处在于"通用性"——不需要为每种语言或每个场景单独训练,一个模型就能处理近100种语言的语音。Whisper后来被集成到ChatGPT的移动端应用中,为语音输入功能提供支持,也成为GPT-4o原生语音能力的技术前身。OpenAI后来承认,他们用Whisper转录了超过100万小时的YouTube视频作为GPT-4的训练数据——这一做法引发了关于训练数据版权的广泛争议。
从技术演进角度看,2021-2022年的这三条产品线(代码、图像、语音)揭示了一个重要规律:Transformer架构具有惊人的通用性——同一个底层架构,通过不同的训练数据和微调策略,可以被"特化"到完全不同的模态。GPT-3是通用语言底座,Codex是代码专家,DALL-E是图像创作者,Whisper是语音转录员。这种"一个架构统治所有模态"的趋势,在后来的GPT-4o和GPT-5中达到了逻辑终点——不再是多个专用模型的组合,而是一个统一的多模态系统(第七章详述了Codex与Vibe Coding的故事)。
InstructGPT:让模型"听话"的关键一步(2022年1月)
2022年1月,OpenAI发表了InstructGPT[5]——第七章已经详细讲述了RLHF三步法的技术细节。这里要强调的是InstructGPT背后的战略判断。
在InstructGPT之前,GPT-3虽然能力强大但"不听话"——经常答非所问、生成有害内容、输出格式混乱、编造不存在的事实。用一个比喻来说:GPT-3像一个博学但任性的天才——它什么都知道,但你很难让它按你想要的方式回答问题。这对研究者来说是可以接受的,但对普通用户来说几乎无法使用。
OpenAI的关键洞察是:模型的"原始能力"和"用户体验"之间存在巨大的鸿沟——弥合这个鸿沟的技术就是RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)。InstructGPT的训练分三步:首先,让人类标注员示范如何回答问题(监督微调);然后,让标注员对模型的多个回答进行排序,训练一个"奖励模型"来预测人类偏好;最后,用强化学习让模型最大化这个奖励模型的评分。
结果令人印象深刻:虽然InstructGPT只有13亿参数,但在人类评估中,用户更喜欢它的回答而非1750亿参数的GPT-3。这证明了"对齐"——让模型按照人类意图行事——是一项独立于"能力"的核心技术。一个更小但更听话的模型,比一个更大但不听话的模型更有用。
InstructGPT的论文本身只在学术界引起关注,但它所开创的RLHF方法论,直接催生了十个月后改变世界的产品——ChatGPT。
ChatGPT:五天一百万,AI走向大众(2022年11月)
2022年11月30日,OpenAI发布了ChatGPT——本质上就是InstructGPT的技术路线应用到了GPT-3.5上,加上一个简洁的对话界面。GPT-3.5是GPT-3的改进版本,同样使用了RLHF进行对齐训练,在处理代码和对话方面有显著提升。ChatGPT的初始训练过程是:先让人类标注员同时扮演用户和AI助手来生成对话数据做监督微调,再收集模型多个回答的人类排序来训练奖励模型,最后用PPO(近端策略优化)算法进行强化学习。
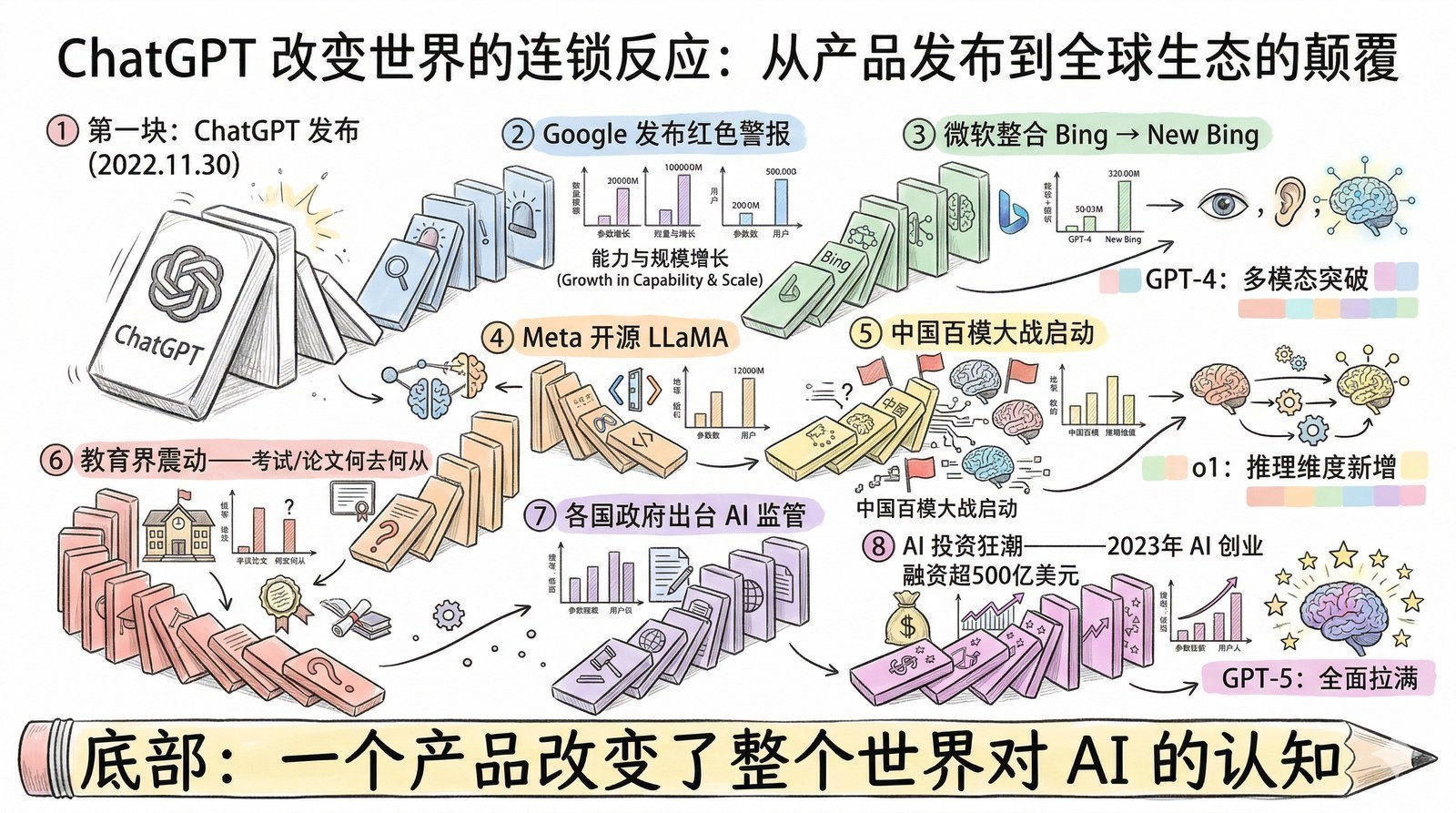
ChatGPT在5天内获得100万用户,到2023年1月底达到1亿月活跃用户——超越TikTok(9个月)和Instagram(2.5年),成为历史上增长最快的消费级应用。2023年2月,OpenAI推出了每月20美元的ChatGPT Plus订阅服务,提供更快的响应速度和更少的服务中断。
ChatGPT的成功证明了一个深刻的产品哲学:在AI领域,"可用性"可能比"能力"更重要。GPT-3已经很强了,但它只有API,普通用户用不了。ChatGPT的能力不比GPT-3强多少,但它加上了对齐(RLHF)和一个聊天界面——就让AI从"少数技术人员的工具"变成了"每个人都能用的产品"。对话界面的选择看似简单,实则至关重要——它将语言模型的交互方式从"写一段精心设计的prompt"变成了"像和朋友聊天一样说话"。这是一个产品洞察,而非技术突破。
ChatGPT的爆发也重新定义了科技行业的竞争格局。Google在ChatGPT发布后宣布进入"红色警报"状态,紧急加速了自己的大模型产品。微软迅速将ChatGPT整合进Bing搜索引擎,试图挑战Google长达二十年的搜索垄断。整个科技行业在2023年初进入了"AI军备竞赛"——而ChatGPT就是那声发令枪。
GPT-4:闭源标杆与"CloseAI"争议(2023年3月)
2023年3月14日,OpenAI发布了GPT-4[6]——第九章已经介绍了它的能力和围绕它的争议。GPT-4标志着OpenAI彻底从"开放的研究机构"转变为"封闭的商业公司"。
GPT-4的技术报告只有98页,却不包含任何有意义的架构和训练细节——不公布参数量、不公布数据组成、不公布训练方法。外部专家估计GPT-4可能拥有约1.8万亿参数,但OpenAI从未确认。OpenAI给出的理由是"安全考虑和竞争格局",但这和创立时"开放AI研究造福人类"的初心已经完全背离——越来越多的人开始讽刺它应该叫"CloseAI"。
从能力角度看,GPT-4的提升是实质性的。它是OpenAI第一个多模态模型——可以同时处理文本和图像输入。在美国律师资格考试中,GPT-4的成绩排在前10%(GPT-3.5只能排在后10%);在GRE、SAT等标准化考试中也表现出色。GPT-4还首次支持图像输入——你可以给它一张手写笔记的照片,它能准确解读内容。
GPT-4的商业影响同样深远。它被集成进了微软Copilot、GitHub Copilot、Snapchat的My AI、可汗学院的Khanmigo等众多产品中,成为首个被大规模嵌入到第三方应用中的大模型。OpenAI同时推出了ChatGPT Enterprise版本,面向企业用户提供更强的安全性、更长的上下文窗口和不限量使用。到2023年底,OpenAI的年化收入已经超过16亿美元。
2023年11月发生了著名的"宫斗"事件——OpenAI董事会突然解雇CEO Sam Altman,引发员工集体威胁辞职(超过700名员工签署联名信),Altman在几天内被重新任命。Ilya在这次事件中投票支持解雇Altman,但随后表达了后悔。这次事件暴露了"非营利使命"和"商业利益"之间的根本性张力,也导致了董事会的大幅改组。同月,OpenAI还发布了GPT-4 Turbo——上下文窗口从8K扩展到128K tokens,API价格大幅下降,并且更新了知识截止日期。
GPT-4时代的OpenAI还在构建一个更广泛的产品生态系统。2023年10月,DALL-E 3发布并原生集成到ChatGPT中——用户可以直接在对话中描述想要的图像,ChatGPT会自动将描述转化为精确的DALL-E 3提示词。相比DALL-E 2,DALL-E 3在理解复杂描述、渲染文字和生成细节方面有了巨大提升,并且内置了拒绝生成在世艺术家风格作品的安全措施。2023年11月,OpenAI推出了GPTs——允许用户创建定制化的ChatGPT变体,为特定任务或领域进行优化。2024年1月,GPT Store上线,上线时已有超过300万个用户创建的GPTs,形成了一个"AI应用商店"生态。这些举措将ChatGPT从一个"聊天工具"转变为一个可扩展的平台。
GPT-4o:原生多模态的突破(2024年5月)
2024年5月13日,OpenAI发布了GPT-4o[7]——"o"代表"omni"(全能)。这个命名本身就暗示了它的核心特征:这不是把文字、图片和声音"拼在一起"的多模态——而是一个在统一神经网络中同时处理文本、图像和音频的端到端模型。
在GPT-4o之前,ChatGPT的语音对话需要三个独立模型协同工作:一个把语音转成文字(Whisper),一个处理文字并生成回复(GPT-4),再一个把回复转成语音(TTS)。这个管道式方案意味着GPT-4无法感知语调、情绪和背景噪音——它只能"看到"文字转录。响应延迟也很大:GPT-3.5需要2.8秒,GPT-4需要5.4秒。
GPT-4o将这三步合为一步。它对音频输入的最快响应时间仅为232毫秒,平均约320毫秒——接近人类在正常对话中的反应速度(约210毫秒)。这是响应时间从5.4秒到0.32秒的16倍提升——从"等AI回复"变成了"和AI对话"。GPT-4o同时在50多种语言上表现优异,非英语文本性能相比GPT-4 Turbo有显著提升,API价格还降低了50%。
GPT-4o的发布伴随着一个有趣的插曲。OpenAI在发布前让模型化名"im-a-good-gpt2-chatbot"秘密上线了聊天机器人竞技场(Chatbot Arena),进行匿名A/B测试。CEO Altman在推特上发了一条意味深长的帖子:"im-a-good-gpt2-chatbot"——后来这被确认是GPT-4o的预热。更引人注目的是语音功能的"Sky"嗓音与好莱坞女演员斯嘉丽·约翰逊相似的争议——Altman在发布当天发了一条推文只写了一个词"her"(约翰逊曾主演电影《她》,饰演AI助手),这引发了广泛关注和约翰逊本人的不满。OpenAI最终下线了"Sky"嗓音。
2024年7月,OpenAI发布了更小、更便宜的GPT-4o mini,取代了GPT-3.5 Turbo成为ChatGPT的基础模型。GPT-4o mini的API价格仅为GPT-4o的十五分之一(输入0.15美元/百万token),使AI应用的门槛进一步降低。
从技术战略角度看,GPT-4o在商业上的意义可能比技术上更大——它证明了"多模态融合"可以做成一个流畅的消费级产品。你可以和AI像和真人一样自然地语音对话,给它看你的屏幕让它实时辅助,或者拍张照片让它帮你分析。这不再是技术演示,而是可以日常使用的产品体验。
GPT-4o发布前后,OpenAI还在多条产品线上快速推进。2024年2月,OpenAI预览了Sora——一个文字生成视频的模型。Sora基于DALL-E 3的扩散Transformer技术,能根据文字描述生成长达一分钟的高质量视频,展示出对物理世界的初步理解(物体遮挡、光影变化、人物动作连续性)。OpenAI自己将Sora类比为"视频领域的GPT-1时刻"——第一次让视频生成看起来真正可行(第八章详述了Sora的技术架构)。Sora经过近一年的安全测试和优化后,在2024年12月的"OpenAI十二天"活动中以Sora Turbo的形式正式向ChatGPT Plus和Pro用户开放。
2024年7月,OpenAI推出了SearchGPT原型——一个AI驱动的搜索引擎,直接用自然语言回答用户问题并提供来源链接。这是OpenAI首次正面挑战Google的核心业务——搜索。SearchGPT后来在2024年10月以"ChatGPT Search"的形式正式整合进ChatGPT,2025年2月向所有用户开放,将"搜索"从一个独立功能变成了对话的自然延伸。
o1:推理范式的开辟(2024年9月)
2024年9月12日,OpenAI发布了o1——此前内部代号为"草莓"(Strawberry),更早期的传闻中则被称为Q*。o1代表了OpenAI的一次根本性方向转换:从"让模型知道更多"到"让模型想得更深"(第十章详述)。
o1的技术核心是将"思维链"(Chain of Thought)从一种提示技巧升级为模型的内在能力。以前,你需要在prompt中写"请一步步思考"来引导模型进行逐步推理。o1不同——它通过大规模强化学习被训练成了一个"天生会思考"的模型。OpenAI将其描述为:模型在回答问题前,先进行一轮内部推理——识别错误、分解复杂步骤、尝试不同方法——然后才给出最终答案。用丹尼尔·卡尼曼在《思考,快与慢》中的框架来说:此前的GPT模型是"系统1"(快速直觉),o1则增加了"系统2"(慢速深思)。
o1的推理结果令人印象深刻:在竞赛编程平台Codeforces上排名前11%(第89百分位),在美国数学奥林匹克资格赛(AIME 2024)上跻身全美前500名,在物理、生物、化学博士级问题基准(GPQA)上超过了人类博士的平均水平。但代价也很明显——o1的推理过程消耗的计算资源约为普通GPT模型的数十倍,响应时间也大幅增加。
更重要的是,o1验证了OpenAI的一个战略判断:当预训练Scaling遇到瓶颈时,"测试时计算"(test-time compute)——让模型在回答前花更多时间"思考"——是一条新的Scaling路线。OpenAI发现,给o1更多的思考时间,它的回答通常更准确——这在之前的GPT模型上并不成立(让GPT-4自主循环运行,反而更容易跑偏或陷入死循环)。这意味着AI性能提升不再只依赖于更大的模型和更多的训练数据——推理时间本身也成为了一个可以"扩展"的维度。
从企业竞争角度看,o1让OpenAI重新拉开了与竞争对手的差距。2024年上半年,Claude 3.5 Sonnet、Gemini 1.5 Pro等竞品已经在很多基准上追平甚至超越了GPT-4o——大模型竞争似乎在走向"同质化"。o1的发布用一个全新的维度(推理能力)重新定义了竞争规则。
GPT-4.5(Orion):一个时代的终章(2025年2月)
2025年2月27日,OpenAI发布了GPT-4.5——内部代号Orion(猎户座)。这个模型有着一个特殊的历史地位:它是OpenAI最后一个不使用"思维链推理"的GPT模型,也是纯粹依靠扩大预训练规模来提升能力的路线的"终章"。
据两位前OpenAI员工透露,Orion最初的目标是成为GPT-5——一个展现出相比GPT-4全面飞跃的系统。但这个目标未能实现。模型的能力提升虽然存在,但不是数量级的跃迁——特别是在数学和编程等推理任务上,它甚至不如已经发布的o1和o3-mini。OpenAI最终将其以"GPT-4.5"的名义发布,暗示这只是一个增量升级而非换代产品。
GPT-4.5的规模空前——外部分析师估计其参数量可能达到4万亿到5万亿。Sam Altman自己形容它是一个"巨大而昂贵的模型"。API定价反映了这一点:输入75美元/百万token,输出150美元/百万token——是GPT-4o的30倍。这个定价如此之高,以至于OpenAI自己都在评估是否值得长期在API中提供这个模型。
GPT-4.5的亮点在于"世界知识"和"情商"。在SimpleQA基准上(测试简单事实问答),GPT-4.5的幻觉率降到了37.1%(GPT-4o是59.8%)。OpenAI的内部测试显示,用户认为GPT-4.5更"自然"、更像和一个"有思想的人"交谈。Altman在推特上说GPT-4.5是第一个让他觉得"像在和一个有思考能力的人对话"的AI。
但GPT-4.5的发布恰恰证明了一个关键结论:纯粹依靠扩大预训练规模的路线正在触及天花板。正如《纽约时报》评论的那样,GPT-4.5"标志着一个时代的终结"——此后,OpenAI的所有模型都将融合推理能力。Altman在GPT-4.5发布两周前就已经预告:真正的GPT-5将在"几周到几个月内"到来,它将把GPT系列的直觉能力和o系列的推理能力合二为一。
在GPT-4.5和GPT-5之间,OpenAI还密集推出了一系列Agent和智能体产品。2025年1月23日,OpenAI发布了Operator——一个能够自主浏览网页、填写表单、完成在线任务的AI Agent,标志着OpenAI从"对话助手"向"行动执行者"迈出了实质性的一步。2025年2月,OpenAI发布了Deep Research——基于o3模型的深度研究功能,能够结合高级推理和网页搜索,用数分钟时间自动撰写一份通常需要人类研究者数小时才能完成的深度报告。同年9月,Sora 2发布,OpenAI将其类比为"视频领域的GPT-3.5时刻"——能够生成此前完全不可能的复杂场景(奥运体操动作、桨板上的后空翻、精确的物理动力学模拟)。2025年12月,Disney宣布投资10亿美元与OpenAI合作,允许用户在Sora 2上生成包括漫威、星球大战、皮克斯在内的200多个迪士尼版权角色——这是AI生成内容与传统IP融合的标志性事件。
GPT-5:快慢统一的新范式(2025年8月)
2025年8月7日,OpenAI通过直播发布了GPT-5[8]——GPT系列迄今为止最重要的一次发布。这不只是"更大的模型"——它代表了OpenAI对"AI应该怎么工作"的一次根本性重构。
GPT-5的核心创新是"统一路由"架构——一个内置的实时路由器根据对话类型、问题复杂度、工具需求和用户明确意图来自动决定使用哪种模式。在底层,GPT-5是一个由多个组件构成的系统:一个快速高吞吐量的主模型(gpt-5-main)处理大多数日常问题;一个深度推理模型(gpt-5-thinking)处理需要仔细思考的复杂问题;以及它们各自更小的mini版本在用量超限时接管。用户不需要手动选择——AI自己判断这个问题需要"快想"还是"慢想"。
在基准测试上,GPT-5达到了新的高度:AIME 2025数学竞赛94.6%(不用工具),SWE-bench编程74.9%,多模态理解MMMU 84.2%。GPT-5 pro版本在GPQA科学推理上达到了88.4%。在幻觉率方面,启用网页搜索时,GPT-5比GPT-4o减少了约45%的事实错误;使用推理模式时,比o3减少了约80%的事实错误,欺骗率从4.8%降到2.1%。
GPT-5还引入了多项新特性:最大256K tokens的上下文窗口(API中达400K);"个性"选项(包括Cynic、Robot、Listener、Nerd等风格);新的"安全补全"(safe completions)方法取代了简单的拒绝回答,让模型在面对敏感话题时给出安全但有信息量的回复而非一刀切地拒绝。2025年3月,OpenAI用GPT Image替换了DALL-E 3作为ChatGPT内置的图像生成引擎——最显著的改进是图像中的文字渲染质量大幅提升,这对品牌营销和设计场景尤其重要。2025年10月,OpenAI发布了ChatGPT Atlas——一个内置ChatGPT助手的浏览器,具备"Agent模式"可以代替用户执行在线操作,直接挑战Chrome和Safari的市场地位。
但GPT-5的发布并非一帆风顺。OpenAI在发布时移除了ChatGPT中的GPT-4o选项,引发了大量用户不满——很多人更喜欢GPT-4o更温暖、更有个性的对话风格,认为GPT-5虽然更聪明但语气"平淡""缺乏创意",甚至有人形容它像一个"疲惫的秘书"。Altman在社交媒体上坦承OpenAI"低估了人们对GPT-4o某些特质的重视程度",并表示需要在个性化方面做更多工作。OpenAI随后恢复了GPT-4o供付费用户选择。这个插曲揭示了一个深刻的产品洞察:用户需要的不只是"更聪明的AI",还有"更有温度的AI"——智能和人格是两个独立的维度。
GPT-5同时发布了GPT-OSS——两个开源权重模型:120B(约1170亿总参数,使用MoE架构,每token仅51亿参数活跃,可在单块H100 GPU上运行)和20B(约210亿参数,优化用于Agent任务和工具调用,可在16GB显存的消费级硬件上运行)。这是OpenAI自2019年GPT-2以来第一次发布开源模型,回应了Meta LLaMA和DeepSeek等开源竞争者的压力。
GPT-5.2:专业知识工作的新标杆(2025年12月)
2025年12月11日,OpenAI发布了GPT-5.2[9]——距离前一个版本GPT-5.1仅一个月不到。这次发布的背景是:Google的Gemini 3 Pro在11月中旬发布后,在多项基准上领先于OpenAI的模型。多家媒体报道称,Altman为此发布了内部"红色警报"(Code Red),重新调配资源加速ChatGPT的改进。
OpenAI应用部门CEO Fidji Simo否认GPT-5.2是对Google的"应激反应"——她说这个模型"已经开发了很多个月",内部代号为"Garlic"(大蒜)。Altman在发布前一天在社交媒体上发了一段自己用大量大蒜做菜的视频作为暗示。
GPT-5.2分为三种模式:Instant(快速日常模式)、Thinking(推理模式)和Pro(扩展推理模式)。知识截止日期更新至2025年8月,上下文窗口400K tokens,输出128K tokens。
GPT-5.2 Thinking在GDPval基准上——一个衡量44个职业的知识工作任务的评测——首次达到了"超越人类专家"的水平:在70.9%的对比中,GPT-5.2 Thinking的输出质量等于或超过了顶级行业专业人士,而且速度快11倍、成本不到专业人士的1%。在AIME 2025数学竞赛上达到100%(满分),GPQA Diamond科学推理达到93.2%,SWE-bench Pro编程达到55.6%。它也是第一个在ARC-AGI-1上突破90%的模型。
在编码领域,GPT-5.2的专用版本GPT-5.2-Codex于2026年1月14日发布,针对长周期Agent编码任务进行了优化,具备上下文压缩能力和增强的网络安全功能。一位安全研究员使用GPT-5.1-Codex-Max配合Codex CLI发现并负责任地披露了React框架中的三个安全漏洞——这是AI辅助安全研究的一个里程碑事件。
GPT-5.2的发布反映了2025年末AI竞争的激烈程度:OpenAI、Google、Anthropic之间的模型迭代周期从年度缩短到了月度。前端模型的领先优势可能只能维持数周。在这种环境下,GPT-5.2的意义不仅在于它的能力——还在于OpenAI展示的迭代速度。
GPT-5.3-Codex:自我创造的编码Agent(2026年2月)
2026年2月5日,OpenAI发布了GPT-5.3-Codex[11]——发布时间距离Anthropic发布Claude Opus 4.6仅30分钟。这个发布时机本身就说明了2026年初AI竞争的白热化程度。
GPT-5.3-Codex的核心突破在于"融合"——它不再像前代那样将"通用推理模型"和"编码专用模型"分开维护,而是首次将GPT-5.2的推理和知识工作能力与GPT-5.2-Codex的编码能力合并到同一个模型中。这意味着同一个模型既能写代码和调试,也能更新Jira工单、撰写文档、管理部署流水线——从"编码助手"进化为"通用工作Agent"。同时速度还快了25%。
GPT-5.3-Codex最引人注目的特质是:它参与了自身的创造过程。OpenAI透露,早期版本的GPT-5.3-Codex被用于监控和调试自己的训练运行——检测训练过程中的模式、诊断评测结果、编写脚本来动态扩展GPU集群应对流量变化。OpenAI的工程师们说,这个模型的出现让他们的工作方式在短短两个月内发生了根本性改变。这和Google的Gemini 3用模型生成自己的训练数据不同——GPT-5.3-Codex不仅生成数据,还充当了基础设施的"驻场可靠性工程师"。
在Codex应用中,GPT-5.3-Codex引入了全新的交互模式:你可以在模型工作过程中随时介入——提问、讨论方案、调整方向——而不会丢失上下文。这种"边工作边对话"的体验,让AI Agent从"提交任务等结果"变成了"和同事一起干活"。
GPT-5.3-Codex也是OpenAI第一个在网络安全领域被标记为"高能力"(High capability)的模型——这意味着它在发现和利用软件漏洞方面的能力已经强到需要额外的安全防护措施。OpenAI为此部署了迄今最全面的网络安全安全堆栈,包括安全训练、自动监控、受信任访问机制,并延迟了面向开发者的完整API访问。这是一个值得深思的信号:当AI模型强大到需要限制自己的能力时,技术发展与安全防护之间的张力变得前所未有的紧迫。
2026年2月12日,OpenAI又发布了GPT-5.3-Codex-Spark——一个更小的版本,专为实时编码优化。这是OpenAI与Cerebras合作的第一个成果,利用Cerebras的晶圆级引擎实现超过每秒1000个token的推理速度。这个方向揭示了AI编码的下一个前沿:不仅要聪明,还要快到让人感觉不到延迟。
GPT-5.4:原生Computer Use与百万上下文(2026年3月)
2026年3月5日,OpenAI发布了GPT-5.4[12]——距离GPT-5.3 Instant的更新仅两天,距离GPT-5.3-Codex仅一个月。这种近乎疯狂的发布节奏,反映了OpenAI在Google Gemini 3.1 Pro和Anthropic Claude Opus 4.6双重压力下的竞争态势。
GPT-5.4的定位是:第一个将前沿推理、前沿编码和原生Computer Use(计算机操控)能力整合到同一个主线模型中的版本。OpenAI将GPT-5.3-Codex的编码能力"吸收"进了GPT-5.4,不再需要用户在"通用模型"和"编码模型"之间手动切换——从此GPT-5.x的主线模型就是一个能做一切的统一体。
原生Computer Use是GPT-5.4最具突破性的新能力。模型可以解读用户的屏幕截图,理解界面元素,然后直接执行鼠标点击和键盘输入——在不同应用之间导航、编辑文档、操作电子表格、填写表单。在OSWorld-Verified基准上(衡量AI操控桌面环境的能力),GPT-5.4得分75.0%——不仅远超GPT-5.2的47.3%,甚至超过了OpenAI引用的人类平均基线72.4%。这意味着在标准化的桌面操作任务上,GPT-5.4的表现已经和普通人类用户持平甚至更好。
API版本支持高达105万token的上下文窗口和12.8万token的最大输出,是GPT-4时代8K上下文的130倍。GPT-5.4还引入了"工具搜索"(tool search)机制,在工具密集型工作流中减少47%的token消耗。在ChatGPT中,GPT-5.4 Thinking可以在开始复杂任务前先展示"思考计划",让用户在模型完成全部输出之前就能调整方向——解决了此前用户"等了30分钟结果方向错了"的痛点。
在专业工作基准上,GPT-5.4在GDPval上达到83.0%(GPT-5.2为70.9%),在投资银行建模任务上达到87.3%(GPT-5.2为68.4%),在SWE-Bench Pro编程上达到57.7%。更高端的GPT-5.4 Pro版本在BrowseComp信息检索上达到89.3%,在ARC-AGI-2上达到83.3%。相比GPT-5.2,GPT-5.4的事实错误率降低了33%,整体回答中包含错误的概率降低了18%。
GPT-5.4也是OpenAI在网络安全防御领域达到"高能力"评级的第一个通用模型。同日发布的ChatGPT for Excel插件,让GPT-5.4可以直接嵌入电子表格工作流——这是"AI Agent进入日常办公"最直观的体现。3月17日,OpenAI又发布了GPT-5.4 mini和nano版本,其中mini版本在多项评测中接近GPT-5.4的表现,但速度快2倍以上,成本仅为30%——这为"大模型调度、小模型执行"的多Agent架构模式提供了理想的组件。
回望GPT-5系列从2025年8月到2026年3月的七个月演化——GPT-5 → 5.1 → 5.2 → 5.3-Codex → 5.4——OpenAI已经从"一年发布一个重大版本"变成了"每月都有实质性升级"。这种持续迭代的节奏本身就是一种战略武器:它让竞争对手永远在追赶一个移动的靶标。
OpenAI的四次范式转移
回顾GPT从1到5.4的八年历程,可以清晰地看到四次范式转移:
第一次(2018-2019,GPT-1/GPT-2):预训练+微调。确立了"用同一个Transformer解码器架构通过Scaling获得更强能力"的基本哲学。GPT-1证明了方法可行,GPT-2证明了规模带来质变。
第二次(2020-2021,GPT-3/Codex):规模化涌现。证明了"更大=更强"的Scaling Law,发现了涌现能力。开始商业化(API),Codex开辟了代码生成赛道。
第三次(2022-2023,InstructGPT/ChatGPT/GPT-4):对齐+产品化。用RLHF让模型"听话",用ChatGPT让AI走向大众。从研究机构转变为产品公司,估值从十亿级跃升到千亿级。
第四次(2024-2026,o1/GPT-5/GPT-5.4):推理+Agent+统一。用强化学习训练推理能力,用GPT-5把快速回答和深度推理统一到一个系统中,用GPT-5.2首次在专业知识工作上超越人类专家水平,用GPT-5.3-Codex实现模型参与自身创造,用GPT-5.4让AI具备原生计算机操控能力——AI从"回答问题的工具"变成了"能独立完成工作的数字同事"。
每一次转移都不只是技术升级——而是对"AI应该怎么做"的根本性重新定义。
从非营利到科技巨头:OpenAI的风雨十年
GPT系列的技术进化伴随着OpenAI公司本身的深刻蜕变——而这个蜕变的过程远比技术演进更加曲折。
2015年12月,OpenAI以非营利组织的形式成立——创始团队包括Sam Altman、马斯克、Greg Brockman、Ilya等人,获得10亿美元捐赠承诺,使命是"确保通用人工智能造福全人类"。马斯克是最耀眼的联合创始人——他不仅贡献了约3800万美元的早期资金,还带来了巨大的公众关注度和行业号召力。OpenAI成立之初之所以能吸引世界顶级的AI研究者加入一个非营利组织,马斯克的名字和愿景功不可没。
但资金压力很快就暴露了非营利模式的根本局限。训练Dota 2的AI需要从Google租用12.8万个CPU,2017年全年预算的四分之一花在了云计算上,而竞争对手DeepMind背靠Google的无限算力。2017年,OpenAI的创始人们开始讨论从非营利转向某种盈利结构的可能性。马斯克提出了一个激进方案:让Tesla收购OpenAI——他认为Tesla的算力资源和工程团队是对抗Google的唯一筹码。这个方案被Altman和Ilya等人拒绝了。他们坚持OpenAI必须保持独立——不能成为任何公司的附属品。
2018年2月,马斯克离开了OpenAI董事会。官方理由是"避免与Tesla的AI开发产生利益冲突"。但真正的原因更复杂——据后来披露的内部邮件和法庭文件,马斯克曾试图争取对OpenAI的控制权,在收购提议被拒后选择了离开。他的离开带走了一个关键的资金来源,直接加速了OpenAI向商业化转型的紧迫性。在一段时间内,双方关系看似友好——马斯克继续担任顾问角色,推荐的Shivon Zilis加入了OpenAI董事会。
马斯克的离开制造的资金缺口,在2019年被一个决定性的合作伙伴填补——微软。
2019年7月,微软向OpenAI投资10亿美元,双方签署了一份改变AI产业格局的协议:微软成为OpenAI的独家云计算提供商,为OpenAI在Azure上共同设计和构建专用的AI超级计算集群;作为回报,微软获得了将OpenAI技术商业化的优先权。为了接受微软的投资,OpenAI创建了"有限盈利"子公司——投资回报上限为100倍。
微软提供的不仅仅是钱——更关键的是算力基础设施。微软Azure团队与OpenAI紧密合作,构建了前所未有规模的GPU集群:数千块NVIDIA AI优化GPU通过NVIDIA Quantum InfiniBand高速网络互联,形成了当时世界上最强大的AI训练平台之一。2020年,微软宣布为OpenAI建造了全球排名前五的超级计算机。微软Azure产品负责人后来回忆说:"OpenAI需要的基础设施规模是史无前例的——比行业中任何人尝试过的GPU集群都要大出一个数量级。"正是这个超级计算基础设施,让GPT-3的1750亿参数训练成为可能,让GPT-4的万亿级参数成为现实。没有微软的算力,GPT系列的规模化路线根本无法执行。
2023年1月,微软宣布追加投资——据报道总额约100亿美元,使其对OpenAI的累计投资达到约130亿美元。这次投资伴随着更深层的商业整合:微软将ChatGPT整合进Bing搜索,将GPT-4嵌入Microsoft 365 Copilot、GitHub Copilot等核心产品线。OpenAI的技术成为微软挑战Google的核心武器。但这种深度绑定也带来了紧张——2023年6月,微软急于将GPT-4整合进Bing,OpenAI内部对过早发布表达了担忧。
2023年11月的"宫斗"事件让这种紧张达到了顶点。董事会突然解雇Altman时,微软事先完全不知情——这让微软CEO Nadella极为不满。微软的反应速度惊人:几乎立即宣布愿意雇佣Altman和所有愿意跟随的OpenAI员工。超过700名OpenAI员工签署联名信威胁集体辞职。在这场短短几天的危机中,微软展示了它作为OpenAI"最后救生艇"的角色——如果董事会不让步,OpenAI的核心团队可以整体搬到微软。这种底牌最终帮助Altman在几天内回归,但也暴露了OpenAI对微软的深层依赖。事件之后,微软获得了OpenAI董事会的观察员席位(后于2024年7月主动放弃)。
与此同时,马斯克与OpenAI的关系从疏远走向了全面对抗。2023年,当ChatGPT成为现象级产品、OpenAI估值飙升时,马斯克开始公开抨击OpenAI背离了非营利使命。2023年7月,他创立了自己的AI公司xAI,直接与OpenAI竞争。2024年3月,马斯克正式起诉OpenAI,指控其"欺诈"和"背叛创始协议"——随后撤诉,又在8月以更多指控重新起诉,包括将微软也列为被告。马斯克的核心主张是:他基于"OpenAI将永远是非营利组织"的承诺投入了3800万美元和大量时间精力,而OpenAI背弃了这个承诺。2025年2月,马斯克甚至提出了974亿美元的"收购要约"——被Altman拒绝。截至2026年初,这场诉讼已进入陪审团审判阶段,马斯克的损害赔偿专家估计其索赔金额高达780亿到1350亿美元。OpenAI则将诉讼定性为马斯克为其竞争对手xAI争取优势的"骚扰策略"。
OpenAI也在逐步减少对微软的独家依赖。2024年夏天,OpenAI与Oracle达成了云计算合作——虽然名义上是微软同意的"例外",但实际上标志着独家关系的松动。2025年1月,OpenAI参与了Stargate项目——与Oracle、SoftBank合作的5000亿美元AI基础设施计划。2025年10月,OpenAI在一轮66亿美元的融资中估值达到5000亿美元,成为全球最有价值的私营公司。同月完成的公司重组中,微软持有OpenAI盈利部门约27%的股份(价值约1350亿美元),OpenAI则承诺向微软采购2500亿美元的Azure服务——双方关系从"投资人-被投资方"演变为更对等的"战略合作伙伴"。
从非营利实验室到估值5000亿美元的科技巨头,OpenAI的十年蜕变是一部关于理想主义与现实主义碰撞的故事。马斯克代表了最初的理想主义愿景——开放、非营利、造福人类;微软代表了让这个愿景在现实中落地所必需的资源和商业化路径。二者缺一不可,又注定产生张力。Anthropic的成立(第九章)本身就是这种张力的产物——它代表了一批研究者对OpenAI路线的"用脚投票"。而马斯克创立xAI并起诉OpenAI,则是另一种形式的"用脚投票"。这场关于AI应该由谁控制、为谁服务的争论,远未结束。
这一章告诉我们什么
OpenAI的故事有几个值得记住的启示。
第一,技术路线的坚定比单次突破更重要。从GPT-1到GPT-5.4,OpenAI始终坚持"Transformer解码器+Scaling"的基本路线——当BERT的编码器路线风头正劲时没有动摇(第五章),当RL在游戏上失去热度时也保留了RL能力(后来用于InstructGPT和o1)。这种战略定力最终回报巨大。
第二,"最后一公里"可能比"核心技术"更重要。GPT-3和ChatGPT的核心技术差异很小(主要是RLHF对齐和对话界面),但产品影响力天差地别。在AI领域,把一个"可用"的技术变成一个"好用"的产品,价值可能比技术本身更大。
第三,能力和人格是两个独立的维度。GPT-5发布时的用户反弹表明,一个更聪明但缺乏个性的模型不一定比一个稍逊色但更有温度的模型更受欢迎。这个发现正在深刻影响所有AI公司的产品策略。
第四,开放vs封闭的选择没有对错——只有取舍。OpenAI从"开放"走向"封闭"遭到了很多批评,但封闭让它获得了巨大的商业成功。2025年GPT-OSS的发布则显示,OpenAI在竞争压力下开始重新拥抱部分开放——开放和封闭并非非此即彼,而是可以组合使用的策略工具。
第五,迭代速度本身就是竞争力。GPT-5系列在七个月内完成了五次重大升级(5→5.1→5.2→5.3→5.4),迭代周期从年度缩短到月度。在这种节奏下,任何单一模型的领先优势都是暂时的——真正的护城河不是某一个模型有多强,而是一家公司持续进化的速度有多快。
第六,即使是OpenAI,也不是从一开始就看清了终局。OpenAI最初押注的是强化学习和机器人,花了两年时间和大量资源去打Dota 2和训练机械手。从RL到GPT的转向、从非营利到"有限盈利"的挣扎、创始人出走、董事会政变、与马斯克反目——这条路上充满了误判、内斗和方向修正。没有任何一家公司是沿着一条笔直的道路走到今天的。对于正在进入AI领域的创业者和从业者来说,这可能是最重要的启示:你不需要在第一天就看清全貌,你需要的是在不断试错中找到对的方向,然后坚定地走下去。
GPT系列的七年编年史讲完了"先发者"的故事。但2025年最震动世界的AI事件不来自OpenAI——而来自一家中国公司。它用OpenAI十分之一的资源,走出了一条完全不同的路径。
本章引用论文
[1] Improving Language Understanding by Generative Pre-Training (GPT-1), 2018, OpenAI (Radford et al.)
[2] Language Models are Unsupervised Multitask Learners (GPT-2), 2019, OpenAI (Radford et al.)
[3] Language Models are Few-Shot Learners (GPT-3), 2020, OpenAI (Brown et al.)
[4] Evaluating Large Language Models Trained on Code (Codex), 2021, OpenAI (Chen et al.) — 交叉引用第七章
[5] Training Language Models to Follow Instructions with Human Feedback (InstructGPT), 2022, OpenAI (Ouyang et al.)
[6] GPT-4 Technical Report, 2023, OpenAI
[7] GPT-4o System Card, 2024, OpenAI
[8] GPT-5 System Card, 2025, OpenAI
[9] Update to GPT-5 System Card: GPT-5.2, 2025, OpenAI
[10] OpenAI o1 System Card, 2024, OpenAI — 交叉引用第十章
[11] GPT-5.3-Codex System Card, 2026, OpenAI
[12] Introducing GPT-5.4, 2026, OpenAI
第十三章:DeepSeek现象——效率优先的中国路径
2025年1月27日,美国股市经历了AI时代最惨烈的一天。
纳斯达克市值蒸发超过1万亿美元。NVIDIA单日暴跌17%,市值蒸发近5900亿美元——美国股市历史上单只股票最大的单日市值损失,比2024年9月NVIDIA创下的上一个纪录(2790亿美元)翻了一倍还多。Broadcom暴跌17%,AMD下跌6%,微软下跌2%。数据中心概念股、能源概念股、芯片概念股全线崩塌。引发这场金融地震的不是任何一家美国公司的财报爆雷,而是来自杭州的一家成立不到两年的创业公司——DeepSeek。
硅谷知名风险投资人Marc Andreessen在推特上写下了一句后来被反复引用的话:"DeepSeek R1是AI的'斯普特尼克时刻'。"——1957年苏联发射第一颗人造卫星,让美国意识到自己在太空竞赛中可能已经落后。68年后,一个来自中国的AI模型让硅谷再次体验了这种震惊。
一颗种子:从量化基金到AGI梦想
2023年4月14日,一篇题为《幻方新征程》的公众号文章悄然发布。文章引用法国导演特吕佛的名言——"务必要疯狂地拥抱雄心,同时要疯狂地真诚"——宣布杭州量化投资公司幻方量化正式进入大模型领域。这篇文章至今只有8000多阅读量。距离DeepSeek-R1震动全球,还有647天。
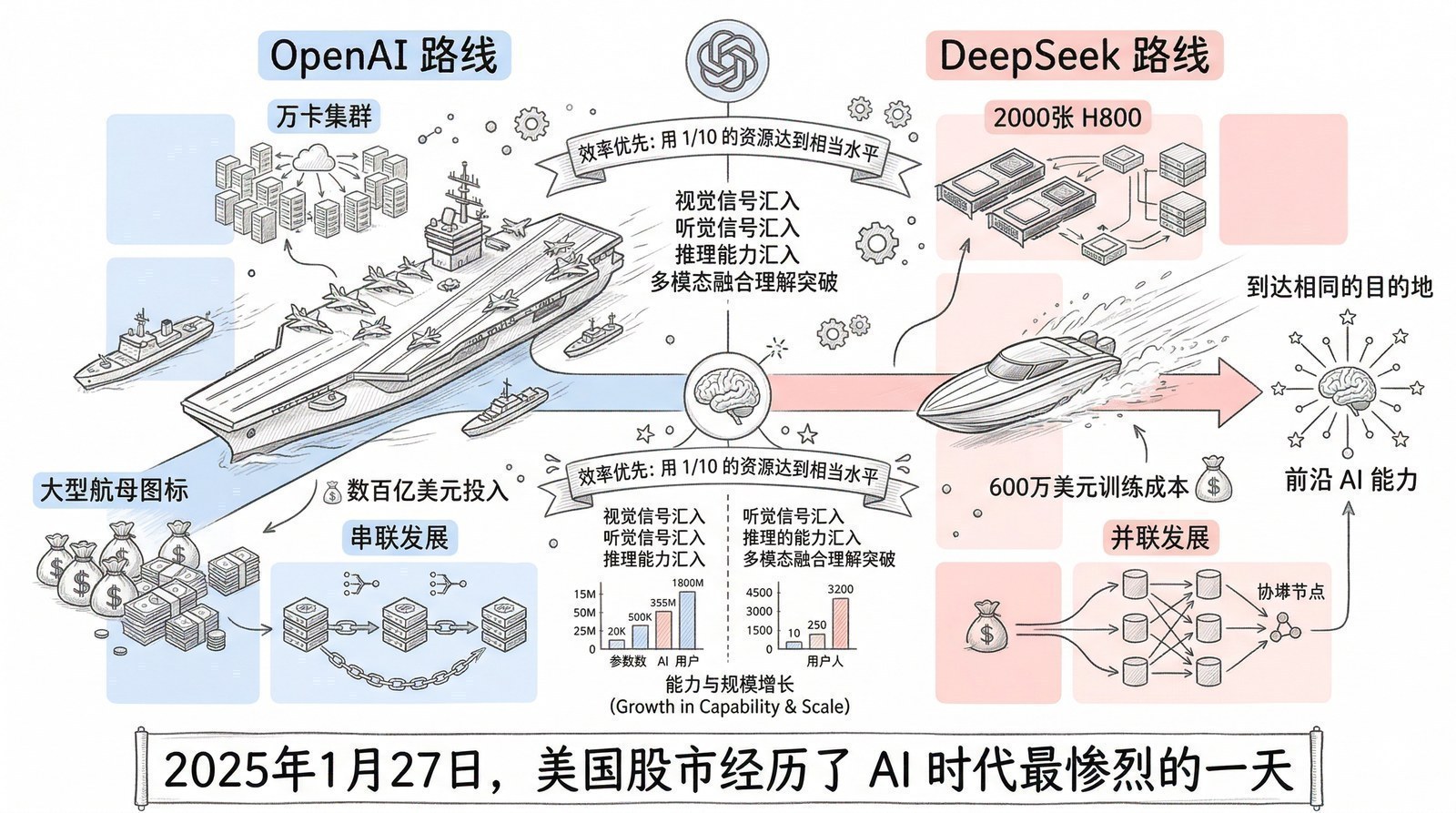
幻方量化是中国头部的量化对冲基金,管理数百亿资产。量化基金的核心竞争力就是"用数学和算力换钱"——多年来幻方持续投入建设领先的AI硬件基础设施,积累了两项别人很难同时具备的资源:大量的GPU算力和深厚的分布式计算工程能力。如果训练大模型是建摩天大楼,大多数AI创业公司有设计图纸(算法论文)但缺施工队和建材(GPU和工程能力)。幻方多年来一直在"盖楼"——只不过盖的是金融模型。现在,它要用同一套施工队盖一座新楼。
另一方面,幻方"相对不差钱"。量化基金的商业模式是用算法从金融市场中赚取超额收益——幻方多年来持续盈利,积累了充裕的资金储备。这意味着DeepSeek不需要像大多数AI创业公司那样急于融资、急于推出产品、急于证明商业模式。它可以在一个相对宽松的环境中专注做基础研究——不必为季度KPI焦虑,不必为投资人写商业计划书,不必在技术成熟之前就匆忙推出半成品。这种"既有钱又有耐心"的状态,在2023年的中国AI创业圈中几乎是独一无二的。
事实上,DeepSeek从一开始就凑齐了做大模型最重要的三要素:钱(幻方的持续资金支持)、算力经验(多年运营大规模GPU集群的实战积累)、顶级人才(做量化交易本身就需要世界级的数学和算法能力——幻方团队中不乏数学竞赛金牌、顶尖高校博士和资深系统工程师)。在大模型领域,这三要素缺一不可:有钱没有算力经验,花了钱也训不好模型;有算力没有顶级人才,架构创新无从谈起;有人才没有资金耐心,还没出成果就弹尽粮绝。幻方的独特之处在于,三者都是内生的、多年积累的——而不是靠一轮融资从外部临时凑齐的。
2023年5月,媒体"暗涌"采访了幻方创始人梁文锋。梁说:"我们希望更多人,哪怕一个小app都可以低成本去用上大模型,而不是技术只掌握在一部分人和公司手中,形成垄断。"这番话在当时几乎无人注意——事后看来,它精准预告了DeepSeek后来的路线:极致低成本、完全开源、让每个人都用得起。
2023年7月17日,"杭州深度求索人工智能基础技术研究有限公司"正式注册。全称中两个关键词——"基础技术"和"研究"——表明这不是一家瞄准应用的公司,而是从第一天就定位在底层技术。注册资本仅1000万人民币,初始团队仅4人。
对比同期的OpenAI:数千名员工、来自微软的130亿美元投资、全球最强的GPU集群。但"小而专注"给了DeepSeek大公司不具备的优势:没有历史包袱,没有组织惯性,可以从零设计最高效的技术路线。
在接下来的647天里,DeepSeek将沿着五条平行的产品线同时推进——基座模型、代码、数学、多模态、推理——最终汇聚成R1的爆发。这五条线的故事,是一条效率至上的登山路线。
五条线的交响:从V1到R1的技术积木
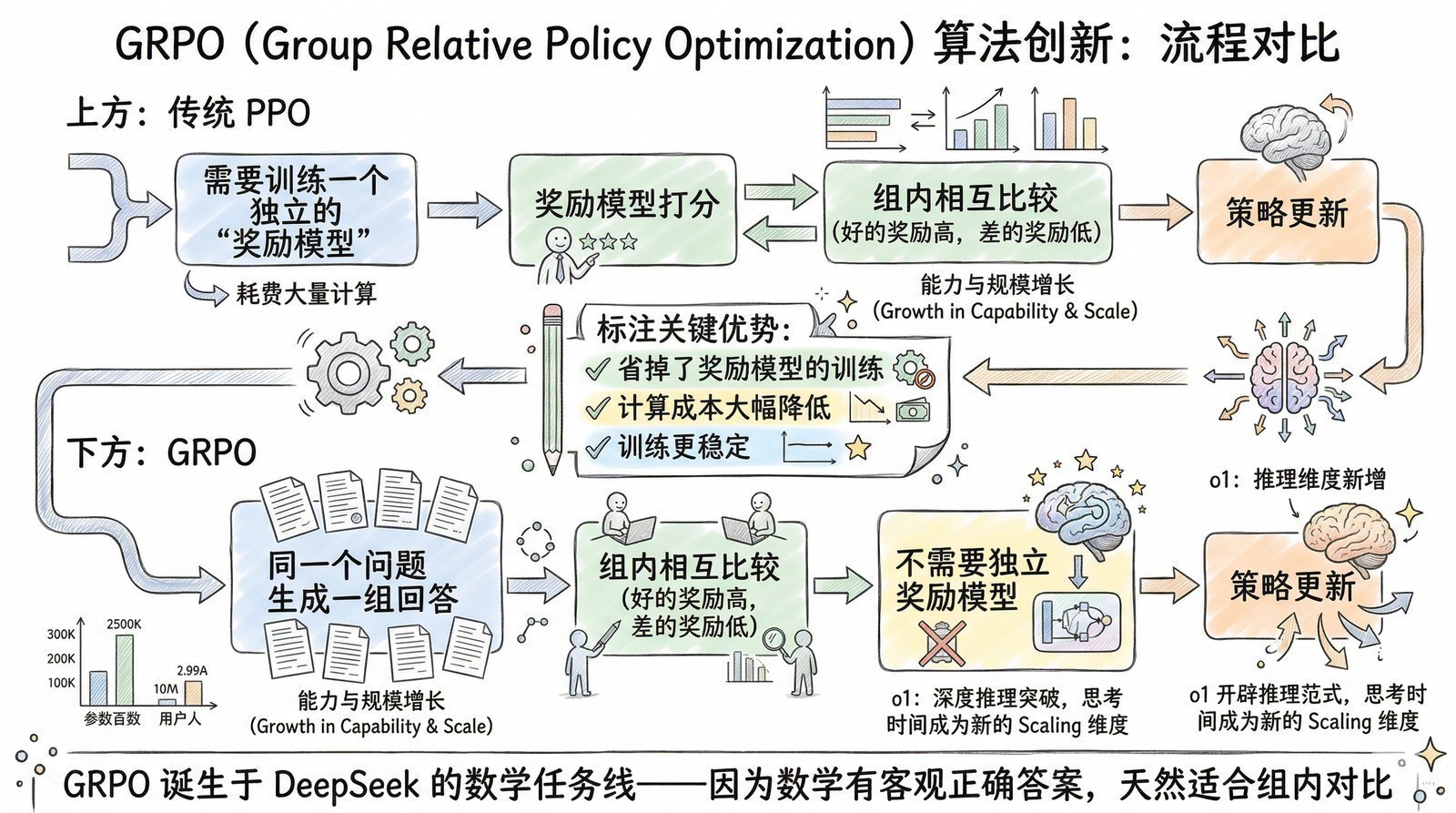
对照:OpenAI的"串联"vs DeepSeek的"并联"
要理解DeepSeek技术演进的独特之处,先要回顾第十二章讲到的OpenAI路径。OpenAI的发展是"串联"式的:GPT-1→GPT-2→GPT-3→Codex→InstructGPT→ChatGPT→GPT-4→o1——每一代是上一代的直接延续和放大。Codex是GPT-3微调出来的,InstructGPT是GPT-3加RLHF,GPT-4是GPT-3.5的规模升级。整条线围绕一个核心模型展开,像一棵树从主干上长出枝条。
DeepSeek的发展是"并联"式的:五条产品线——基座、代码、数学、多模态、推理——几乎同时推进,每条线独立解决特定领域的问题,但每一项创新都被设计成可以"回流"到主干。代码模型Coder探索了仓库级代码训练方法,数学模型DeepSeekMath发明了GRPO算法,定理证明模型Prover发展了Self-instruct和蒸馏方法论,多模态模型VL验证了视觉编码器的集成——这些创新最终全部汇入V3和R1。像一条河流的多条支流,最终在入海口汇成汹涌的洪流。
这种"并联"策略的好处是:每条线可以用较小的模型(7B-67B)快速验证想法,成功了就集成到主干上,失败了损失也很小。OpenAI每次迭代都是在万亿参数的主干上直接操作,成本高、周期长、容错率低。DeepSeek在支流上做小规模实验,验证通过再搬到大模型上——这本身就是一种"效率优先"的研发策略。
第一条线:基座模型——从跟跑到自研架构
基座模型是所有其他产品线的地基。DeepSeek的基座线经历了三代演进:V1(2023年11月)→V2(2024年5月)→V3(2024年12月),每一代都引入了关键的架构创新。
V1-67B[2]是DeepSeek的第一个通用大语言模型,论文标题中有一个意味深长的词——"Longtermism"(长期主义)。这个词不是学术界常见的术语,放在论文标题中显得格外醒目——它更像是一份宣言。
这份宣言的含义在技术路线上体现得淋漓尽致。2023年底的中国AI产业,绝大多数团队在做什么?赶进度。用LLaMA的现成架构加上中文数据快速微调出一个"中国版ChatGPT",抢先发布、抢占用户、抢融资。而DeepSeek在做什么?从最底层、最基础的多头注意力机制开始优化——从定理、公式、算法、工程实现上进行系统优化。V1的论文花了大量篇幅讨论Scaling Law的最优超参数配比、学习率调度策略、数据配比实验——这些都是"短期看不到回报、长期奠定地基"的基础工作。
这种选择背后是创始人梁文锋的格局和眼光。当行业里所有人都在追逐"最快出产品"的时候,梁文锋选择了一条更慢但更扎实的路——先把基础问题搞清楚,再去做上层建筑。这种"反共识"的判断需要极大的自信和定力:你必须相信,今天在基础研究上多花的每一个月,未来都会以十倍的速度回报。事实证明他是对的——V1中对注意力机制和Scaling Law的系统研究,直接催生了V2中MLA和MoE的原创性突破,而这些突破最终成为了R1的核心架构。
V1借鉴了LLaMA的微观架构(第九章),但宏观设计完全不同:67B模型采用了罕见的95层深度(LLaMA-65B是80层),并引入了GQA(分组查询注意力)来加速推理。
GQA的原理可以用办公室的比喻来理解。标准多头注意力中,每个"查询员"(Query)都有自己专属的"档案柜"(Key和Value)——32个查询员需要32个档案柜,占用大量空间。GQA让每4个查询员共享一组Key和Value——32个查询员只需要8个档案柜。信息几乎没有损失,但空间和检索时间大幅减少。
V1只是热身。半年后的V2-236B[5]才是真正的分水岭——它标志着DeepSeek从"借鉴别人的架构"转向"发明自己的架构"。V2有两项原创性的架构创新,都成为了后来V3和R1的核心。
第一项是MLA(Multi-head Latent Attention,多头潜注意力)。要理解MLA,先要理解"KV缓存"。大模型生成回答时,每生成一个新词都需要"回忆"之前的所有内容——这个"回忆"需要存储大量中间结果,就是KV缓存。对话越长,KV缓存越大。在128K上下文的模型中,KV缓存可以轻松占用几十GB显存——甚至超过模型参数本身。这就像写长论文时桌面堆满了参考资料,桌面面积成了写作速度的瓶颈。
MLA的解决方案是"压缩记忆"——不直接存储完整的Key和Value矩阵,而是联合压缩成低维的"潜在表示",需要时再解压。就像把桌面上的参考资料全部拍照存进平板电脑——桌面空间大幅释放,需要查阅时在平板上找到就行。压缩和解压增加一点计算量,但节省的内存是数量级的。
第二项是DeepSeekMoE[3]——自研的混合专家模型架构。为什么DeepSeek在这个时间点(2024年1月,R1发布前375天)要做MoE?因为V1的经验暴露了一个尖锐的矛盾:要达到GPT-4的性能,参数量必须够大(数百亿甚至万亿);但DeepSeek的GPU远少于OpenAI,根本负担不起每次推理都激活全部参数的Dense模型。MoE是解决这个矛盾的钥匙——让模型"知识存量"很大,但每次"调用"的计算量很小。
MoE的核心思想可以用一个大型律师事务所来类比。一家国际律所有200名律师,分布在公司法、知识产权、劳动法、税法等几十个专业方向。当一个客户带着一个合同纠纷来了,前台(路由器)判断这个案子主要涉及公司法和知识产权,就把案子分给这两个方向的律师——其余198名律师不参与这个案子,也不需要支付他们的工时费。律所的"知识存量"是200名律师的总和,但每个案子的"服务成本"只是2-3名律师的工时。MoE模型也是如此:R1总参数671B(200名律师),但每次推理只激活37B(2-3名律师)——仅5.5%的参数参与计算,但能调用的"知识"覆盖了全部671B。
DeepSeekMoE相比Mixtral(第九章)有两个关键创新。第一是"细粒度专家分割"——Mixtral有8个大专家,DeepSeekMoE把它们拆成了更多更小的专家(比如64个甚至更多)。用律所的比喻:与其设8个"大部门"(公司法部、诉讼部……),不如设64个"精准专业组"(上市公司股权争议组、跨境并购合规组……),这样每个案子可以被更精确地匹配到最相关的专家组。实验表明:DeepSeekMoE 2B在12个基准上超过了GShard 2B(Google的MoE方案),DeepSeekMoE 16B用约40%的计算量就达到了与DeepSeek 7B和LLaMA2 7B相当的性能——计算资源减少超过一半,性能不降。
第二是"共享专家隔离"——一部分参数设为所有问题都会经过的"公共通道"。类比:律所有些工作不论什么案子都需要做——文件检索、合同模板准备、法规数据库查询——这些交给"共享服务中心"统一处理,不走专家路由。这样既保证了基础能力(所有案子都能获得基本的法律支持),又让专家组可以专注于各自的专业方向。
这里要澄清一个常见误解:MoE的"专家"和人类的专家完全不一样。人类专家有明确的专业领域——你知道一个心脏外科医生擅长什么。但MoE中的"专家"是训练中自动形成的,每个专家学到了什么对人类来说是不可理解的黑箱。你只能观察到"某些token经常被路由到专家3和专家7",但很难解释为什么。这也是为什么MoE的路由机制如此关键——它需要在不理解专家"内心"的情况下做出最优的分配决策。
MoE对开源社区的影响是深远的。在DeepSeekMoE之前,MoE主要被Google内部使用(Switch Transformer等),开源社区几乎没有成熟的MoE实践。DeepSeekMoE连同后来Mistral的Mixtral,共同把MoE从"大厂专属技术"变成了"开源标配架构"——2025年之后几乎所有追求性价比的大模型都采用了MoE。
V2在8.1万亿token上预训练,性能超过所有开源模型,直逼GPT-4——激活参数仅21B。更重要的是,V2的后训练实验证实了一个关键发现:RL数据比SFT数据效果明显更好——用强化学习让模型自我优化,比人工标注训练数据效果更好。这坚定了DeepSeek全面拥抱RL的决心,也让团队下定决心专门构建了一个RL训练框架——这直接催生了后来的GRPO。
但V2的MoE训练中暴露了一个新问题:专家负载不均衡。回到律所的比喻:如果80%的案子都涌向公司法组,知识产权组几乎无事可做——公司法组的律师累得要命、知识产权组的律师闲得发慌,整体效率很低。之前的解决方案是"丢弃溢出的案子"——当某个专家已经满负荷时,多余的token就不处理了。这提高了训练效率(不会因为某个专家卡住而拖慢整个流程),但损失了精度。
2024年8月,DeepSeek用Auxiliary-Loss-Free Load Balancing[8]解决了这个问题。新方法相当于给律所安装了一个"智能接案系统":它实时监控每个专业组的工作量,如果公司法组排队太长就自动调低它的接案优先级,后续案子更倾向于被分配到其他组。关键是,这个调整不会干扰律师的正常工作——不会因为负载均衡而让律师分心或降低工作质量。这个"无损负载均衡"直接提升了V3和R1的训练质量,也被开源社区广泛采用。
2024年12月27日,V3[9]发布——集大成之作。671B参数,激活37B,集成了此前所有创新:MLA、MoE负载均衡、GRPO、FP8混合精度训练、DualPipe双向流水线、Multi-Token Prediction(MTP)。
MTP值得单独解释。传统模型每次只预测"下一个词"——给定"今天天气",预测下一个词是"很"。MTP让模型同时预测"下一个词"和"下下一个词"——给定"今天天气",同时预测"很"和"好"。这个改变看似简单,但对训练效果有显著提升——模型被迫"看得更远",不能只靠眼前的几个字来猜测,必须理解更长的上下文和更深层的语义。用写作来类比:如果你只需要猜下一个字,"今天天"后面跟"气"几乎是确定的。但如果你要同时猜后面两个字,你就必须理解整个句子的意思——是在谈天气预报还是在形容心情。MTP还有一个附带好处:它可以用于推理加速——模型一次吐出两个token,推理速度理论上可以提升接近一倍。
FP8混合精度训练也需要解释。通常大模型用BF16(16位浮点数)训练——每个数字用16个二进制位来表示。FP8把精度压缩到8位——就像用更粗的刻度尺量东西。好处是显存占用理论上减半、计算速度理论上翻倍。坏处是精度降低可能导致训练不稳定——如果你用厘米刻度尺量零件,1cm和1.5cm的差距还看得清;但如果换成10cm刻度尺,就量不准了。V3是第一个在如此大规模上成功使用FP8训练的模型——通过精心设计的数值缩放策略,在不损失训练稳定性的前提下实现了巨大的效率提升。开源周Day 3公布的DeepGEMM就是让FP8真正跑出理论极限性能的核心代码。
V3训练仅用2048块H800 GPU、约两个月、成本不到600万美元——而GPT-4训练成本估计超过1亿美元。
V3论文还透露:它利用了R1-lite(R1早期版本)的推理数据做二次微调。V3和R1是相互喂养的"共生"关系。
V3和R1的关系值得展开讨论。V3于2024年12月27日发布,R1于2025年1月20日发布——仅相隔24天。但这不意味着R1是V3之后才开始做的。实际上,R1的研发和V3是并行推进的:R1-lite(R1的早期实验版本)在V3训练的中后期就已经在内部运行了。V3论文中明确提到,在后训练阶段引入了"基于R1-lite的推理数据"来增强V3在开放性问题上的推理能力——也就是说,R1的推理能力反哺了V3的通用能力。反过来,R1本身是在V3-Base(V3的预训练基座)之上做的强化学习——V3-Base的强大基座能力是R1能够"涌现"出推理行为的前提条件。
用一个比喻来说:V3是一个博学的"通才",什么都知道一点但不会深入推理;R1是在这个通才基础上通过强化学习训练出来的"思考者"——它继承了V3的全部知识,但额外学会了一项V3没有的能力:在回答之前先"想一想"。而R1"想"出来的高质量推理过程,又被拿来训练下一个版本的V3,让通才也变得更善于推理。这种"通才孵化思考者、思考者反哺通才"的循环,是DeepSeek技术路线中最精妙的设计之一。
V3为R1提供的具体技术铺垫包括:①MLA注意力机制——让R1在长链推理(经常需要回看前面的推理步骤)时不会因为KV缓存爆掉而崩溃;②MoE架构——让671B参数的模型以37B的推理成本运行,使得大规模RL训练在有限GPU上成为可能;③MTP(Multi-Token Prediction)——让基座模型具备更强的"前瞻"能力,为后续的长链推理打下基础;④FP8混合精度和DualPipe——让整个训练流程的成本降到可控范围内。没有V3的这些架构和工程创新,R1的RL训练根本跑不起来——或者说,跑得起来但成本会高到无法承受。
对比OpenAI的基座线:GPT-1→GPT-4,每一代主要靠"堆更多参数和数据"——参数从1.17亿涨到约1万亿。这是"规模优先"的路线。DeepSeek每一代引入新的架构创新(GQA→MLA→MoE→负载均衡→MTP),靠"更聪明的设计"在更少资源下达到同等性能。这是"效率优先"的路线。
第二条线:代码——仓库级理解与首次超越GPT
代码线是DeepSeek最早切入的领域,也是第一个产出"超越GPT"成果的方向。
DeepSeek-Coder[1](2023年11月)是公司注册仅四个月后发布的第一个模型——13亿到330亿参数系列,2万亿token训练。关键创新是在代码仓库层面组织训练数据:模型不只看单个文件,还看整个项目中文件之间的调用关系。这就像培养程序员不是让他看孤立的函数,而是让他看完整个项目——数据如何流动、模块如何协作。结果:一个刚成立四个月的公司的第一个模型,在多项基准上就超越了Codex和GPT-3.5。
Coder-V2[7](2024年6月)是首个开源百亿级以上代码模型,基于V2的MoE架构,支持338种编程语言和128K上下文,性能极度逼近GPT-4。巧的是:仅4天后,Anthropic发布了Claude 3.5 Sonnet——后来成为代码模型长期冠军。两个团队在完全不同的路径上几乎同时抵达同一个前沿。
代码线对R1的贡献超越"代码能力"本身——它从根本上塑造了DeepSeek对"什么是推理"的理解。DeepSeekMath[4]的研究发现:代码训练有助于提升数学推理,而学术论文帮助不大。这个发现乍看违反直觉——论文里满是数学公式,为什么对数学推理没帮助?
答案藏在"推理"这个词的本质里。数学推理不是"知道定理",而是"会用定理一步一步推导出新结论"。论文中的数学内容更多是"陈述"已有的结论——"由定理3.2可得"——但不展示推导的过程。而代码天然就是一种推理过程的完整表达:每一行代码都必须在逻辑上正确才能运行,变量之间的依赖关系就像数学证明中的因果链条,if-else分支就像定理证明中的分情况讨论,for循环就像数学归纳法。更重要的是,代码有一个数学论文不具备的天然优势——它可以被执行和验证。一段代码跑通了就是对的,报错了就是错的,没有模糊地带。这为强化学习提供了完美的奖励信号——也正是后来R1训练中"让模型写代码→运行→通过就奖励"这个循环的基础。
从更深的层面看,代码训练教会了模型三种对推理至关重要的能力:第一,严格的逻辑链条——每一步必须从上一步逻辑推出,不能跳步;第二,状态追踪——代码执行过程中变量的值在不断变化,模型必须在"脑中"追踪这些变化,这和数学推理中"追踪已知条件的变化"是同构的;第三,调试和纠错——程序员写代码最常做的事就是"跑一下→看哪里错了→改一下→再跑",这种"生成→验证→修正"的循环,正是R1在推理中展现的"Aha Moment"("等等,让我重新想想")的雏形。
这就是为什么代码和数学成为了衡量模型推理能力的两大支柱——它们本质上是同一种能力(严密的逻辑推导)的两种表达形式。DeepSeek的代码线和数学线从一开始就是为推理能力服务的——虽然在名义上它们是"垂直领域"的模型,但在技术路线上它们是通向R1的必经之路。
第三条线:数学——GRPO的诞生地
数学线表面上是"垂直领域"探索,实际上却是R1最核心训练方法论的发源地。
DeepSeekMath[4](2024年2月)的最大贡献不是数学能力本身,而是发明了GRPO(Group Relative Policy Optimization)——后来成为V3和R1训练的核心RL算法。
为什么DeepSeek在这个时间点需要一个新的RL算法?因为V2的实验已经证明"RL比SFT效果更好",但当时业界标准的RL方法——OpenAI的PPO——对资源的需求极为夸张。要理解GRPO的革命性,需要先理解PPO有多"贵"。
PPO需要同时维护四个组件:①策略模型(正在训练的模型)——相当于正在考试的学生;②参考模型(原始未训练的模型)——相当于"原来的自己",用来确保训练不要偏太远;③奖励模型(评估回答质量的模型)——相当于阅卷老师;④价值模型(估计未来收益的模型)——相当于一个"预估师",预测这个学生未来大概能考多少分。做一次RL训练要在GPU上同时加载四个大模型——如果每个模型是671B,光是加载到内存中就需要天文数字的GPU。
GRPO的核心创新是去掉价值模型。用考试评分类比:PPO给每个学生配一个"预估师",先预估能考多少分,再把实际分数和预估分数的差距当改进信号——"你这次考了80分,预估你能考75分,所以你比预期好5分,奖励!"GRPO的做法完全不同:给同一道题让一组学生(比如16个)同时答卷,直接在组内比较——"这16份答卷里你排第3名,答得比大多数人好,奖励!"不需要"预估师",直接用组内排名。
这个改变看似简单,效果却很大。第一,减少约25%的GPU内存需求(不需要加载价值模型)。第二,训练更稳定——价值模型本身需要训练,如果它估计不准,整个RL训练的信号就会偏差;GRPO完全跳过了这个不确定性。第三,性能不降反升——实验表明GRPO在数学推理任务上超过了PPO。
没有GRPO就没有R1——在H800而非H100的资源限制下做671B参数模型的大规模RL训练,每减少25%的内存需求都是生死攸关的。GRPO论文发布后迅速被开源社区广泛采用,成为2024-2025年最受欢迎的RL训练方法之一,多个开源项目(如OpenRLHF、TRL等)都增加了GRPO支持。
DeepSeek-Prover系列[6][14](2024年5-8月)进一步为R1铺路。定理证明是个小众领域——用Lean形式语言严格证明数学定理——但贡献了两个关键方法。第一是"Self-instruct":训练数据不够时,让模型自己出题自己做,做对的(用Lean验证器判定)加入训练集。第二是"蒸馏冷启动":用强大模型为弱模型生成高质量思维链标注,作为训练起点——像经验丰富的老师为学生写解题范例。两个方法后来都直接出现在R1的训练流程中。
Prover-V1.5还创造了"数学问题+自然语言推理(CoT)+验证器状态反馈"的三元组训练数据结构。在R1中,"Lean验证器"被替换成了数学答案正确性检查和代码运行结果——训练逻辑完全一致。
第四条线:多模态——视觉编码器的探索
多模态线是五条线中和R1关系最"远"的一条,但体现了DeepSeek"全面布局、不押单一赛道"的策略。
DeepSeek-VL[11](2024年3月)是第一个视觉语言模型,1.3B和7B两个版本,采用混合视觉编码器,以DeepSeek LLM为基础构建。DeepSeek-VL2[12](2024年12月)升级到MoE架构,融入MLA,推出Tiny/Small/27B三个版本——证明MLA和MoE可以从文本扩展到多模态。
多模态线目前的发展阶段可以类比为DeepSeek基座线的V1时期——有了基本框架,但还没有达到V2/V3那种令人惊艳的效率突破。视觉模型的架构与V3/R1系列联系不大——更像独立的探索方向。这再次说明"并联"策略的特点:每条线独立推进,有的成为主线核心组件(如数学线的GRPO),有的则处于"蓄势待发"的状态。
截至2025年底,行业对DeepSeek下一代模型(V4或R2)最大的期待,恰恰集中在多模态和推理能力的融合上。V3/R1系列的明显短板是:R1只能处理文本,无法"看"图片、"听"音频、"看"视频——而竞争对手如GPT-4o和Gemini早已实现了多模态推理。如何把R1级别的深度推理能力和多模态感知能力结合到一个统一的模型中——让模型不仅能"想"还能"看着想"——这可能是DeepSeek下一个里程碑式突破的方向。多模态线的前期积累(VL和VL2的视觉编码器设计经验、MoE在多模态中的验证),将在这个融合中发挥关键作用。
第五条线:推理——五线汇聚
五条线的汇聚点在2025年1月20日——DeepSeek-R1[10]发布。
R1的核心原理已在第十章详细讲述,这里从"五线汇聚"的视角做一个完整总结。R1的训练分为两个阶段,体现了两种截然不同的哲学。
第一阶段是R1-Zero——纯粹的"放手让模型自己学"。直接在V3-Base(671B参数的预训练基座)上做大规模RL,不给任何人类编写的推理样本,不告诉模型"好的推理过程长什么样"——只给数学题,答对了奖励,答错了惩罚。这就像一个教练把学员扔进泳池里,不教任何泳姿,只告诉他"浮起来就给糖吃、沉下去就不给"。经过数千步训练,R1-Zero自发涌现出了令人震惊的推理行为:自我验证(做完一步回头检查)、反思("等等,这一步好像不对")、动态策略切换(一种方法走不通自动换另一种)。在AIME 2024数学竞赛上,准确率从训练前的15.6%跳到了71.0%。DeepSeek的研究者记录了一个"Aha Moment"——训练过程中的某个阶段,模型突然学会了说"让我重新想想"然后回退重试。这种自我纠错能力不是编程进去的,是从RL奖励中自发涌现的。
第二阶段是完整版R1——在R1-Zero的野性基础上加上"教养"。R1-Zero虽然推理能力惊人,但输出混乱(中英文混杂、格式不稳定、有时无限循环)。完整版R1用四步流程解决这些问题:①冷启动SFT——用几千条高质量推理样本(来自Prover线的蒸馏方法)给模型一个"格式模板";②推理RL——和R1-Zero类似的大规模强化学习,但有了更好的起点;③拒绝采样SFT——用前一轮RL生成的好结果做进一步微调;④人类偏好RL——针对有用性和安全性做最后一轮对齐。
R1的几个关键优势使它与众不同。第一,完全开源——MIT许可证,模型权重、训练方法、技术报告全部公开,允许商业化和蒸馏。OpenAI的o1不公开思维链、不公开训练细节、不允许蒸馏——R1在开放性上是o1的反面。第二,蒸馏生态——R1不仅自己强,还可以把推理能力"传授"给小模型。DeepSeek同时发布了基于Qwen和LLaMA架构的蒸馏版本(1.5B到70B),让R1的推理能力可以在手机、笔记本、树莓派上运行。第三,成本——R1的API定价仅为o1的3.6%,本地部署版本完全免费。第四,公开思维链——用户可以看到模型完整的推理过程,这不仅提升了可信度,还催生了"思维链迁移"等创新用法。
但R1不是凭空出现的。它是五条线14篇论文的汇聚:基座线提供了V3这个强大底座(MLA+MoE+MTP);代码线和数学线证明了"代码+数学"是推理两大支柱,并提供了GRPO;定理证明线提供了冷启动和蒸馏方法论;MoE负载均衡[8]保证了大规模训练稳定性;基础设施优化(FP8+DualPipe)让训练成本降到600万美元以内。
用建筑比喻:V3是地基和框架,GRPO是施工方法,Self-instruct和蒸馏是建材供应链,MoE负载均衡是质量管理,FP8和DualPipe是节能系统。每一块不可或缺,合在一起才能盖出R1。
破壳而出:R1发布后的七天震动
R1发布后的七天,是AI历史上信息传播速度最快的一次"破圈"事件。
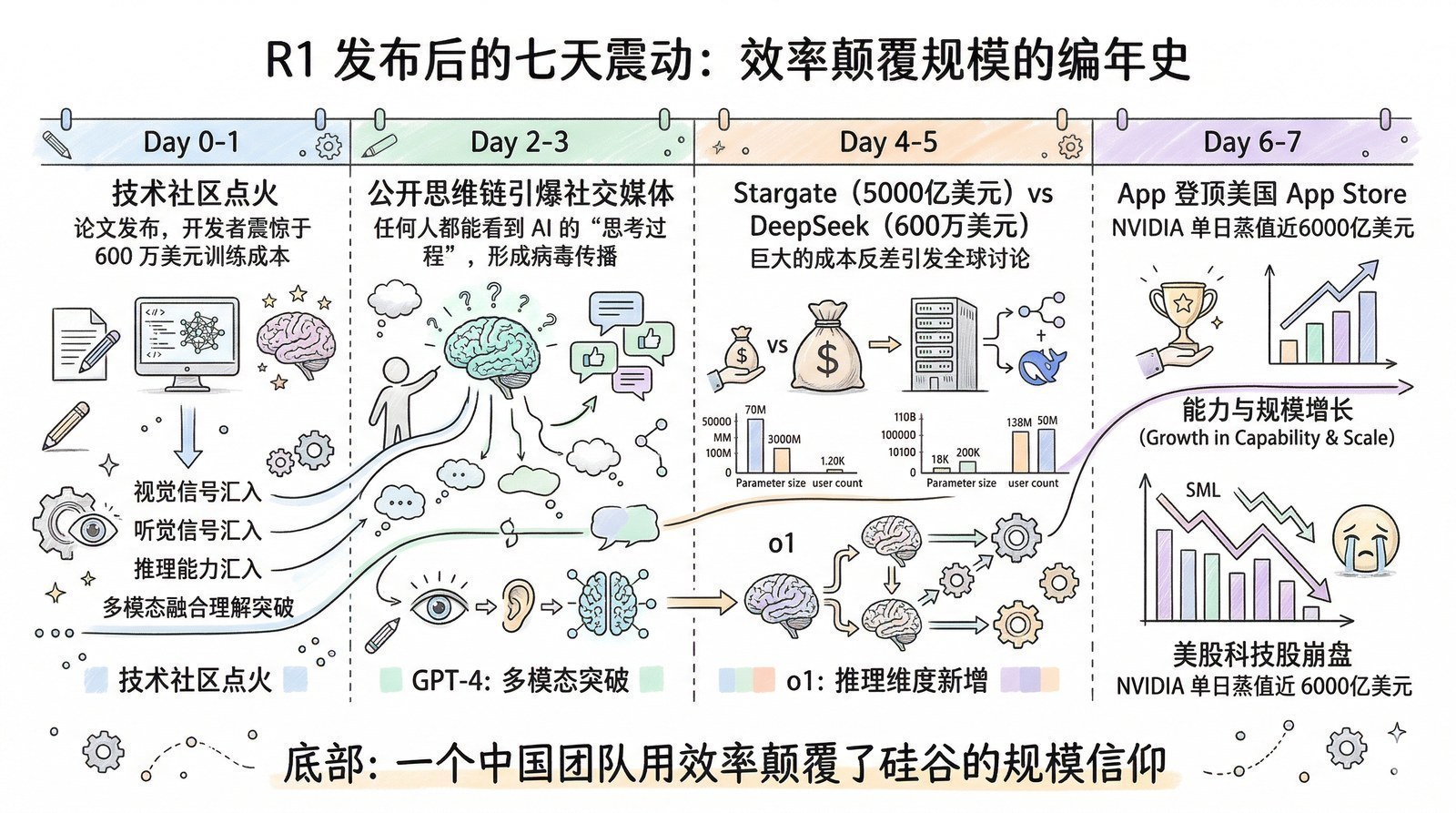
Day 0-1:技术社区点火
发布当天,Jim Fan发出浏览量136.6万的评价:"我们正处在一个非美国公司延续OpenAI原始使命的时代。"ollama当天支持本地部署。
第二天,性价比引爆社交媒体:R1 API价格仅o1的3.6%(每百万输出token 2.19美元 vs 60美元)。有人用7台Mac Mini搭建"家庭版AGI"——496GB统一内存、分布式推理、4位量化。更有人在50美元的树莓派上运行R1蒸馏版,200 token/秒。从200美元/月的ChatGPT Pro到50美元树莓派——这种成本差距是颠覆性的。
Day 2-3:公开思维链与病毒传播
R1和o1的一个关键区别:o1的思维链隐藏,R1的完全公开。有人发现可以提取R1的推理过程发送给任何模型——"像把GPT-3.5变成天才"。多个R1 vs o1-pro对比视频病毒式传播。蒸馏到1.5B的版本在iPhone 16上以60 token/秒流畅运行。
Artificial Analysis确认:R1在所有主流推理基准上与o1平手,但便宜25倍以上。字节跳动紧急发布Doubao-1.5-pro,比DeepSeek还便宜5倍——中国AI价格战迅速升温。
Day 4-5:Stargate vs 600万美元
1月24日,两条新闻形成刺眼对比。特朗普和孙正义宣布5000亿美元Stargate项目——同一天,社交媒体热议DeepSeek用不到600万美元做出同级模型。Scale AI CEO透露DeepSeek拥有约5万块H100,但因出口管制"无法讨论"。
越来越多人问那个要命的问题:"如果击败OpenAI只需600万美元,说明行业商品化速度超出预期。"
Day 6-7:App登顶与市场崩盘
DeepSeek App登上全球苹果商店免费榜第一,超越ChatGPT。"为什么要为ChatGPT付20美元月费,当DeepSeek完全免费?"
1月27日开盘,恐慌性抛售席卷科技板块。NVIDIA暴跌17%、蒸发近5900亿美元——史上最大单日市值损失。纳斯达克总市值蒸发超过1万亿美元。
投资者恐慌有三层逻辑。第一,如果前沿模型600万美元就能训练,美国公司动辄数十亿的AI投资是否过度?第二,如果不需要最先进芯片,NVIDIA最贵GPU需求是否被高估?第三,如果AI模型被商品化——性能相当但价格3%——整条产业链利润率都会被压缩。
黄仁勋后来回应:"市场误以为AI完了。推理是下一个扩展前沿,仍需大量计算力。"他部分正确——NVIDIA股价几周内逐步恢复。但DeepSeek的深层影响是永久性的:它打破了"烧更多钱=更强模型"的等式。
授人以渔:开源周的全栈"交底"
如果R1是炸弹,2025年2月的开源周就是把制造图纸也公开了。
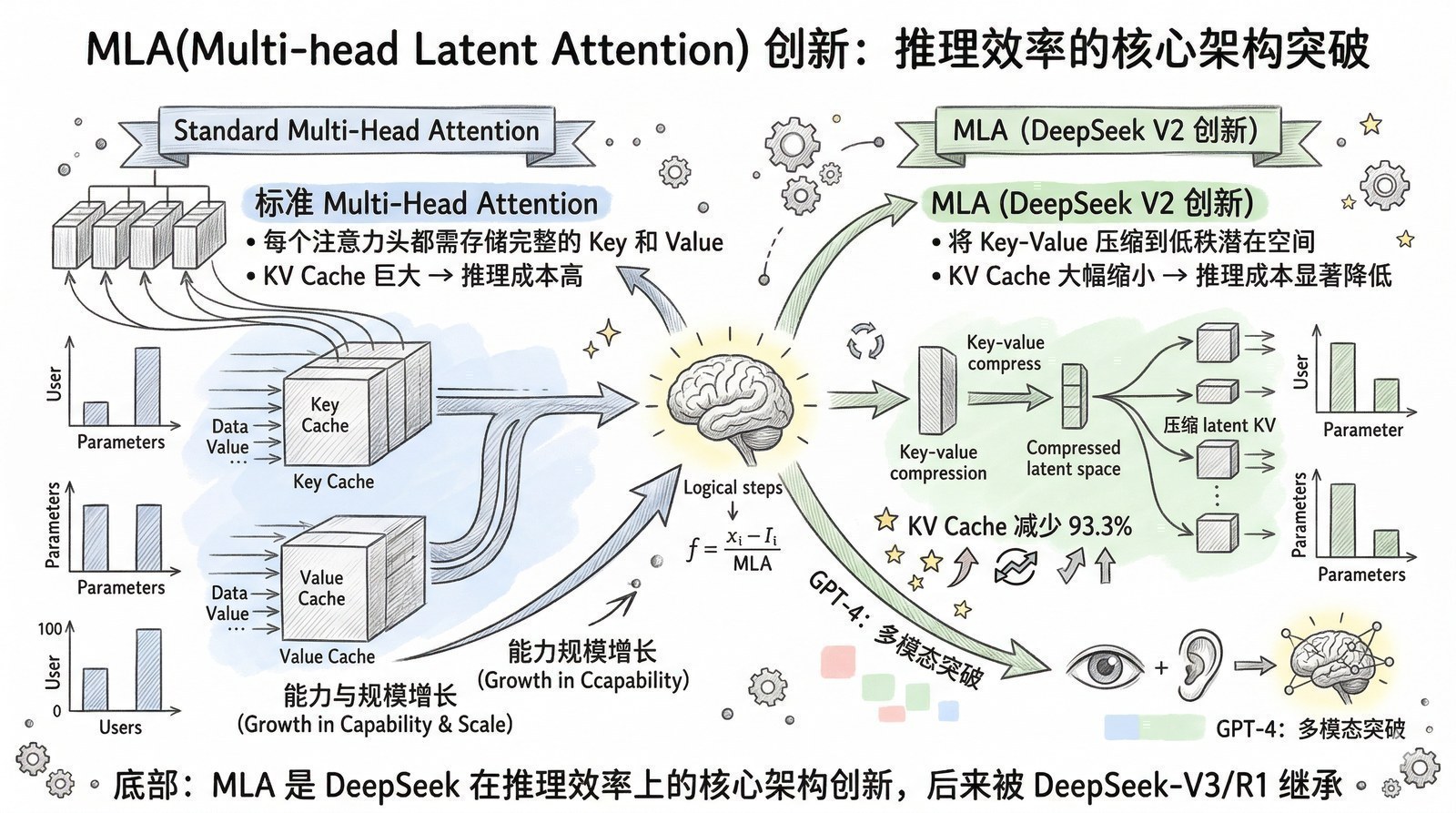
DeepSeek的公告:"没有象牙塔——只有纯粹的车库精神和社区驱动的创新。"社区回应:"DeepSeek is the real OpenAI。"
开源周揭示了一个被算法论文掩盖的事实:DeepSeek不仅在算法上创新,更在从GPU底层到通信框架到存储系统的每一个基础设施层面都做了深度优化。这才是600万美元训练V3的真正秘密。
要理解开源周的真正价值,需要回到第三章和第六章的一个核心论点:大模型的竞争,表面上是算法的竞争,底层是算力基础设施的竞争。再好的模型架构,如果GPU集群调度不好、通信效率低下、存储读写跟不上,训练就跑不起来——或者跑起来了但90%的算力在空转。比开源一个大模型更难的事情,是搭建一个能高效训练大模型的算力集群;而比搭建集群更难的事情,是开发出能让集群发挥出最大效率的软件框架。开源周开放的正是这些"万金难求"的算力基础设施软件——这不是"授人以鱼"(给你一个模型用),而是"授人以渔"(教你怎么训练自己的模型)。
Day 1:FlashMLA——针对Hopper GPU优化的MLA推理解码内核。不是算法论文,是精调的CUDA底层代码——把GPU性能榨取到接近理论极限。借鉴FlashAttention"以算代存"思想(GPU切菜比取食材快,一次性摆上案板减少走冰箱次数),针对MLA低秩压缩做定制优化。H800上实现3000 GB/s显存带宽和580 TFLOPS。
Day 2:DeepEP——首个开源MoE通信库。GPU是发动机,传输带宽是变速箱——V8发动机配2AT变速箱,嚎叫但跑不快。在数千块GPU训练中,通信瓶颈导致GPU空等、数据拥塞、训练崩溃。DeepEP就是给GPU集群配匹配的"变速箱"。
Day 3:DeepGEMM——FP8矩阵乘法计算库。矩阵乘法是大模型中最基本的操作(工厂里的"拧螺丝")。核心逻辑仅约300行代码,却在Hopper上实现1350 TFLOPS——超越GPU厂商专家团队数月调优的内核。极致简洁却极致高效——DeepSeek技术哲学的缩影。
Day 4:DualPipe——双向流水线并行。传统流水线中GPU空等时间("气泡")可占10%-30%。DualPipe从两端同时输入数据,计算与通信完全重叠,气泡率接近零。
Day 5:3FS——高性能分布式文件系统。如果前四天是"大脑"和"神经"优化,3FS是"血液循环"。180节点集群实现6.6 TiB/s聚合读取(约1秒读6700GB,相当于1600部蓝光电影)。
Day 6:One More Thing——V3/R1推理系统全景。每个H800节点每秒处理73.7K输入token和14.8K输出token,成本利润率545%。即使极低定价,仍然利润丰厚。
五天项目被整合成完整拼图:FlashMLA解决显存瓶颈、DeepEP解决通信瓶颈、DeepGEMM提升计算效率、DualPipe优化调度、3FS解决存储。从存储到通信到计算到调度,每层都有专门优化——"授人以鱼"升级为"授人以渔"。
先发者vs后发者:两条路径的深层对照
读完第十二章和第十三章,一个自然的问题浮出水面:OpenAI和DeepSeek,谁的路线更"对"?
答案是:两条路线各自回答了不同的问题。
OpenAI回答的是"如果不计资源限制,AI能走多远?"它的七年路径从无到有探索了预训练→规模涌现→对齐→推理的每一个范式转移,为整个行业定义了什么是"可能的"。没有GPT-3证明规模出奇迹,就不会有Scaling Law信仰。没有InstructGPT证明RLHF有效,就不会有ChatGPT。没有o1证明测试时计算的价值,就不会有R1的纯RL涌现实验。OpenAI是拓荒者——开辟路径,承担全部拓荒成本。
DeepSeek回答的是"在资源受限条件下,效率的极限在哪里?"它站在OpenAI的认知基础上,走出完全不同的实现路径:MoE替代Dense、MLA替代标准KV Cache、GRPO替代PPO、FP8替代BF16、DualPipe替代传统流水线——每个替代都用更少资源实现同等甚至更好的效果。DeepSeek是"效率工程师"——不开辟新路径,但把已知路径上的每一步走到极致。
两条路线在几个维度上形成对照。时间:OpenAI七年(2018-2024),DeepSeek不到两年(2023-2025)——后发者的优势是前人已证明哪些方向可行。规模:OpenAI"规模优先"——参数从1亿到万亿;DeepSeek"效率优先"——通过架构创新让671B只激活37B。开放:OpenAI从开放走向封闭(GPT-1代码开源→GPT-4零细节→o1思维链隐藏),DeepSeek从第一天完全开源。商业:OpenAI需要持续巨额融资支撑规模扩张;DeepSeek以极低成本为基础,通过开源建立生态,API定价低到令竞争对手不安——但仍盈利。
但两条路线不是简单对立——它们互补。DeepSeek能在两年内达到o1水平,很大程度上因为站在OpenAI七年认知基础上。反过来,DeepSeek的效率创新也倒逼OpenAI反思——GPT-OSS(首次开源)和o1-mini都可视为对效率路线的回应。两个路径的共存和竞争,推动了AI整体更快演进。
但两者的产业角色有本质区别。如果说OpenAI发明了大模型、定义了大模型能做什么——它让世界知道了"AI可以像人一样对话、推理、创作"——那么DeepSeek的角色是让大模型真正走进了各行各业。OpenAI的GPT-4 API每百万token收费30-60美元,这个价格对于大型企业和科技公司来说可以接受,但对于教育机构、中小企业、独立开发者、发展中国家的研究者来说,是一道难以逾越的门槛。DeepSeek把同等性能的模型以3%的价格(甚至免费开源)推向全世界——这意味着一个非洲大学的学生可以用和硅谷工程师同样强大的AI工具做研究,一个县城的小企业主可以用AI辅助运营管理,一个独立开发者可以在笔记本电脑上运行推理模型来构建自己的产品。
这种"把顶级技术变成公共基础设施"的角色,在科技史上是有先例的:Linux让服务器操作系统从IBM和Sun的昂贵专有产品变成了免费的公共资源,Android让智能手机从苹果的高端奢侈品变成了全球数十亿人的日常工具。DeepSeek正在对大模型做同样的事——把它从少数公司的"秘密武器"变成所有人都能用的"公共设施"。
涟漪:DeepSeek引发的产业连锁反应
DeepSeek的影响远不止于一家公司的成功——它引发了一系列连锁反应,重塑了2025年的AI产业格局。

R1发布仅两天后(1月22日),月之暗面发布了Kimi k1.5长思考模型。相比R1的技术报告,Kimi k1.5披露了更多的训练细节——包括强化学习基础设施、混合集群、代码沙箱、并行化策略、长上下文处理、链式推理压缩等。Kimi k1.5分为长思维链和短思维链两种模式:长思维链对标o1推理模型,短思维链则兼顾推理和效率。它还提出了一个实用性很强的概念——"long2short",将长思维链模型的知识迁移到短思维链模型中,在有限计算资源下保持推理能力的同时提升效率。这直接回应了推理模型的一个核心痛点:它们经常把简单问题复杂化,强行增加不必要的反思过程,消耗大量token。
2025年3月6日,阿里通义千问发布了QwQ-32B——一个32B参数的dense模型(不用MoE)。在基准测试上,QwQ-32B效果明显优于DeepSeek-R1蒸馏到Qwen-32B和LLaMA-70B的版本,接近R1满血版和o1-mini的水平。32B的dense模型经过量化后可以直接跑在消费级显卡上——这意味着本地就可以部署性能比肩R1的模型。QwQ遵循Apache 2.0协议开源,让个人开发者和小团队能以极低成本接入顶级推理能力。
同一天,Manus智能体发布,将AI Agent的概念推到了空前热度。Manus基于Claude Sonnet构建,配备29种工具,使用browser_use开源项目实现浏览器自动化。虽然褒贬不一,但它的出现标志着行业关注点开始从"更强的模型"转向"更有用的应用"。随后OpenAI发布了Agent SDK,openManus和OWL等开源智能体项目相继涌现。
2025年3月24日凌晨,DeepSeek自己也没有停下脚步——悄然更新了V3-0324版本(685B参数),在数学推理和前端开发方面的表现优于Claude 3.5和Claude 3.7 Sonnet,中文写作能力也有显著提升。仅一小时后,千问又发布了Qwen2.5-VL-32B视觉模型——32B的视觉模型在多项基准上超过了Qwen2-VL-72B。中国AI的创新节奏,已经从"年度发布"加速到了"周级别竞赛"。
与此同时,MCP(Model Context Protocol,模型上下文协议)开始迅速升温。自Anthropic 2024年11月推出MCP以来,这个为大模型和工具之间制定标准API的协议逐渐成为行业热点——因为大家都在琢磨做大模型应用了,而复杂应用动辄集成几十个工具,MCP大幅降低了集成工作量。MCP的升温标志着行业从"训练更强的模型"转向"让模型更好地使用工具"——这是DeepSeek式的效率思维在应用层面的延伸。
永不停歇:从R1到V3.2的持续进化(2025年3月-12月)
R1发布和开源周之后,很多人以为DeepSeek会暂停脚步、享受荣光。事实恰恰相反——2025年的后续十个月,DeepSeek以令人窒息的节奏持续迭代,完成了从"追平o1"到"追平GPT-5"的又一次跨越。这段历程也是DeepSeek"效率优先"哲学的进一步延伸:不是训练一个全新的V4或R2,而是在同一个671B参数的架构上,通过不断改进后训练方法和注意力机制,持续榨取性能。
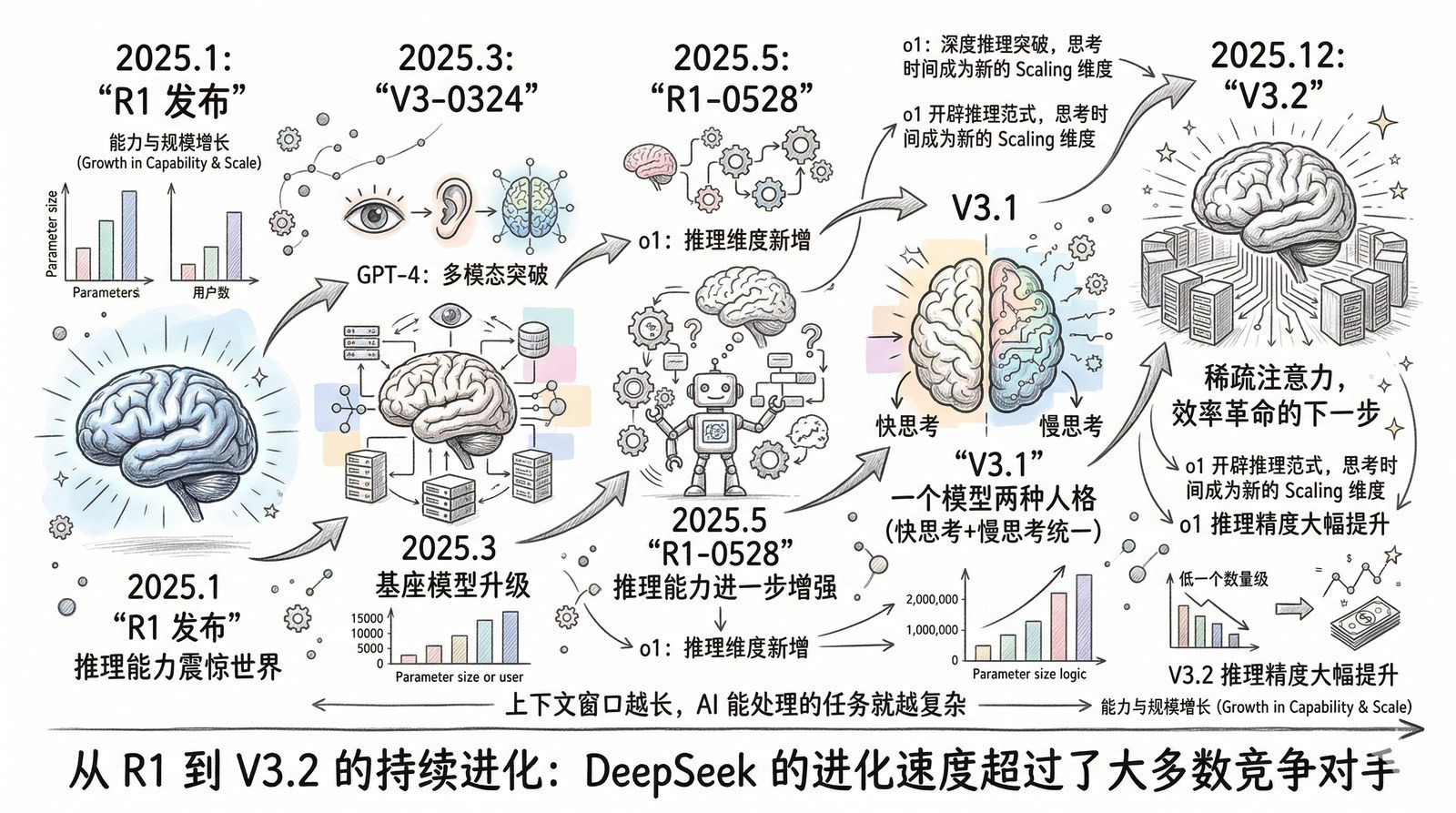
V3-0324与R1-0528:在同一地基上加盖楼层
2025年3月24日凌晨,DeepSeek悄然更新了V3-0324版本。架构和V3完全相同,改进集中在后训练——把R1积累的RL经验反哺回V3的训练流程。效果显著:MMLU-Pro从75.9提升到81.2,AIME从39.6飙升到59.4(提升近20个百分点),前端开发能力在社区测评中超过了Claude 3.5和Claude 3.7 Sonnet。中文写作也有明显提升。这个版本传递了一个重要信号:V3和R1不是两个独立产品,而是一个相互增强的循环——R1的推理训练改善V3的通用能力,V3的通用能力反过来为R1提供更好的基座。
2025年5月28日,R1-0528发布——R1的"小版本升级"。架构不变,但推理质量大幅提升。AIME 2025从70.0跃升至87.5,GPQA从71.5升至81.0,Aider编程基准从57.0升至71.6。幻觉(hallucination)率降低了45%-50%——这是实用性的巨大改善。R1-0528还首次支持了JSON输出和函数调用,让推理模型可以被集成到更复杂的应用流程中。不过代价是:复杂推理任务平均消耗的token从12K翻倍到23K——模型"想得更深"了,但也"说得更多"了。
V3.1:一个模型,两种人格
2025年8月21日,DeepSeek-V3.1发布——这是一个里程碑式的架构决策。V3.1把V3(快速直答)和R1(深度推理)合并成了一个混合模型。用户不再需要在两个模型之间切换——同一个模型可以通过改变对话模板在"思考模式"(thinking,像R1一样展开思维链)和"非思考模式"(non-thinking,像V3一样快速回答)之间无缝切换。
这就像一个员工同时拥有"快速模式"和"深度模式":老板问"今天天气怎么样",快速模式秒答;老板问"这个项目的投资回报率分析",自动切换到深度模式,展开详细推理。用户不需要判断"这个问题该用哪个模型"——模型自己判断。
V3.1在Agent和工具调用方面的提升尤为突出——在SWE-bench和Terminal-Bench上超越了V3和R1超过40%。V3.1的"思考模式"比R1更快更高效:经过链式推理压缩训练,V3.1-Think在保持几乎相同性能的前提下,输出token减少了20%-50%。换句话说,V3.1想的一样好,但说得更精炼。
2025年9月22日,V3.1-Terminus发布——一个"修缮"版本,解决了用户反馈的中英文混杂、偶发乱码和Agent能力不稳定等问题。名字中的"Terminus"(终点站)暗示这是V3.1系列的最终形态。
V3.2:稀疏注意力——效率革命的下一步
2025年9月29日,V3.2-Exp发布——引入了一项全新的架构创新:DeepSeek Sparse Attention(DSA,稀疏注意力)。
要理解DSA的意义,需要回顾一个Transformer的根本性瓶颈。标准的注意力机制让每个token都要"看"所有其他token——如果上下文有128K个token,每个token都要计算与其他128K个token的关联度。计算量随上下文长度的平方增长——上下文翻倍,计算量变四倍。这就像一个班级开会,如果10个人每人都要和其他9个人一对一交谈,需要45次对话;但如果100个人每人都要和其他99个人交谈,需要4950次——人数增加10倍,对话次数增加了100倍。
DSA的解决方案可以比喻为"先浏览目录再精读正文"。它引入了一个轻量级的"闪电索引器"(Lightning Indexer),用极低的计算成本(FP8精度、极少参数)快速扫描所有token,给每个token打一个"重要性分数"。然后,模型只对得分最高的前k个token做完整的注意力计算——其余token被跳过。这把计算复杂度从O(L²)降低到O(L·k),其中k远小于L。在128K上下文中,如果只关注前1%最重要的token,计算量就减少了近100倍。
DSA和之前的MLA是互补的:MLA压缩了每个token的"记忆大小"(KV缓存),DSA减少了需要关注的token数量。两者叠加,让超长上下文的推理效率获得了数量级的提升——这也是为什么V3.2能在API定价上比V3.1再降50%以上。
2025年12月1日,V3.2正式版发布。在DSA的基础上,DeepSeek还做了两件关键的事。
第一,大规模强化学习——RL阶段消耗的计算资源超过了预训练计算量的10%。这在业界是前所未有的比例——之前大多数模型的RL阶段只占预训练的1%-3%。DeepSeek的研究员在社交媒体上写道:"如果说Gemini 3.0证明了持续扩展预训练的价值,那么V3.2-Speciale证明了扩展RL的价值。我们花了一年把V3推到极限,教训是后训练的瓶颈可以通过改进方法和数据来解决,而不是只等一个更好的基座。"
第二,大规模Agent训练数据合成——构建了1800多个不同的环境和85000多条复杂Agent任务指令,涵盖搜索、编程、工具调用等场景。这让V3.2成为DeepSeek第一个将"思考"能力直接整合到工具调用中的模型——它可以在使用工具的过程中展开推理,而不是先想好再调工具。
V3.2的性能进入了前沿领域:AIME 2025达到93.1%,HMMT达到92.5%,SWE-Verified达到73.1%。V3.2-Speciale(放宽长度限制的高计算版本)更进一步——AIME达到96.0%,HMMT达到99.2%,在IMO 2025、CMO 2025、IOI 2025和ICPC World Finals 2025中获得金牌级成绩,性能与Gemini 3.0-Pro持平。
从V3(2024年12月)到V3.2(2025年12月),同一个671B参数的架构,仅用一年时间,通过MLA→DSA的注意力进化、持续扩大的RL训练、越来越丰富的Agent数据合成,性能从"逼近GPT-4o"提升到了"追平GPT-5-High"。这条演进路线本身就是DeepSeek效率哲学的最佳注脚:不急着训练一个参数更大的新模型,而是在已有架构上持续优化——就像赛车手不换车,但通过调校引擎、更换轮胎、优化空气动力学,一圈一圈刷新圈速。
DeepSeek的647天历程,有几个值得记住的启示。
第一,"并联研发"可以大幅加速创新。同时推进五条产品线,每条线用较小模型快速验证,成功创新汇入主干——"多条支流最终汇成洪流"。对资源有限的团队来说,"小规模快速验证,成功后再放大"比"一开始就做最大规模"更理智。
第二,算法创新和工程优化是一体两面。大多数AI公司只做算法,把底层优化留给NVIDIA。DeepSeek同时在两个层面创新——不仅造了更好的发动机(MLA、MoE),还自己造了变速箱(DeepEP)、铺了公路(3FS)、调校了悬挂(DualPipe)。
第三,资源约束可以催生创新。芯片出口管制的本意是遏制,但MoE、MLA、GRPO、FP8——这些创新需要数学直觉和工程功力,不是"有钱有GPU就能想出来的"。
第四,开放是竞争策略,不仅是价值观。DeepSeek的完全开源让全世界开发者成为其生态的一部分,极低定价逼迫所有竞争对手降价或开源。一家公司用开源策略重塑了整个行业的价格结构和竞争规则。
第五,即使是DeepSeek,也不是从一开始就看清终局。第一篇论文是3D内容生成——和后来的LLM方向几乎无关。就像OpenAI最初花两年做Dota 2,顶级AI机构也需要试错。重要的不是起点方向是否正确,而是能否在试错中快速收敛到正确路径。
为什么是幻方DeepSeek?
在讲完DeepSeek的技术路径之后,一个更深层的问题值得探讨:为什么是幻方量化的DeepSeek,而不是百度、阿里、腾讯、字节跳动这些拥有更多资源和人才的互联网巨头,也不是清华、北大这些拥有顶尖研究者的学术机构,做出了中国AI领域最具全球影响力的突破?
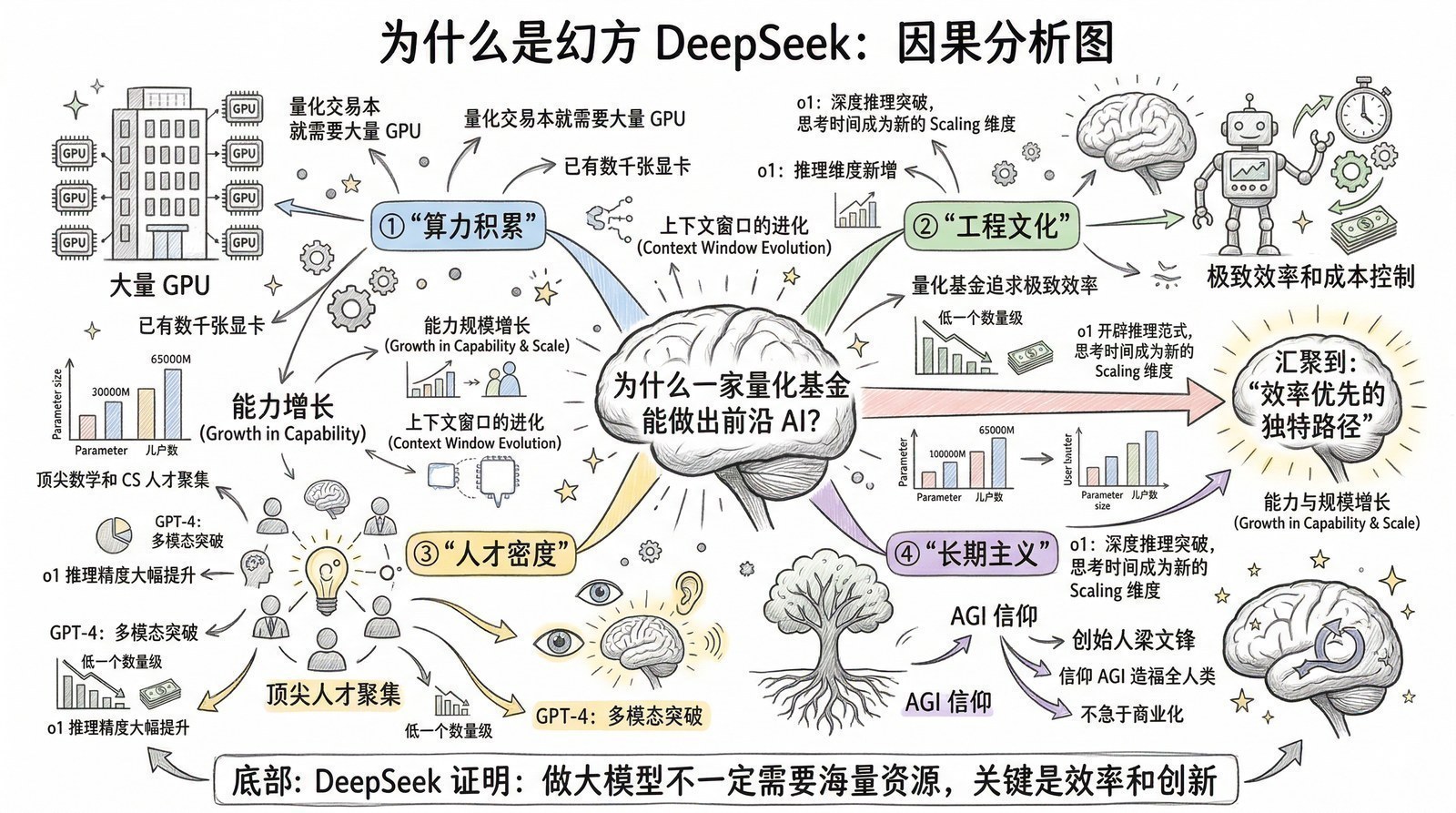
这个问题的答案,可能比任何技术细节都更值得从业者思考。
第一个原因是"无包袱"。互联网大厂做大模型,天然背负着庞大的组织惯性和商业压力。百度要考虑文心一言如何服务搜索和云业务,阿里要考虑通义千问如何对接电商和企业服务,腾讯要考虑混元大模型如何融入微信生态。这些商业考量不是坏事——它们推动了大模型的落地和变现——但它们会让技术团队的注意力分散在"如何满足业务需求"上,而不是"如何从底层做出最优的技术架构"。DeepSeek没有任何现有业务需要服务,没有任何产品线需要兼顾,公司名字里的"基础技术研究"不是装饰——它真的可以把100%的精力投入到底层技术探索上。
第二个原因是"算力基因"。幻方量化不是一般意义上的"有GPU"——它从2019年前后就开始自建大规模GPU集群,先后打造了多代"萤火"(Firefly)系列算力集群。萤火系列从最初的几百块GPU起步,逐步扩展到数千块甚至上万块的规模,运行着幻方自研的分布式训练和推理框架。多年来,幻方的工程师们在这些集群上日复一日地训练量化交易模型——处理GPU之间的通信瓶颈、解决分布式训练中的各种故障、优化存储系统的读写效率、调试大规模并行计算中层出不穷的bug。这些经验是在几千块GPU上真刀真枪练出来的,不是读论文能学到的。
开源周的五个项目(FlashMLA、DeepEP、DeepGEMM、DualPipe、3FS)清楚地展示了这种积累的深度:从GPU底层的CUDA内核优化到跨节点通信到分布式存储——每一个都带着"在真实集群上踩过无数坑"的痕迹。DeepEP论文中对NVLink和RDMA两种通信模式的深度优化、3FS对SSD和RDMA网络的极限利用、DualPipe对流水线气泡的精确消除——这些不是几个月的项目能做出来的,而是多年运营大规模集群的经验结晶。
大厂虽然也有GPU集群,但它们的集群主要用来跑推荐系统、广告系统、搜索引擎——这些应用的计算模式(大量小模型并行推理)和大模型训练(少数超大模型的分布式训练)有本质区别。学术机构虽然有顶尖的算法研究者,但通常缺乏管理和优化大规模GPU集群的工程能力——一个教授的实验室可能有8块A100,但从8块到2048块的跨越不是数量上的线性增长,而是质变。幻方量化的独特之处在于,它的日常业务就是"在大规模GPU集群上训练复杂的AI模型"——这和训练大语言模型的核心工程挑战几乎完全重叠。萤火系列集群的经验,直接催生了DeepSeek在算力基础设施上的全栈优化能力。
第三个原因是"效率至上的文化基因"。量化基金的商业逻辑是"用更少的计算成本获得更高的投资回报"——每一分算力都必须产生实际的经济价值,浪费是不可容忍的。这种文化基因被直接移植到了DeepSeek:MoE架构(只激活5.5%的参数)、MLA(压缩记忆以节省显存)、GRPO(去掉价值模型以减少内存)、FP8(把精度压缩一半以加速计算)——每一项创新的核心驱动力都是"如何用更少的资源做同样的事"。这不是在资源充裕之后的锦上添花式优化,而是一开始就把"效率"当作首要设计原则。大厂因为资源相对充裕,往往不会被迫走到这个极致——它们可以直接加更多GPU来解决性能问题,而不必费力设计更高效的架构。
第四个原因是"创始人的技术信仰"。梁文锋不是职业经理人,不是投资人,而是一个技术出身、靠算法和工程建立起数百亿基金的创始人。他对"基础技术研究"的执念——公司名字就叫"基础技术研究有限公司"——不是商业包装,而是真实信仰。这种信仰让DeepSeek在没有明确商业回报路径的情况下,敢于投入14篇论文系统性地构建底层技术组件——从注意力机制到MoE到RL算法到基础设施,每一步都是长期主义的选择。大厂的KPI考核体系和短期业绩压力很难支撑这种"先花两年做基础研究、不着急出产品"的路线。
这四个因素——无包袱、硬件基因、效率文化、技术信仰——共同解释了为什么是一家量化基金的衍生公司,而不是资源远更丰厚的大厂或学术声望更高的高校,做出了这个突破。这也给了中国AI产业一个重要启示:决定AI竞争胜负的不是资源的绝对量,而是资源的使用效率和组织的专注程度。
DeepSeek对中国AI的深远意义
DeepSeek的意义不仅仅是"一家中国公司做出了世界级模型"——它从根本上改变了中国AI产业的自我认知和发展路径。
第一,从"跟跑"到"并跑甚至领跑"的心理转折。在DeepSeek之前,中国AI产业的主流叙事是"追赶"——美国有GPT-4我们也要有、美国有RLHF我们也要做、美国有MoE我们也要学。技术路线上跟着OpenAI走,数据和中文化是差异点。DeepSeek证明了另一种可能:不是在别人定义的赛道上追赶,而是用自己发明的方法(MLA、GRPO、DeepSeekMoE)走出一条效率更高的路。R1发布后,全球AI社区第一次大规模地在学习和复用一家中国公司的原创技术创新——这不是"追赶",而是"输出"。
第二,大幅降低了中国AI创业和研究的门槛。R1的完全开源(MIT许可证)加上开源周的全栈基础设施,意味着任何中国团队——从大厂到创业公司到高校实验室——都可以站在DeepSeek的肩膀上起步。不需要从零摸索MoE的通信瓶颈怎么解决,不需要自己发明注意力机制的优化方法,不需要花几个月调试FP8的数值稳定性——DeepSeek已经把这些最难的工程问题都解好了,代码就在GitHub上。这种"公共基础设施"级别的开源,对整个中国AI生态的加速效应是巨大的。
第三,改变了芯片制裁的叙事逻辑。美国芯片出口管制的前提假设是:中国缺乏顶尖芯片就无法训练顶级模型。DeepSeek用H800(而非H100或H200)训练出了匹配o1的模型,这个事实本身就是对这个假设的最有力反驳。它向全世界展示了:在芯片受限的条件下,算法创新和工程优化可以在很大程度上弥补硬件差距。这不仅影响了中国AI产业的信心,也影响了美国政策制定者对出口管制效果的评估——如果限制芯片出口反而催生了更高效的技术路线,那这个政策的实际效果可能与初衷相反。
第四,加速了大模型从"技术研究"到"产业渗透"的进程。R1的极低成本(API价格仅o1的3.6%)引发的价格战,不仅影响了AI公司之间的竞争,更从根本上降低了各行各业使用AI的经济门槛。当推理模型的使用成本从每百万token 60美元降到2美元时,大量原本"算不过账"的应用场景突然变得经济可行了——教育、医疗、法律、制造业中那些本来嫌AI太贵的中小企业,现在可以用极低的成本接入世界级的推理能力。DeepSeek式的成本结构,可能比模型性能本身更深刻地推动AI在中国经济中的渗透速度。
第五,重新定义了开源在AI竞争中的角色。在DeepSeek之前,中国的开源大模型更多是"开源权重"——把模型文件放出来让别人用。DeepSeek的开源是"全栈开源"——从模型权重到训练方法到基础设施代码到运营数据,把整个技术栈从上到下全部公开。这种彻底的开放策略在短期内看似"把竞争优势拱手让人",但实际上建立了一种更强大的护城河:当全世界的开发者都在用你的MLA、你的GRPO、你的DeepEP来构建他们的系统时,你就成为了事实上的技术标准——而制定标准的人,永远比遵循标准的人走在前面。
DeepSeek用647天证明了效率可以弥补资源不足,开源可以重塑竞争格局,"长期主义"的技术积累可以产生爆炸性成果。但DeepSeek不是孤例——它是全球AI开源运动中最耀眼的一颗星,但绝非唯一。从Meta的LLaMA到Mistral到阿里的千问,从月之暗面到QwQ-32B,一幅更宏大的全景画卷正在展开。
本章引用论文
[1] DeepSeek-Coder: When the Large Language Model Meets Programming, 2023, DeepSeek-AI
[2] DeepSeek LLM: Scaling Open-Source Language Models with Longtermism, 2023, DeepSeek-AI
[3] DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models, 2024, DeepSeek-AI
[4] DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models, 2024, DeepSeek-AI
[5] DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model, 2024, DeepSeek-AI
[6] DeepSeek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic Data, 2024, DeepSeek-AI
[7] DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence, 2024, DeepSeek-AI
[8] Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts, 2024, DeepSeek-AI
[9] DeepSeek-V3 Technical Report, 2024, DeepSeek-AI
[10] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, 2025, DeepSeek-AI — 交叉引用第十章
[11] DeepSeek-VL: Towards Real-World Vision-Language Understanding, 2024, DeepSeek-AI
[12] DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding, 2024, DeepSeek-AI
[13] DreamCraft3D: Hierarchical 3D Generation with Bootstrapped Diffusion Prior, 2023, DeepSeek-AI
[14] DeepSeek-Prover-V1.5: Harnessing Proof Assistant Feedback for Reinforcement Learning and Monte-Carlo Tree Search, 2024, DeepSeek-AI
第十四章:群星闪耀——开源大模型全景图与产业格局
2025年2月,全球AI竞赛的格局在一个月内发生了两次地震。
1月20日,来自杭州的DeepSeek发布R1,以不到OpenAI o1三十分之一的训练成本达到了同等推理水平——纳斯达克单日蒸发1万亿美元市值,NVIDIA暴跌17%。全世界刚刚从这场冲击中回过神来,2月18日,马斯克的xAI发布Grok-3,声称在数学和科学推理上超越了所有现有模型——背后是一座拥有20万块GPU的超级计算集群,从动工到运行只用了122天。同一个月,Google更新了Gemini 2.0,Anthropic的Claude在开发者社区的口碑持续走高,阿里的Qwen悄然刷新了多项开源模型基准纪录。
两年前,AI世界只有一个名字——OpenAI。现在,ChatGPT不再是唯一的选择,甚至不再是很多场景下的最优选择。从硅谷到巴黎、从北京到杭州,至少八个中心在同时闪耀,每一个都代表着截然不同的技术路线、商业逻辑和价值信念。
第一部分:大模型群雄谱——从一家独大到群星闪耀
2023年初的AI世界只有一个中心:OpenAI。到2025年底,这个中心已经裂变成了至少八个。
每一家大模型公司的崛起,都不是偶然的——它背后站着一群特定的人,带着特定的技术积累、价值观和商业判断。理解这些公司,不能只看它们的基准测试分数,更要看它们的"基因"——创始团队从哪里来、为什么要做这件事、选择了什么样的技术路线和商业策略。下面我们逐一展开。
Google Gemini:巨人的觉醒
在所有大模型公司中,Google的故事最具讽刺性——Transformer是Google发明的(第四章),但ChatGPT却是OpenAI做出来的。Google拥有发明注意力机制的团队、全世界最大的搜索数据、自研的TPU芯片集群、以及DeepMind这个全球最顶尖的AI研究实验室——但在2022年末ChatGPT横空出世时,Google的内部产品还停留在实验阶段。CEO桑达尔·皮查伊(Sundar Pichai)后来承认,ChatGPT的发布在Google内部引发了"红色警报"(Code Red)。
Google的"慢"不是因为技术不行,而是因为它太成功了——第五章讲过的"创新者的窘境"在这里再次上演。Google搜索每年带来超过1500亿美元的广告收入,任何可能"颠覆搜索"的产品都会在内部遇到巨大的阻力。一个能直接给出答案的AI助手,本质上是在蚕食Google搜索的核心商业模式——用户不需要点击十个蓝色链接了,AI直接告诉你答案。让Google主动拥抱这种变化,就像让一个年收入千亿的公司主动革自己的命。
2023年4月,Google做了一个关键的组织决策——将Google Brain和DeepMind合并为Google DeepMind,由DeepMind联合创始人、2024年诺贝尔化学奖得主德米斯·哈萨比斯(Demis Hassabis)担任CEO,Google传奇工程师杰夫·迪恩(Jeff Dean)担任首席科学家。这次合并结束了两个顶级AI团队多年来的内部竞争和资源重复,集中力量对抗OpenAI。
2023年12月6日,Gemini 1.0发布——这是合并后Google DeepMind的第一个重大产品。Gemini从第一天起就选择了一条和GPT不同的技术路线:原生多模态(Natively Multimodal)。GPT-4的多模态是"后加"的——先训练一个文本模型,再接上视觉编码器。Gemini则从预训练阶段就同时处理文本、图像、音频和视频,让模型从一开始就在多种模态之间建立联系。这就像培养一个孩子——GPT-4的方式是先教他读书写字,长大后再教他看图听音乐;Gemini的方式是从婴儿期就让他同时接触语言、图像和声音,让多种感知能力自然融合。
Gemini的迭代速度极快。2024年2月,Gemini 1.5 Pro发布,带来了一个让整个行业震惊的数字——100万token的上下文窗口(后来扩展到1000万token)。100万token意味着什么?它可以一次性处理107小时的音频、90分钟的完整视频、超过4万行代码、或者一本1400页的书。在此之前,GPT-4的上下文窗口是12.8万token——Gemini一步把天花板拉高了近8倍。这个超长上下文能力的底层技术是混合专家架构(MoE),让模型在处理极长输入时保持效率。
2024年12月,Gemini 2.0发布,引入了实时多模态交互能力——用户可以通过摄像头和麦克风与AI实时对话,AI能同时"看到"你展示的东西并给出语音回应。2025年3月,Gemini 2.5 Pro发布,在多项推理基准上达到了当时的最高水平。到2025年底,Gemini 3系列登场——Gemini 3 Flash成为Google产品的默认模型,Gemini 3 Deep Think专注于科学和工程领域的深度推理。2026年2月,Gemini 3.1 Pro在SWE-Bench编程基准上达到80.6%——进入了世界最强模型的第一梯队。
Google的核心优势在于分发渠道。全球超过40%的搜索查询已经由Gemini驱动,Gmail、Google Docs、YouTube、Google Maps——Google几乎所有产品都在集成Gemini。这是任何其他大模型公司都不具备的优势:OpenAI需要用户主动打开ChatGPT,但Google可以让AI"无处不在"地出现在用户已经在用的产品里。这种"嵌入式AI"的战略,让Google在用户触达上拥有无与伦比的规模优势。
但Google的劣势同样明显:组织庞大导致决策慢、人才流失严重(Transformer论文的八位作者几乎全部离开了Google,其中多人创办了AI公司)、以及"大公司病"——内部政治和风险规避文化让很多有潜力的产品迟迟无法推出。Google拥有做出最强模型的所有原材料,但能否把这些原材料转化为最好的产品,始终是一个悬而未决的问题。
Anthropic与Claude:安全主义者的逆袭
如果说Google是"发明了技术但没抓住机会",Anthropic则是"因为担心技术太危险而离开,最终却做出了最受开发者喜爱的产品"。
Anthropic的创立故事已在第九章简要介绍。2021年,OpenAI研究副总裁达里奥·阿莫迪(Dario Amodei)和他的妹妹达妮艾拉·阿莫迪(Daniela Amodei,时任OpenAI安全与政策副总裁),带着另外五位OpenAI核心成员集体出走,创立了Anthropic。出走的核心原因是一个深层的哲学分歧:OpenAI在追求更强能力的道路上越走越快,而这群人认为AI安全研究的优先级应该高于能力研究——你应该先搞清楚怎么控制一个超级智能,再去制造它。
达里奥的背景很有意思。他本科学物理,博士在普林斯顿读的是计算神经科学——研究大脑如何处理信息。这种"从生物系统理解智能"的训练,让他对AI系统的内部机制有一种独特的直觉。在OpenAI期间,他主导了GPT-2和GPT-3的研发,亲眼见证了大模型能力随规模增长的"涌现"现象。正是这种亲身经历让他意识到:这些模型的能力增长速度可能超过人类理解和控制它们的速度——这不是科幻小说里的假设,而是他在实验室里每天观察到的现实。
Anthropic的核心技术创新是Constitutional AI("宪法AI",第九章已介绍基本原理)。传统的RLHF需要大量人类标注者来判断"哪个回答更好",这个过程成本高、标准因人而异、难以规模化。Constitutional AI的核心思路是:给模型一套明确的原则("宪法"),让AI自己根据这些原则来评判和改进回答。这套原则可以被公开审查和迭代——就像一个国家的宪法可以被修正。
Claude模型的迭代路径很有启发性。2023年3月Claude 1发布时,它只是一个"安全但能力平平"的模型——很多用户觉得它过于谨慎,动不动就拒绝回答。2023年7月Claude 2上下文窗口扩展到10万token,开始展现差异化优势。2024年3月Claude 3发布了三个版本——Haiku(轻量)、Sonnet(均衡)、Opus(旗舰)——这种"分层定价"策略成为行业标准。
真正的转折点是2024年6月的Claude 3.5 Sonnet。这个模型在代码生成和复杂推理上的表现让开发者社区炸了锅——一个中等规模、中等价格的模型,在实际编程任务中的表现超过了更大、更贵的GPT-4。到2025年,Claude进一步推出了Claude Code(命令行编程工具)和Claude Cowork(图形界面协作工具),从"聊天机器人"进化为"AI工作伙伴"。2025年5月,Claude Sonnet 4和Claude Opus 4发布,巩固了Claude在代码和推理领域的领先地位。
"安全优先"的公司为什么做出了最强的代码和推理模型?这个看似矛盾的结果背后有深层逻辑。要让模型"安全",你需要理解模型为什么会产生不安全的输出——这需要深入理解模型的内部推理过程。Anthropic在可解释性(Mechanistic Interpretability)研究上投入了大量资源,试图打开模型的"黑箱",理解信息在模型内部如何流动。这些研究不仅帮助了安全对齐,还为能力提升提供了独特的洞察——因为你越理解模型怎么"想",就越能让它"想"得更好。
Anthropic的融资历程也值得关注。从2021年成立到2026年2月,Anthropic的估值从几十亿美元飙升到3800亿美元,完成了300亿美元的G轮融资——这是科技史上第二大私募融资。亚马逊累计投资超过80亿美元,成为最大的外部投资者。这种融资能力证明了一件事:在AI领域,"安全"不是商业的对立面——投资者愿意为"负责任地开发最强AI"支付巨额溢价。
xAI与Grok:硅谷叛逆者的算力暴击
如果说Anthropic代表了"从OpenAI出走的安全主义者",xAI则代表了"对OpenAI心怀不满的硅谷最富有的人"。
2023年3月,埃隆·马斯克(Elon Musk)创立了xAI。马斯克是OpenAI最早的联合创始人和主要资助者之一,但在2018年因董事会控制权争议离开。此后他多次公开批评OpenAI从非营利转向营利、从开源转向闭源的路线——在他看来,OpenAI已经背叛了成立时的初衷。xAI的创立,是马斯克用行动表达不满的方式:既然你们不做"真正的OpenAI",那我来做。
xAI的创始团队几乎是从全球顶级AI实验室"定点挖人"组建的。伊戈尔·巴布什金(Igor Babuschkin)来自DeepMind,吴宇怀(Tony Wu)来自Google DeepMind,克里斯蒂安·塞格迪(Christian Szegedy)是Google Inception网络(第一章)的发明者之一,吉米·巴(Jimmy Ba)是Adam优化器论文的共同作者——Adam是深度学习中被引用最多的论文之一,累计引用超过9.5万次。这支团队在技术实力上不逊于任何一家AI实验室。
xAI的风格和其他公司截然不同——它继承了马斯克一贯的"暴力美学"。2023年11月,Grok-1发布,名字来自科幻小说《银河系漫游指南》(The Hitchhiker's Guide to the Galaxy)——马斯克从不掩饰他对科幻文化的热爱。Grok的人设被设计成"有幽默感、敢说话、偶尔有点叛逆"——和ChatGPT的礼貌谨慎、Claude的温和理性形成鲜明对比。当用户问一些"敏感问题"时,ChatGPT可能会说"我不方便回答这个问题",Grok更可能用一种调侃的方式给出回答。
2024年3月,马斯克做了一件让行业意外的事——将Grok-1完全开源(Apache 2.0许可证)。一个3140亿参数的MoE模型,权重全部公开。这在当时是最大的开源模型之一。马斯克此举的动机很明确:用开源来挑战"CloseAI"(他对OpenAI的讽刺称呼),同时为xAI在开发者社区中建立声誉。
但xAI真正让行业侧目的不是模型本身,而是它的算力建设速度。2024年,xAI在美国田纳西州孟菲斯建造了Colossus——一个拥有10万块H100 GPU的超级计算集群,从动工到运行仅用了122天。到2025年,Colossus扩展到15万块H100加5万块H200加3万块GB200,总规模超过55万块GPU,功耗达到2吉瓦。这个规模远超OpenAI和Google的公开集群——马斯克用SpaceX式的"不计成本、极速执行"风格,在算力上建立了碾压性的硬件优势。
Grok的迭代速度也极快。Grok-2(2024年8月)引入了多模态能力。Grok-3(2025年2月)在多项基准上进入第一梯队。Grok-4(2025年7月)是旗舰版本,具备原生工具调用、实时搜索和多智能体协作能力。
xAI的独特优势是它和X(原Twitter)的深度整合。Grok可以实时访问X平台上的所有公开帖子、讨论和新闻——这意味着它拥有一个其他模型都无法获取的"实时信息流"。当你问Grok"今天科技圈发生了什么",它不是从过时的训练数据中找答案,而是直接检索X上最新的讨论。这种"实时性"在新闻、金融、社交媒体分析等场景中有独特价值。
xAI的劣势同样鲜明:马斯克的个人风格和政治立场让很多企业客户和开发者望而却步;Grok的"叛逆"人设在某些场景下会产生不恰当的回答;团队的稳定性也是问题——核心成员巴布什金和塞格迪分别在2025年离开。到2026年初,xAI的估值已接近2300亿美元,但它能否将算力优势转化为持久的产品竞争力,仍然是一个开放的问题。
Mistral:欧洲的AI旗帜
在硅谷和中国的巨头混战之外,巴黎悄然升起了一面属于欧洲的AI旗帜。
Mistral AI的故事已在第九章介绍过基础背景。2023年4月,阿瑟·门施(Arthur Mensch,前Google DeepMind研究科学家,Chinchilla论文核心作者)、纪尧姆·朗普尔(Guillaume Lample,前Meta FAIR研究员,LLaMA论文共同作者)和蒂莫泰·拉克鲁瓦(Timothée Lacroix,前Meta FAIR研究员)在巴黎联合创立Mistral AI。三位创始人都毕业于法国顶级理工院校——巴黎综合理工学院(École Polytechnique)。他们不仅是论文作者,更是亲手训练过世界级大模型的一线工程师。
第九章已经介绍了Mistral 7B和Mixtral的技术细节。这里我们补充Mistral此后的发展轨迹。
Mistral的产品哲学可以用三个词概括:小而强、快而省、开而精。从Mistral 7B到Mixtral 8x22B,每一代模型都在追求"用更少的参数做到更好的效果"。这种哲学和DeepSeek的"效率优先"异曲同工——不同的是,Mistral的切入点是欧洲市场和多语言能力。Mistral的模型在法语、德语、西班牙语、意大利语等欧洲语言上的表现明显优于同级别的美国模型——这不是偶然的,而是创始团队有意识地在训练数据和评估基准中加大了欧洲语言的权重。
2024年,Mistral进入了全面扩张期。Mistral Large系列面向企业市场,性能直逼GPT-4。Codestral专注代码生成,支持80多种编程语言。Pixtral 12B是开源多模态模型,集成了4亿参数的视觉编码器。2025年6月,Mistral发布了Magistral系列推理模型,加入了"让AI思考"的竞赛(第十章)。
2025年12月,Mistral 3系列发布——Mistral Large 3是旗舰模型,675亿总参数、410亿激活参数,具备多模态和多语言能力,在多项基准上和GPT-4o、Gemini 2正面竞争。同时发布的还有三个不同参数规模的小模型(140亿、80亿、30亿),覆盖从云端到边缘的全场景部署。
Mistral的商业产品Le Chat也值得关注。Le Chat是一个深度可定制的AI助手,速度极快(每秒可生成约1000字),集成了实时网页搜索、语音交互、图像生成、代码解释器等功能。2026年3月,Mistral在NVIDIA GTC大会上发布了Mistral Forge——一个面向企业的定制模型平台,允许企业在自己的私有数据上构建专属AI模型。CEO门施透露,Mistral正朝着2026年超过10亿美元年度经常性收入(ARR)的目标前进。
Mistral的融资轨迹反映了欧洲对"本土AI冠军"的渴望。2023年6月种子轮1.05亿欧元(欧洲AI创业公司纪录),2023年12月B轮3.85亿欧元,2024年6月B+轮6亿欧元,2025年9月C轮17亿欧元(估值117亿欧元,约140亿美元)。C轮由荷兰光刻机巨头ASML领投(持股11%)——一家半导体设备公司投资AI软件公司,这个组合本身就说明了AI对整个科技产业链的渗透之深。到2025年底,三位创始人成为了法国历史上第一批AI领域的亿万富翁。
Mistral对全球AI产业的意义超越了一家公司的成功——它证明了前沿AI不是美国和中国的专利。一个成立仅两年、总部在巴黎的小团队,可以用精良的技术和精准的市场定位,在巨头林立的竞争中占据一席之地。Mistral的存在本身,就是对"AI只能靠砸钱"这个叙事的有力反驳。
DeepSeek:效率至上的中国黑马
DeepSeek的完整故事已在第十三章详细讲述——从幻方量化的"算力转型"到R1震动全球的647天。这里我们将它放进全球产业全景图中,看看它在这张地图上的独特坐标。
在所有大模型公司中,DeepSeek的"出身"最为特殊。其他公司的创始人要么来自学术界(智谱的唐杰、月之暗面的杨植麟),要么来自科技大厂(Anthropic的阿莫迪兄妹出自OpenAI,Mistral的三位创始人出自Google和Meta),要么本身就是科技巨头(Google、字节、阿里)。DeepSeek的母公司幻方量化是一家量化对冲基金——它的核心能力是"用数学和GPU从金融市场里赚钱"。这个背景赋予了DeepSeek三件别人很难同时具备的东西:充裕且有耐心的资金(不需要外部融资,不用为投资人的季度KPI焦虑)、多年运营大规模GPU集群的实战经验(训练金融模型本身就是高性能计算)、以及顶级的数学和算法人才(做量化交易需要世界级的数学能力)。
DeepSeek在这张全景图上的坐标是独一无二的:它是唯一一家完全自筹资金、没有外部投资者、没有上市计划、也没有急于盈利压力的一线大模型公司。这种"与世无争"的状态,让创始人梁文锋可以做出一系列反常识的决策——最重要的一个就是全栈开源。当其他公司用闭源模型的API赚钱,或者有选择地开源部分模型权重时,DeepSeek把一切都公开了:模型权重(MIT许可证,最宽松的开源协议)、训练方法、架构创新(MLA、DeepSeekMoE、GRPO)、甚至底层的工程代码(开源周连续七天公开了从FlashMLA到DeepGEMM的全栈基础设施)。
这种极致开源策略的效果是爆炸性的。DeepSeek-R1发布后,全球AI社区第一次大规模地研究、复现和改进一家中国公司的原创技术。R1的蒸馏生态——从671B到1.5B的全系列蒸馏模型——让推理能力可以在手机和嵌入式设备上运行。到2025年中,基于DeepSeek架构和方法论的衍生模型在HuggingFace上数以千计。DeepSeek不是在"参与"开源运动——它在重新定义开源的边界。
从产品角度看,DeepSeek的差异化在于"用二十分之一的成本做到同级效果"。V3训练仅用2048块H800 GPU、成本不到600万美元,而GPT-4的训练成本估计超过1亿美元。R1的API价格仅为OpenAI o1的3.6%。这种极致的性价比不仅让DeepSeek在中国市场引发了价格战,也让全球的企业客户和开发者开始重新审视"AI一定很贵"的固有认知。DeepSeek的存在证明了一件事:在大模型时代,效率创新的战略价值可能超过规模堆叠——因为效率让更多人用得起AI,而规模只是少数巨头的游戏。
阿里Qwen:从中国走向世界的开源旗舰
如果说DeepSeek的标签是"效率极致"和"全栈开源",那么阿里通义千问(Qwen)的标签则是"全面覆盖"和"全球渗透"。在全球开源大模型的版图上,Qwen是中国国际影响力最大的系列之一——累计超过4亿次下载、300多个模型变体发布,在HuggingFace等国际平台上的存在感仅次于Meta的LLaMA。
Qwen的技术团队由林俊洋(Justin Lin)领导,他本科毕业于北京大学语言学系,2019年加入阿里达摩院。和很多AI公司依赖海归团队不同,Qwen的核心团队更多是从中国本土研究环境中成长起来的——这种背景让Qwen在中文数据处理和中文场景优化上有天然的优势。后训练负责人于博文是中科院信息工程研究所博士,代码方向负责人惠斌远1999年出生、天津大学硕士毕业——Qwen团队的年轻化程度在同级别的AI团队中相当突出。
Qwen的迭代节奏极快,几乎每半年一个大版本。从Qwen 1到Qwen 3.5(2026年2月),每一代都有明显的能力跃迁。几个关键里程碑:Qwen 2.5(2024年)在多项国际基准上和LLaMA 3.1正面竞争,确立了"中国最强开源模型之一"的地位;QwQ-32B(2025年初)是320亿参数的推理模型,在数学和代码推理上展现出超越尺寸的能力;Qwen3(2025年4月)在36万亿token上训练,支持201种语言和方言——从上一代的82种飞跃到201种,这个数字表明Qwen的雄心不仅是"中文最强",而是"全球通用";Qwen3-Omni(2025年9月)实现了文本、图像、音频、视频的全模态理解和生成,是中国第一个全模态开源模型;Qwen3-Max-Thinking(2026年1月)在推理基准上超越了Claude Opus 4.5和GPT-5.2——这是中国开源模型第一次在推理能力上全面超越最强闭源模型。
Qwen的开源策略是"全面开放、Apache 2.0许可证、完全免费商用"。这个策略的商业逻辑非常清晰:阿里是中国最大的云计算厂商,开源模型是云计算的"流量入口"——开发者免费使用Qwen模型,但需要在阿里云上购买GPU算力来部署和运行。模型免费,算力收费——这是"剃刀和刀片"的经典商业模式。
Qwen和DeepSeek的对比很有意思。两者都是中国开源大模型的标杆,但路线差异明显:DeepSeek走的是"深度极致"路线——在效率优化和架构创新上做到极致,模型数量少但每一个都是精品;Qwen走的是"广度覆盖"路线——模型变体极多(300+),覆盖从0.6B到235B的全尺寸谱、从纯文本到全模态的全能力谱、从通用到代码/数学/视觉的全场景谱。DeepSeek像一把精心锻造的手术刀——极致锋利、用途精准;Qwen像一个装备齐全的工具箱——什么场景都能找到合适的工具。
2026年3月,Qwen技术负责人林俊洋宣布离任——这在产业界引发了广泛关注。但Qwen的技术积累和开源生态已经形成了自己的惯性,团队的后续发展值得持续关注。
从OpenAI到群星:一张产业全景图
回顾这些公司的崛起路径,一个清晰的产业格局已经形成。
闭源阵营的三强格局相对稳定:①OpenAI凭借先发优势、最强品牌认知和最大的用户基数,占据C端市场的统治地位——ChatGPT是大多数普通用户接触AI的第一个产品,也是很多人唯一在用的AI产品;②Google凭借搜索、邮件、文档、视频等产品矩阵的嵌入式分发,让Gemini渗透到数十亿用户的日常工作流中——很多用户甚至不知道自己在"用AI",因为Gemini已经融入了他们熟悉的产品界面;③Anthropic凭借在代码、推理和安全上的差异化优势,成为开发者社区的首选——程序员用Claude Code写代码、用Claude分析复杂问题的场景越来越多。
开源阵营的竞争则更加多元和激烈。Meta的LLaMA系列是开源运动的奠基者(第九章已详述),但到2025年已不再是唯一的领跑者——DeepSeek、阿里Qwen和Mistral在各自的方向上都达到了世界前沿。开源模型的能力边界在2023-2025年间经历了五次关键跃迁,每一次都重新定义了"开源能做到什么"——这个故事将在第二部分详细展开。
xAI/Grok占据了一个独特的生态位:它既不是纯闭源(Grok-1曾开源),也不是纯开源;它的核心竞争力不完全在模型本身,而在于X平台的实时数据和马斯克个人的影响力。这让Grok在社交媒体分析、实时新闻和"非正式"对话场景中有独特的吸引力,但在企业级应用市场的渗透率远不如OpenAI、Google和Anthropic。
中国的两面旗帜——DeepSeek和Qwen——则代表了开源阵营中最具冲击力的力量。DeepSeek以极致效率和全栈开源震动了全球产业格局,证明了"用更少资源做同等甚至更好的事"不是口号而是现实;Qwen以全面覆盖和全球化运营,成为HuggingFace上下载量最大的中国开源模型系列,在多语言、多模态、多尺寸的维度上构建了最完整的开源模型矩阵。两者共同把中国AI从"跟跑者"推向了"并跑者甚至领跑者"的位置。
每一家公司的差异化,归根结底来自三个因素的不同组合:技术基因(创始团队的学术和工程背景)、商业逻辑(靠什么赚钱、服务谁)和价值观(对AI应该如何发展的根本信念)。OpenAI相信"能力第一,安全跟上";Anthropic相信"安全第一,能力随之而来";Google相信"AI应该嵌入每个产品";Mistral相信"小而美、开而精";xAI相信"打破政治正确的AI才是真正有用的AI";DeepSeek相信"效率可以弥补资源不足";Qwen相信"开源的广度就是生态的深度"。这些信念的差异,最终塑造了产品的差异——而产品的差异,才是用户和市场真正关心的东西。
第二部分:开源的力量——五次里程碑跃迁
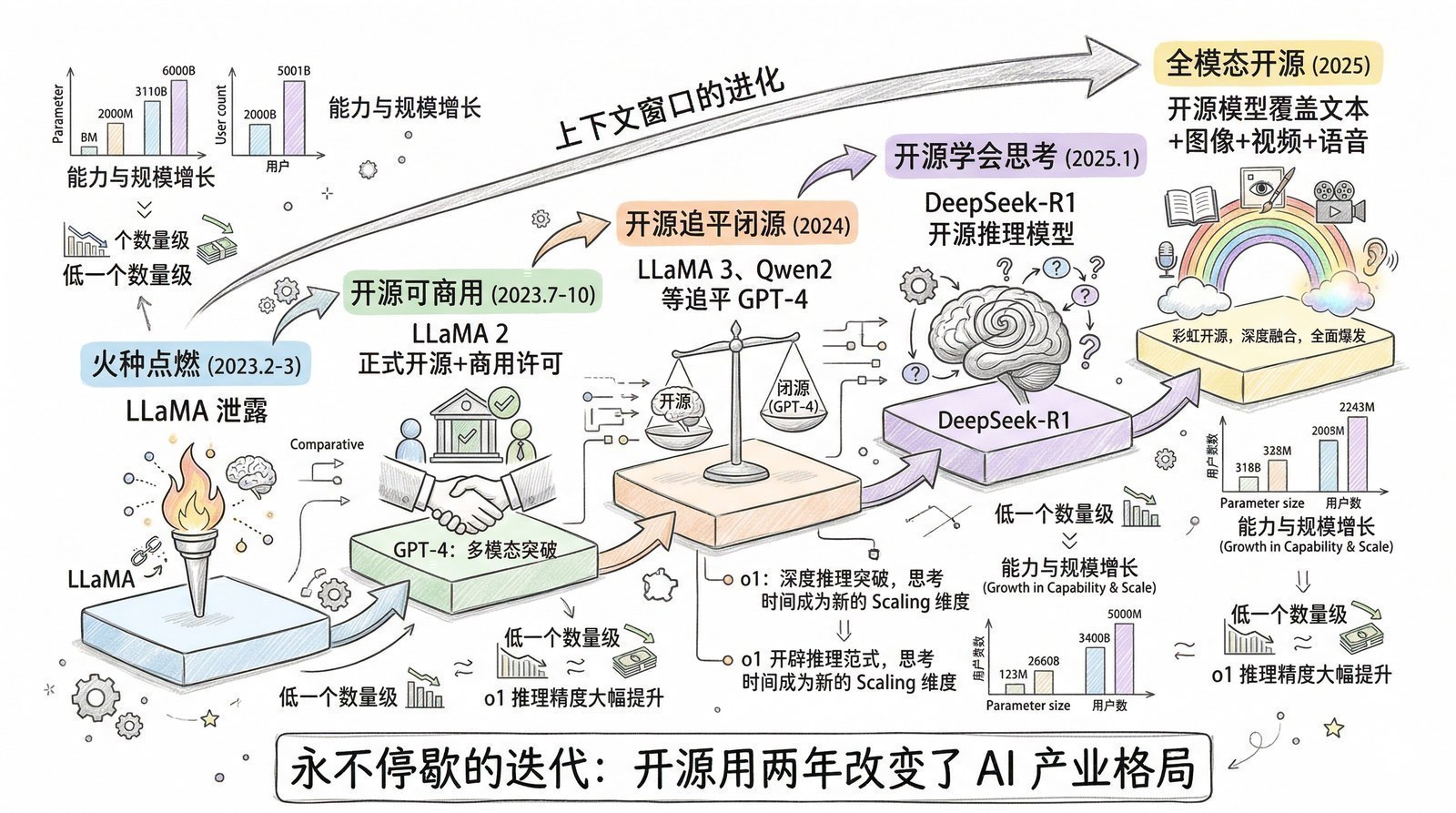
2023年初,开源大模型是一个学术界的边缘话题。到2025年底,它已经成为重塑全球AI产业格局的核心力量。
要理解开源大模型的意义,不能只看单个模型的发布,而要看整个运动的演进轨迹。从2023年2月LLaMA泄露到2025年底,开源社区经历了五次里程碑式的跃迁,每一次都把开源模型的能力天花板提高了一个台阶,也把"什么人可以用AI、用AI做什么"的边界大幅扩展。
第一次跃迁:火种点燃(2023年2月-3月)
2023年2月,Meta发布LLaMA[1](第九章已详述)。一周后模型权重泄露到互联网上。这次"泄露"是否是有意的,至今众说纷纭——但结果是确定的:全世界的开发者第一次可以免费下载并使用一个GPT级别的大模型。
泄露后发生的事情,用"星火燎原"来形容毫不过分。斯坦福大学的一个研究小组只花了600美元,用52000条由GPT-3.5生成的指令数据,在LLaMA 7B上微调了3小时,就得到了Alpaca[16]——一个在很多日常对话任务上接近ChatGPT水平的模型。UC Berkeley的团队更进一步,用ShareGPT上用户分享的对话数据(完全免费),在LLaMA 13B上微调出了Vicuna[17]——据非官方评测,Vicuna达到了ChatGPT约90%的质量。然后是GPT4ALL——一个可以在没有GPU的普通笔记本电脑上运行的大模型。
这意味着什么?OpenAI花了数亿美元、数千块GPU、数年时间训练出的ChatGPT,现在有人用600美元和一个下午就能做出"勉强够用"的替代品。这就像核武器的秘密被公开了——虽然你自己造的版本不如超级大国的精良,但"能造核弹"和"不能造核弱"之间的差距是质变的。仅2023年一年,HuggingFace上就出现了超过7000个基于LLaMA的衍生模型。Google内部那份著名的匿名备忘录——"我们没有护城河,OpenAI也没有"——正是对这次爆发的直接反应。
为什么一次"泄露"就能引发如此大的连锁反应?因为大模型的核心竞争壁垒在预训练阶段——收集数据、设计架构、调参训练,这些需要巨额投入和顶级人才。但一旦预训练完成,模型权重就像一个"半成品"——在上面做微调(Fine-tuning)的成本只有预训练的千分之一到万分之一。LLaMA的泄露相当于把最昂贵、最难的那一步跳过了——全世界的开发者直接拿到了"半成品",只需要花极低的成本就能把它变成自己需要的"成品"。
这次跃迁的意义是:把大模型从"巨头专利"变成了"公共资源",打破了心理门槛,让全世界数以万计的开发者和研究者开始相信:"我也可以做大模型。"
第二次跃迁:开源可商用(2023年7月-10月)
LLaMA虽然引爆了开源运动,但它有一个致命的问题:许可证限制。LLaMA最初只允许"研究用途",不允许商业化。这个限制看起来只是一句法律条款,但它的实际影响是巨大的——它意味着任何一家企业,如果想把基于LLaMA微调的模型用到自己的产品里(比如做一个客服机器人、一个法律助手、一个代码工具),在法律上都是违规的。风险投资人不会投一个核心技术存在法律风险的项目,大企业的法务部门也不会批准部署一个许可证不清晰的模型。火种虽然点燃了,但在商业世界里它还是"地下火"。
2023年7月,Meta发布LLaMA 2——这一次是主动开源、明确允许商用(仅月活超过7亿的公司需要单独授权)。这个变化的意义,可以类比为软件行业从"盗版软件"到"免费开源软件"的转变——技术内容可能相似,但法律地位的变化让整个商业生态从"灰色地带"走向了"阳光之下"。
同年9月,Mistral发布了Mistral 7B[2]——采用Apache 2.0许可证(最宽松的开源协议之一,几乎没有任何使用限制)。一个70亿参数的模型,在多项基准上超越了LLaMA 2的130亿版本——参数量小了近一倍,效果却更好。Mistral 7B的成功传递了一个重要信号:开源模型不仅"可商用"了,而且"效率更高"——你不需要最大的模型,精心设计的小模型就能达到甚至超越大模型的效果。
在中国,同一时期也发生了类似的变化。智谱AI的ChatGLM系列[9]和阿里的Qwen[13]先后开放商用许可,中国的开发者第一次有了合法的、高质量的国产开源选择。
这次跃迁的意义是:开源大模型从"学术玩具"变成了"商业基础设施"。企业可以合法地将开源模型集成到自己的产品和服务中,而不需要向OpenAI或Google支付API费用。这催生了一个全新的商业生态——围绕开源模型的微调、部署、优化和应用开发,出现了数百家创业公司和服务商。一个简单的类比:如果说第一次跃迁是把种子撒到了地里,第二次跃迁就是给种子浇上了水——法律上的"可商用"许可,是让开源AI从实验室走向产业的必要条件。
第三次跃迁:开源追平闭源(2024年)
2024年是开源模型和闭源模型的差距急剧缩小的一年。这种缩小不是在某一个指标上的小幅追赶,而是在多个维度上的全面逼近。
7月,Meta发布LLaMA 3.1——其中405B版本在多项基准上接近GPT-4[3],是当时最大的开源模型。405B意味着什么?GPT-3的参数量是1750亿(第六章),被认为是"大得不可思议"的规模。现在一个完全免费、权重公开的模型已经是GPT-3的两倍还多,而且性能接近比它晚一年发布的、最先进的闭源模型GPT-4。
几乎同期,阿里发布Qwen 2.5系列[14]——在多项国际基准上和LLaMA 3.1正面竞争,特别是在中文和多语言能力上有明显优势。Qwen 2.5的意义不仅在于它的绝对性能,更在于它证明了开源模型的竞争已经不再是"美国一家独大"——中国公司也有能力训练出世界顶级的开源模型。DeepSeek-V2和V3在MoE架构上做出了远超同行的效率创新(第十三章),用不到六分之一的训练成本达到了同级效果。Mistral的Mixtral和Mistral Large系列在欧洲市场站稳了脚跟。
用一个产业化的视角来看这次跃迁:2023年初,如果一个企业想要使用前沿AI能力,唯一的选择是调用OpenAI的API——每百万token的价格从几美元到几十美元不等,而且数据需要发送到OpenAI的服务器上(这对很多企业来说是不可接受的隐私风险)。到2024年底,同一个企业可以在自己的服务器上部署一个免费的开源模型,性能达到GPT-4的百分之九十以上,数据完全留在本地,推理成本仅为电费和GPU折旧。这不是"便宜了一点"——这是从"依赖别人"到"自己掌控"的结构性变化,就像一个国家从"进口石油"转向"自产新能源"。
这次跃迁的标志性事件是:第一次有开源模型在严肃的、多维度的评测中逼近甚至追平最强的闭源模型。很多企业CTO开始重新审视自己的AI采购策略——"我真的需要为GPT-4 API付费吗?"这个问题第一次有了一个可信的"不需要"的答案。
第四次跃迁:开源模型学会思考(2025年1月)
前三次跃迁解决的是"知识"和"能力"的问题——让开源模型知道更多东西、做更多事情。但2024年9月OpenAI发布o1模型(第十章)之后,行业意识到了一个新的能力维度:推理——让模型不仅"知道答案",而且能"想出答案"。o1在回答问题之前会先进行一段内部"思考"过程,像人类解数学题一样一步一步推导。这种能力让o1在数学、代码、科学推理等任务上远超GPT-4。
问题是:o1是完全闭源的。OpenAI没有公开o1的架构细节、训练方法、甚至思维链的具体内容。这意味着整个开源社区面对一个巨大的能力鸿沟——闭源模型已经"学会思考"了,而开源模型还停留在"靠记忆回答"的阶段。这个鸿沟如果持续扩大,开源运动前三次跃迁积累的优势可能会被一夜之间抹平。
2025年1月,两个事件让开源模型跨入了这个全新的能力维度。
DeepSeek-R1[5](第十三章已详述)证明了开源模型也可以具备深度推理能力——不仅如此,它还公开了完整的思维链、训练方法和技术细节。R1用纯强化学习(RL)让模型自发"学会了思考"——不需要人工标注的推理过程,模型通过不断尝试和获得奖励反馈,自己摸索出了解决复杂问题的策略。更惊人的是,R1在训练过程中自发涌现出了"反思"行为——当发现自己的推理走入死胡同时,它会回头检查之前的步骤、修正错误、尝试新的路径。这些能力不是人类编程进去的,而是从RL训练中"生长"出来的。
几乎同时,阿里发布了QwQ-32B——一个320亿参数的推理模型,在数学和代码推理上展现出了和更大模型相当的能力。QwQ的重要性在于它的尺寸:320亿参数意味着它可以在单块消费级GPU上运行(比如NVIDIA RTX 4090),而不需要企业级的服务器集群。一个普通开发者花几千元买一块显卡,就能在自己的电脑上运行一个具备深度推理能力的AI——这在一年前是不可想象的。
这次跃迁的真正突破在于R1的蒸馏生态。"蒸馏"是一种把大模型的能力"压缩"到小模型里的技术——用大模型("老师")生成高质量的推理过程作为训练数据,再用这些数据训练一个小得多的模型("学生")。R1的671B参数被蒸馏成了一系列小模型:70B、32B、14B、7B、一直到1.5B——推理能力被压缩了400多倍。1.5B的模型可以在手机上运行,甚至可以在树莓派上运行。这意味着"让AI思考"不再需要昂贵的服务器——它可以发生在你口袋里的设备上。
更重要的是,DeepSeek以MIT许可证开源了R1的全部内容,任何人都可以基于它做二次开发。这种"把前沿能力民主化"的模式,是开源运动最激动人心的体现——不是让少数人拥有最强的技术,而是让所有人都能站在巨人的肩膀上。
第五次跃迁:全模态开源(2025年)
前四次跃迁让开源模型在文本领域——理解语言、生成语言、进行推理——追平了闭源模型。但人类和世界的交互不仅仅是文字。我们看图片、听声音、看视频、画画、创作音乐——GPT-4o在2024年5月发布时展示的"原生多模态"能力(可以同时处理文本、图像和语音),让很多人意识到:如果开源模型只会处理文字,它和闭源模型之间还有一道巨大的鸿沟。
2025年下半年,这道鸿沟开始被填平。
阿里的Qwen3-Omni(2025年9月)是一个能同时处理和生成文本、图像、音频、视频的全模态开源模型。"全模态"意味着什么?你可以给它一张产品设计图,让它用语音讲解设计思路;可以给它一段会议录音,让它生成带图表的会议纪要;可以用文字描述一个场景,让它生成对应的图片。这些能力之前只有GPT-4o级别的闭源模型才具备——现在一个完全免费、权重公开的模型也能做到了。
月之暗面的Kimi K2[12](2025年7月)拥有1万亿总参数、320亿激活参数的MoE架构,支持25.6万token上下文,在智能体(Agent)任务上表现突出——所谓"智能体"能力,是指模型不仅能回答问题,还能自主地调用工具、执行多步任务、甚至浏览网页和操作软件。Kimi K2.5(2026年1月)进一步加入了原生视觉能力——一个4亿参数的视觉编码器(MoonViT)让模型可以直接"看到"图片和视频中的内容。腾讯的混元Video[15](130亿参数)成为了行业领先的开源视频生成模型。
这次跃迁的意义远不止"又多了几种能力"。它从根本上改变了AI的应用边界。之前的开源模型是一个"文字助手"——你给它文字,它还你文字。现在的开源模型是一个"全感知助手"——它可以看、听、说、画、创作。这意味着AI的应用场景从"办公和编程"扩展到了几乎所有人类活动:教育(AI老师可以看到学生的手写作业、用语音讲解错误、生成可视化的解题过程)、医疗(AI可以分析X光片、听诊音频、生成文字报告)、创意产业(AI可以根据文字描述生成视频、根据哼唱生成编曲)、制造业(AI可以通过摄像头检测产品缺陷并生成质检报告)。
更深层的影响是:全模态能力降低了使用AI的"门槛"。文字交互需要用户会打字、会组织语言——对于老年人、儿童、文化水平有限的用户来说,这本身就是一道障碍。但语音和视觉交互是人类最自然的沟通方式——当开源模型可以"听你说话、看你比划"时,AI就不再是程序员和知识工作者的专属工具,而是真正面向所有人的。
开源的深层推动力
这五次跃迁的背后,有三股力量在持续推动。
第一股力量是商业博弈。Meta开源LLaMA的战略逻辑(第九章已分析)是"用开源打破闭源垄断"——当全世界都在用LLaMA生态时,OpenAI的API就不再是唯一选择。阿里开源Qwen的逻辑类似——作为云计算厂商,阿里需要一个强大的开源模型来吸引开发者使用阿里云的GPU和推理服务。DeepSeek开源R1的逻辑更极致——通过全栈开源成为事实上的技术标准制定者。开源不是理想主义,是精密的商业策略。
第二股力量是技术溢出。每一次重要的开源发布,都会引发大规模的社区创新。LLaMA催生了7000多个衍生模型。DeepSeek的GRPO算法被开源社区广泛采用。Mistral的MoE实践让这项技术从"大厂专属"变成了"人人可用"。开源模型的论文和代码成为了全球AI研究者的"公共教科书"——你不需要在Google或OpenAI工作,也可以通过阅读DeepSeek-V3的技术报告来学习如何训练一个世界级的大模型。这种知识的民主化,是技术进步最强大的加速器。
第三股力量是生态网络效应。当一个开源模型被足够多的开发者使用时,围绕它的工具链、教程、微调方法、部署方案就会自发涌现——这反过来吸引更多开发者加入,形成正反馈循环。HuggingFace平台上的模型数量从2023年的几千个增长到2025年的数十万个。开源模型的"可组合性"(任何人都可以在现有模型基础上做微调、蒸馏、量化、适配)创造了一个任何单一公司都无法独立完成的创新生态。
对产业而言,开源大模型最深远的影响是重新定义了AI的成本结构。2023年,使用前沿AI的唯一方式是通过OpenAI的API付费——每百万token几十美元。到2025年,企业可以在自己的服务器上免费部署一个性能相当的开源模型,推理成本降到接近于零。这不是渐进式的成本下降,而是从"按量付费"到"接近免费"的结构性跳跃。就像互联网从按分钟计费的拨号时代跳跃到宽带包月时代——当基础成本趋近于零时,大量原本"算不过账"的应用场景突然变得经济可行,AI开始真正渗透到各行各业的毛细血管中。
对社会而言,开源大模型的意义在于防止了AI成为少数巨头的垄断工具。如果大模型技术只掌握在OpenAI和Google手中,那么这两家公司就对全球的信息获取、知识生产和创意表达拥有了巨大的控制力——它们可以决定AI"愿意回答什么"、"拒绝回答什么"、以及"用什么方式回答"。开源模型的存在,让这种控制力被分散了:如果你不满意某个闭源模型的限制或偏见,你可以部署一个开源替代品。这种"退出权"(exit option)对于维持AI生态的健康多元至关重要。
对技术本身而言,开源加速了AI研究的迭代速度。闭源模型的技术细节被严格保密——GPT-4的技术报告几乎不包含任何有意义的信息。而DeepSeek-V3的技术报告详细描述了MLA、MoE负载均衡、FP8训练的每一个工程细节,Mistral的论文公开了Mixtral的完整架构设计。这些公开的知识让全球的研究者可以站在前人的肩膀上继续前进,而不需要从零重新发明轮子。科学的本质是知识的积累和共享——开源模型让AI研究重新回到了这个轨道上。
第三部分:中国AI群像——六小虎与三巨头
2023年上半年的中国AI产业,可以用一个词形容:百模大战。到2025年底,战场的硝烟散去,幸存者的面孔变得清晰。
第九章已经介绍了百模大战的基本格局——从大厂(百度、阿里、腾讯、字节、华为)到创业公司(智谱、月之暗面、MiniMax、百川、零一万物、DeepSeek),数十家机构在2023年涌入大模型赛道。两年后的格局已经大不相同:大量中小玩家退出或转型,头部效应日益明显。中国的大模型产业形成了"六小虎"创业军团和阿里、字节、腾讯三巨头并立的格局——DeepSeek作为超级黑马已在第十三章单独讲述,本节聚焦其他玩家。
AI"六小虎":从百模大战中杀出的创业者
中国AI产业在2023-2024年间涌现了六家备受关注的大模型创业公司,媒体借用"亚洲四小龙"的概念,将它们称为"大模型六小虎"——智谱AI、月之暗面、MiniMax、百川智能、零一万物和阶跃星辰。六家公司在2024年初全部达到独角兽估值(10亿美元以上),背后站着阿里、腾讯、美团、小米等中国科技巨头的资本支持。
这六家公司的创始人背景各有不同,但有一个共同点:几乎全部来自中国最顶尖的AI学术和产业圈子。
智谱AI(Z.ai):清华系的学术底蕴
智谱AI成立于2019年,是六小虎中成立最早的一家,脱胎于清华大学计算机系。核心领导人包括清华教授唐杰和董事长刘德兵。智谱的技术根基是清华自研的GLM(General Language Model)架构——和GPT的纯自回归不同,GLM在早期版本中采用了一种"自回归填空"的混合策略,后来逐步向主流的自回归架构靠拢。
ChatGLM系列是中国最早的开源中文大模型之一。从ChatGLM-1到ChatGLM-4,智谱的模型一直保持着在中文理解和对话上的优势。GLM-4系列在1万亿token上预训练,支持中英文加24种其他语言。在国际基准MMLU上达到83.3%(GPT-4为86.4%),在GSM8K数学推理上达到93.3%(GPT-4为92.0%),在BIG-Bench综合评测上达到84.7%(GPT-4为83.1%)——在部分指标上已经追平甚至超越GPT-4。
智谱的开源策略是Apache 2.0许可证,模型完全免费用于学术研究,商用只需填写问卷注册。智谱还特别关注轻量化部署——支持TensorRT-LLM优化、GPTQ量化(4/8位)、CPU和MPS运行,让模型可以在各种硬件条件下高效运行。
2025年,智谱更名为Z.ai,加速国际化布局。2026年3月,智谱成为六小虎中第一家完成IPO的公司——也是中国第一家上市的大模型基础公司。从清华实验室到上市公司,智谱用了七年时间,走完了中国AI创业从学术到商业的完整路径。
月之暗面(Moonshot AI):最年轻的颠覆者
在六小虎中,月之暗面的创始人杨植麟可能是最具传奇色彩的一位。1992年出生的杨植麟,清华本科、卡内基梅隆大学(CMU)计算机科学博士,是中国NLP领域35岁以下被引用最多的研究者。他的学术履历令人瞩目——Transformer-XL和XLNet两篇论文的第一作者。Transformer-XL解决了原始Transformer在长序列处理上的瓶颈,XLNet则在发布时超越了BERT在多项基准上的表现。这两篇论文直接影响了后来大模型处理长文本的技术路线。在博士期间,杨植麟还和杨立昆(Yann LeCun)、Quoc V. Le(Google Brain)、约书亚·本吉奥(Yoshua Bengio)等顶级学者合作发表论文。
2023年3月,杨植麟和清华同学周昕宇、吴育昕共同创立月之暗面。公司从第一天起就瞄准了一个当时几乎没人关注的方向:超长上下文。2023年10月,Kimi Chat发布,支持20万字的上下文窗口——在当时,ChatGPT的上下文窗口约为8000字。20万字意味着用户可以把一本完整的书、一份几百页的合同、或者整个项目的代码一次性扔给AI,让它理解和分析。这种"把整本书一口气读完"的能力,在法律、金融、学术研究等需要处理大量文档的场景中具有巨大的实用价值。
Kimi的长上下文能力不是简单的"把输入框变大"——它需要在注意力机制和推理效率上做大量的架构优化(杨植麟在Transformer-XL上的研究积累在此发挥了关键作用)。这种"从学术论文到产品特性"的直接转化,是学者创业最理想的模式。
2025年是月之暗面的产品爆发年。Kimi K1.5引入了基于强化学习的推理能力,在部分基准上和OpenAI o1持平。Kimi K2(2025年7月)是一个万亿参数的MoE模型,320亿激活参数、25.6万token上下文,在智能体(Agent)任务上表现突出——训练成本仅约460万美元,延续了中国AI公司"效率优先"的传统。2026年1月,Kimi K2.5加入了原生视觉能力,可以处理图像和视频。
月之暗面的融资速度同样惊人。2024年B轮融资超过10亿美元,估值25亿美元。此后腾讯和高榕资本追加3亿美元,估值升至33亿美元。2025年12月C轮5亿美元,估值43亿美元。到2026年3月,据报道月之暗面正在以180亿美元估值进行新一轮10亿美元融资。一个33岁的创始人带领的三年老公司,正在向200亿美元估值冲刺——这在中国创业史上是罕见的。
MiniMax:从商汤到AGI的跨界
MiniMax的创始人闫俊杰的背景和其他创始人截然不同。他不是学术圈出身,而是产业界老兵——曾任商汤科技副总裁、研究院副院长、智慧城市事业群CTO,负责深度学习工具链和通用智能技术的开发。这种产业经验让MiniMax从一开始就具有更强的"产品化"基因——他不只关心模型有多强,更关心用户实际怎么用。
MiniMax成立于2021年12月,是六小虎中成立最早的创业公司之一(仅晚于智谱)。MiniMax的差异化路线非常明确:全模态、重视娱乐和社交场景。当大多数大模型公司还在专注文本对话时,MiniMax已经在探索语音、音乐、视频等多种模态的生成能力。旗下产品包括海螺AI(通用AI助手)、Talkie(AI角色扮演和社交,面向海外市场)和星野(AI角色互动平台)。
MiniMax的模型能力在2025-2026年间取得了显著进步。MiniMax M2.7在复杂智能体任务上的表现引人注目——在SWE-Pro编程基准上达到56.22%的准确率,和GPT-5.3-Codex持平。海螺AI 2.3的视频生成能力支持动漫、水墨画、游戏CG等多种风格,在物理理解和人物微表情等细节上有明显提升。
MiniMax最引人注目的里程碑是2026年1月在香港联交所上市——这是六小虎中第一家IPO的公司(比智谱早了约两个月),也是全球大模型创业公司中最大规模的IPO之一。上市首日股价暴涨约110%,市值突破1万亿港元。从成立到IPO仅用了四年时间。投资人阵容豪华——阿里巴巴、腾讯、高瓴、红杉、IDG、阿布扎比投资局等中国和国际顶级资本齐聚。MiniMax的上市为中国大模型创业公司走向资本市场开辟了先例。
百川智能:互联网老兵的垂直深耕
百川智能由前搜狗CEO王小川于2023年4月创立。王小川是中国互联网行业最资深的老兵之一——他在1996年(16岁)获得国际信息学奥林匹克竞赛金牌,大学期间加入搜狐,之后创建搜狗搜索和搜狗输入法。搜狗输入法在鼎盛时期覆盖了超过5亿中国用户——这意味着王小川比几乎任何人都更理解中国用户如何使用文字、如何组织语言、如何表达需求。这种对中文用户的深刻理解,是百川在中文大模型领域的独特基因。
百川的技术路线偏向通用大语言模型,发布了Baichuan系列开源模型。但和其他六小虎更注重通用能力不同,百川在商业化上选择了垂直深耕——特别是在医疗和金融两个行业。王小川曾公开表示,他认为大模型的真正价值不在于"聊天",而在于解决特定行业的特定问题。百川的"百小应"AI助手在医疗问诊辅助上有独特的产品定位,尝试用AI帮助患者理解病情、整理病历、对接医疗资源。
2025年7月,百川完成了50亿元人民币(约6.88亿美元)的融资,估值超过200亿元——在六小虎中属于融资规模较大的一家。百川的故事代表了一种和"追求通用AGI"截然不同的路径:不追求在基准测试上排名最高,而是在特定行业中做到"最好用"。
零一万物(01.AI):AI布道者的创业
零一万物由创新工场创始人李开复于2023年创立。李开复可能是中国科技界公众知名度最高的人物之一——他的职业生涯横跨了苹果、微软和Google三家全球顶级科技公司,曾担任Google中国区总裁。2009年离开Google后创办创新工场,成为中国最活跃的科技投资人之一。他的微博粉丝超过5000万,出版的多本AI科普书籍在中国销量巨大——他既是投资人,也是AI领域最有影响力的"布道者"。
李开复的个人品牌和国际化视野,让零一万物从一开始就具备了很多中国AI创业公司不具备的优势:海外市场的品牌认知度。当海外媒体报道中国AI创业时,零一万物往往是第一个被提到的名字——不是因为它的技术最强,而是因为李开复在英文世界的知名度远超其他中国AI创始人(他的英文自传《AI Superpowers》是亚马逊畅销书)。
零一万物发布的Yi系列开源模型在中英文双语能力上表现出色,Yi-34B在发布时是同等参数规模下性能最强的开源模型之一。但零一万物在2024-2025年也面临了战略调整——在大模型基础研发的"军备竞赛"中,烧钱速度远超商业化收入,团队开始更多地转向应用层和To B服务。零一万物的经历折射了一个中国AI创业的共同难题:创始人的个人光环可以帮助公司起步,但长期竞争最终还是要回到技术和产品本身。
阶跃星辰(StepFun):微软系的工程化哲学
阶跃星辰由前微软亚洲研究院(MSRA)副院长姜大昕于2023年创立。MSRA是中国AI人才的"黄埔军校"——过去二十年间,从MSRA走出的AI研究者和工程师遍布中国科技产业的各个角落。姜大昕在微软工作超过20年,对大规模AI系统的工程化有极其深厚的经验——他不是纯学术背景,而是"能把论文变成产品"的工程型领导者。
阶跃星辰的差异化在于"多模态全面覆盖"。当大多数六小虎还在专注于文本大模型时,阶跃星辰已经发布了11个基础模型,覆盖视觉、音频、多模态等多个方向——这种"广撒网"的策略和其他公司"单点突破"的策略形成了对比。其中Step-2模型拥有万亿参数规模,在LiveBench等国际基准上和DeepSeek、阿里、OpenAI的模型同台竞技——证明了一家成立不到两年的创业公司也能训练出万亿级别的模型。
姜大昕的微软背景赋予了阶跃星辰一种独特的"工程化哲学"——不追求单一指标上的极致,而是追求整个技术栈的系统性、可靠性和可扩展性。这种哲学在短期内可能不如"刷基准分数"那么引人注目,但在长期的产品化和商业化竞争中可能是更大的优势。
三巨头:阿里、字节、腾讯
如果说六小虎代表了中国AI创业的锐度和速度,那么阿里、字节、腾讯三巨头代表的则是规模和生态的力量。三家公司各自以不同的方式参与大模型竞赛,但共同点是:它们都拥有创业公司梦寐以求的三大资源——海量用户、充裕资金和丰富的应用场景。
阿里Qwen:中国开源的全球名片
在所有中国大模型中,阿里的通义千问(Qwen)是国际化做得最好的一个——不仅在国内有广泛应用,在全球开源社区中也享有很高的声誉,累计超过4亿次下载,发布超过300个模型变体。
Qwen的技术团队由林俊洋(Justin Lin)领导。林俊洋本科毕业于北京大学语言学系,2019年加入阿里达摩院,从中国本土研究环境中成长起来——和很多AI公司依赖海归团队不同,Qwen的核心团队更多是"本土培养"的。这种背景让Qwen在中文数据处理和中文模型优化上有天然的优势。
Qwen的迭代节奏极快。从Qwen 1到Qwen 3.5(2026年2月),版本号几乎是以半年为周期递增。每一代都有明显的能力提升:Qwen 2.5在多项国际基准上和LLaMA 3.1正面竞争,QwQ-32B推理模型在数学和代码上展现出超越模型尺寸的能力(第十章),Qwen3(2025年4月)在36万亿token上训练、支持201种语言——从82种到201种的飞跃,展示了Qwen在多语言能力上的雄心。Qwen3-Omni(2025年9月)实现了文本、图像、音频、视频的全模态理解和生成——这是中国第一个全模态开源模型。Qwen3-Max-Thinking(2026年1月)在推理基准上超越了Claude Opus 4.5和GPT-5.2。
Qwen的开源策略是"全面开放"——所有主要模型都采用Apache 2.0许可证,完全免费、允许商用。这个策略的商业逻辑和Meta开源LLaMA类似但更直接:阿里是中国最大的云计算厂商(阿里云),开源模型吸引开发者在阿里云上部署和运行——模型免费,但GPU算力收费。这种"剃刀和刀片"的商业模式(免费送剃刀,靠卖刀片赚钱),让Qwen的开源不是"做慈善",而是精准的云计算获客策略。
Qwen对中国AI产业的意义在于它提供了一个高质量的"国产替代"。在DeepSeek-R1发布之前,很多中国企业和开发者如果需要一个强大的开源基座模型,首选是LLaMA——一个美国公司的产品。Qwen的持续进步,让"用中国的开源模型做中国的AI应用"成为了一个切实可行、甚至在很多场景下效果更好的选择。特别是在中文理解、中文生成和中国特定的应用场景(如电商、社交媒体、政务服务)中,Qwen的表现往往优于LLaMA等国际模型。
2026年3月,Qwen技术负责人林俊洋在推动了这一系列成就后宣布离任——这在中国AI产业界引发了广泛关注,也折射出高强度竞赛下技术领军人物的流动性。
字节跳动豆包:流量之王的AI野心
如果说Qwen的策略是"开源建生态",字节跳动豆包(Doubao)的策略则是"流量碾压一切"。
字节跳动是中国最擅长"做产品"和"做增长"的科技公司——抖音(TikTok)的全球崛起是过去十年中国科技界最大的成功故事之一。当字节把同样的产品能力和流量思维应用到AI助手上时,结果是惊人的:到2025年底,豆包的月活跃用户达到2.26亿,周活跃用户1.55亿——几乎是DeepSeek同期周活跃用户(8160万)的两倍。2026年春节期间,借助央视春晚合作的推广,豆包的日活跃用户突破了1亿——这个数字让它成为了中国、也可能是全球用户量最大的AI助手之一。
字节的AI模型发展路线也在快速演进。2026年2月发布的豆包2.0(Doubao-Seed-2.0)定位于"Agent时代"——专注于长链推理和复杂任务执行,性能对标GPT-5.2和Gemini 3 Pro。更引人注目的是定价策略:豆包2.0的API价格仅为竞争对手的约十分之一——字节延续了"以价格换规模"的经典互联网打法。几乎同时发布的Seedance 2.0是视频生成模型,产出质量被著名导演贾樟柯称赞,达到了电影级品质。
字节的独特优势是它庞大的产品矩阵——抖音、今日头条、飞书(企业协作)、剪映(视频编辑)——每一个产品都是AI的天然应用场景和分发渠道。AI不需要作为一个独立产品去获取用户,而是作为"增强功能"嵌入到用户已经在用的产品中。这种嵌入式的AI部署策略,和Google的Gemini战略有异曲同工之妙——但字节在短视频和内容推荐领域的统治地位,让它在这些场景中比Google更有优势。
字节2026年计划投入1600亿元人民币(约230亿美元)的AI资本支出——这个数字超过了大多数中国科技公司的全年营收。这种不惜成本的投入,反映了字节对AI的战略判断:AI不是"又一个新功能",而是"下一代互联网的基础设施"。
腾讯混元:社交帝国的AI渗透
腾讯的AI策略和字节、阿里都不同——它不追求"最强模型"或"最大开源社区",而是追求"最深度的产品集成"。
腾讯混元(Hunyuan)大模型于2023年9月发布,此后持续迭代。2024年11月发布的混元Large是当时最大的开源MoE模型之一——389亿总参数、520亿激活参数、支持25.6万token上下文。腾讯还开源了混元Video(130亿参数的视频生成模型,在视频质量和运动稳定性上达到了行业领先水平)和混元3D(3D资产生成模型)。2026年4月,腾讯预计将发布混元3.0。
但腾讯真正的"杀手锏"不是模型本身,而是微信。微信拥有超过13亿月活跃用户,是中国人日常生活中不可或缺的基础设施——聊天、支付、点餐、打车、购物、工作……几乎所有事情都可以在微信中完成。当AI被嵌入微信时,它不需要用户去下载一个新App、注册一个新账号、学习一个新界面——它就在你每天已经打开几十次的那个App里。
腾讯的AI助手"元宝"已经深度集成到微信生态中。它可以总结公众号文章、分析网页链接、处理图片和文件。微信的AI搜索已经承接了90%的问答类查询。更激进的是,腾讯正在开发微信AI Agent——让AI可以直接操控微信小程序(拥有14亿月活跃用户的生态)来完成实际任务,比如帮你订餐、买票、预约服务。
腾讯的优势在于分发和场景的深度。其他AI公司需要花巨额营销费用来获取用户,腾讯只需要在微信中加一个功能入口——13亿用户立刻就能触达。而且微信的社交属性意味着AI功能会自然传播——当你的朋友在群里用AI总结了一篇文章,你也会想试试。这种"零成本获客、社交裂变传播"的优势,是任何创业公司都无法复制的。
腾讯在开源方面的投入也在加大——混元系列的语言、视觉和3D模型都选择了开源路线,展现了腾讯参与全球AI开源生态的意愿。但相比阿里Qwen的全面开源和国际化运营,腾讯的开源更多服务于自身产品生态的建设,国际社区的影响力相对有限。
中国AI产业的三个独特特征
纵观中国AI产业的全景,有三个特征值得特别关注。
第一,价格战的烈度远超全球同行。从2024年开始,中国大模型的API定价进入了"血战"模式。DeepSeek-R1的API价格仅为OpenAI o1的3.6%。字节豆包的定价又比DeepSeek低了数倍。通义千问一度推出免费调用。这种价格战的底层逻辑是:中国的大模型公司大多依靠外部融资或母公司补贴运营,还没有建立自我造血的商业模式——在这个阶段,"跑马圈地、先占用户再说"的互联网思维占据了主导。价格战对用户是好事(AI变得极其便宜),对行业健康是隐忧(大量公司在亏损运营)。
第二,"应用为王"的产业取向。与美国AI产业更偏重基础模型研发不同,中国AI产业从一开始就非常注重应用落地。字节的豆包深度集成到抖音和飞书,腾讯的混元深度集成到微信,阿里的通义千问深度集成到淘宝和钉钉。中国公司更擅长"把AI塞进用户已经在用的产品里",而不是"让用户去学一个全新的AI产品"。这种应用导向的策略,让中国AI的用户渗透率在某些场景中甚至超过了美国——尽管在底层模型能力上可能还有差距。
第三,开源与芯片制约的双重博弈。美国的芯片出口管制限制了中国AI公司获取最先进GPU的能力——这是一个不争的事实。但正如第十三章所分析的,这个约束反而催生了两种应对策略:一是DeepSeek式的"效率创新"——用更聪明的算法弥补硬件差距;二是全面拥抱开源——当你不能靠砸更多GPU来赢得竞争时,开源社区的集体智慧就成为了最重要的资源。阿里、智谱、月之暗面、MiniMax都选择了不同程度的开源路线,中国开源大模型在HuggingFace上的下载量和影响力持续增长。芯片制约在短期内限制了算力,但在长期可能反而加速了中国AI产业的效率创新和开源文化的形成。
这一章告诉我们什么
没有永恒的赢家,只有不停的迭代
2023年初,ChatGPT看起来是不可撼动的王者。两年后,Claude在代码上超过了GPT-4,Gemini在多模态上建立了独特优势,DeepSeek用二十分之一的成本训练出了同级模型,Qwen成为了全球下载量最大的开源模型之一,Kimi在长上下文上开辟了新赛道,豆包在用户量上碾压了所有人。大模型时代没有"赢者通吃"——因为AI的应用场景太多元、用户需求太分散、技术迭代太快速,任何一家公司都不可能在所有维度上同时领先。
选择比努力更重要
每一家成功的大模型公司,都不是在"所有方向上都做到最好",而是在一个精心选择的方向上做到极致。Anthropic选择了安全和代码,Mistral选择了效率和欧洲市场,月之暗面选择了长上下文,MiniMax选择了全模态和娱乐场景,DeepSeek选择了效率优先。对创业者和从业者来说,最重要的不是追赶最新的基准分数,而是找到自己的差异化位置。
开源是这个时代最重要的基础设施
从LLaMA泄露到DeepSeek全栈开源,开源运动在三年内将大模型的使用门槛从数亿美元降到了接近于零。这不仅仅是技术的民主化——它是整个AI产业格局重塑的底层力量。任何一个从业者,无论身处什么行业、什么规模的公司,都可以站在开源社区的肩膀上,用世界级的AI能力来提升自己的产品和服务。这是大模型时代给每个人的最大礼物。
2023年只有一个OpenAI让全世界仰望,2026年有几十家公司让全世界选择。从硅谷到巴黎、从北京到杭州,群星闪耀的背后是技术的民主化、商业的多元化和创新的全球化。对读者来说,这张全景图的意义不在于记住每个公司的名字和参数——而在于理解一个时代的本质:当基础技术被开源、被共享、被每个人都能使用时,真正的竞争不再是"谁有最强的模型",而是"谁能用AI创造最大的价值"。
这个问题的答案,不在实验室里,而在每一个正在思考"AI能为我做什么"的人手中。
本章引用论文
[1] LLaMA: Open and Efficient Foundation Language Models, 2023, Meta (Touvron et al.) — 交叉引用第九章
[2] Mixtral of Experts, 2024, Mistral AI (Jiang et al.) — 交叉引用第九章
[3] GPT-4 Technical Report, 2023, OpenAI — 交叉引用第九章
[4] Constitutional AI: Harmlessness from AI Feedback, 2022, Anthropic (Bai et al.) — 交叉引用第九章
[5] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, 2025, DeepSeek-AI — 交叉引用第十三章
[6] DeepSeek-V3 Technical Report, 2024, DeepSeek-AI — 交叉引用第十三章
[7] Gemini: A Family of Highly Capable Multimodal Models, 2023, Google DeepMind (Gemini Team)
[8] Gemini 1.5: Unlocking Multimodal Understanding Across Millions of Tokens of Context, 2024, Google DeepMind
[9] ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools, 2024, Zhipu AI (GLM Team)
[10] Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context, 2019, CMU (Dai, Yang et al.)
[11] XLNet: Generalized Autoregressive Pretraining for Language Understanding, 2019, CMU & Google (Yang et al.)
[12] Kimi K1.5: Scaling Reinforcement Learning with LLMs, 2025, Moonshot AI
[13] Qwen Technical Report, 2023, Alibaba Cloud (Qwen Team)
[14] Qwen2.5 Technical Report, 2024, Alibaba Cloud (Qwen Team)
[15] Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent, 2024, Tencent
[16] Stanford Alpaca: An Instruction-following LLaMA Model, 2023, Stanford (Taori et al.)
[17] Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality, 2023, LMSYS Org
终章:站在涌现的边缘
写到这里,我想回到序章里的那个凌晨两点。
那个坐在屏幕前、对着客户需求文档发愁的人——两年前的我——如果穿越到今天,会看到一个他完全无法想象的世界。他当时纠结的那个"工程图纸识别"的问题,现在用一个免费的开源模型就能解决。他当时不敢下注的那个"模型会不会在三个月内进步"的赌局,后来的事实证明,答案永远是"会,而且比你想的更快"。他在过去一年多里断断续续读的150多篇论文,现在有AI助手可以帮你在一个下午里梳理出核心脉络。
但有些东西没有变。这个行业依然让人焦虑——只不过焦虑的内容从"大模型到底有没有用"变成了"大模型好像什么都能做了,那我还能做什么?我怎么才能把它用得更好?怎么才能用它创造出真正的价值?"每隔几周依然有新模型发布,媒体依然不是说"颠覆"就是说"革命"。我依然需要在信息洪流中判断:什么是真的趋势,什么是暂时的噪音;什么需要现在就行动,什么可以等一等。
所以这个终章,与其说是"给读者的行动指南",不如说是写给我自己的一封信——站在2026年3月这个时间节点上,把前面十四章讲述的技术演进线索汇总到一起,理一理自己看清了什么、还没想明白什么、接下来打算怎么做。如果这些思考对你也有用,那就更好了。
第一部分:技术的五条河流——大模型正在往哪里去
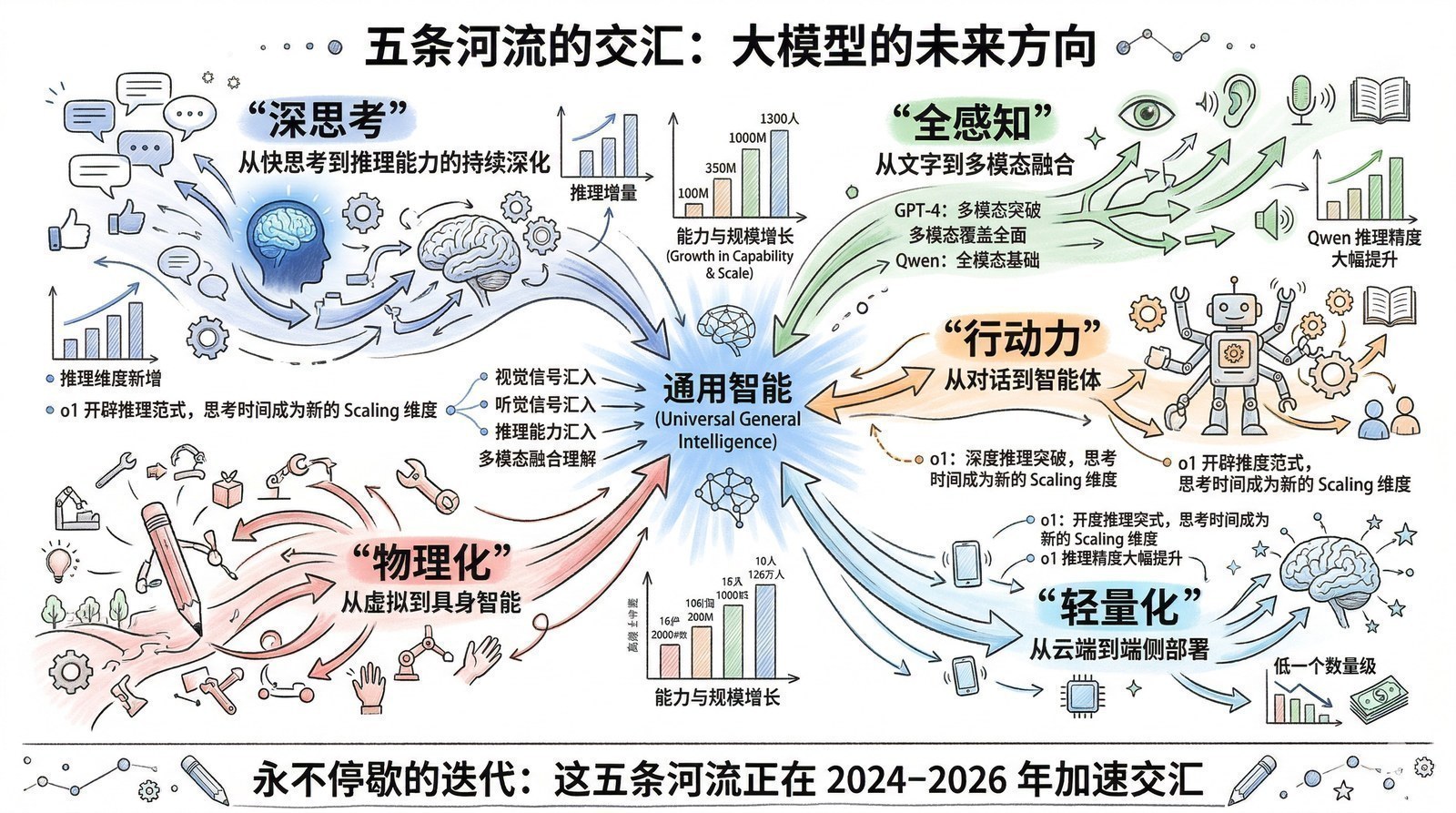
在过去十四章中,我们看到大模型的能力像台阶一样一级一级往上跳。但如果你把视角拉远一点,会发现这些台阶不是沿着一条直线排列的——它们分布在至少五个不同的方向上,像五条河流各自奔涌,偶尔交汇。
第一条河:从"快思考"到"深思考"——推理能力的持续深化
第十章讲了OpenAI o1如何让模型学会"想一想再回答"。第十三章讲了DeepSeek-R1如何用纯强化学习让推理能力"涌现"。这两个故事揭示的是大模型演进中最重要的一条路线:推理能力的持续深化。
2022年的ChatGPT是"快思考"——你问它一个问题,它立刻给出答案,速度很快但容易犯错,特别是在数学、逻辑和多步骤推理上。2024年的o1和2025年的R1是"慢思考"——模型在回答之前先进行一段内部推理,像人类解数学题一样一步步推导。这个转变(第十章称之为"从System 1到System 2")极大地提升了模型在复杂任务上的表现。
但"慢思考"只是起点。到2026年,推理能力正在向三个更深的方向演进。
第一个方向是推理时间的动态伸缩。早期的推理模型有一个明显的缺点:它"思考"的时长是固定的——无论问题简单还是复杂,模型都会花差不多的时间去"想"。这就像一个学生不管遇到什么题目都要演算半小时——简单题浪费时间,复杂题又不够用。新一代推理模型(包括OpenAI的o3和DeepSeek的后续版本)开始具备"动态分配思考时间"的能力——简单问题快速回答,复杂问题深度推理,自动判断什么时候该"想更久"。
第二个方向是推理过程的可验证性。当模型的推理链变得越来越长(R1的思维链有时长达数千字),一个新的问题浮现了:我怎么知道模型的推理过程是对的?人类可以检查一段三步推理,但检查一段五十步推理就非常困难了——如果第七步出了错,后面四十三步都建立在错误的基础上,但表面上看起来"逻辑通顺"。如何让长链推理变得可验证、可审计,是当前学术界和产业界都在攻克的难题。
第三个方向是推理与行动的融合。"思考"和"做事"在人类身上是自然融合的——你在修一辆自行车时,手在拧螺丝的同时大脑在判断下一步该做什么。但当前的推理模型是"先想完再做"——它把整个思考过程走完,然后一次性输出答案。2025-2026年的一个重要趋势是"智能体"(Agent):模型不仅能思考,还能自主地调用工具、浏览网页、执行代码、操作软件。
这些技术方向说起来有点抽象,但落到产品和应用层面,变化已经非常具体了。
以我自己的工作为例。2024年初,我让ChatGPT帮忙审核一份技术合同——它能读懂每一段话的意思,但不会主动去交叉比对第3页的"交付标准"和第17页的"验收条件"之间是否矛盾。我得自己告诉它:"请对比这两段话"。到了2025年底,同样的任务交给一个推理模型,它会自己发现矛盾、标注冲突、甚至建议修改方案——不需要我手把手指挥每一步。从"你告诉它检查哪里"到"它自己知道该检查哪里",这个变化看似不大,但在实际业务中意味着一个人可以完成原来需要三个人分工才能做的审核工作。
再看一个更贴近日常的场景。一个跨境电商运营,以前让AI帮忙写产品文案——给它一段产品描述,它能生成还不错的广告语。但他不能让AI去分析"这个产品在日本市场和东南亚市场的文案策略应该有什么区别",因为这需要模型理解文化差异、消费心理、平台算法等多个维度的知识并做交叉推理。推理模型正在让这种"需要想一想才能回答好"的复杂任务变得可行。
推理能力的持续深化,意味着AI能处理的任务复杂度正在快速上升——从"帮我写一封邮件"到"帮我分析这份合同里的风险点"再到"帮我做一个完整的竞品分析并给出行动建议"。对我这样天天在业务一线的人来说,这意味着AI从"打字机"进化成了"初级分析师"——它还不能完全替代有经验的专业人士,但它已经能独立完成很多原来需要初级员工花几天才能做完的分析工作。
第二条河:从"文字"到"全感知"——多模态的融合
第一章讲了AI如何学会"看见"(计算机视觉),第二章讲了AI如何学会"听懂"(语音识别),第八章讲了AI如何学会"创造"(图像生成)。这些能力在过去是各自独立的——你需要一个模型来看图,另一个模型来听声音,再一个模型来生成图片。
2024-2025年最重要的趋势之一,是这些能力开始融合到同一个模型里。GPT-4o(2024年5月)第一次展示了一个模型同时"看、听、说"的能力——你可以和它视频通话,它能看到你展示的东西、听到你的问题、用语音回答。Gemini从第一天起就选择了"原生多模态"的技术路线(第十四章)。Qwen3-Omni成为了中国第一个全模态开源模型。
这种融合不只是"多了几种输入输出方式"那么简单。它代表着一种根本性的变化:AI开始像人类一样通过多种感官来理解世界。
用一个具体的例子来感受这种变化。2023年,如果你想让AI帮你分析一段工厂车间的视频,你需要:先用一个视频处理工具把视频切成帧,再用一个物体检测模型识别帧中的设备和人员,再用一个OCR模型识别设备上的仪表读数,再用一个文本模型把这些信息整合成报告——整个流程需要四五个模型串联,每个环节都可能出错。2025年,你可以直接把视频扔给一个全模态模型,用一句话说"帮我检查这段视频里有没有安全隐患",模型会自己看视频、识别异常、生成报告。从"人类设计流程、AI执行步骤"到"人类提出目标、AI自主完成"——这是多模态融合带来的真正范式转变。
多模态的下一步是什么?两个方向正在同时推进。一个是"感知的精度"——当前的多模态模型在理解日常照片和视频上已经很强,但在理解工程图纸、医学影像、卫星遥感等专业视觉内容上还有明显差距。弥补这个差距需要大量的专业领域训练数据——序章里提到的"工程图纸识别"问题,本质上就是这个短板的体现。另一个是"交互的实时性"——当前的多模态交互还有明显的延迟(你说一句话,模型要想几秒才能回应),离真正流畅的"面对面对话"还有距离。当延迟降到200毫秒以下(人类正常对话中的自然停顿时长),AI的多模态交互体验才会发生质变。
第三条河:从"对话"到"行动"——智能体的崛起
过去十四章讲述的大模型,本质上都是"对话系统"——你输入文字(或图片、语音),模型输出文字(或图片、语音)。无论它有多聪明,它的能力都被限制在"对话框"里。它可以告诉你怎么修bug,但不能帮你打开编辑器真的去修。它可以帮你写一份市场分析报告,但不能帮你登录数据库去拉数据。
2025年,这个边界开始被打破。
"智能体"(Agent)是2025-2026年AI产业最热的关键词之一。它的核心思想是:让大模型不仅能"说",还能"做"——自主地调用工具、执行操作、完成任务。Claude Code可以在终端里自主编写、测试和部署代码。字节的豆包2.0定位于"Agent时代"。腾讯正在开发的微信AI Agent可以操控小程序帮你订餐、买票、预约服务。
智能体和传统的AI助手有什么区别?用一个日常场景来感受:你对传统的AI助手说"帮我订今天下午3点从北京到上海的高铁票",它会回复你"你可以打开12306 App,选择北京到上海的线路……"——它告诉你怎么做,但你得自己去做。你对一个智能体说同样的话,它会自己打开12306、搜索车次、选择座位、完成支付(需要你确认),然后告诉你"已经订好了,G7次列车,下午3点发车,二等座"。
这个区别看起来只是"多做了几步",但它的产业意义是深远的。当AI从"给建议"进化为"能执行"时,它能替代的不再只是"知识工作"(写文档、分析数据),而是"流程性工作"(下单、填表、发邮件、调API)。大量重复性的、跨系统的操作性工作——在企业中占据了惊人比例的工时——突然有了被自动化的可能。
但智能体也带来了新的挑战。首先是信任问题:你愿意让AI代替你操作银行账户吗?当AI执行的操作不可逆(比如发送一封邮件、提交一个订单)时,"AI犯错"的代价比"AI说错话"高得多。其次是安全问题:一个能操作软件的AI,理论上也能被恶意利用。这些问题在技术上还没有完善的解决方案,也是当前智能体产品大多停留在"人类确认后执行"阶段的原因。
第四条河:从"云端"到"身边"——模型的小型化与端侧部署
第十三章讲了DeepSeek如何用MoE架构让671B参数的模型只激活37B参数——"总知识量"很大,但每次"调用"的计算量很小。第十四章讲了R1的蒸馏生态——把671B模型的推理能力压缩到1.5B的小模型里,可以在手机上运行。
这些不是孤立的技术进步——它们代表着一个重要的产业趋势:大模型正在从"只能在云端运行"走向"在你身边的设备上运行"。
为什么"在身边运行"很重要?三个原因。第一是隐私——你的个人数据不需要发送到远程服务器上,AI在你自己的设备上本地处理。对于医疗、法律、金融等隐私敏感场景,这是刚需。第二是延迟——本地运行意味着不需要等待网络传输,响应速度可以从秒级降到毫秒级。对于实时交互(比如同声传译、实时辅助驾驶),低延迟是必须的。第三是成本——一旦模型部署到终端设备上,推理的边际成本几乎为零,不需要按API调用次数付费。
2025年,苹果的Apple Intelligence、高通和联发科的端侧AI芯片、以及各家手机厂商集成的本地大模型,让"手机上运行AI"从概念变成了现实。虽然端侧模型的能力还远不如云端模型,但对于很多日常任务(文本摘要、简单问答、语音助手、照片编辑),端侧模型已经"够用"了。
真正让我觉得有意思的是"云端和端侧的协作"——这可能是未来AI产品架构的标准模式。
想象一下这样的场景:你的手机里有一个小型AI模型常驻运行。你在微信里收到一段语音消息,本地模型立刻帮你转成文字——不需要联网,毫秒级完成,你的语音内容完全不离开手机。然后你想让AI帮你拟一段回复,这时候手机判断"这个任务需要更强的语言能力",把请求(而不是原始语音)加密上传到云端的大模型,几秒后收到一段措辞得体的回复建议。整个过程中,你的原始语音数据始终留在本地,只有经过处理和脱敏的请求才会到达云端。
这种"本地做隐私敏感的、简单的、需要低延迟的任务,云端处理需要强大能力的复杂任务"的分级架构,解决了一个长期以来的矛盾:用户既想要最强的AI能力(需要云端),又不想把所有数据都上传到别人的服务器上(需要本地)。分级协作让两者兼得成为可能。
再举一个企业场景的例子。一家医院部署了本地的AI模型,医生口述病历时,本地模型实时转写并结构化——患者的姓名、病情、检查结果全部在院内服务器上处理,绝不外传。但当医生需要AI帮忙做复杂的辅助诊断(比如对比最新的医学文献、分析罕见病例),院内系统会将脱敏后的症状描述发送到云端的大模型获取建议。病人的隐私留在本地,AI的能力天花板由云端保障——这种架构对于医疗、金融、法律等隐私敏感行业来说几乎是唯一可行的AI部署方式。
从产业趋势来看,端云协作正在催生多种AI商业模式的探索:不同形态的模型在不同的设备上以不同的方式提供服务——有的预装在设备中作为基础能力,有的通过订阅提供增值服务,有的按调用量付费。苹果、华为、小米等手机厂商,以及各类IoT设备厂商,都在探索适合自己生态的端云协作模式。最终的商业格局可能不会是单一的"免费+付费"模式,而是多种模式并存——就像今天的互联网服务有免费广告模式、订阅模式、按量付费模式一样,AI的商业模式也会因设备、场景和用户群体的不同而呈现多样化的形态。
第五条河:从"虚拟"到"物理"——具身智能的萌芽
前面四条河都发生在"数字世界"里——AI处理的是文字、图片、代码、网页。第五条河开始流向"物理世界"——让AI控制机器人,在真实环境中行动。
第九章提到了GPT-4的多模态能力为机器人感知带来的革命性提升。这个故事在2025-2026年有了更具体的进展。大模型的"通用理解能力"正在被应用到机器人的感知和决策系统中——一个搭载了多模态大模型的机器人,不需要为每个物体和每个动作编写专门的识别规则,它可以"理解"一个场景的整体含义,然后做出合理的行动。2026年春节联欢晚会上,具身智能机器人在舞台上表演武术的场景让数亿观众见证了这项技术的进步——虽然离真正实用还有距离,但它展示了一种可能性:机器人不再是只能在工厂流水线上重复同一个动作的"机械臂",而是可以在开放环境中理解场景、做出灵活反应的"智能体"。
具身智能是这五条河中最早期、最不成熟的一条。当前的AI机器人在实验室环境中可以完成一些令人印象深刻的任务(叠衣服、整理厨房、搬运物品),但离真正进入家庭和工作场所还有很长的距离——物理世界的复杂性、安全要求和成本约束,让具身智能的商业化比纯软件AI困难得多。
但它的长期意义可能超过前面四条河的总和。如果AI只停留在数字世界里,它能影响的主要是"知识工作"和"信息处理"。当AI进入物理世界——制造、物流、农业、建筑、家政——它影响的就是实体经济的每一个角落。
五条河的交汇——通用智能的地基
这五条河不是各自孤立的——它们正在交汇。而每一次交汇,都会催生出比单条河流更强大的能力。
推理能力+智能体=一个能"想清楚再做"的AI执行者。当前的智能体大多是"接到指令就去执行",像一个听话但不太会变通的实习生。当推理能力和智能体深度融合后,AI可以在执行过程中自主判断"这步做得对不对""遇到意外该怎么调整""有没有更高效的方案"——从"盲目执行指令"进化为"有判断力的执行者"。这对企业级应用意义巨大:你可以让AI去处理一个复杂的客户投诉,它不仅能调取客户记录、查询订单状态,还能判断这个投诉是否合理、应该用什么策略回应、是否需要升级到人工处理。
多模态+具身智能=一个能"看到并理解环境、然后做出行动"的机器人。不再是只能在预设轨道上运行的机械臂,而是一个能走进一间从未见过的房间、观察环境、理解需要做什么、然后灵活行动的智能体。这种能力的基础,恰恰是前面几条河汇聚的结果:视觉理解来自多模态融合(第二条河),动作规划来自推理能力(第一条河),自主执行来自智能体(第三条河),在设备端低延迟运行来自小型化(第四条河)。
小型化+多终端=一个"随身携带的全感知助手"。可以在你的手机、眼镜、耳机、手表、车机中运行——不同的终端各自承担最适合自己的感知和交互任务,在本地做即时处理,必要时调用云端能力。苹果的Vision Pro、Meta的智能眼镜、各家车企的座舱AI,都是这个方向上的具体探索。
把视角再拉远一点。如果我们把这五条河的交汇看作一个整体,它实际上是在为一个更大的东西打地基——通用人工智能(AGI)。所谓AGI,简单说就是一个"什么都能做"的AI系统:能理解自然语言、能看懂周围环境、能自主思考和规划、能调用工具和操作设备、能在各种新场景中灵活适应,而且在你的手机上就能运行。
今天我们离这个目标还有多远?说实话,没有人知道。行业内的观点差异巨大——乐观者认为三到五年内可达,谨慎者认为还需要根本性的理论突破。但有一件事是确定的:这五条河的每一步进展,都在为AGI铺设一块基石。推理能力让AI具备了"思考"的基础,多模态让AI具备了"感知"的基础,智能体让AI具备了"行动"的基础,小型化让AI具备了"无处不在"的基础,具身智能让AI具备了"进入物理世界"的基础。即使AGI的最终形态还不清晰,这五块基石的价值已经是实实在在的——每一块都在当下产生着巨大的产业影响。
本书不做预测,但我自己的判断是:不管AGI是五年后还是十五年后到来,在那之前的每一年,这五条河各自和交汇带来的能力增长,都足以重塑一批行业、创造一批机会、淘汰一批旧模式。关注这些能力增长本身,比猜测AGI什么时候到来更有意义。
第二部分:这些变化意味着什么
前面讲的是"技术往哪里去"。现在我换一个视角:这些技术变化,对我们这些在行业里摸爬滚打的人来说,到底意味着什么?
"软件吞噬世界"之后,"AI吞噬软件"
2011年8月20日,硅谷传奇投资人马克·安德森(Marc Andreessen)在《华尔街日报》发表了一篇著名的文章——《为什么软件正在吞噬世界》(Why Software Is Eating the World)。他的核心观点是:每一个传统行业最终都会被软件重塑——出租车行业被Uber重塑,酒店行业被Airbnb重塑,零售行业被亚马逊重塑。十五年过去了,他说对了——2011年全球企业软件支出2690亿美元,到2026年已经远超这个数字的三倍。
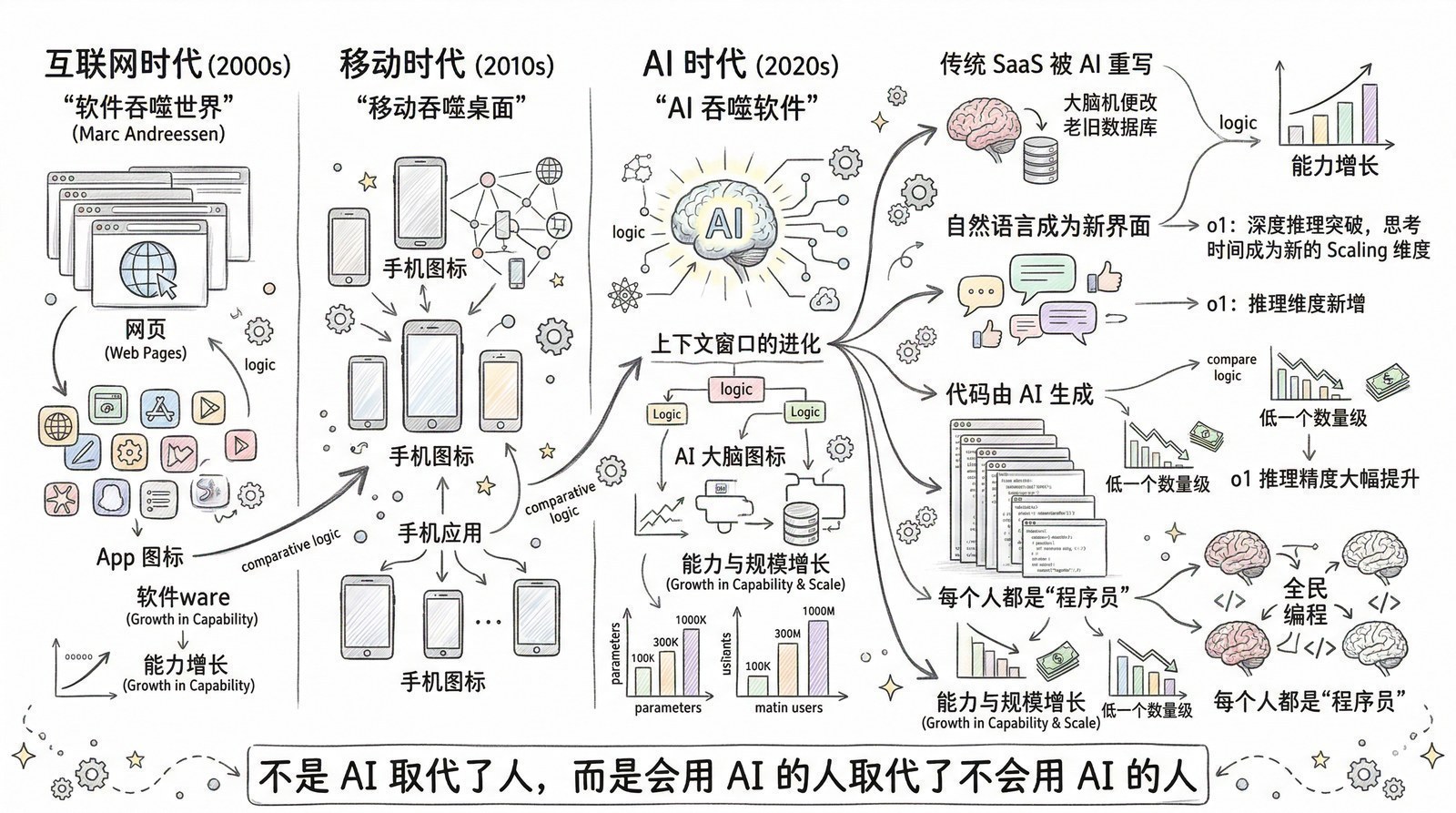
现在,我们可以在这个论断上加一层:AI正在吞噬软件。
什么意思?过去十年软件行业的核心工作模式是"人类编写规则,软件执行规则"——产品经理写需求文档,工程师把需求翻译成代码,代码在服务器上按照预设的逻辑运行。每一个功能、每一个流程、每一个边界条件,都需要人类明确地用代码表达出来。
大模型正在改变这个模式。越来越多的软件功能不再需要人类编写明确的规则——你只需要告诉AI"目标是什么",AI自己去理解、推理、生成解决方案。客服系统不再需要人工编写FAQ和决策树——大模型可以直接理解用户的问题并给出合理的回答。数据分析不再需要数据分析师写SQL查询——用户用自然语言描述"我想看上个月各地区的销售额对比",AI自动生成查询、执行查询、可视化结果。代码开发本身也在被AI重塑——Claude Code写代码的能力在很多场景下已经超过了初级程序员,GitHub Copilot让开发者可以用自然语言描述功能,AI生成代码。
这种变化对就业市场的冲击,我觉得需要诚实地面对。
初级程序员和工程师的岗位正在被真实地影响。当AI可以在几分钟内写出一段几百行的代码,而且质量不比一个两年经验的程序员差——那些"按照需求文档写代码"的纯执行性工作,确实面临着巨大的替代压力。这不是危言耸听——我身边已经有团队开始缩减初级开发岗位,因为一个资深工程师配合AI的产出效率,可以覆盖原来两三个初级工程师的工作量。
但硬币的另一面是:对人的要求不是降低了,而是变得更高了。
以前,一个产品经理只需要会写需求文档、画原型图、和开发沟通——这些技能在大模型时代的价值正在缩水,因为AI也能做。但一个真正优秀的产品经理——能深入理解客户的业务、能把制造业客户说不清楚的需求翻译成精确的产品定义、能判断一个零售企业的核心痛点到底是库存管理还是用户画像——这些能力AI做不了,而且在AI时代变得比以前更重要。因为当"写代码"不再是瓶颈时,"到底该写什么代码"就成了真正的稀缺能力。
同样的逻辑适用于工程师。以前你靠的是"写代码的能力"——对某种编程语言的熟练度、对算法的掌握、对系统架构的理解。现在AI可以替你写代码,但它不能替你理解客户的业务逻辑、不能替你判断在一个特定的行业场景中什么方案是可行的、什么方案是看起来好但实际上行不通的。真正的竞争力从"专业技能"转向了"行业理解"——从"我会写Python"变成了"我理解供应链管理的逻辑,并且能用AI工具把这个理解转化成可运行的系统"。
说得更直白一点:大模型时代对人的要求,从"专业领域的深度"变成了"跨行业的广度+对特定行业的深度理解+驾驭AI工具的能力"。这三者的结合,才是未来真正的竞争力。一个只懂技术不懂业务的工程师,和一个只懂业务不会用AI的产品经理,都会越来越吃力。而一个既理解行业know-how、又能熟练使用AI工具的人——无论他的头衔是工程师、产品经理还是架构师——会成为最抢手的人才。
开源vs闭源:不是二选一,而是生态共生
第九章讲了Meta开源LLaMA的战略逻辑,第十三章讲了DeepSeek全栈开源的震撼效果,第十四章梳理了开源运动的五次里程碑跃迁。到这里,一个自然的问题是:未来的AI产业是开源主导还是闭源主导?
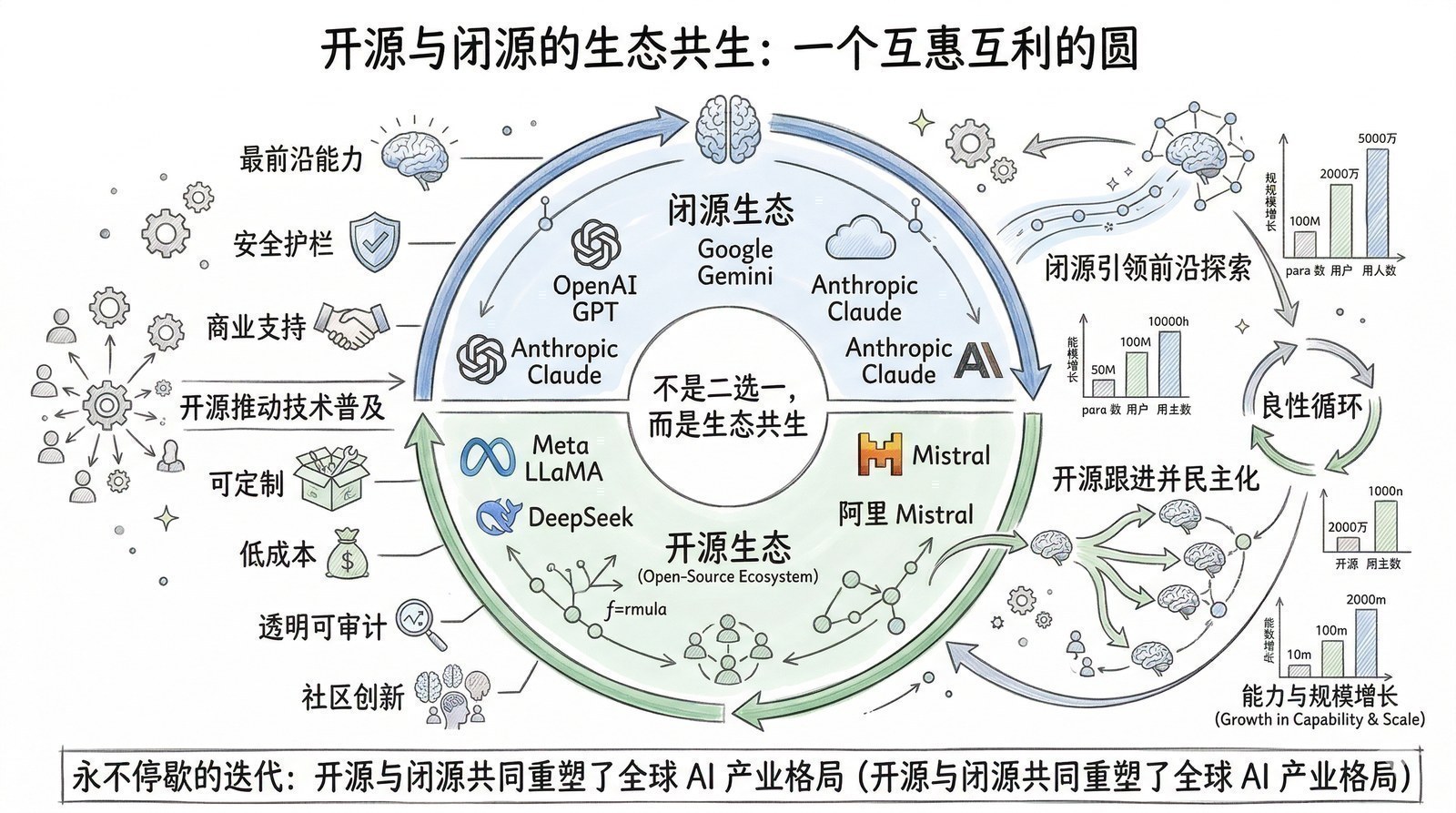
答案可能是:两者共存,各有领地。
闭源模型的优势在于"最后那5%的能力差距"和"端到端的产品体验"。在需要最极致能力的场景(顶级的代码生成、最复杂的科学推理、最精准的多模态理解),闭源模型通常比同时期的开源模型强一些——因为闭源公司可以用最大的资源、最好的人才、最多的数据去训练一个不需要公开的模型,并且通过持续的在线学习和反馈优化来保持领先。OpenAI的GPT系列、Anthropic的Claude、Google的Gemini在各自的优势领域保持着性能上的微弱领先。
开源模型的优势在于"够用的能力"加上"完全的控制权"。对于大多数实际应用场景,开源模型的能力已经"够用"了——不需要最强的模型,需要的是一个足够好、可以在自己的服务器上运行、可以针对自己的数据做微调、不需要担心隐私和供应商锁定的模型。DeepSeek、Qwen、LLaMA、Mistral的开源模型覆盖了这个庞大的需求。
更可能的格局是"闭源做旗舰,开源做基座"——闭源模型占据最高端的、最追求极致性能的场景(专业研究、顶级企业服务),开源模型覆盖广泛的、追求性价比和自主可控的场景(中小企业、垂直行业、个人开发者)。这和操作系统市场的格局类似——macOS/iOS(闭源)占据高端市场,Linux/Android(开源)占据广泛市场,两者长期共存。
中国特色的AI产业
第十四章用了大量篇幅描绘中国AI产业的全景——六小虎、三巨头、成本优化、应用为王。写到这里,我想说说我对中国AI产业机会的理解。
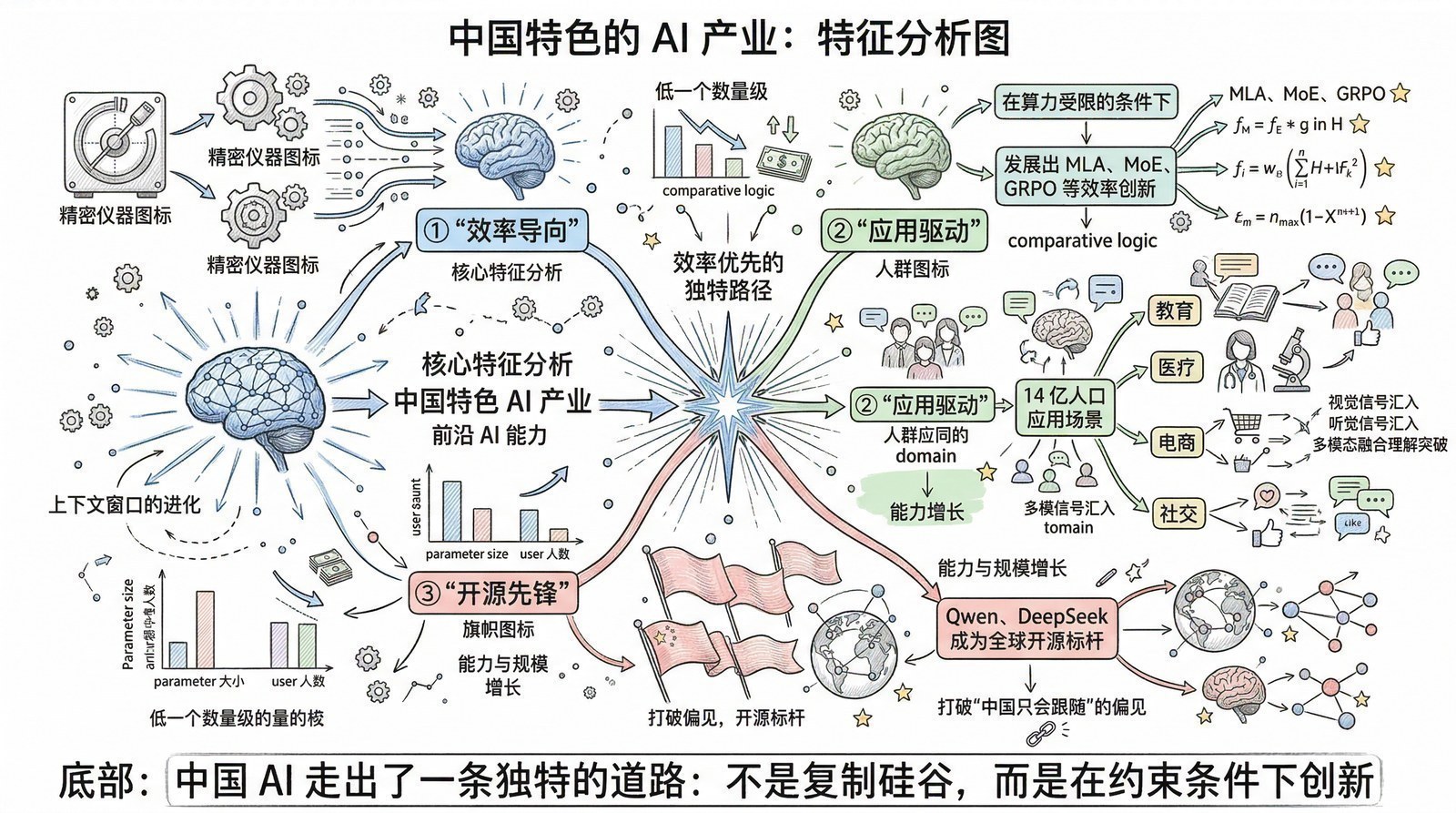
先说算力的问题。很多人担心芯片制裁会卡住中国AI的脖子——这种担心在一两年前确实有道理,但到2026年,情况已经没有那么悲观了。
原因是这样的:AI的使用场景中,99%以上是推理(让训练好的模型回答问题),而不是训练(从零开始训练一个新模型)。推理对芯片的要求远低于训练——国产芯片对推理任务的适配已经相当不错了。训练确实需要最顶级的NVIDIA GPU,但训练是集中式的——全中国只需要DeepSeek、Qwen、智谱这几个头部团队拥有训练级别的算力就够了。他们用集中的NVIDIA卡训练出基座模型,然后开源给全行业使用——全行业在推理端用国产芯片部署和运行。这种"训练集中、推理分散"的模式,让芯片制裁的实际影响比表面看起来小得多。
而且中国在推理的成本优势上是碾压性的。中国的电费便宜、机房建设成本低、芯片(国产推理芯片)价格远低于NVIDIA——这意味着在中国部署AI推理的综合成本可以做到极低。DeepSeek的API价格是OpenAI的几十分之一,这不仅仅是因为算法高效,也因为整条推理基础设施的成本结构就比美国便宜。
顺着这个逻辑想下去,我觉得中国AI产业真正能和美国并驾齐驱、甚至超越的机会,在于两件事。
第一件事是把AI的使用成本做到极致——让token的价格无限趋近于电费。当AI的推理成本低到和水电气一样的时候,token就不再是"技术服务",而是和水、电、燃气一样的"基础设施"——每个人、每个企业、每天都在消耗,像空气一样无处不在。中国在这方面有天然优势:电力成本低、基础设施建设能力强、全产业链配套完善。当token变成了"新型公用事业",那么成本结构就决定了竞争力——而这恰恰是中国最擅长的战场。
第二件事是把AI深深地扎进各行各业的产业链中。美国确实发明了以大模型为代表的这一波AI技术——但"发明技术"和"把技术用好"是两件完全不同的事情。一个最贴切的类比是电动汽车:特斯拉定义和发明了智能电动汽车,但真正把电动车带到千家万户、把电动化和智能化做到极致的,是以比亚迪为首的中国车企。特斯拉做的是"从0到1",中国车企做的是"从1到10000"——而"从1到10000"的过程中创造的价值和就业,远远超过"从0到1"。
AI的故事可能也是如此。OpenAI发明了ChatGPT,Google发明了Transformer——但真正把AI渗透到制造业的每一条产线、零售业的每一个门店、物流业的每一个仓库、教育的每一间教室的,可能还是中国。因为中国有全世界最完整的产业链、最多样的应用场景、最庞大的用户基数——这些都是AI"落地"的沃土。AI本身只是工具,工具的价值在于它能提升多少生产力——而中国特别擅长的,恰恰就是把新技术嵌入到产业链中去推动整个社会的效率提升。
对于我这样的从业者来说,最大的启发是:不要去做"中国的OpenAI"——那是属于少数先驱者的赛道。去做"AI+你最懂的行业"——用AI去解决你身边的、具体的、真实的行业问题。这才是这片土地上最肥沃的机会。
第三部分:我打算怎么做——也许对你也有用
序章里我说过,这个系列的目标是给你三样东西:一条时间线、一张地图、一种直觉。前面十四章和终章的前两部分,已经尝试交付了前两样。这一部分关于第三样——直觉。
但直觉不是"读"出来的,是"做"出来的。所以这一部分不是理论分析,而是我自己接下来打算做的事情——也许对你也有参考价值。
先把AI用起来——像用电脑一样自然
这是我给自己的第一条行动准则,也是最重要的一条。
"会用AI"正在变成和"会用电脑"一样基础的能力。注意,我说的不是"学AI"——不是让你去读论文、学算法、搞模型训练。而是把AI变成你日常工作的一部分,像打开Word写文档一样自然。
具体来说就是三件事。
第一,选一个AI助手,每天用它。不是偶尔尝鲜,而是把它变成你日常工作流的一部分。写邮件时让它帮你润色,读报告时让它帮你摘要,做决策时让它帮你列出正反两方面的论据,学新东西时让它当你的家教。选哪个不重要——ChatGPT、Claude、Kimi、豆包、通义千问都可以——重要的是坚持用。只有在大量的实际使用中,你才能建立起对AI能力边界的真实感知——知道什么任务它做得好、什么任务它会胡说八道、什么样的提问方式能得到更好的回答。这种感知不能通过阅读文章获得,只能通过亲身体验积累。
第二,学会"验证"AI的输出。AI最危险的不是"不知道",而是"自信地说错"。它会用极其流畅和自信的语气给你一个完全错误的答案——如果你不具备验证能力,就可能被它误导。养成习惯:对于任何重要的AI输出,都要交叉验证。这不是"不信任AI",而是"正确地使用AI"——就像你不会因为有了计算器就不检查计算结果一样。
第三,保持对新产品的好奇心。AI产品的迭代速度极快,每隔几个月就会有新的工具出现。不需要每个都深入研究,但值得定期试用最新的产品——很多时候,你觉得"AI做不到"的事情,只是因为你用的还是半年前的产品。
向下扎根——在细分行业里找到自己的位置
如果你和我一样在考虑"AI时代该做什么",我的想法是:不要去做通用的AI大模型产品。
原因很现实:通用大模型是巨头的赛道。训练一个前沿基座模型需要数千块顶级GPU、数亿美元投入、全球顶尖的研究团队——这是OpenAI、Google、DeepSeek、阿里的战场,不是普通创业者能玩得起的。而且"通用"意味着它什么都能做一点、但对任何一个具体行业都不够精确——一个通用大模型能帮你写一封还不错的营销邮件,但它不懂你们行业的合规要求、不了解你的客户画像、不知道你们的销售流程。
真正的机会在"AI+细分行业"——用AI去解决特定行业、特定场景中的具体问题。
一个最典型的反面例子是:给每个行业的客户装一个ChatBot对话框,让客户"和AI聊天"来解决业务问题。这种做法太简单粗暴了——一个制造业的质检工程师不需要一个"聊天机器人",他需要的是一个能自动分析产品缺陷图片、对比质量标准、生成质检报告的专业工具。一个零售门店的店长不需要一个"AI助手",他需要的是一个能根据天气、节假日、历史销售数据自动调整进货计划的智能系统。
这些细分场景的AI产品,需要的不是最强的模型——Qwen、DeepSeek的开源模型已经足够强了。它们真正需要的是对行业的深入理解:这个行业的流程是什么?痛点在哪里?数据长什么样?用户的工作习惯是什么?什么样的AI功能是"真的有用"而不是"看起来很酷"?
这就回到了前面说的:大模型时代对人的要求,不是"懂AI",而是"懂行业+会用AI"。最有价值的人,是能走进一个制造业工厂、一家零售连锁店、一个物流仓库,把他们说不清楚的需求翻译成AI能解决的问题的人。
中国在这方面有巨大的优势——第十四章讲过的"应用为王"的产业取向、全产业链的协同能力、以及各行各业对数字化和智能化的旺盛需求,都是AI向下扎根的沃土。这片土地上的机会,比做一个"通用AI聊天机器人"大得多。
在技术栈中找到"对的层"
大模型的技术栈可以粗略分为四层:
(1) 基座模型层(预训练大模型)——这是DeepSeek、OpenAI、Google在做的事情,需要数千块GPU、数亿美元投入、顶尖的研究团队。除非你在这些公司工作,否则这一层不需要你投入。
(2) 微调与适配层(在开源模型基础上做领域适配)——门槛远低于预训练,但仍然需要一定的GPU资源和算法能力。
(3) 应用与产品层(用AI的能力解决具体问题)——这是价值创造最直接、离用户最近的一层。不需要深厚的AI算法知识,但需要理解AI的能力边界和用户需求。对大多数技术从业者来说,这一层的投入回报比最高。
(4) 基础设施层(GPU集群、推理优化、模型部署)——如果你有系统工程背景,这一层的人才需求在快速增长。
我观察到的一个常见误区是:很多技术从业者花大量时间去学"怎么训练模型""怎么做微调"——但实际上,99%的AI应用不需要你自己训练或微调模型。开源模型已经足够强了,API也已经足够便宜了。真正稀缺的不是"能训练模型的人",而是"能用AI解决具体行业问题的人"。
一个制造业客户不关心你用的是什么模型、参数量多大、用了几块GPU——他关心的是"你的AI系统能不能让我的质检效率提升50%"。回答这个问题需要的不是模型训练能力,而是对制造业质检流程的理解、对AI能力边界的判断、对产品体验的设计。
把时间花在"怎么用AI解决具体问题"上,比花在"怎么训练AI"上,对大多数人来说回报率更高。这是我给自己的提醒,也分享给有同样困惑的人。
保持清醒,保持好奇
最后,两个对我帮助最大的认知。
第一个是:大模型的进步速度可能比你想的更快,但它的局限性也比你想的更顽固。每隔几个月,就有一个新模型在某个基准上"超越人类"——但在真实的业务场景中,这些模型依然会犯低级错误、会"幻觉"(自信地说出错误信息)、会在看似简单的逻辑推理上翻车。"基准测试上的超人类"和"实际应用中的可靠"之间,有一条巨大的鸿沟。我在做项目时反复提醒自己这一点——因为每次被AI的能力震撼之后,就容易低估它犯错的概率。
第二个是:AI不会取代你,但会用AI的人可能会取代不用AI的人。这句话已经被说烂了,但我自己的体会是真切的。过去一年,我用AI辅助写作、分析论文、梳理技术方案、审核文档、生成代码——它把我很多工作的效率提高了好几倍。AI是一个"放大器"——它放大你已有的能力和判断力。如果你的基础能力强、行业理解深、判断力好,AI会让你如虎添翼。如果你缺乏这些,AI只会帮你更高效地犯错误。
所以,最好的行动不是"学AI"——而是把你本来就擅长的事情做得更好,然后用AI来放大它。
涌现的边缘
写到这里,这个系列暂时告一段落了。
从2012年Alex Krizhevsky用两块游戏显卡训练AlexNet(第一章),到2025年DeepSeek用2048块H800训练出匹配GPT级别的模型(第十三章)——十三年的时间,大模型从一个学术界的边缘实验,变成了重塑全球科技产业的核心力量。在这条路上,有无数的论文、无数的工程师、无数的深夜调试和灵光一现。这个系列尝试把其中最重要的里程碑串联起来,给出一张尽可能完整的地图。
但地图不是目的地。而且这张地图本身就是不完整的。
我所有读过的论文、梳理过的技术演进,截止到2025年底。然而就在我写这个终章的2026年3月,新的技术又在不断涌现——Google DeepMind的AlphaFold已经从蛋白质结构预测拓展到了更广泛的科学发现领域;OpenAI也在探索AI驱动科学研究的新路径;世界模型(World Model)——让AI不仅理解语言和图像,还能理解物理世界运行规律——正在从概念走向实验;2026年春晚上表演武术的具身智能机器人,让数亿中国观众第一次直观感受到"AI走进物理世界"的可能性。这些最新的进展,在本书的十四个章节中还没有被充分覆盖。
技术不会等人。当你读到这里的时候,可能又有新的模型发布了,又有新的能力被解锁了,又有新的论文把某个我以为还很远的能力变成了现实。
这也是我希望"智能涌现"这个系列能够持续更新的原因。大模型的故事还在不断续写,我会持续跟踪最新的技术进展——世界模型、具身智能、AI for Science、多智能体协作——把它们纳入这个不断生长的知识体系中。就像序章里说的"论文是前面的伏笔,产品发布是后面的揭晓"——这个故事还远没有到结局。
序章里我用了"涌现"这个词来命名这个系列——当模型的规模达到某个临界点时,会突然展现出没有人设计过的新能力。我希望你读完这个系列之后获得的不仅是知识,更是一种"涌现"——当足够多的论文、故事、数据和洞见被串联在一起时,你能自发地形成一种看待AI发展的全局直觉。这种直觉不是任何单篇文章能给的,它只能从对全貌的理解中自然生长出来。
我们正站在涌现的边缘。没有人知道下一次涌现会在哪里发生——也许是一个推理能力再次飞跃的新模型,也许是一个真正能在物理世界中自如行动的机器人,也许是一个我们今天还无法想象的全新应用场景。
但有一件事是确定的:无论未来怎样演进,那些理解了"这一切是怎么来的"的人,会比其他人更有能力理解"这一切将往哪里去"。
这就是这个系列想给你的东西——也是我写给自己的东西。
愿我们都能在涌现的边缘,找到属于自己的位置。然后用AI,去释放出各行各业中沉睡的生产力。
故事未完,让我喘口气,我们持续更新。
本章引用论文
本章为综述性质的终章,不引入新论文,所有技术论断均基于前序章节中已引用的论文。以下列出关键的交叉引用:
[1] Attention Is All You Need (Transformer), 2017, Google — 交叉引用第四章
[2] GPT-3: Language Models are Few-Shot Learners, 2020, OpenAI — 交叉引用第六章
[3] InstructGPT: Training Language Models to Follow Instructions with Human Feedback, 2022, OpenAI — 交叉引用第七章
[4] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, 2022, Google — 交叉引用第十章
[5] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, 2025, DeepSeek-AI — 交叉引用第十三章
[6] LLaMA: Open and Efficient Foundation Language Models, 2023, Meta — 交叉引用第九章
[7] GPT-4 Technical Report, 2023, OpenAI — 交叉引用第九章
智能涌现——大模型是如何练成的
陈浩 博士 著
版式:155mm × 230mm
正文字体:10.5pt
行距:1.44倍
页边距:上22mm 下36mm 左18mm 右18mm
版本:v1.0 2026年3月23日
排版工具:Playwright + PyMuPDF